Fazer referência a consultas do Power Query
Este artigo destina-se a você como um modelador de dados que trabalha com o Power BI Desktop. Ele fornece orientação ao definir consultas do Power Query que fazem referência a outras consultas.
Vamos ser claros sobre o que isso significa: quando uma consulta faz referência a uma segunda consulta, é como se as etapas da segunda consulta fossem combinadas e executadas antes das etapas da primeira consulta.
Considere várias consultas: Query1 origina dados de um serviço Web e sua carga está desabilitada. Query2, Query3 e Query4 fazem referência a Query1 e suas saídas são carregadas no modelo de dados.
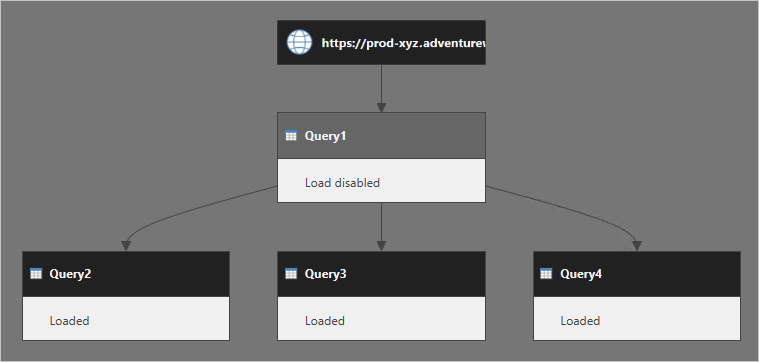
Quando o modelo de dados é atualizado, geralmente presume-se que o Power Query recupera o resultado do Query1 e que ele é reutilizado por consultas referenciadas. Este raciocínio é incorreto. Na verdade, o Power Query executa Query2, Query3 e Query4 separadamente.
Você pode pensar que o Query2 tem as etapas do Query1 incorporadas nele. É o caso do Query3 e do Query4 também. O diagrama a seguir apresenta uma imagem mais clara de como as consultas são executadas.
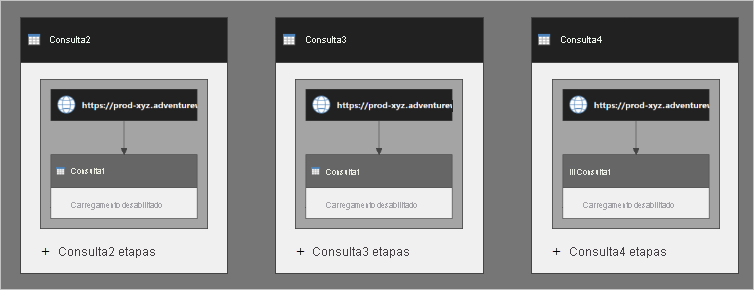
Query1 é executado três vezes. As várias execuções podem resultar em lenta atualização de dados e afetar negativamente a fonte de dados.
O uso da função Table.Buffer em Query1 não eliminará a recuperação de dados adicionais. Essa função armazena uma tabela em buffer na memória e a tabela em buffer só pode ser usada na mesma execução de consulta. Portanto, no exemplo, se Query1 é armazenado em buffer quando Query2 é executado, os dados armazenados em buffer não podem ser usados quando Query3 e Query4 são executados. Eles próprios armazenarão os dados em buffer mais duas vezes. (Esse resultado pode, de fato, compor o desempenho negativo, porque a tabela será armazenada em buffer por cada consulta de referência.)
Nota
A arquitetura de cache do Power Query é complexa e não é o foco deste artigo. O Power Query pode armazenar em cache dados recuperados de uma fonte de dados. No entanto, quando ele executa uma consulta, ele pode recuperar os dados da fonte de dados mais de uma vez.
Recomendações
Geralmente, recomendamos que você faça referência a consultas para evitar a duplicação de lógica em suas consultas. No entanto, conforme descrito neste artigo, essa abordagem de design pode contribuir para atualizações de dados lentas e fontes de dados sobrecarregadas.
Em vez disso, recomendamos que você crie um fluxo de dados. O uso de um fluxo de dados pode melhorar o tempo de atualização de dados e reduzir o impacto em suas fontes de dados.
Você pode projetar o fluxo de dados para encapsular os dados de origem e as transformações. Como o fluxo de dados é um armazenamento persistente de dados no serviço do Power BI, sua recuperação de dados é rápida. Assim, mesmo quando as consultas de referência resultam em várias solicitações para o fluxo de dados, os tempos de atualização de dados podem ser melhorados.
No exemplo, se Query1 for redesenhado como uma entidade de fluxo de dados, Query2, Query3 e Query4 poderão usá-lo como uma fonte de dados. Com esse design, a entidade originada pela Query1 será avaliada apenas uma vez.
Conteúdos relacionados
Para obter mais informações relacionadas a este artigo, confira os seguintes recursos: