Integrar o OneLake com o Azure HDInsight
O Azure HDInsight é um serviço gerenciado baseado em nuvem para análise de big data que ajuda as organizações a processar grandes quantidades de dados. Este tutorial mostra como se conectar ao OneLake com um bloco de anotações Jupyter de um cluster do Azure HDInsight.
Usando o Azure HDInsight
Para conectar-se ao OneLake com um bloco de anotações Jupyter a partir de um cluster HDInsight:
Crie um cluster do HDInsight (HDI) Apache Spark. Siga estas instruções: Configurar clusters no HDInsight.
Ao fornecer informações sobre o cluster, lembre-se do seu nome de usuário e senha de login do cluster, pois você precisa deles para acessar o cluster mais tarde.
Criar uma identidade gerenciada atribuída ao usuário (UAMI): crie para o Azure HDInsight - UAMI e escolha-a como a identidade na tela Armazenamento .
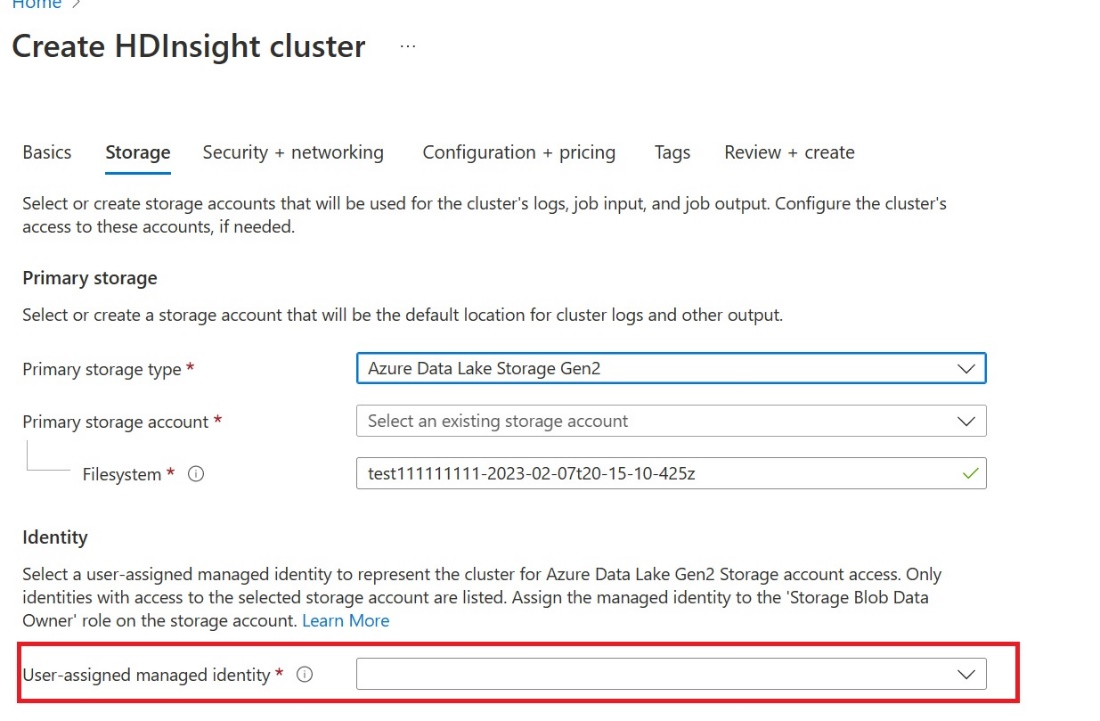
Dê a esse UAMI acesso ao espaço de trabalho Malha que contém seus itens. Para obter ajuda para decidir qual é a melhor função, consulte Funções do espaço de trabalho.
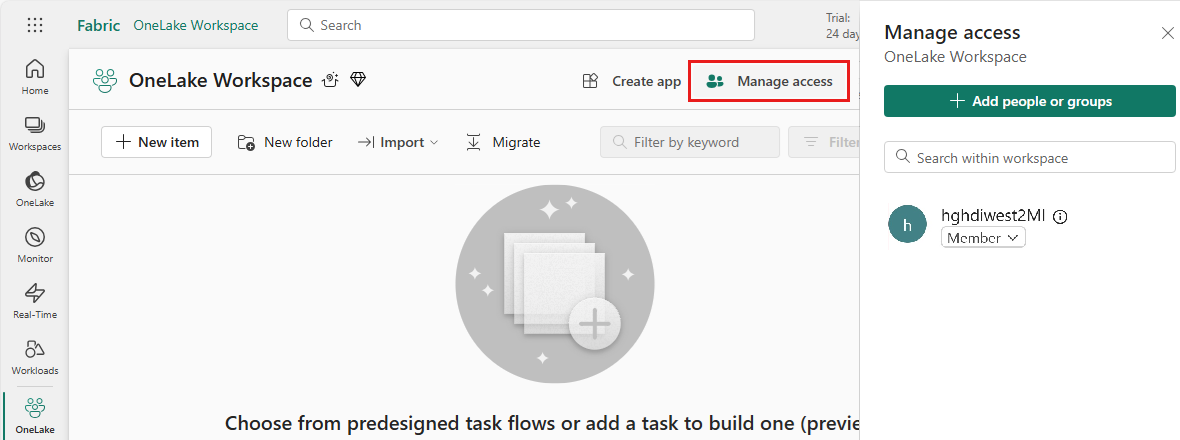
Navegue até a sua casa do lago e encontre o nome do seu espaço de trabalho e da casa do lago. Você pode encontrá-los no URL da sua casa do lago ou no painel Propriedades de um arquivo.
No portal do Azure, procure seu cluster e selecione o bloco de anotações.
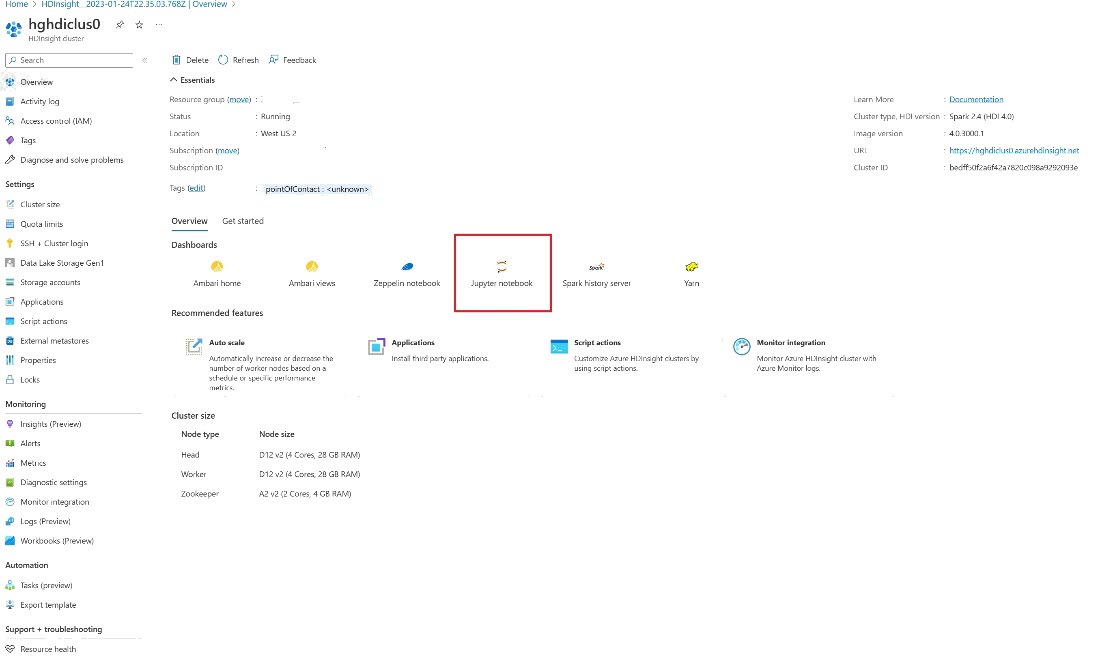
Insira as informações de credenciais fornecidas durante a criação do cluster.
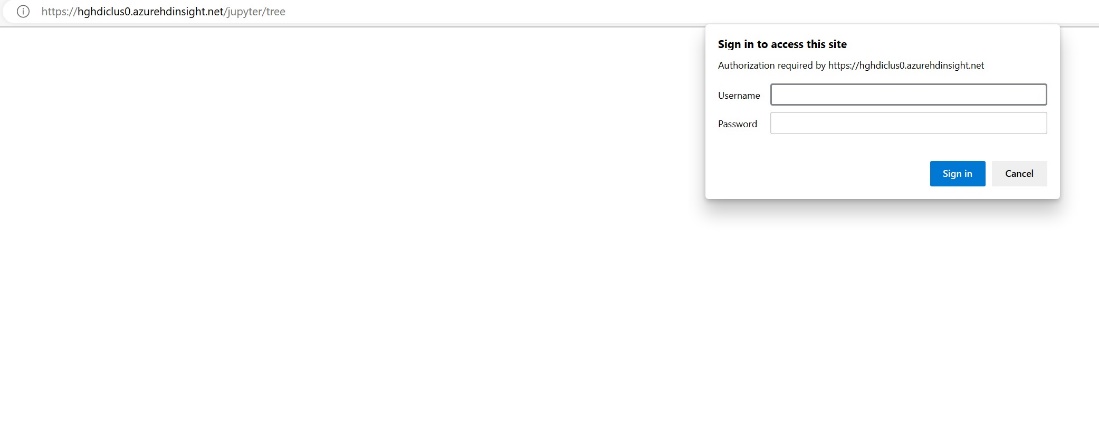
Crie um novo bloco de anotações Apache Spark.
Copie os nomes do espaço de trabalho e da casa do lago para o seu bloco de anotações e crie a URL do OneLake para a sua casa do lago. Agora você pode ler qualquer arquivo a partir deste caminho de arquivo.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()Tente escrever alguns dados na casa do lago.
writecsvdf = df.write.format("csv").save(fp + "out.csv")Teste se seus dados foram gravados com sucesso verificando sua casa do lago ou lendo seu arquivo recém-carregado.




Agora você pode ler e gravar dados no OneLake usando seu notebook Jupyter em um cluster HDI Spark.