dbscan_fl()
A função dbscan_fl() é uma UDF (função definida pelo usuário) que agrupa um conjunto de dados usando o algoritmo DBSCAN.
Pré-requisitos
- O plug-in Python deve ser habilitado no cluster. Isso é necessário para o Python embutido usado na função.
- O plug-in Python deve estar habilitado no banco de dados. Isso é necessário para o Python embutido usado na função.
Sintaxe
T | invoke dbscan_fl(Características, cluster_col metric_params, métrica, min_samples ,Epsilon, )
Saiba mais sobre as convenções de sintaxe.
Parâmetros
| Nome | Digitar | Obrigatória | Descrição |
|---|---|---|---|
| features | dynamic |
✔️ | Uma matriz que contém os nomes das colunas de recursos a serem usadas para clustering. |
| cluster_col | string |
✔️ | O nome da coluna para armazenar a ID do cluster de saída para cada registro. |
| epsilon | real |
✔️ | A distância máxima entre duas amostras a serem consideradas como vizinhas. |
| min_samples | int |
O número de amostras em uma vizinhança para que um ponto seja considerado como um ponto central. | |
| métrica | string |
A métrica a ser usada ao calcular a distância entre pontos. | |
| metric_params | dynamic |
Argumentos de palavra-chave extras para a função métrica. |
- Para obter uma descrição detalhada dos parâmetros, consulte a documentação do DBSCAN
- Para obter a lista de métricas, consulte cálculos de distância
Definição de função
Você pode definir a função inserindo seu código como uma função definida por consulta ou criando-a como uma função armazenada em seu banco de dados, da seguinte maneira:
Defina a função usando a instrução let a seguir. Nenhuma permissão é necessária.
Importante
Uma instrução let não pode ser executada sozinha. Ele deve ser seguido por uma instrução de expressão tabular. Para executar um exemplo funcional de kmeans_fl(), consulte o exemplo.
let dbscan_fl=(tbl:(*), features:dynamic, cluster_col:string, epsilon:double, min_samples:int=10,
metric:string='minkowski', metric_params:dynamic=dynamic({'p': 2}))
{
let kwargs = bag_pack('features', features, 'cluster_col', cluster_col, 'epsilon', epsilon, 'min_samples', min_samples,
'metric', metric, 'metric_params', metric_params);
let code = ```if 1:
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
features = kargs["features"]
cluster_col = kargs["cluster_col"]
epsilon = kargs["epsilon"]
min_samples = kargs["min_samples"]
metric = kargs["metric"]
metric_params = kargs["metric_params"]
df1 = df[features]
mat = df1.values
# Scale the dataframe
scaler = StandardScaler()
mat = scaler.fit_transform(mat)
# see https://docs.scipy.org/doc/scipy/reference/spatial.distance.html for the various distance metrics
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples, metric=metric, metric_params=metric_params) # 'minkowski', 'chebyshev'
labels = dbscan.fit_predict(mat)
result = df
result[cluster_col] = labels
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
// Write your query to use the function here.
Exemplo
O exemplo a seguir usa o operador invoke para executar a função.
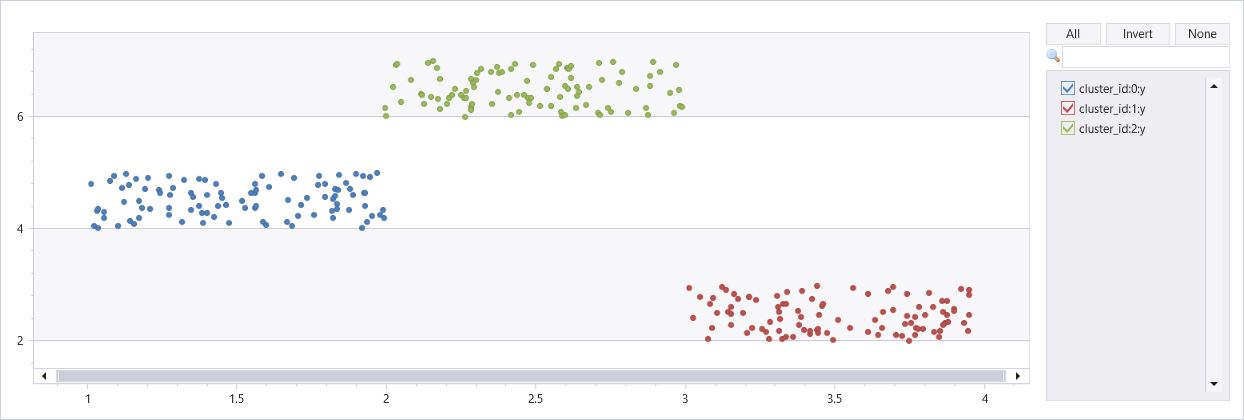
Agrupamento de conjuntos de dados artificiais com três clusters
Para usar uma função definida por consulta, invoque-a após a definição da função inserida.
let dbscan_fl=(tbl:(*), features:dynamic, cluster_col:string, epsilon:double, min_samples:int=10,
metric:string='minkowski', metric_params:dynamic=dynamic({'p': 2}))
{
let kwargs = bag_pack('features', features, 'cluster_col', cluster_col, 'epsilon', epsilon, 'min_samples', min_samples,
'metric', metric, 'metric_params', metric_params);
let code = ```if 1:
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
features = kargs["features"]
cluster_col = kargs["cluster_col"]
epsilon = kargs["epsilon"]
min_samples = kargs["min_samples"]
metric = kargs["metric"]
metric_params = kargs["metric_params"]
df1 = df[features]
mat = df1.values
# Scale the dataframe
scaler = StandardScaler()
mat = scaler.fit_transform(mat)
# see https://docs.scipy.org/doc/scipy/reference/spatial.distance.html for the various distance metrics
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples, metric=metric, metric_params=metric_params) # 'minkowski', 'chebyshev'
labels = dbscan.fit_predict(mat)
result = df
result[cluster_col] = labels
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
union
(range x from 1 to 100 step 1 | extend x=rand()+3, y=rand()+2),
(range x from 101 to 200 step 1 | extend x=rand()+1, y=rand()+4),
(range x from 201 to 300 step 1 | extend x=rand()+2, y=rand()+6)
| extend cluster_id=int(null)
| invoke dbscan_fl(pack_array("x", "y"), "cluster_id", epsilon=0.6, min_samples=4, metric_params=dynamic({'p':2}))
| render scatterchart with(series=cluster_id)