Stream mensagens de bot
Observação
A mensagem do bot de transmissão em fluxo está disponível:
- apenas para conversas um-para-um.
- está geralmente disponível apenas no cliente web e de ambiente de trabalho.
- está disponível na pré-visualização de programadores públicos no Android e iOS.
A mensagem do bot de transmissão em fluxo não está disponível com a chamada de funções e o modelo OpenAI o1 .
Pode transmitir mensagens de bot para fornecer as respostas de um bot ao utilizador como pequenas atualizações enquanto a resposta completa está a ser gerada para melhorar a experiência do utilizador. Muitas vezes, os bots demoram muito tempo a gerar respostas sem atualizar a interface de utilizador, o que leva a uma experiência menos envolvente.
Quando os utilizadores observam o bot a processar o pedido em tempo real, este pode aumentar a sua satisfação e confiança. Esta perceção de capacidade de resposta e transparência melhora o envolvimento do utilizador e diminui o abandono de conversações com o bot.
Stream experiência de utilizador de mensagens
As mensagens do bot de transmissão em fluxo têm dois tipos de atualizações:
Atualizações informativas: as atualizações informativas aparecem como uma barra de progresso azul na parte inferior do chat. Informa o utilizador sobre as ações em curso do bot enquanto está a ser gerada uma resposta.

Transmissão em fluxo de resposta: a transmissão em fluxo de resposta é apresentada como um indicador de escrita. Revela a resposta do bot ao utilizador como pequenas atualizações enquanto a resposta completa está a ser gerada.

O ![]() botão permite que os utilizadores controlem as respostas de transmissão em fluxo ao pará-las mais cedo. Está disponível por predefinição durante a transmissão em fluxo, permitindo que os utilizadores refinem pedidos ou enviem novos pedidos. Compreender como funciona o botão parar a transmissão em fluxo pode ajudar a conceber interfaces de conversação mais eficazes e fáceis de utilizar.
botão permite que os utilizadores controlem as respostas de transmissão em fluxo ao pará-las mais cedo. Está disponível por predefinição durante a transmissão em fluxo, permitindo que os utilizadores refinem pedidos ou enviem novos pedidos. Compreender como funciona o botão parar a transmissão em fluxo pode ajudar a conceber interfaces de conversação mais eficazes e fáceis de utilizar.
Pode implementar mensagens de bot de transmissão em fluxo na sua aplicação de uma das seguintes formas:
Além disso, também aprenderá a parar a resposta e os códigos de resposta do bot de transmissão em fluxo para mensagens de bot de transmissão em fluxo.
Stream mensagem através da biblioteca de IA do Teams
A biblioteca de IA do Teams fornece a capacidade de transmitir mensagens em fluxo para bots com tecnologia de IA. A transmissão em fluxo de mensagens de bot ajuda a aliviar o atraso no tempo de resposta enquanto o Modelo de Linguagem Grande (LLM) gera a resposta completa. Os principais fatores que contribuem para o tempo de resposta lento incluem vários passos de pré-processamento, como Retrieval-Augmented Geração (RAG) ou chamadas de função, e o tempo necessário para o LLM gerar uma resposta completa.
Observação
As mensagens de bot de transmissão em fluxo não estão disponíveis com chamadas de funções.
Através da transmissão em fluxo, o bot com tecnologia de IA pode oferecer uma experiência apelativa e reativa para o utilizador. Configure as seguintes funcionalidades para transmitir mensagens para a sua aplicação com tecnologia de IA:
Ativar a transmissão em fluxo para o bot com tecnologia de IA:
As mensagens do bot podem ser transmitidas através do SDK de IA. O bot baseado em IA envia segmentos ao utilizador à medida que o modelo gera a resposta. As mensagens de transmissão em fluxo suportam texto. No entanto, os anexos, a etiqueta de IA, o ciclo de comentários e as etiquetas de confidencialidade só estão disponíveis para a mensagem de transmissão em fluxo final.
Definir mensagem informativa:
Pode definir uma mensagem informativa para o bot baseado em IA. Esta mensagem é apresentada ao utilizador sempre que o bot envia uma atualização. Eis alguns exemplos de mensagens informativas que pode definir na sua aplicação:
- Analisar documentos
- A resumir conteúdo
- Localizar itens de trabalho relevantes
O exemplo seguinte mostra as atualizações de informações num bot com tecnologia de IA:
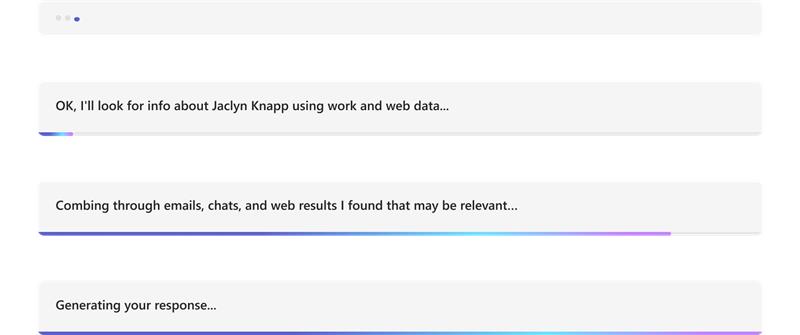
Formate a mensagem em fluxo final:
Ao utilizar o SDK de IA, as mensagens de texto e o markdown simples podem ser formatados enquanto são transmitidos em fluxo. No entanto, para Cartões Ajustáveis, imagens ou HTML avançado, a formatação pode ser aplicada assim que a mensagem final estiver concluída. O bot só pode enviar anexos no segmento transmitido em fluxo final.
O exemplo seguinte mostra a resposta de transmissão em fluxo num bot com tecnologia de IA:

O exemplo seguinte mostra o bot com tecnologia de IA a formatar a resposta transmitida em fluxo:

O exemplo seguinte mostra a resposta em fluxo final num bot com tecnologia de IA após a formatação estar concluída:

Ativar funcionalidades com tecnologia de IA para a mensagem final:
Pode ativar as seguintes funcionalidades com tecnologia de IA para a mensagem final enviada pelo bot:
- Citações: a biblioteca de IA do Teams inclui automaticamente citações nas respostas do bot. Fornece referências para as origens que o bot utilizou para gerar a resposta. Permite que os utilizadores referenciem a fonte através de citações e referências em texto.
- Etiqueta de Confidencialidade: utilize a etiqueta de confidencialidade para ajudar os utilizadores a compreender a confidencialidade de uma mensagem.
- Ciclo de comentários: isto permite que os utilizadores forneçam comentários positivos ou negativos sobre as mensagens do bot.
- Gerado pela IA: a biblioteca de IA do Teams inclui automaticamente uma etiqueta Gerado por IA nas respostas do bot. Esta etiqueta ajuda os utilizadores a identificar que uma mensagem foi gerada com IA.
Para obter mais informações sobre a formatação de mensagens de bot com tecnologia de IA, veja mensagens de bot com conteúdo gerado por IA.
Configurar mensagens de bot de transmissão em fluxo
Siga estes passos para configurar mensagens de bot de transmissão em fluxo:
Ativar a transmissão em fluxo para o bot com tecnologia de IA:
a. Utilize a
DefaultAugmentationclasse noconfig.jsonficheiro e, numa das seguintes main classes de aplicação da sua aplicação bot:- Para uma aplicação de bot C#: Atualizar
Program.cs. - Para uma aplicação JavaScript: Atualizar
index.ts. - Para uma aplicação Python: Atualizar
bot.py.
b. Defina
streamcomo verdadeiro naOpenAIModeldeclaração.- Para uma aplicação de bot C#: Atualizar
Definir mensagem informativa: especifique a mensagem informativa na
ActionPlannerdeclaração com aStartStreamingMessageconfiguração.Formate a mensagem em fluxo final:
- Defina o botão de alternar do ciclo de comentários no
AIOptionsobjeto na declaração da aplicação e especifique um processador.- Para uma aplicação de bot criada com Python, defina o botão de alternar do ciclo de comentários no
ActionPlannerOptionsobjeto, além doAIOptionsobjeto.
- Para uma aplicação de bot criada com Python, defina o botão de alternar do ciclo de comentários no
- Defina anexos no segmento final com a
EndStreamHandlernaActionPlannerdeclaração .
- Defina o botão de alternar do ciclo de comentários no
O fragmento de código seguinte mostra um exemplo de mensagens de bot de transmissão em fluxo:
// Create OpenAI Model
builder.Services.AddSingleton<OpenAIModel > (sp => new(
new OpenAIModelOptions(config.OpenAI.ApiKey, "gpt-4o")
{
LogRequests = true,
Stream = true, // Set stream toggle
},
sp.GetService<ILoggerFactory>()
));
ResponseReceivedHandler endStreamHandler = new((object sender, ResponseReceivedEventArgs args) =>
{
StreamingResponse? streamer = args.Streamer;
if (streamer == null)
{
return;
}
AdaptiveCard adaptiveCard = new("1.6")
{
Body = [new AdaptiveTextBlock(streamer.Message) { Wrap = true }]
};
var adaptiveCardAttachment = new Attachment()
{
ContentType = "application/vnd.microsoft.card.adaptive",
Content = adaptiveCard,
};
streamer.Attachments = [adaptiveCardAttachment]; // Set attachments
});
// Create ActionPlanner
ActionPlanner<TurnState> planner = new(
options: new(
model: sp.GetService<OpenAIModel>()!,
prompts: prompts,
defaultPrompt: async (context, state, planner) =>
{
PromptTemplate template = prompts.GetPrompt("Chat");
return await Task.FromResult(template);
}
)
{
LogRepairs = true,
StartStreamingMessage = "Loading stream results...", // Set informative message
EndStreamHandler = endStreamHandler // Set final chunk handler
},
loggerFactory: loggerFactory
);
Desenvolvimento de Modelos e Planner Personalizados
A StreamingResponse classe é a classe auxiliar para respostas de transmissão em fluxo para o cliente. Permite-lhe enviar uma série de atualizações numa única resposta, tornando a interação mais suave. Se estiver a utilizar o seu próprio modelo personalizado, pode utilizar facilmente esta classe para transmitir respostas de forma totalmente integrada. É uma excelente forma de manter o utilizador envolvido.
As mensagens do bot de transmissão em fluxo têm de utilizar a seguinte sequência:
queueInformativeUpdate()queueTextChunk()endStream()
Depois de o modelo chamar endStream(), o fluxo termina e o bot não pode enviar mais atualizações.
Eis uma lista de outros métodos que pode utilizar para personalizar a experiência da aplicação:
setAttachmentssetSensitivityLabelsetFeedbackLoopsetGeneratedByAILabel
Limitações do Azure OpenAI ou OpenAI
- Quando o bot chama a API de transmissão em fluxo demasiado rápido, pode causar problemas e interromper a experiência de transmissão em fluxo. Para evitar esta situação, transmita uma mensagem de cada vez a um ritmo consistente. Se não o fizer, o pedido poderá ser limitado. Intermédia os tokens do modelo durante 1,5 a 2 segundos para garantir uma transmissão em fluxo suave.
- As funcionalidades com tecnologia de IA, como citações, etiquetas de confidencialidade, ciclo de feedback e Geradas pela etiqueta de IA são suportadas apenas no segmento final. As citações são definidas por cada segmento de texto em fila de espera.
- Só é possível transmitir em fluxo texto formatado.
- Só pode definir uma mensagem informativa. O bot reutiliza esta mensagem para cada atualização. Os exemplos incluem:
- Analisar documentos
- A resumir conteúdo
- Localizar itens de trabalho relevantes
- O modelo compõe a mensagem informativa apenas no início de cada mensagem devolvida a partir do LLM.
- Os anexos só podem ser enviados no segmento final.
- A transmissão em fluxo ainda não está disponível com as chamadas de função do SDK de IA e o modelo da AOAI ou da
o1OAI. - Eis os requisitos a utilizar
streamSequencepara o SDK de IA:- A sequência tem de começar com o número "1".
- Os números subsequentes (exceto final) têm de ser um número inteiro de aumento monotónico (por exemplo, 1-2-3>>).
- Para a mensagem final,
streamSequencenão deve ser definido.
Stream mensagem através da API REST
As mensagens do bot podem ser transmitidas através da API REST. As mensagens de transmissão em fluxo suportam texto formatado e citação. Anexo, etiqueta de IA, botão de feedback e etiquetas de confidencialidade estão disponíveis apenas para a mensagem de transmissão em fluxo final. Para obter mais informações, veja anexos e mensagens de bot com conteúdo gerado pela IA.
Quando o bot invocar a transmissão em fluxo através da API REST, certifique-se de que chama a API de transmissão em fluxo seguinte apenas depois de receber uma resposta com êxito da chamada inicial à API. Se o bot utilizar o SDK, verifique se recebe um objeto de resposta nulo do método de atividade de envio para confirmar que a chamada anterior foi transmitida com êxito.
Quando o bot chama a API de transmissão em fluxo demasiado rápido, pode deparar-se com problemas e a experiência de transmissão em fluxo pode ser interrompida. Recomendamos que o bot transmita uma mensagem de cada vez para garantir que chama a API de transmissão em fluxo a um ritmo consistente. Caso contrário, o pedido poderá ser limitado. Intermédia os tokens do modelo durante 1,5 a dois segundos para garantir um processo de transmissão em fluxo suave.
Seguem-se as propriedades das mensagens do bot de transmissão em fluxo:
| Propriedade | Obrigatório | Descrição |
|---|---|---|
type |
✔️ | Os valores suportados são typing ou message.
• typing: utilize ao transmitir a mensagem em fluxo.
• message: Utilize para a mensagem transmitida em fluxo final. |
text |
✔️ | O conteúdo da mensagem que vai ser transmitida em fluxo. |
entities.type |
✔️ | Deve ser streamInfo |
entities.streamId |
✔️ |
streamId no pedido de transmissão em fluxo inicial, inicie a transmissão em fluxo. |
entities.streamType |
Tipo de atualizações de transmissão em fluxo. Os valores suportados são informative, streamingou final. O valor padrão é streaming.
final é utilizado apenas na mensagem final. |
|
entities.streamSequence |
✔️ | Número inteiro incremental para cada pedido. |
Observação
Eis os requisitos para utilizar streamSequence as APIs REST:
- O primeiro tem de ser o número "1".
- Os números subsequentes (exceto final) têm de ser um número inteiro de aumento monotónico (por exemplo, 1-2-3>>).
- Para a mensagem final,
streamSequencenão pode ser definido.
Para ativar a transmissão em fluxo em bots, siga estes passos:
Iniciar transmissão em fluxo
O bot pode enviar uma mensagem informativa ou de transmissão em fluxo como a comunicação inicial. A resposta inclui o streamId, que é importante para executar chamadas subsequentes.
O bot pode enviar várias atualizações informativas ao processar o pedido do utilizador, como Analisar através de documentos, Resumir Conteúdo e Localizar itens de trabalho relevantes. Pode enviar estas atualizações antes de o bot gerar a resposta final ao utilizador.
//Ex: A bot sends the first request with content & the content is informative loading message.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "typing",
"serviceurl": "https://smba.trafficmanager.net/amer/",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id": "<conversationId>"
},
"recipient": {
"id": "<recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en-US",
"text": "Searching through documents...", //(required) first informative loading message.
"entities":[
{
"type": "streaminfo",
"streamType": "informative", // informative or streaming; default= streaming.
"streamSequence": 1 // (required) incremental integer; must be present for start and continue streaming request, but must not be set for final streaming request.
}
],
}
201 created { "id": "a-0000l" } // return stream id
A imagem seguinte é um exemplo de início da transmissão em fluxo:

Continuar a transmissão em fluxo
Utilize o streamId que recebeu do pedido inicial para enviar mensagens informativas ou de transmissão em fluxo. Pode começar com atualizações informativas e, mais tarde, mudar para a transmissão em fluxo de resposta quando a resposta final estiver pronta.
Começar com atualizações informativas
À medida que o bot gera uma resposta, envie atualizações informativas ao utilizador, como Analisar documentos, Resumir Conteúdo e Localizar itens de trabalho relevantes. Certifique-se de que efetua chamadas subsequentes apenas depois de o bot receber uma resposta bem-sucedida das chamadas anteriores.
// Ex: A bot sends the second request with content & the content is informative loading message.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "typing",
" serviceurl": "https://smba.trafficmanager.net/amer/",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id" : "<conversationId>"
},
"recipient": {
"id": "<recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en -US",
"text ": "Searching through emails...", // (required) second informative loading message.
"entities":[
{
"type": "streaminfo",
"streamId": "a-0000l", // // (required) must be present for any subsequent request after the first chunk.
"streamType": "informative", // informative or streaming; default= streaming.
"streamSequence": 2 // (required) incremental integer; must be present for start and continue streaming request, but must not be set for final streaming request.
}
],
}
202 0K { }
A imagem seguinte é um exemplo de um bot que fornece atualizações informativas:

Mudar para a transmissão em fluxo de resposta
Depois de o bot estar pronto para gerar a mensagem final para o utilizador, mude de fornecer atualizações informativas para a transmissão em fluxo de resposta. Para cada atualização de transmissão em fluxo de resposta, o conteúdo da mensagem deve ser a versão mais recente da mensagem final. Isto significa que o bot deve incorporar quaisquer novos tokens gerados pelos Modelos de Linguagem Grande (LLMs). Acrescente estes tokens à versão da mensagem anterior e, em seguida, envie-os ao utilizador.
O limite de limitação é de 1 pedido por segundo. Tem de garantir que o bot envia o pedido dentro deste limite. O bot pode enviar pedidos a um ritmo mais lento, conforme necessário.
// Ex: A bot sends the third request with content & the content is actual streaming content.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "typing",
" serviceurl" : "https://smba.trafficmanager.net/amer/ ",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id" : "<conversationId>"
},
"recipient": {
"id" : "<recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en-US" ,
"text ": "A brown fox", // (required) first streaming content.
"entities":[
{
"type": "streaminfo",
"streamId": "a-0000l", // // (required) must be present for any subsequent request after the first chunk.
"streamType": "streaming", // informative or streaming; default= streaming.
"streamSequence": 3 // (required) incremental integer; must be present for start and continue streaming request, but must not be set for final streaming request.
}
],
}
202 0K{ }
// Ex: A bot sends the fourth request with content & the content is actual streaming content.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "typing",
" serviceurl" : "https://smba.trafficmanager.net/amer/ ",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id" : "<conversationId>"
},
"recipient": {
"id" : "<recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en-US" ,
"text ": "A brown fox jumped over the fence", // (required) first streaming content.
"entities":[
{
"type": "streaminfo",
"streamId": "a-0000l", // // (required) must be present for any subsequent request after the first chunk.
"streamType": "streaming", // informative or streaming; default= streaming.
"streamSequence": 4 // (required) incremental integer; must be present for start and continue streaming request, but must not be set for final streaming request.
}
],
}
202 0K{ }
A imagem seguinte é um exemplo de um bot que fornece atualizações em segmentos:

Transmissão em Fluxo Final
Depois de o bot concluir a geração da mensagem, envie o sinal de transmissão em fluxo final juntamente com a mensagem final. Para a mensagem final, a type atividade é message. Aqui, o bot define todos os campos permitidos para a atividade de mensagens regulares, mas final é o único valor permitido para streamType.
// Ex: A bot sends the second request with content && the content is informative loading message.
POST /conversations/<conversationId>/activities HTTP/1.1
{
"type": "message",
" serviceurl" : "https://smba.trafficmanager.net/amer/ ",
"channelId": "msteams",
"from": {
"id": "<botId>",
"name": "<BotName>"
},
"conversation": {
"conversationType": "personal",
"id" : "<conversationId>"
},
"recipient": {
"id" : "recipientId>",
"name": "<recipientName>",
"aadObjectId": "<recipient aad objecID>"
},
"locale": "en-US",
"text ": "A brown fox jumped over the fence.", // (required) first streaming content.
"entities":[
{
"type": "streaminfo",
"streamId": "a-0000l", // // (required) must be present for any subsequent request after the first chunk.
"streamType": "final", // (required) final is only allowed for the last message of the streaming.
}
],
}
202 0K{ }
A imagem seguinte é um exemplo da resposta final do bot:

Parar a resposta do bot de transmissão em fluxo
O ![]() botão permite que os utilizadores controlem as respostas de transmissão em fluxo. O botão Parar está disponível por predefinição durante a transmissão em fluxo, permitindo que os utilizadores parem uma resposta mais cedo. Os utilizadores podem interromper a transmissão em fluxo de mensagens e refinar os pedidos ou enviar novos. Melhora a gestão de conversações com bots para uma melhor experiência de utilizador.
botão permite que os utilizadores controlem as respostas de transmissão em fluxo. O botão Parar está disponível por predefinição durante a transmissão em fluxo, permitindo que os utilizadores parem uma resposta mais cedo. Os utilizadores podem interromper a transmissão em fluxo de mensagens e refinar os pedidos ou enviar novos. Melhora a gestão de conversações com bots para uma melhor experiência de utilizador.
Depois de um utilizador parar a geração de mensagens:
Os bots tratam as respostas paradas como incompletas ou rejeitadas na conversação.
Os bots não podem alterar o conteúdo já transmitido em fluxo.
O seguinte erro é gerado se um bot continuar a transmitir em fluxo numa mensagem que é parada por um utilizador:
Detalhe do erro Descrição Código http status 403 Código de erro ContentStreamNotAllowedMensagem de erro O fluxo de conteúdos foi cancelado pelo utilizador. Descrição A transmissão em fluxo foi interrompida pelo utilizador.
Códigos de resposta
Seguem-se os códigos de êxito e de erro:
Códigos de êxito
| Código http status | Valor de retorno | Descrição |
|---|---|---|
201 |
streamId, é o mesmo que activityId , por exemplo, {"id":"1728640934763"} |
O bot devolve este valor depois de enviar o pedido de transmissão em fluxo inicial.
Para quaisquer pedidos de transmissão em fluxo subsequentes, o streamId é necessário. |
202 |
{} |
Código de êxito para quaisquer pedidos de transmissão em fluxo subsequentes. |
Códigos de erro
| Código http status | Código de erro | Mensagem de erro | Descrição |
|---|---|---|---|
202 |
ContentStreamSequenceOrderPreConditionFailed |
PreCondition failed exception when processing streaming activity. |
Poucos pedidos de transmissão em fluxo podem chegar fora de sequência e ser removidos. O pedido de transmissão em fluxo mais recente, determinado por streamSequence, é utilizado quando os pedidos são recebidos de forma desordenada. Certifique-se de que envia cada pedido de forma sequencial. |
400 |
BadRequest |
Consoante o cenário, poderá encontrar várias mensagens de erro, como Start streaming activities should include text |
O payload recebido não cumpre nem contém os valores necessários. |
403 |
ContentStreamNotAllowed |
Content stream is not allowed |
A funcionalidade de API de transmissão em fluxo não é permitida para o utilizador ou bot. |
403 |
ContentStreamNotAllowed |
Content stream is not allowed on an already completed streamed message |
Um bot não pode transmitir continuamente em fluxo numa mensagem que já tenha sido transmitida e concluída. |
403 |
ContentStreamNotAllowed |
Content stream finished due to exceeded streaming time. |
O bot não conseguiu concluir o processo de transmissão em fluxo dentro do limite de tempo rigoroso de dois minutos. |
403 |
ContentStreamNotAllowed |
Message size too large |
O bot enviou uma mensagem que excede a restrição de tamanho da mensagem atual. |
| '403' | ContentStreamNotAllowed |
O fluxo de conteúdos foi cancelado pelo utilizador. | A transmissão em fluxo foi interrompida pelo utilizador. |
429 |
NA | API calls quota exceeded |
O número de mensagens transmitidas pelo bot excedeu a quota. |
Exemplo de código
| Nome do exemplo | Descrição | Node.js | C# | Python |
|---|---|---|---|---|
| Exemplo de bot de transmissão em fluxo do Teams | Este exemplo de código demonstra como criar um bot ligado a um LLM e enviar mensagens através do Teams. | NA | View | NA |
| Bot de transmissão em fluxo de conversação | Este é um bot de transmissão em fluxo de conversação com a biblioteca de IA do Teams. | View | View | Exibir |