Integre o Databricks Unity Catalog com o OneLake
Este cenário mostra como integrar tabelas Delta externas do Unity Catalog ao OneLake usando atalhos. Depois de concluir este tutorial, você poderá sincronizar automaticamente suas tabelas Delta externas do Catálogo Unity com uma casa de lago do Microsoft Fabric.
Pré-requisitos
Antes de se conectar, você deve ter:
- Um espaço de trabalho de malha.
- Uma casa de lago de tecido no seu espaço de trabalho.
- Tabelas Delta do Catálogo de Unidade Externa criadas no seu espaço de trabalho do Azure Databricks.
Configurar a sua ligação de armazenamento na nuvem
Primeiro, examine quais locais de armazenamento no Azure Data Lake Storage Gen2 (ADLS Gen2) suas tabelas do Catálogo Unity estão usando. Esta conexão de armazenamento em nuvem é usada pelos atalhos do OneLake. Para criar uma conexão de nuvem com o local de armazenamento apropriado do Catálogo Unity:
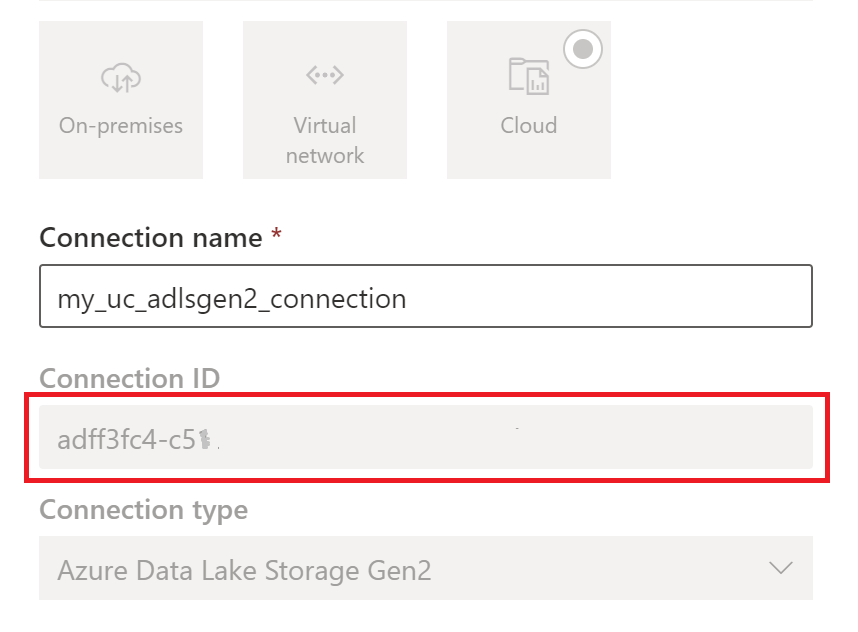
Crie uma conexão de armazenamento em nuvem usada por suas tabelas do Catálogo Unity. Veja como configurar uma conexão ADLS Gen2.
Depois de criar a conexão, obtenha o ID da conexão selecionando Configurações
 > Gerenciar conexões e configurações de conexões de gateways.>>
> Gerenciar conexões e configurações de conexões de gateways.>>
Nota
Conceder aos usuários acesso direto ao nível de armazenamento ao armazenamento de local externo no ADLS Gen2 não honra quaisquer permissões concedidas ou auditorias mantidas pelo Unity Catalog. O acesso direto ignorará auditoria, linhagem e outros recursos de segurança/monitoramento do Unity Catalog, incluindo controle de acesso e permissões. Você é responsável por gerenciar o acesso direto ao armazenamento por meio do ADLS Gen2 e garantir que os usuários tenham as permissões apropriadas concedidas via Fabric. Evite todos os cenários que concedem acesso direto de gravação no nível de armazenamento para buckets que armazenam tabelas gerenciadas Databricks. Modificar, excluir ou evoluir quaisquer objetos diretamente através do armazenamento que foram originalmente gerenciados pelo Unity Catalog pode resultar em corrupção de dados.
Executar o bloco de notas
Depois que o ID de conexão de nuvem for obtido, integre as tabelas do Unity Catalog ao Fabric lakehouse da seguinte maneira:
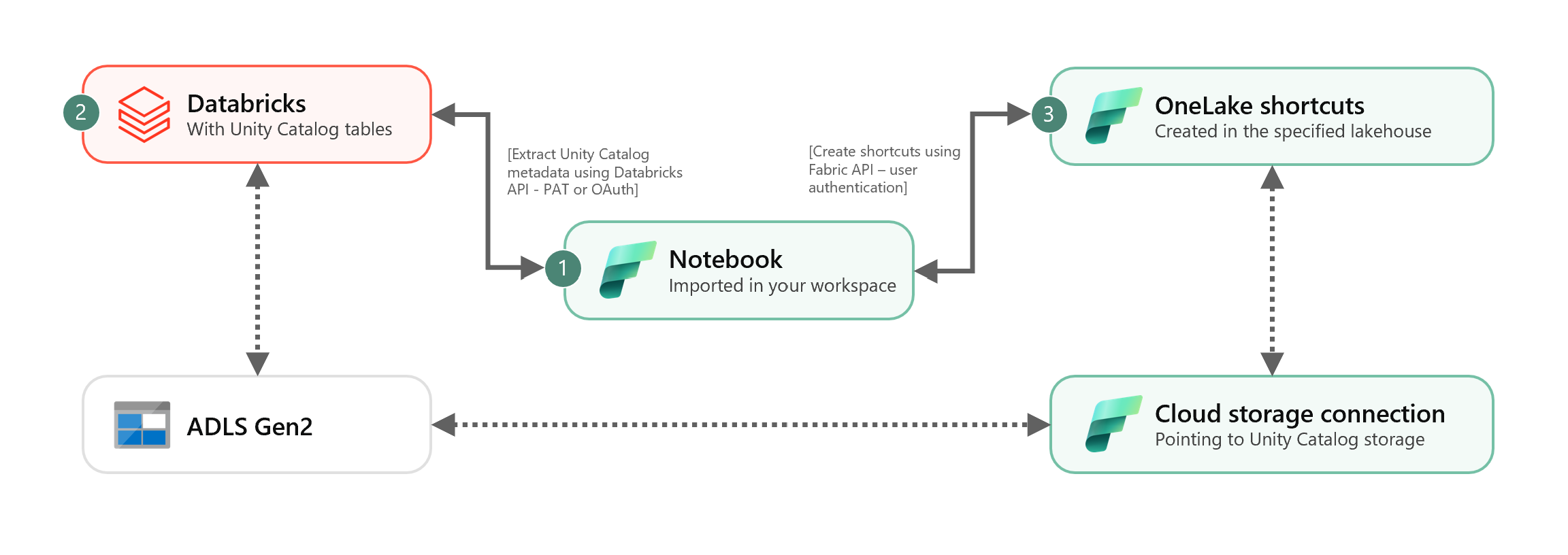
Importe o bloco de anotações de sincronização para o espaço de trabalho do Fabric. Este bloco de anotações exporta todos os metadados das tabelas do Unity Catalog de um determinado catálogo e esquemas em seu metastore.
Configure os parâmetros na primeira célula do bloco de anotações para integrar tabelas do Catálogo Unity. A API Databricks, autenticada através do token PAT, é utilizada para exportar tabelas do Catálogo Unity. O trecho a seguir é usado para configurar os parâmetros de origem (Unity Catalog) e destino (OneLake). Certifique-se de substituí-los por seus próprios valores.
# Databricks workspace dbx_workspace = "<databricks_workspace_url>" dbx_token = "<pat_token>" # Unity Catalog dbx_uc_catalog = "catalog1" dbx_uc_schemas = '["schema1", "schema2"]' # Fabric fab_workspace_id = "<workspace_id>" fab_lakehouse_id = "<lakehouse_id>" fab_shortcut_connection_id = "<connection_id>" # If True, UC table renames and deletes will be considered fab_consider_dbx_uc_table_changes = TrueExecute todas as células do bloco de anotações para começar a sincronizar tabelas Delta do Unity Catalog com o OneLake usando atalhos. Quando o bloco de anotações for concluído, os atalhos para as tabelas Delta do Unity Catalog estarão disponíveis no lakehouse, no ponto de extremidade de análise SQL e no modelo semântico.
Agendar o caderno
Se quiser executar o bloco de anotações em intervalos regulares para integrar tabelas Delta do Unity Catalog no OneLake sem ressincronização/repetição manual, você pode agendar o bloco de anotações ou utilizar uma atividade do bloco de anotações em um pipeline de dados no Fabric Data Factory.
No último cenário, se você pretende passar parâmetros do pipeline de dados, designe a primeira célula do bloco de anotações como uma célula de parâmetro de alternância e forneça os parâmetros apropriados no pipeline.

Outras considerações
- Para cenários de produção, recomendamos usar o Databricks OAuth para autenticação e o Azure Key Vault para gerenciar segredos. Por exemplo, você pode usar os utilitários de credenciais MSSparkUtils para acessar segredos do Cofre da Chave.
- O notebook funciona com tabelas Delta externas do Unity Catalog. Se você estiver usando vários locais de armazenamento em nuvem para suas tabelas do Catálogo Unity, ou seja, mais de um ADLS Gen2, a recomendação é executar o bloco de anotações separadamente por cada conexão de nuvem.
- Não há suporte para tabelas Delta gerenciadas pelo Unity Catalog, visualizações, exibições materializadas, tabelas de streaming e tabelas não Delta.
- As alterações nos esquemas de tabela do Unity Catalog, como adicionar / excluir colunas, são refletidas automaticamente nos atalhos. No entanto, algumas atualizações, como a renomeação e a exclusão da tabela do Catálogo Unity, exigem uma ressincronização/execução do bloco de anotações. Isso é considerado por
fab_consider_dbx_uc_table_changesparâmetro. - Para escrever cenários, usar a mesma camada de armazenamento em diferentes mecanismos de computação pode resultar em consequências indesejadas. Certifique-se de compreender as implicações ao usar diferentes mecanismos de computação Apache Spark e versões de tempo de execução.