Treinamento de modelo de IA distribuído no HPC Pack
Fundo
Nos dias atuais, os modelos de IA estão evoluindo para se tornarem mais substanciais, exigindo uma demanda crescente por hardware avançado e um cluster de computadores para treinamento eficiente de modelo. O HPC Pack pode simplificar o trabalho de treinamento de modelo para você com eficiência.
PyTorch Distributed Data Parallel (também conhecido como DDP)
Para implementar o treinamento de modelo distribuído, é necessário utilizar uma estrutura de treinamento distribuída. A escolha da estrutura depende da usada para criar seu modelo. Neste artigo, vou orientá-lo sobre como proceder com o PyTorch no HPC Pack.
O PyTorch oferece vários métodos para treinamento distribuído. Entre eles, o DDP (Distributed Data Parallel) é amplamente preferencial devido à sua simplicidade e alterações mínimas de código necessárias ao seu modelo de treinamento de máquina única atual.
Configurar um cluster do HPC Pack para treinamento de modelo de IA
Você pode configurar um cluster HPC Pack usando seus computadores locais ou VMs (Máquinas Virtuais) no Azure. Basta garantir que esses computadores estejam equipados com GPUs (neste artigo, usaremos GPUs Nvidia).
Normalmente, uma GPU pode ter um processo para um trabalho de treinamento distribuído. Portanto, se você tiver dois computadores (também conhecidos como nós em um cluster de computador), cada um equipado com quatro GPUs, poderá obter 2 * 4, o que equivale a 8, processos paralelos para um único treinamento de modelo. Essa configuração pode potencialmente reduzir o tempo de treinamento para cerca de 1/8 em comparação com o treinamento de processo único, omitindo algumas sobrecargas de sincronização de dados entre os processos.
Criar um cluster do HPC Pack no modelo do ARM
Para simplificar, você pode iniciar um novo cluster do HPC Pack no Azure, em modelos do ARM no GitHub.
Selecione o modelo "Cluster de nó de cabeçalho único para cargas de trabalho do Linux" e clique em "Implantar no Azure"
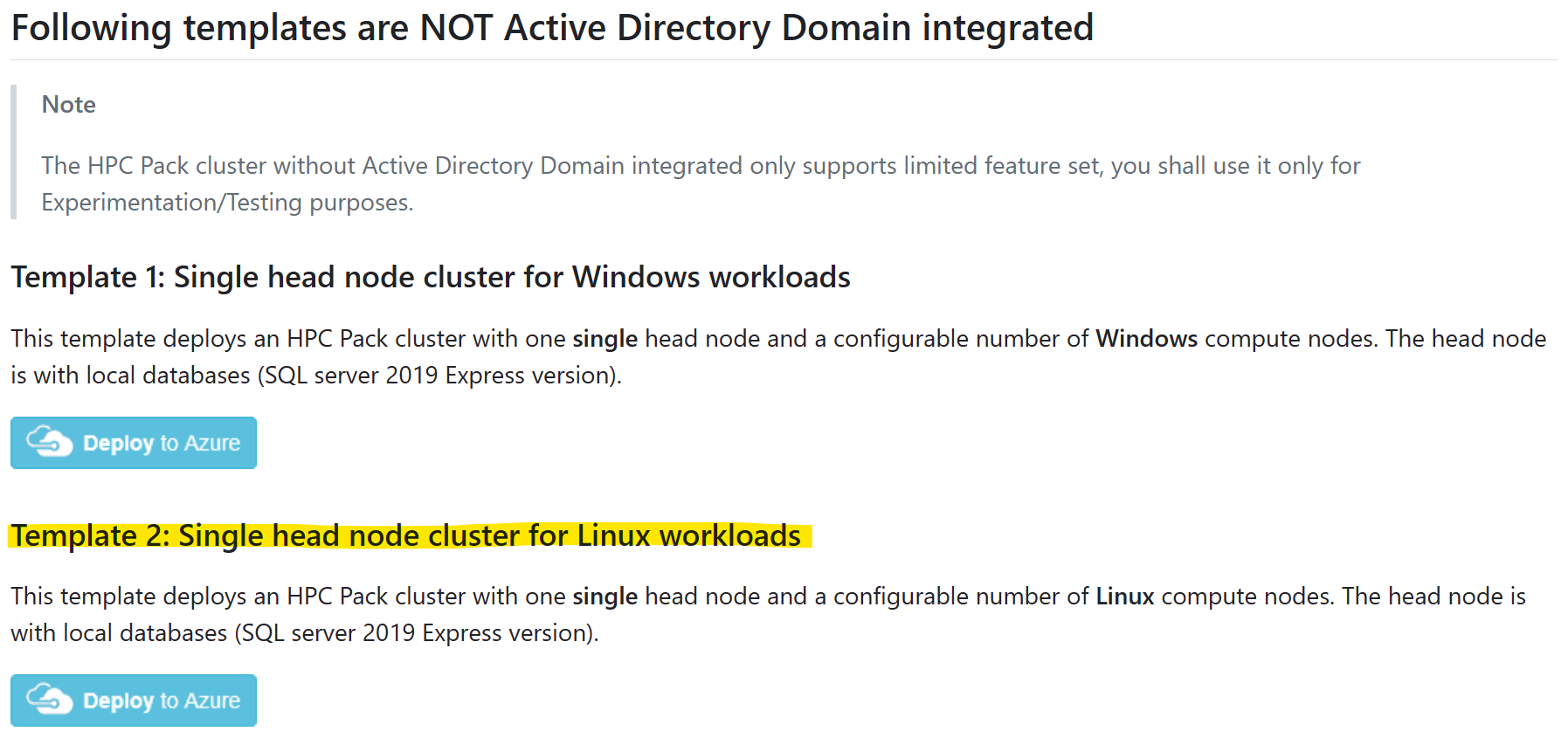
E consulte os pré-requisitos de de como fazer e carregar um certificado para uso do HPC Pack.
Observe:
Você deve selecionar uma Imagem do Nó de Computação marcada com "HPC". Isso indica que os drivers de GPU estão pré-instalados na imagem. Não fazer isso exigiria a instalação manual do driver de GPU em um nó de computação em um estágio posterior, o que poderia ser uma tarefa desafiadora devido à complexidade da instalação do driver de GPU. Mais informações sobre imagens HPC podem ser encontradas aqui.
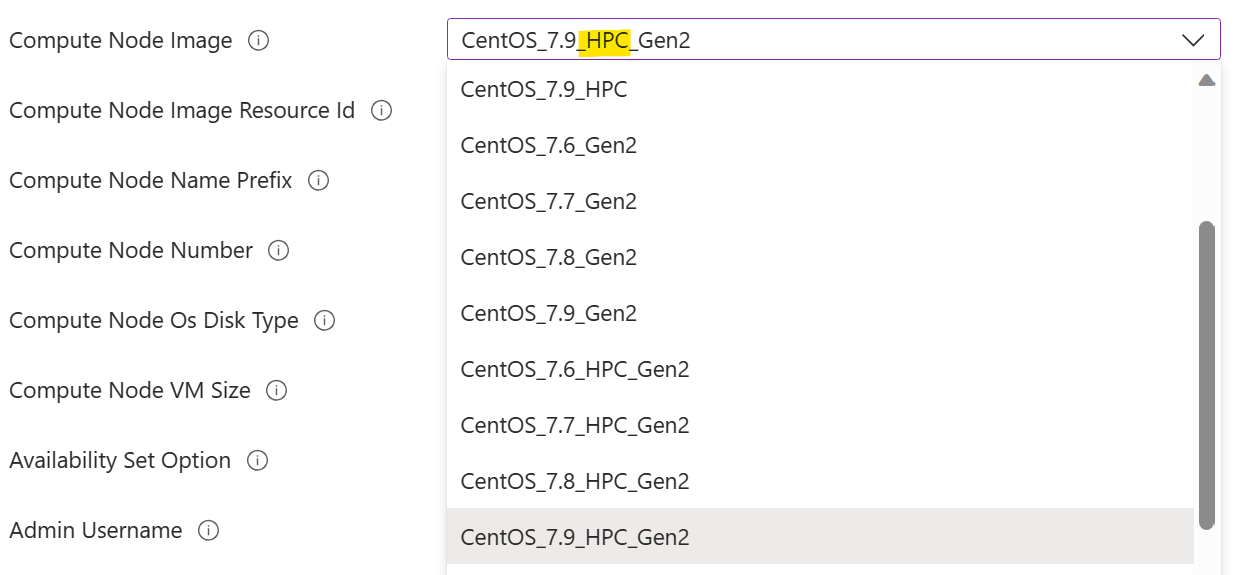
Você deve selecionar um Tamanho da VM do Nó de Computação com GPU. Esse é tamanho da VM da série N.
 de GPU
de GPU
Instalar o PyTorch em nós de computação
Em cada nó de computação, instale o PyTorch com o comando
pip3 install torch torchvision torchaudio
Dicas: você pode aproveitar "Executar Comando" do HPC Pack para executar um comando em um conjunto de nós de cluster em paralelo.
Configurar um diretório compartilhado
Antes de executar um trabalho de treinamento, você precisa de um diretório compartilhado que possa ser acessado por todos os nós de computação. O diretório é usado para treinamento de código e dados (conjunto de dados de entrada e modelo treinado de saída).
Você pode configurar um diretório de compartilhamento SMB em um nó principal e montá-lo em cada nó de computação com cifs, da seguinte maneira:
Em um nó principal, faça um diretório
appem%CCP_DATA%\SpoolDir, que já é compartilhado comoCcpSpoolDirpelo HPC Pack por padrão.Em um nó de computação, monte o diretório
appcomosudo mkdir /app sudo mount -t cifs //<your head node name>/CcpSpoolDir/app /app -o vers=2.1,domain=<hpc admin domain>,username=<hpc admin>,password=<your password>,dir_mode=0777,file_mode=0777NOTA:
- A opção
passwordpode ser omitida em um shell interativo. Você será solicitado a fazer isso nesse caso. - O
dir_modeefile_modeestá definido como 0777, para que qualquer usuário do Linux possa lê-lo/gravá-lo. Uma permissão restrita é possível, mas mais complicada de ser configurada.
- A opção
Opcionalmente, faça a montagem permanentemente adicionando uma linha em
/etc/fstabcomo//<your head node name>/CcpSpoolDir/app cifs vers=2.1,domain=<hpc admin domain>,username=<hpc admin>,password=<your password>,dir_mode=0777,file_mode=0777 0 2Aqui, o
passwordé necessário.
Executar um trabalho de treinamento
Suponha que agora temos dois nós de computação do Linux, cada um com quatro GPUs NVidia v100. E instalamos o PyTorch em cada nó. Também configuramos um "aplicativo" de diretório compartilhado. Agora podemos começar nosso trabalho de treinamento.
Aqui estou usando um modelo de toy simples baseado no PyTorch DDP. Você pode obter o código no GitHub.
Baixe os seguintes arquivos no diretório compartilhado %CCP_DATA%\SpoolDir\app no nó principal
- neural_network.py
- operations.py
- run_ddp.py
Em seguida, crie um trabalho com o Nó como unidade de recurso e dois nós para o trabalho, como
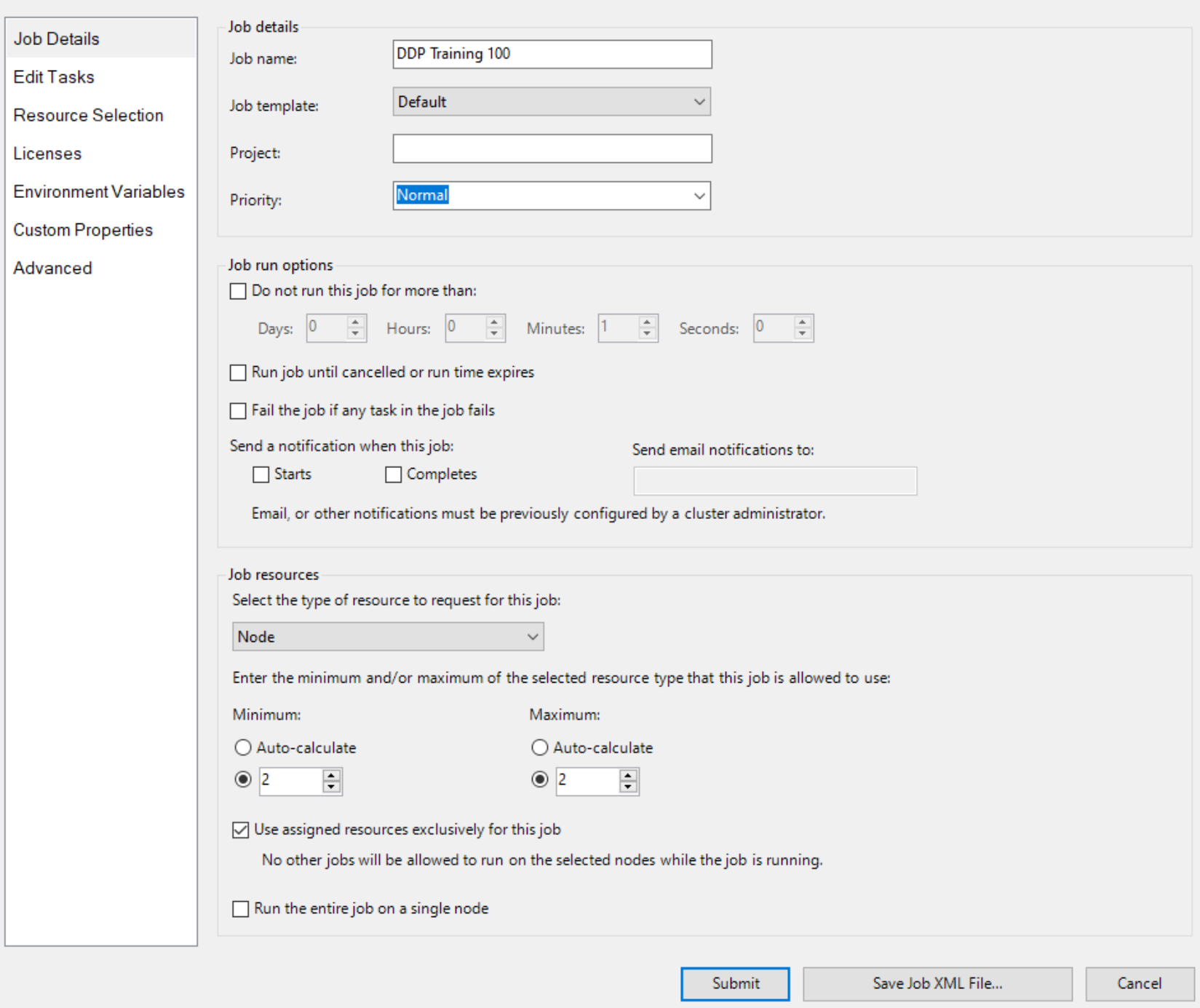
E especifique dois nós com GPU explicitamente, como
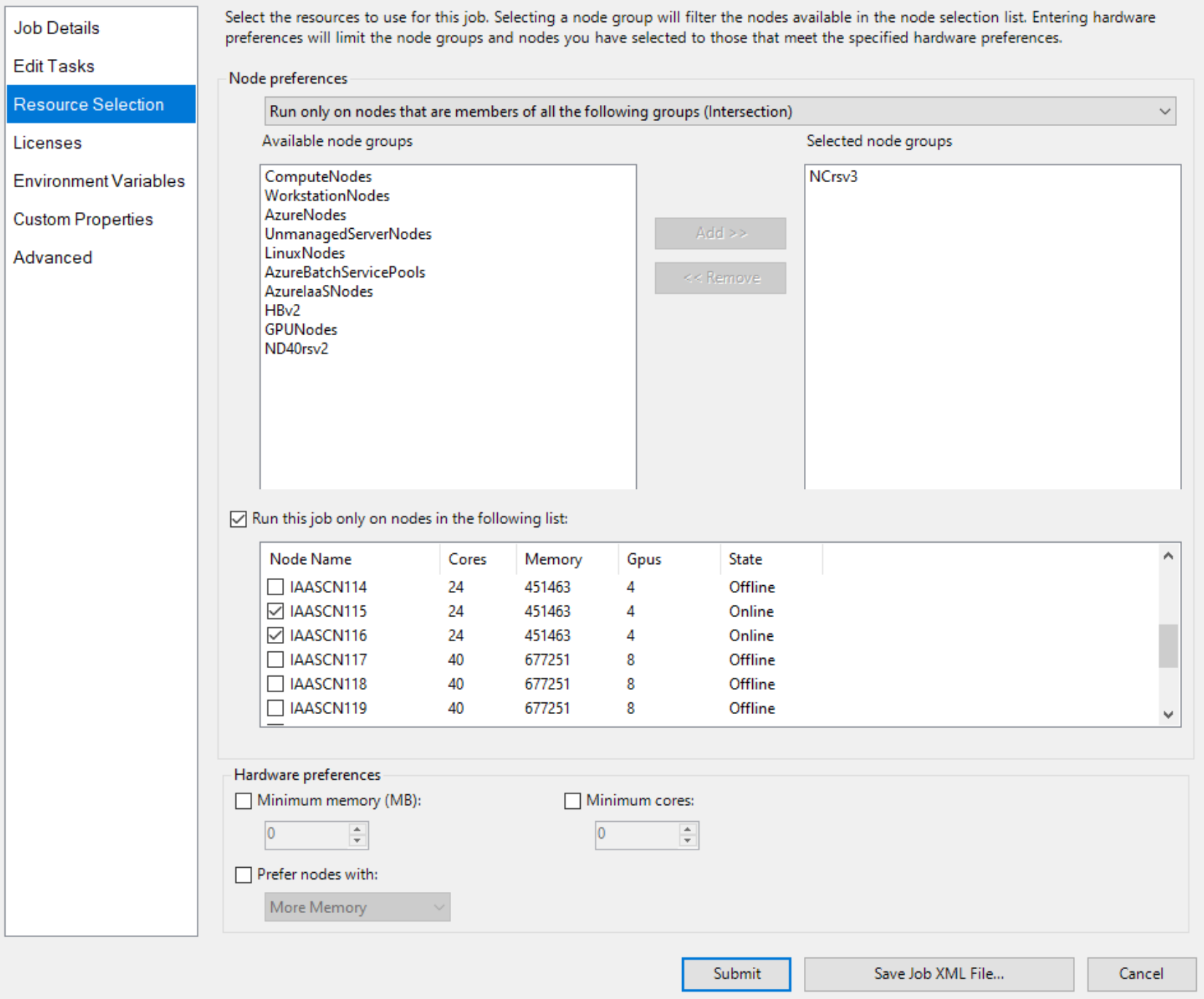
Em seguida, adicione tarefas de trabalho, como
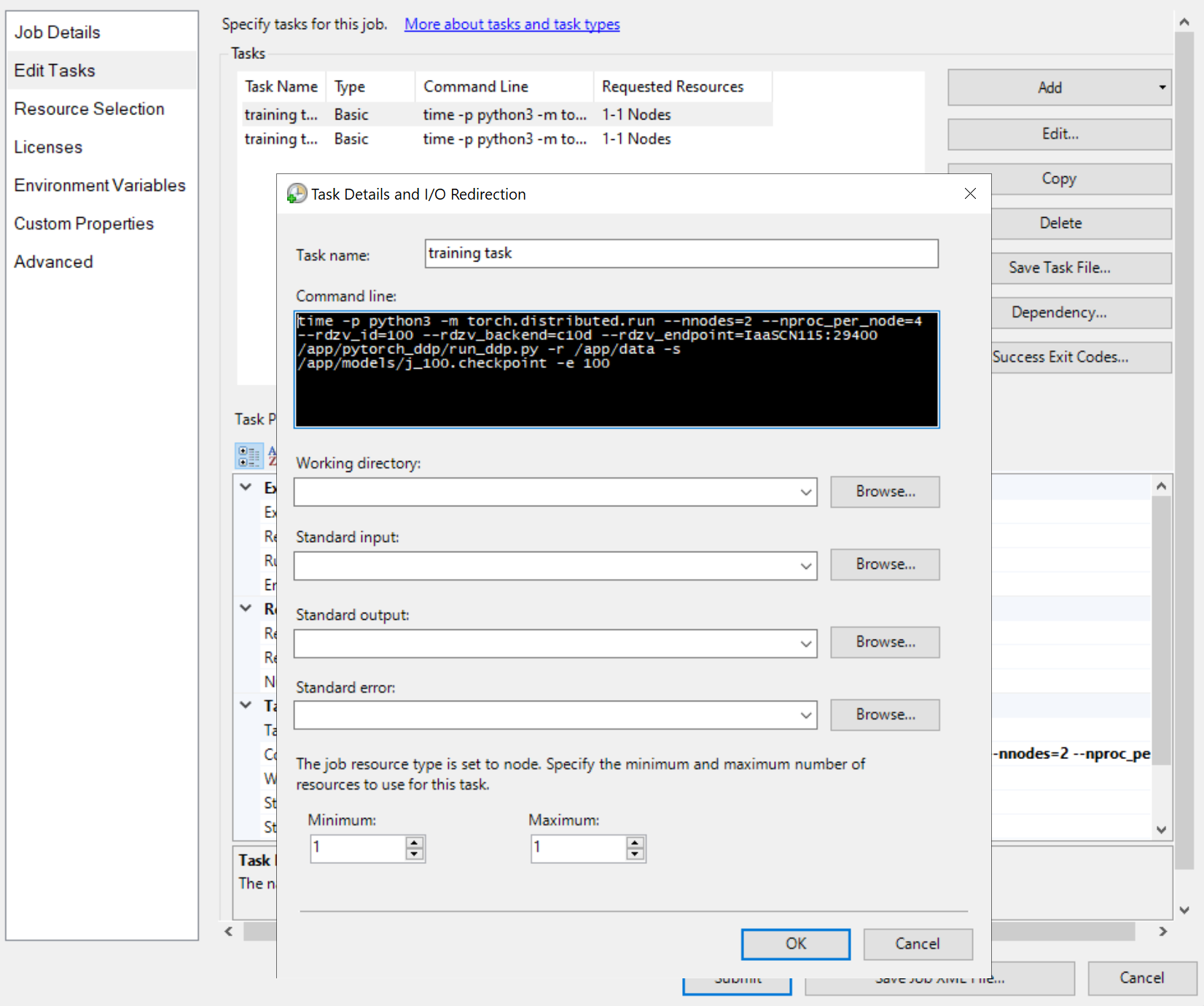
As linhas de comando das tarefas são todas iguais, como
python3 -m torch.distributed.run --nnodes=<the number of compute nodes> --nproc_per_node=<the processes on each node> --rdzv_id=100 --rdzv_backend=c10d --rdzv_endpoint=<a node name>:29400 /app/run_ddp.py
-
nnodesespecifica o número de nós de computação para seu trabalho de treinamento. -
nproc_per_nodeespecifica o número de processos em cada nó de computação. Ele não pode exceder o número de GPUs em um nó. Ou seja, uma GPU pode ter no máximo um processo. -
rdzv_endpointespecifica um nome e uma porta de um nó que atua como um encontro. Qualquer nó no trabalho de treinamento pode funcionar. - "/app/run_ddp.py" é o caminho para o arquivo de código de treinamento. Lembre-se de que
/appé um diretório compartilhado no nó principal.
Envie o trabalho e aguarde o resultado. Você pode exibir as tarefas em execução, como
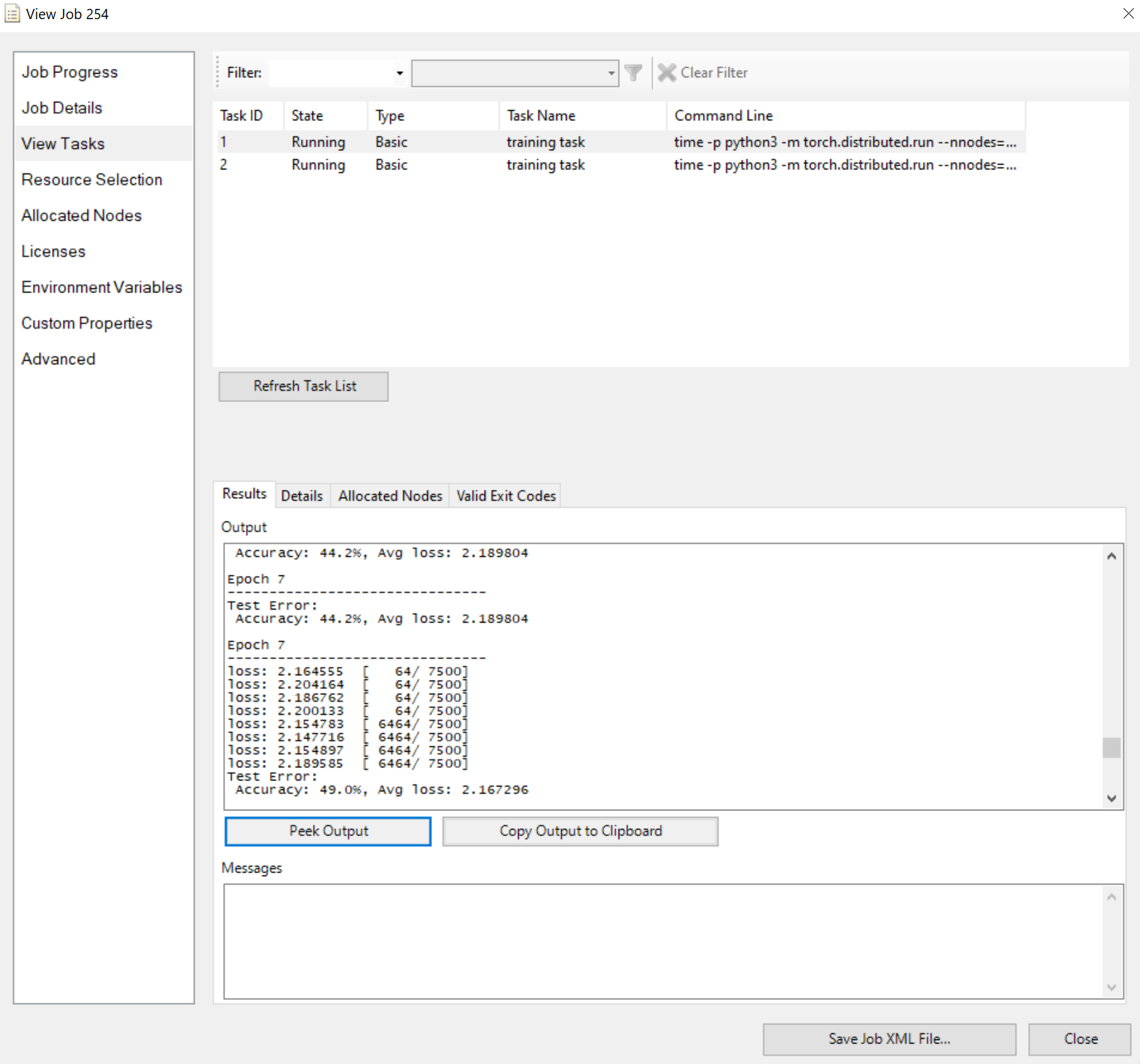
Observe que o painel Resultados mostra a saída truncada se for muito longo.
Isso é tudo para ele. Espero que você consiga os pontos e o HPC Pack possa acelerar seu trabalho de treinamento.