Deploying Applications to Azure Nodes in a Windows HPC Cluster
Starting with HPC Pack 2008 R2 with Service Pack 1 (SP1), HPC Pack includes built-in utilities and mechanisms that help cluster administrators deploy applications (such as executable files, SOA services, XLL files, and cluster-enabled Microsoft Excel workbooks) to Azure nodes that are joined to an on-premises cluster in an Azure "burst" scenario. By default, Azure nodes cannot access on-premises resources and shared folders directly, so the methods that you use to deploy applications on Azure nodes differ from the methods that you use to deploy applications on-premises. Additionally, Azure nodes added to a Windows HPC cluster are deployed and reprovisioned dynamically, so the recommended methods for application deployment help ensure that applications are automatically available on new Azure node instances.
Considerations for HPC application workloads for Azure burst
Before deploying applications to Azure nodes, evaluate whether your existing or planned HPC workloads will run or scale efficiently in Azure. The detailed migration, development, and design considerations for HPC applications that run in an Azure burst scenario are beyond the scope of this topic. In addition, the capabilities of the Azure platform are continuously evolving. However, the following are current characteristics of successful burst to Azure workloads with HPC Pack, particularly for large-scale deployments of Azure nodes:
Highly distributed, single-node computations These include many parametric sweep and certain service oriented architecture (SOA) jobs. Other job types, including Message Passing Interface (MPI) jobs, can run in an Azure burst configuration, but may require selection of a compute-intensive instance size that supports the Azure RDMA network. For general information about HPC job types, see Understanding Parallel Computing Jobs.
Computation time exceeds data movement time Certain HPC workloads require uploading large amounts of data to Azure for computation, or return large amounts of data that has been processed. Ensure that data movement is not a bottleneck in your HPC workflow.
File-based data access Existing HPC applications that access data files on-premises can be readily migrated to run in Azure by accessing data files that are uploaded to Azure blob storage. New HPC applications can be developed to access the variety of storage types in Azure. However, depending on the sensitivity of the data, legal requirements, cost considerations, and other factors, it may not be possible to store application data in Azure.
"Bursty" workload pattern The Azure burst scenario is ideal for resource-intensive workloads that are not easily completed by using the fixed resources of an on-premises cluster. The workloads can include irregular computation spikes, regularly scheduled jobs, or one-off jobs.
For more information about running applications on Azure nodes, see Guidelines for Running HPC Applications on Azure Nodes.
Selecting a method to deploy applications and data to Azure nodes
The method that you use to deploy applications and data (in some cases) to Azure nodes depends on what is required to install your application, as outlined in the following table.
| Installation requirements | Method | Availability |
|---|---|---|
| Installation can be accomplished by copying files and any dependencies such as DLLs or configuration files to the node. | - Administrator packages and stages files to Azure storage by using the hpcpack commands. See Using hpcpack and hpcsync. - Administrator deploys Azure nodes. Packages are automatically deployed (copied and extracted) to new Azure node instances, or administrator can manually deploy if nodes are already running. See Burst to Azure Worker Instances with Microsoft HPC Pack. |
HPC Pack 2008 R2 with SP1 |
| Installation requires silently running an installer or requires additional configuration steps such as setting environment variables or creating firewall exceptions. | - Administrator packages and stages files or installers to Azure storage by using the hpcpack commands. See Using hpcpack and hpcsync. - Administrator specifies a startup script in the Azure node template to configure environment or run install commands. See Use a Startup Script for Azure Nodes. - Administrator deploys Azure nodes. Packages are automatically deployed to new Azure node instances and then the startup script runs as part of the provisioning process. See Burst to Azure Worker Instances with Microsoft HPC Pack. |
HPC Pack 2008 R2 with SP2 |
| Installation and data distribution to Azure nodes can occur during a preparation task at the time the job is run. | - Administrator uses an Azure storage tool such as AzCopy to upload installers and data files to a container in Azure blob storage. - Administrator packages and stages additional files or installers to Azure storage by using the hpcpack commands. See Using hpcpack and hpcsync. - Administrator specifies a startup script in the Azure node template to configure environment or run install commands. See Use a Startup Script for Azure Nodes. - Administrator deploys Azure nodes. Packages are automatically deployed to new Azure node instances and then the startup script runs as part of the provisioning process. See Burst to Azure Worker Instances with Microsoft HPC Pack. - Administrator creates a job with a node preparation task to perform additional installation steps or to download data from an Azure blob storage container. See Define a Node Preparation Task - Job Manager. |
HPC Pack 2008 R2 with SP1 |
| Installation requires steps that are not easily scripted, and the application and application data can be accessed from a durable drive in Azure. - |
- Administrator uses Windows tools to create a virtual hard disk (VHD) and installs the application and any necessary application data on the VHD. - Administrator detaches the VHD and uses the hpcpack upload command to upload the VHD as a page blob to Azure storage. See Using hpcpack and hpcsync. - Administrator specifies the application VHD that is in Azure storage when configuring the Azure node template. See Mount an Application VHD on Azure Worker Nodes. - Optionally, administrator specifies a startup script for additional configurations or to set up shared folders on one or more nodes in the deployment. See Use a Startup Script for Azure Nodes. - Administrator deploys Azure nodes. Azure node instances are created that mount the application VHD, any packages on storage are automatically deployed to the nodes, and then the startup script runs as part of the provisioning process. See Burst to Azure Worker Instances with Microsoft HPC Pack. |
HPC Pack 2012 |
Using hpcpack and hpcsync
Each Azure node deployment is associated with an Azure storage account that is specified in the node template. A cluster administrator can stage files (such as applications, SOA services, XLLs, cluster-enabled Excel workbooks, and utilities) to the storage account by using the hpcpack commands. You can use hpcpack create to package files or folders in a compressed format (.zip) that can be uploaded to Azure storage. Each application, SOA service, or XLL must be packaged separately, and the package must include any required dependencies such as DLLs or configuration files. You can then use hpcpack upload to upload the package to the storage account. You can run the hpcpack commands from the head node, or on a computer that has the HPC client utilities installed.
All packages in the storage account are automatically deployed to new Azure node instances during the provisioning process. This happens when you deploy a set of Azure nodes by using the HPC management utilities, and if your node instances are reprovisioned automatically by the Window Azure system. The hpcsync command runs on each Azure node and copies all packages from storage to the node, and then extracts the files. If you upload packages to storage after the Azure nodes are started, you can deploy the packages by running the hpcsync command manually on each Azure node.
Note
If you create multiple Azure node templates that reference the same storage account, the same staged files will be deployed to all Azure node sets. To deploy different files to different node sets, create a separate Azure storage account for each Azure node template.
The following diagram illustrates the basic workflow and mechanisms for copying applications to Azure nodes:
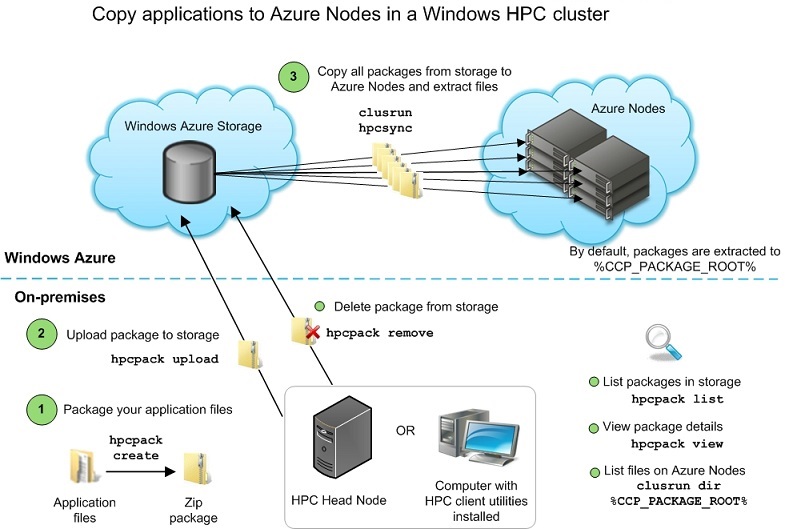
By default, hpcsync extracts files to a location that is specified by the CCP_PACKAGE_ROOT environment variable. This variable is set on Azure nodes during the provisioning process. The extracted files are placed in a folder that is determined as follows: %CCP_PACKAGE_ROOT%\<packageName>\<uploadTimeStamp>. This is the expected location for SOA services, XLLs, and Excel workbooks. However, this is not convenient for applications that cluster users will be calling in their command lines. To simplify the folder structure for executable files, you can set the relative path property for the package when you upload it to storage. hpcsync applies the relative path when extracting the files, so that the path is determined as follows: %CCP_PACKAGE_ROOT%\<relativePath>. Users can then specify the path to their application as in the following example of a job submit command: job submit %CCP_PACKAGE_ROOT%\myRelativePath\myapp.exe
The following are important considerations about hpcsync and CCP_PACKAGE_ROOT:
On Azure worker nodes, the %CCP_PACKAGE_ROOT% folder is created on a 10 GB disk partition. This means that all application files on a node instance cannot exceed 10 GB. If an application has considerable input and output files, you can use a startup script to grant user permissions on the C:\ drives so that users can write to all available scratch space on the node.
When you run hpcsync manually, you can override the default location (%CCP_PACKAGE_ROOT%). For example, you can create a folder on each Azure Node and then specify that location when you run hpcsync. All packages will be extracted to that folder. However, any new node instances that are deployed (or automatically reprovisioned) will not include that folder, and packages will be automatically deployed to the default location. Additionally, cluster users only have write permissions to folders in %CCP_PACKAGE_ROOT%. Unless you modify folder permissions on the Azure nodes, only administrators can run applications outside of %CCP_PACKAGE_ROOT%.
When hpcsync deploys a package, none of the extracted files can have a full path length longer than 256 characters. The root directories where the extracted files are temporarily and then finally placed can take up to 136 characters, leaving 120 characters for the file name, subdirectories (if any), and the relativePath (if specified). If the path for the extracted files exceeds 256 characters, the package deployment fails.
The hpcsync mechanism is sufficient for deploying SOA services, XLL files, and applications that can be installed by simply copying files to a node. If you need to run an installer to install an application, or if the application requires additional configuration steps such as setting environment variables, adding firewall exceptions, modifying folder permissions, or creating folders, you can include a startup script in the node template. This script will run during the provisioning process after hpcsync runs, and can be used to configure the nodes and perform the required application installation steps.
How to stage application files to Azure storage
This section provides information about how to package applications and stage them to Azure storage by using hpcpack. Staged packages are automatically deployed to new Azure node instances that you provision (or that are automatically reprovisioned by the Azure system).
Note
You must be a cluster administrator or at least have the Azure subscription ID and storage account key to stage files to Azure storage.
Requirements
If you are packaging a SOA service:
The name of the package must be the name of the SOA service (that is, the service name that the SOA client specifies in the SessionStartInfo constructor). For example, serviceName.zip or serviceName_serviceVersion.zip.
You must include the service DLL, any dependent DLLs, and the service configuration files in the package.
The service configuration file must also be deployed to the head node. All settings are determined by the on-premises copy of the configuration file.
Do not specify a relative path when you upload the package. SOA services must be unpacked to the default location.
If you are packaging an XLL file:
The name of the package must be the name of the XLL file. For example, XLLName.zip.
If the XLL has dependencies, place the XLL and supporting files in a folder and package the folder. The XLL must be in the top level of the folder (not in a subfolder).
Do not specify a relative path when you upload the package. XLLs must be unpacked to the default location.
If you are packaging an Excel workbook:
The name of the package must be the name of the workbook. For example, workbookName.zip.
If the workbook has dependencies, place the workbook and supporting files in a folder and package the folder. The workbook must be in the top level of the folder (not in a subfolder).
Do not specify a relative path when you upload the package. Workbooks must be unpacked to the default location.
If you are packaging an executable file (such as an MPI application), application installer, or utility that you will call from a startup script:
You must include any dependent DLLs or files in the package.
When you upload the package, specify the relative path property.
If you are packaging a startup script:
The name of the package must be the name of the startup script. For example, startup.bat.zip.
Do not specify a relative path when you upload the package. The startup script must be unpacked to the default location.
If your startup script calls installers or utilities, ensure that you package and stage the required files separately.
Steps
As examples, the following procedures illustrate how to stage various types of application files to Azure storage.
Note
You do not need an elevated command prompt (run as Administrator) to run hpcpack create. However, hpcpack upload requires elevation. To perform the following procedures, run the commands in an elevated command prompt window.
To package and stage a SOA service to Azure storage
If the SOA service is not already registered and deployed to the on-premises cluster, register the SOA service by placing a copy of the service configuration file in the service registration folder on the head node (typically this is %CCP_HOME%\ServiceRegistration). For detailed information, see Deploy and Edit the Service Configuration File.
Copy the service configuration file, the service assembly, and any dependent DLLs to an empty folder. For example, copy the files to a folder named C:\myFiles\myServiceFiles.
At an elevated command prompt, run hpcpack create and specify a name for your package and the folder that contains your service files.
Important
The name of the package must be the name of the SOA service (that is, the service name that the SOA client specifies in the
SessionStartInfoconstructor).For example, to package the content of C:\myFiles\myServiceFiles as myServiceName.zip (and save the package to a folder called AzurePackages):
hpcpack create C:AzurePackagesmyServiceName.zip C:myFilesmyServiceFilesRun hpcpack upload to upload the package to Azure storage by using the following command, where myHeadNode is the name of your head node, and myAzureTemplate is the name of the template that you used to deploy the Azure nodes. For example:
hpcpack upload C:\AzurePackages\myServiceName.zip /nodetemplate:myAzureNodeTemplate /scheduler:myHeadNode
To package and stage an XLL file or Excel workbook to Azure storage
If the XLL or workbook has dependencies on DLLs or other files, copy the XLL or workbook and its dependencies to a folder, such as c:\myFiles\myExcelFiles.
At an elevated command prompt, run hpcpack create to package your XLL or workbook. Specify a name for the package and specify the XLL or workbook. The name of the package must be the name of the XLL file or of the Excel workbook.
For example, if your XLL or workbook has dependencies, package the entire folder (and save the package to a folder called AzurePackages):
hpcpack create C:\AzurePackages\myXLL.zip C:\myFiles\myExcelFilesIf your XLL or workbook has no dependencies, you can package it directly. For example, to package C:\myFiles\myXLL.xll as myXLL.zip:
hpcpack create C:\AzurePackages\myXLL.zip C:\myFiles\myXLL.xllRun hpcpack upload to upload the package to Azure storage by using the following command, where myHeadNode is the name of your head node, and myAzureTemplate is the name of the template that you used to deploy the Azure nodes. For example:
hpcpack upload C:\AzurePackages\myXLL.zip /nodetemplate:myAzureNodeTemplate /scheduler:myHeadNode
To package and stage an executable file to Azure storage
Copy the executable and any dependencies or DLLs to a folder, such as C:\myFiles\myAppFiles.
At an elevated command prompt, run hpcpack create to package your application files. Specify a name for your package and specify the folder that contains your application files.
For example, to package the content of c:\myFiles\myAppFiles as myApp.zip (and save the package to a folder called AzurePackages):
hpcpack create c:\AzurePackages\myApp.zip c:\myFiles\myAppFilesUpload the package to Azure storage by using the following command, where myHeadNode is the name of your head node, and myAzureTemplate is the name of the template that you used to deploy the Azure nodes. Specify a relative path for the application files. For example:
hpcpack upload c:\AzurePackages\myApp.zip /scheduler:myHeadNode /nodetemplate:myAzureTemplate /relativepath:myApp
How to deploy staged packages to Azure nodes
Packages that are staged to Azure storage are automatically deployed to new node instances. You can manually deploy packages - for example, to verify that you have all the necessary dependencies in a package before automating the deployment to all new nodes, or to deploy packages to nodes that are already running. You can use clusrun and hpcsync to deploy the files from the Azure storage account to the Azure nodes.
For example:
clusrun /nodegroup:AzureWorkerNodes hpcsync
To see a list of folders or files that have been deployed to the Azure nodes, you can run the following command:
clusrun /nodegroup:AzureWorkerNodes dir %CCP_PACKAGE_ROOT% /s
Accessing files from Azure nodes
If your HPC application requires file access, the following are options for accessing files from the applications that are deployed to Azure nodes.
| Option | Prerequisites | Notes |
|---|---|---|
| Azure drive | Administrator configures and mounts an application VHD on Azure nodes. See Mount an Application VHD on Azure Worker Nodes. |
- Drive is copied and cached locally on each node - Drive can be written by only one node at a time |
| File server on Azure Virtual Machine | Administrator configures an Azure virtual machine instance, attaches a data disk to the virtual machine, enables the File Server role, and creates a file share folder. See How to Configure an Azure Virtual Machine File Server and Use it from within Windows HPC Server Compute Jobs. |
- Access by jobs to file server resources requires authenticated user access. - Provides SMB compatibility for existing applications - Provides a maximum of 16 TB of data per server - Limits bandwidth to 800 Mb/s |
| Mirror local files to Azure blob storage | Administrator uses an Azure storage tool such as AzCopy to mirror on-premises files to a container in Azure blob storage. |
- Mirroring data from on-premises environment to Azure adds overhead. |
| Access Azure blob storage directly | Application is architected to perform data access operations directly on Azure blobs | - Provides highest scalability of available options |