Recomendações para a resposta a incidentes de segurança
Aplica-se à Power Platform recomendação da lista de verificação de segurança bem arquitetada:
| SE:11 | Defina e teste procedimentos eficazes de resposta a incidentes que abranjam uma gama de incidentes, desde problemas localizados até à recuperação de após desastre. Defina claramente que equipa ou indivíduo executa um procedimento. |
|---|
Este guia descreve as recomendações para implementar uma resposta a incidentes de segurança para uma carga de trabalho. Se a segurança de um sistema for comprometida, uma abordagem sistemática de resposta a incidentes ajuda a reduzir o tempo necessário para identificar, gerir e mitigar incidentes de segurança. Estes incidentes podem ameaçar a confidencialidade, integridade e disponibilidade de sistemas de software e dados.
A maioria das empresas tem uma equipa central de operações de segurança (também conhecida por Centro de Operações de Segurança [SOC] ou SecOps). A responsabilidade da equipa de operações de segurança é rapidamente detetar, priorizar e fazer a triagem possíveis ataques. A equipa também monitoriza os dados de telemetria relacionados com a segurança e investiga falhas de segurança.
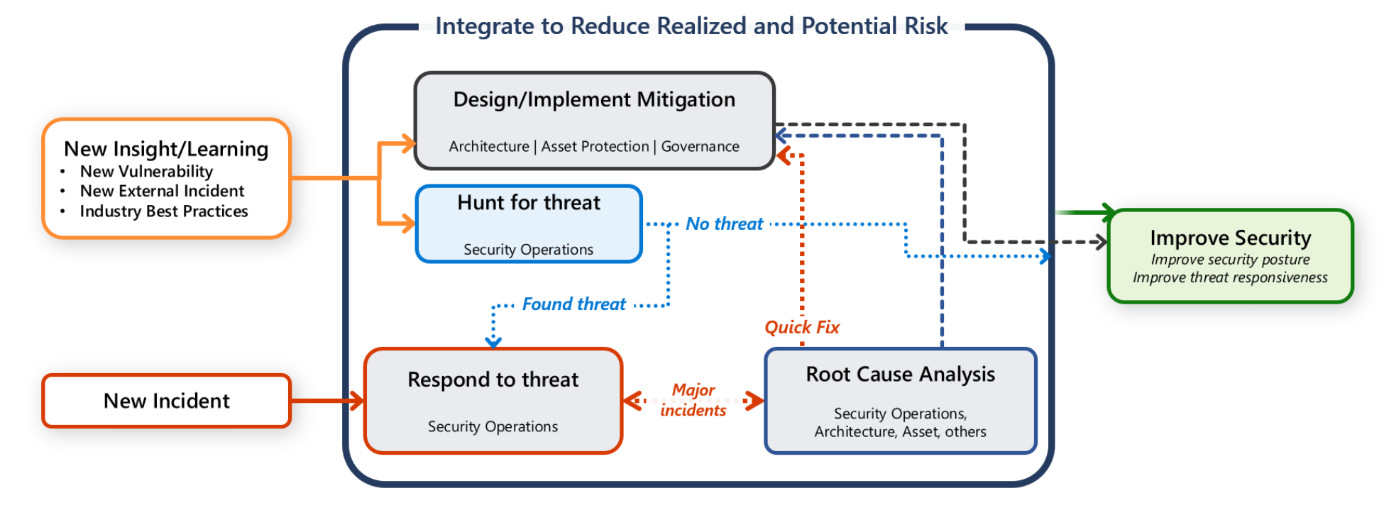
No entanto, também tem a responsabilidade de proteger a sua carga de trabalho. É importante que todas as atividades de comunicação, investigação e procura sejam um esforço colaborativo entre a equipa de carga de trabalho e a equipa SecOps.
Este guia fornece recomendações para si e para a sua equipa de carga de trabalho para o ajudar a detetar, fazer a triagem e investigar ataques rapidamente.
Definições
| Termo | Definição |
|---|---|
| Alerta | Uma notificação que contém informações sobre um incidente. |
| Fidelidade do alerta | A precisão dos dados que determinam um alerta. Os alertas de alta fidelidade contêm o contexto de segurança necessário para tomar ações imediatas. Os alertas de baixa fidelidade não contêm informações ou contêm ruído. |
| Falso positivo | Um alerta que indica um incidente que não aconteceu. |
| Incidente | Um evento que indica acesso não autorizado a um sistema. |
| Resposta ao incidente | Um processo que deteta, responde a e mitiga os riscos associados a um incidente. |
| Triagem | Uma operação de resposta a incidentes que analisa os problemas de segurança e dá prioridade à sua mitigação. |
Principais estratégias de design
O utilizador e a sua equipa executam operações de resposta a incidentes quando um sinal ou alerta indica um potencial incidente de segurança. Os alertas de alta fidelidade contêm um amplo contexto de segurança que facilita a tomada de decisões pelos analistas. Os alertas de alta fidelidade resultam num baixo número de falsos positivos. Este guia pressupõe que um sistema de alerta filtra sinais de baixa fidelidade e concentra-se em alertas de alta fidelidade que podem indicar um incidente real.
Atribuir a notificação do incidente
Os alertas de segurança têm de chegar às pessoas adequadas na sua equipa e na sua organização. Estabeleça um ponto de contacto designado na sua equipa de carga de trabalho para receber notificações de incidentes. Estas notificações devem incluir o máximo de informações possível sobre o recurso comprometido e o sistema. O alerta tem de incluir os passos seguintes, para que a sua equipa possa agir rapidamente.
Recomendamos que registe e gira notificações e ações de incidentes utilizando ferramentas especializadas que mantêm um registo de auditoria. Ao utilizar ferramentas padrão, pode preservar provas que possam ser necessárias para potenciais investigações legais. Procure oportunidades para implementar automatizações que possam enviar notificações com base nas responsabilidades dos responsáveis. Mantenha uma cadeia clara de comunicação e relatórios durante um incidente.
Tire partido das soluções de Gestão de Informações e Eventos de Segurança (SIEM) e das soluções de resposta automatizada de orquestração de segurança (SOAR) que a sua organização oferece. Como alternativa, pode adquirir ferramentas de gestão de incidentes e incentivar a sua organização a padronizá-las para todas as equipas de carga de trabalho.
Investigar com uma equipa de triagem
O membro da equipa que recebe uma notificação de incidente é responsável por configurar um processo de triagem que envolve as pessoas adequadas com base nos dados disponíveis. A equipa de triagem, muitas vezes denominada equipa de bridge, tem de concordar sobre o modo e o processo de comunicação. Este incidente requer chamadas de bridge ou discussões assíncronas? Como deve a equipa acompanhar e comunicar o curso das investigações? Onde é que a equipa pode aceder aos ativos do incidente?
A resposta a incidentes é uma razão crucial para manter a documentação atualizada, como o esquema arquitetónico do sistema, informações ao nível do componente, classificação de privacidade ou segurança, proprietários e principais pontos de contacto. Se as informações estiverem imprecisas ou desatualizadas, a equipa de bridge perde tempo valioso a tentar compreender como o sistema funciona, quem é responsável por cada área e qual pode ser o efeito do evento.
Para investigações adicionais, envolva as pessoas apropriadas. Pode incluir um gestor de incidentes, responsável pela segurança ou líderes centrados na carga de trabalho. Para manter a equipa de triagem focada, exclua as pessoas que estão fora do âmbito do problema. Às vezes, equipas separadas investigam o incidente. Pode haver uma equipa que inicialmente investiga o problema e tenta mitigar o incidente, e outra equipa especializada que pode realizar perícia para uma investigação profunda a fim de determinar problemas mais amplos. Pode colocar em quarentena o ambiente de carga de trabalho para permitir que a equipa forense faça as suas investigações. Em alguns casos, a mesma equipa poderá ser responsável por toda a investigação.
Na fase inicial, a equipa de triagem é responsável por determinar o vetor potencial e o seu efeito sobre a confidencialidade, integridade e disponibilidade (também denominada CIA) do sistema.
Dentro das categorias de CIA, atribua um nível de gravidade inicial que indique a profundidade do dano e a urgência da remediação. Espera-se que este nível mude ao longo do tempo, à medida que mais informações são descobertas nos níveis de triagem.
Na fase de descoberta, é importante determinar um curso imediato de ação e planos de comunicação. Existem alterações ao estado de funcionamento do sistema? Como conter o ataque para impedir uma maior exploração? A equipa precisa enviar de comunicação interna ou externa, como um documento de divulgação responsável? Considere o tempo de deteção e resposta. Poderá ser legalmente obrigado a comunicar alguns tipos de falhas a uma autoridade reguladora dentro de um período de tempo específico, que é frequentemente um período de horas ou dias.
Se decidir encerrar o sistema, os próximos passos levarão ao processo de recuperação após desastre (DR) da carga de trabalho.
Se não encerrar o sistema, determine como remediar o incidente sem afetar a funcionalidade do sistema.
Recuperar de um incidente
Trate um incidente de segurança como um desastre. Se a remediação exigir recuperação completa, utilize mecanismos de DR adequados numa perspetiva de segurança. O processo de recuperação deve evitar a possibilidade de reincidência. Caso contrário, a recuperação de um cópia de segurança corrompida reintroduz o problema. A reimplementação de um sistema com a mesma vulnerabilidade leva ao mesmo incidente. Valide os passos e processos de ativação pós-falha e reativação pós-falha.
Se o sistema permanecer em funcionamento, avalie o efeito nas partes em funcionamento do sistema. Continue a monitorizar o sistema para garantir que as outras metas de fiabilidade e desempenho são atingidos ou reajustados através da implementação de processos de degradação adequados. Não comprometa a privacidade devido à mitigação.
O diagnóstico é um processo interativo até que o vetor, e uma possível correção e ação de contingência, seja identificado. Após o diagnóstico, a equipa trabalha na remediação, que identifica e aplica a correção necessária dentro de um período aceitável.
As métricas de recuperação medem o tempo que demora a corrigir um problema. No caso de um encerramento, pode existir uma urgência em relação aos tempos de remediação. Para estabilizar o sistema, é necessário tempo para aplicar correções, patches e testes, e implementar atualizações. Determine estratégias de contenção para evitar mais danos e a propagação do incidente. Desenvolva procedimentos de erradicação para remover completamente a ameaça do ambiente.
Compensação: há uma compensação entre as metas de fiabilidade e os tempos de correção. Durante um incidente, é provável que não satisfaça outros requisitos não funcionais ou funcionais. Por exemplo, poderá ter de desativar partes do sistema enquanto investiga o incidente ou poderá mesmo ter de colocar todo o sistema offline até determinar o âmbito do incidente. Os decisores de negócios precisam de decidir explicitamente quais são as metas aceitáveis durante o incidente. Especifique claramente a pessoa responsável por esta decisão.
Aprender com um incidente
Um incidente revela lacunas ou pontos vulneráveis num design ou numa implementação. É uma oportunidade de melhoria que é impulsionada por lições em aspetos de design técnico, automatização, processos de desenvolvimento de produto que incluem testes e a eficácia do processo de resposta a incidentes. Mantenha registos detalhados dos incidentes, incluindo as ações tomadas, as linhas cronológicas e os resultados.
É vivamente recomendado que realize análises estruturadas pós-incidente, como a análise da causa raiz e retrospetivas. Acompanhe e priorize o resultado dessas análises e considere utilizar o que aprendeu em futuros designs de carga de trabalho.
Os planos de melhoria devem incluir atualizações para simulações e testes de segurança, como simulações de continuidade de negócios e recuperação após desastre (BCDR). Utilize o comprometimento de segurança como um cenário para executar uma simulação BCDR. As simulações podem validar a forma como os processos documentados funcionam. Não devem existir vários manuais de procedimentos de resposta a incidentes. Utilize uma única fonte que possa ajustar com base na dimensão do incidente e na extensão ou localização do efeito. As simulações baseiam-se em situações hipotéticas. Realize simulações num ambiente de baixo risco e inclua a fase de aprendizagem nas simulações.
Realize análises pós-incidente, ou post mortems, para identificar pontos fracos no processo de resposta e áreas de melhoria. Com base nas lições aprendidas com o incidente, atualize o plano de resposta a incidentes (IRP) e os controlos de segurança.
Enviar a comunicação necessária
Implemente um plano de comunicação para informar os utilizadores sobre uma interrupção e os intervenientes internos sobre a remedição e as melhorias. As outras pessoas na sua organização precisam de ser notificadas de quaisquer alterações na linha de base de segurança da carga de trabalho para impedir incidentes futuros.
Gere relatórios de incidentes para uso interno e, se necessário, para conformidade regulamentar ou fins legais. Além disso, adote um relatório de formato padrão (um modelo de documento com secções definidas) que a equipa SOC utiliza para todos os incidentes. Certifique-se de que cada incidente tem um relatório associado antes de fechar a investigação.
Facilitação do Power Platform
As secções seguintes descrevem os mecanismos que pode utilizar como parte dos seus procedimentos de resposta a incidentes de segurança.
Microsoft Sentinela
Microsoft A solução Sentinel for Microsoft Power Platform permite que os clientes detetem várias atividades suspeitas, incluindo:
- Execução do Power Apps a partir de localizações geográficas não autorizadas
- Destruição de dados suspeitos pelo Power Apps
- Eliminação em massa do Power Apps
- Ataques de phishing efetuados através do Power Apps
- Atividade de fluxos do Power Automate por colaboradores de saída
- Conectores do Microsoft Power Platform adicionados a um ambiente
- Atualização ou remoção de políticas de prevenção de perda de dados do Microsoft Power Platform
Para obter mais informações, consulte Microsoft Solução Sentinel para Microsoft Power Platform obter uma visão geral.
Microsoft Registro de atividades do Purview
Power Apps, Power Automate, Conectores, Prevenção de perda de dados e Power Platform registro de atividades administrativas são rastreados e visualizados no Microsoft portal de conformidade Purview.
Para mais informações, consulte:
- Power Apps registro de atividades
- Power Automate registro de atividades
- Copilot Studio registro de atividades
- Power Pages registro de atividades
- Power Platform registro de atividades do conector
- Registro de atividades de prevenção de perda de dados
- Power Platform registro de atividades de ações administrativas
- Microsoft Dataverse e registro de atividades de aplicativos orientados por modelo
Sistema de Proteção de Dados do Cliente
A maioria das operações, suporte e solução de problemas realizados pelo Microsoft pessoal (incluindo subprocessadores) não requer acesso aos dados do cliente. Com Power Platform o Customer Lockbox, Microsoft fornece uma interface para que os clientes analisem e aprovem (ou rejeitem) solicitações de acesso a dados nas raras ocasiões em que o acesso aos dados do cliente é necessário. Ele é usado nos casos em que um Microsoft engenheiro precisa acessar os dados do cliente, seja em resposta a um tíquete de suporte iniciado pelo cliente ou a um problema identificado por Microsoft. Para obter mais informações, consulte Aceder com segurança aos dados de clientes utilizando o Sistema de Proteção de Dados do Cliente no Power Platform e no Dynamics 365.
Atualizações de segurança
As equipas de Suporte efetuam regularmente o seguinte para assegurar a segurança do sistema:
- Análises do serviço para identificar possíveis vulnerabilidades de segurança.
- Avaliações do serviço para assegurar que os controlos de segurança principais estão a funcionar eficazmente.
- Avaliações do serviço para determinar a exposição a quaisquer vulnerabilidades identificadas pelo Microsoft Security resposta Center (MSRC), que monitoriza regularmente sites externos de sensibilização para vulnerabilidades.
Estas equipas também identificam e monitorizam quaisquer problemas identificados e agem atempadamente para mitigar riscos quando necessário.
Como posso obter informações sobre atualizações de segurança?
Visto as equipas de Suporte se esforçarem para aplicar mitigações de riscos de uma forma que não exija períodos de indisponibilidade de serviço, os administradores normalmente não veem as notificações do Centro de Mensagens sobre atualizações de segurança. Se uma atualização de segurança necessitar do impacto do serviço, será considerada manutenção planeada e será publicada com a previsão da duração do impacto e a janela em que o trabalho ocorrerá.
Para obter mais informações sobre segurança, consulte Microsoft Central de Confiabilidade.
Gerir a sua janela de manutenção
Microsoft realiza regularmente atualizações e manutenções para garantir segurança, desempenho, disponibilidade e fornecer novos recursos e funcionalidades. Este processo de atualização proporciona segurança e pequenos melhoramentos de serviço semanalmente. Cada atualização é disponibilizada região a região de acordo com um calendário de implementação seguro, organizado em Estações. Para obter informações sobre a sua janela de manutenção predefinida para ambientes, consulte Políticas e Comunicações para incidentes de serviço. Consulte também Gerir a sua janela de manutenção.
Certifique-se de que o portal de inscrição do Azure inclui as informações de contacto do administrador para que as operações de segurança possam ser notificadas diretamente através de um processo interno. Para obter mais informações, consulte Atualizar definições de notificação
Alinhamento organizacional
O Cloud Adoption Framework para Azure fornece orientação sobre o planeamento de resposta a incidentes e operações de segurança. Para obter mais informações, consulte Operações de segurança.
Informações relacionadas
- Microsoft Solução Sentinel para Microsoft Power Platform visão geral
- Crie incidentes automaticamente a partir de alertas de Microsoft segurança
- Conduza a caça de ameaças de ponta a ponta usando o recurso Caçadas
- Use o Hunts para conduzir a caça proativa de ameaças de ponta a ponta no Microsoft Sentinel
- Visão geral do resposta de incidentes
Lista de verificação de segurança
Consulte o conjunto completo de recomendações.