Tutorial: Usar um notebook com o Apache Spark para consultar um banco de dados KQL
Os blocos de notas são documentos legíveis que contêm descrições e resultados da análise de dados e documentos executáveis que podem ser executados para executar a análise de dados. Neste artigo, você aprenderá a usar um bloco de anotações do Microsoft Fabric para ler e gravar dados em um banco de dados KQL usando o Apache Spark. Este tutorial usa conjuntos de dados e blocos de anotações pré-criados nos ambientes de Inteligência em Tempo Real e Engenharia de Dados no Microsoft Fabric. Para obter mais informações sobre blocos de anotações, consulte Como usar blocos de anotações do Microsoft Fabric.
Especificamente, você aprende a:
- Criar um banco de dados KQL
- Importar um bloco de notas
- Gravar dados em um banco de dados KQL usando o Apache Spark
- Consultar dados de um banco de dados KQL
Pré-requisitos
- Um espaço de trabalho com uma capacidade habilitada para Microsoft Fabric
1- Crie um banco de dados KQL
Selecione seu espaço de trabalho na barra de navegação esquerda.
Siga uma destas etapas para começar a criar um fluxo de eventos:
- Selecione Novo item e depois Eventhouse. No campo nome Eventhouse, digite nycGreenTaxie, em seguida, selecione Criar. Um banco de dados KQL é gerado com o mesmo nome.
- Em uma casa de eventos existente, selecione Bancos de dados. Em bancos de dados KQL, selecione +; no campo nome do banco de dados KQL, digite nycGreenTaxie, em seguida, selecione Criar.
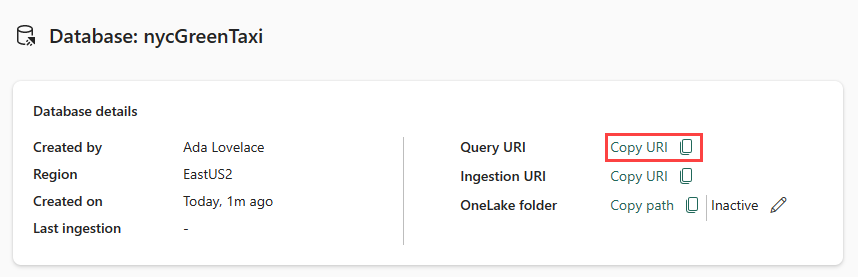
Copie o URI de consulta do cartão de detalhes do banco de dados no painel do banco de dados e cole-o em algum lugar, como um bloco de notas, para usar em uma etapa posterior.
2- Faça o download do notebook NYC GreenTaxi
Criamos um bloco de anotações de exemplo que leva você por todas as etapas necessárias para carregar dados em seu banco de dados usando o conector Spark.
Abra o repositório de amostras de malha no GitHub para baixar o notebook NYC GreenTaxi KQL.
Guarde o bloco de notas localmente no seu dispositivo.
Nota
O bloco de notas tem de ser guardado
.ipynbno formato de ficheiro.

3- Importe o notebook
O restante desse fluxo de trabalho ocorre na seção Engenharia de Dados do produto e usa um bloco de anotações do Spark para carregar e consultar dados em seu banco de dados KQL.
No seu espaço de trabalho, selecione Importar>Bloco de Anotações>Neste computador>Carregar em seguida, escolha o bloco de anotações do NYC GreenTaxi que o utilizador descarregou numa etapa anterior.
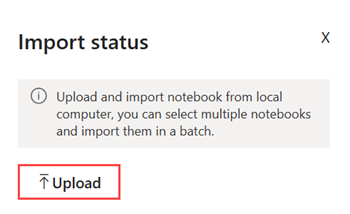
Quando a importação estiver concluída, abra o bloco de notas a partir da sua área de trabalho.
4- Obter dados
Para consultar seu banco de dados usando o conector Spark, você precisa conceder acesso de leitura e gravação ao contêiner de blob GreenTaxi de Nova York.
Selecione o botão de reprodução para executar as seguintes células ou selecione a célula e pressione Shift+ Enter. Repita esta etapa para cada célula de código.
Nota
Aguarde até que a marca de verificação de conclusão apareça antes de executar a próxima célula.
Execute a célula a seguir para habilitar o acesso ao contêiner de blob GreenTaxi de Nova York.
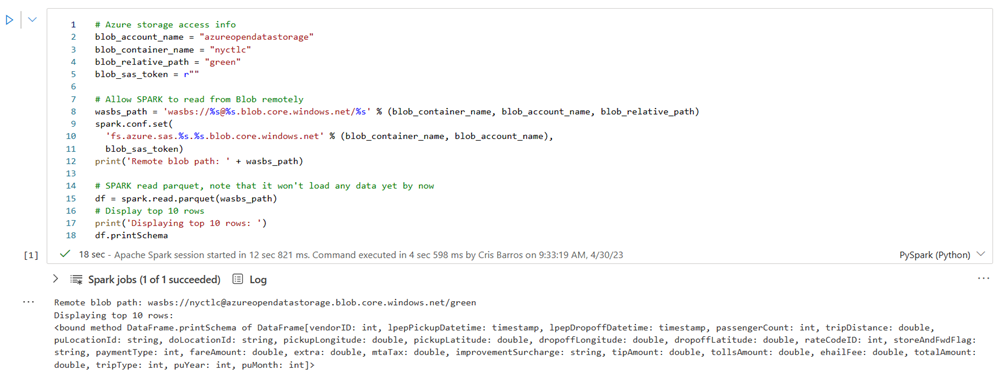
Em KustoURI, cole o URI de consulta que você copiou anteriormente em vez do texto de espaço reservado.
Altere o nome do banco de dados de espaço reservado para nycGreenTaxi.
Altere o nome da tabela de espaço reservado para GreenTaxiData.

Execute a célula.
Execute a próxima célula para gravar dados no banco de dados. Pode levar alguns minutos para que esta etapa seja concluída.




Seu banco de dados agora tem dados carregados em uma tabela chamada GreenTaxiData.
5- Execute o notebook
Execute as duas células restantes sequencialmente para consultar dados da tabela. Os resultados mostram as 20 tarifas e distâncias de táxi mais altas e mais baixas registadas por ano.

6- Limpar recursos
Limpe os itens criados navegando até o espaço de trabalho no qual foram criados.
No seu espaço de trabalho, passe o mouse sobre o bloco de anotações que deseja excluir, selecione o menu Mais [...] >Suprimir.
Selecione Eliminar. Não é possível recuperar o bloco de notas depois de o eliminar.
