Tutorial: Ingerir dados num armazém de dados
Aplica-se a:✅ Armazém no Microsoft Fabric
Neste tutorial, saiba como ingerir dados do Armazenamento do Microsoft Azure em um Depósito para criar tabelas.
Observação
Este tutorial faz parte de um cenário completo . Para concluir este tutorial, você deve primeiro concluir estes tutoriais:
Ingerir dados
Nesta tarefa, saiba como ingerir dados no armazém para criar tabelas.
Verifique se o espaço de trabalho criado no primeiro tutorial está aberto.
No painel inicial do espaço de trabalho, selecione + Novo Item para exibir a lista completa de tipos de itens disponíveis.
Na lista, na secção Obter dados, selecione o item do tipo Pipeline de dados.
Na janela Novo pipeline, na caixa Nome, introduza
Load Customer Data.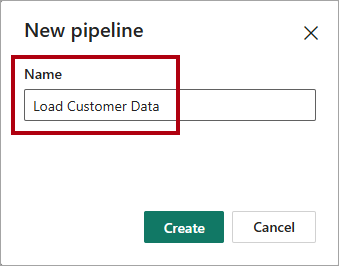
Para provisionar o pipeline, selecione Criar. O provisionamento é concluído quando a página de entrada Criar um pipeline de dados é exibida.
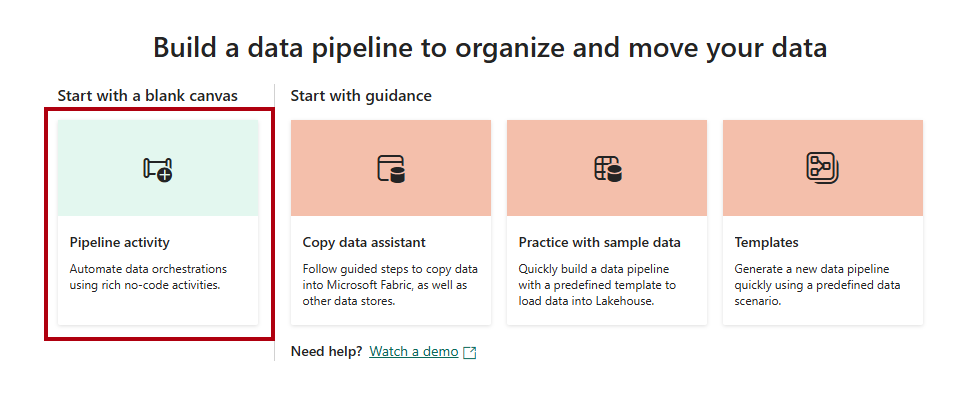
Na página de destino do pipeline de dados, selecione Atividade do pipeline.
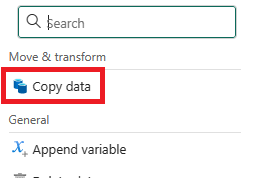
No menu, de dentro da seção Mover e transformar, selecione Copiar dados.
Na canvas de design do pipeline, selecione a atividade Copiar dados.
Para configurar a atividade, na página Geral, na caixa Nome, substitua o texto padrão por
CD Load dimension_customer.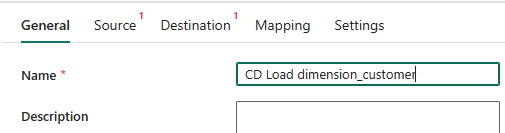
Na página de origem, na lista suspensa de conexão, selecione Mais para revelar todas as fontes de dados que pode escolher, incluindo as que estão no catálogo do OneLake.
Selecione + Novo para criar uma nova fonte de dados.
Procure e selecione Blobs do Azure.
Na página da fonte de dados do
Connect, na caixa Nome da conta ou URL, digite. Observe que a lista suspensa de Nomes de Conexão é preenchida automaticamente e que o método de autenticação está definido para Anónimo.
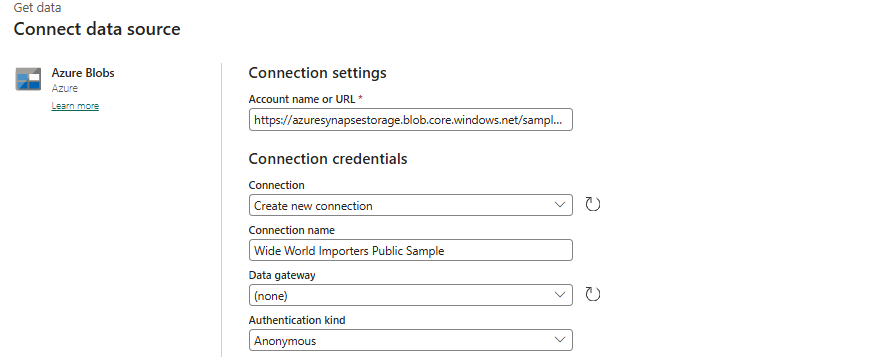
Selecione Ligar.
Na página de origem, para aceder aos ficheiros Parquet na fonte de dados, efetue as seguintes configurações.
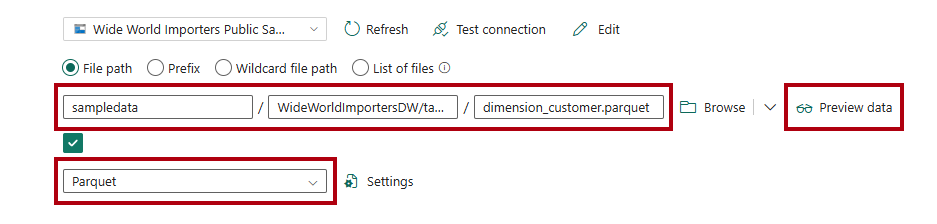
Nas caixas Caminho do arquivo, digite:
Caminho do arquivo - Contêiner:
sampledataCaminho do arquivo - Diretório:
WideWorldImportersDW/tablesCaminho do arquivo - Nome do arquivo:
dimension_customer.parquet
Na lista suspensa Formato de arquivo , selecione Parquet.
Para visualizar os dados e testar se não há erros, selecione Visualizar dados.
Na página de Destino, na lista suspensa de Conexão , selecione o armazém
Wide World Importers.Para a opção Tabela
, selecione a opção de criação automática de tabela . Na primeira caixa da Tabela , digite
dbo.Na segunda caixa, digite
dimension_customer.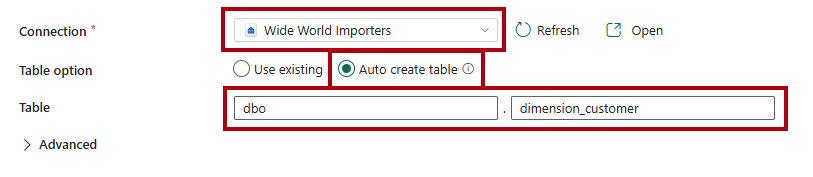
No friso da faixa de opções Início, selecione Executar.
Na caixa de diálogo Salvar e executar?, selecione Salvar e executar para que o pipeline carregue a tabela
dimension_customer.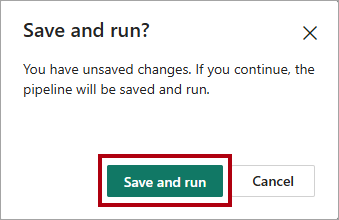
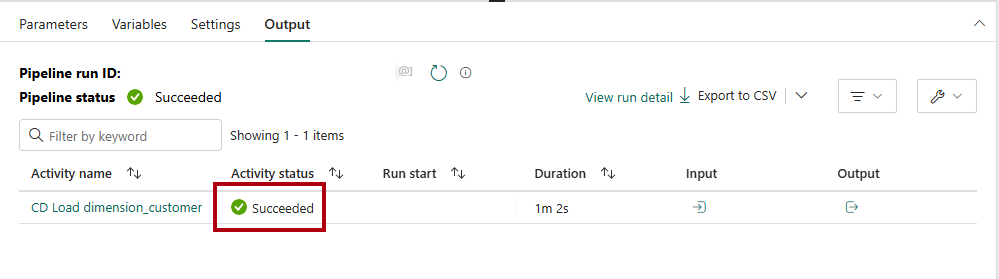
Para monitorizar o progresso da atividade de cópia, reveja as atividades de execução do pipeline na página de saída (aguarde até que o estado seja concluído com sucesso).