Planejando sua migração do Azure Data Factory
O Microsoft Fabric é o produto SaaS de análise de dados da Microsoft que reúne todos os produtos de análise líderes de mercado da Microsoft em uma única experiência de usuário. O Fabric Data Factory fornece orquestração de fluxo de trabalho, movimentação de dados, replicação de dados e transformação de dados em escala com recursos semelhantes que são encontrados no Azure Data Factory (ADF). Se você tiver investimentos existentes no ADF que gostaria de modernizar para o Fabric Data Factory, este documento é útil para ajudá-lo a entender as considerações, estratégias e abordagens de migração.
A migração dos serviços de pipelines e fluxos de dados do ADF & Synapse do Azure PaaS ETL/DI pode fornecer vários benefícios importantes:
- Novos recursos integrados de pipeline, incluindo atividades de e-mail e do Teams, permitem o roteamento fácil de mensagens durante a execução do pipeline.
- Os recursos integrados de integração e entrega contínua (CI/CD) (pipelines de implantação) não exigem integração externa com repositórios Git.
- A integração do espaço de trabalho com seu data lake OneLake permite o gerenciamento fácil de análises com um único painel de vidro.
- Atualizar seus modelos de dados semânticos é fácil no Fabric com uma atividade de pipeline totalmente integrada.
O Microsoft Fabric é uma plataforma integrada para dados corporativos de autoatendimento e gerenciados por TI. Com o crescimento exponencial em volumes de dados e complexidade, os clientes do Fabric exigem soluções corporativas que sejam dimensionáveis, seguras, fáceis de gerenciar e acessíveis a todos os usuários nas maiores organizações.
Nos últimos anos, a Microsoft investiu esforços significativos para fornecer recursos de nuvem escaláveis para o Premium. Para esse fim, o Data Factory in Fabric capacita instantaneamente um grande ecossistema de desenvolvedores de integração de dados e soluções de integração de dados que foram construídas ao longo de décadas para aplicar o conjunto completo de recursos e capacidades que vão muito além da funcionalidade comparável disponível nas gerações anteriores.
Naturalmente, os clientes estão se perguntando se há uma oportunidade de consolidar hospedando suas soluções de integração de dados no Fabric. As perguntas mais comuns incluem:
- Toda a funcionalidade de que dependemos funciona nos pipelines do Fabric?
- Quais capacidades estão disponíveis apenas em Pipelines Fabric?
- Como migramos pipelines existentes para Fabric pipelines?
- Qual é o roteiro da Microsoft para a ingestão de dados corporativos?
Diferenças de plataforma
Quando você migra uma instância inteira do ADF, há muitas diferenças importantes a serem consideradas entre o ADF e o Data Factory na malha, o que se torna importante à medida que você migra para a malha. Exploramos várias dessas diferenças importantes nesta seção.
Para obter uma compreensão mais detalhada do mapeamento funcional das diferenças de recursos entre o Azure Data Factory e o Fabric Data Factory, consulte Compare Data Factory in Fabric e Azure Data Factory.
Tempos de execução de integração
No ADF, os tempos de execução de integração (IRs) são objetos de configuração que representam a computação usada pelo ADF para concluir o processamento de dados. Essas propriedades de configuração incluem a região do Azure para computação em nuvem e tamanhos de computação Spark de fluxo de dados. Outros tipos de RI incluem IRs autogeridos (SHIRs) para conectividade de dados local, IRs do SSIS para executar pacotes de SQL Server Integration Services, e IRs de nuvem habilitados para VNet.
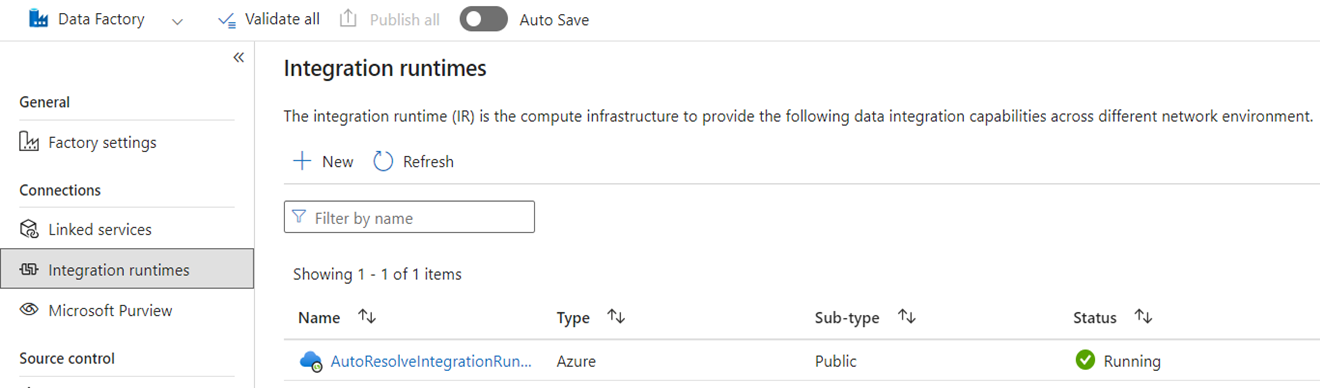
O Microsoft Fabric é um produto de software como serviço (SaaS), enquanto o ADF é um produto de plataforma como serviço (PaaS). O que essa distinção significa em termos de tempos de execução de integração é que você não precisa configurar nada para usar pipelines ou fluxos de dados no Fabric, pois o padrão é usar computação baseada em nuvem na região onde suas capacidades de malha estão localizadas. Os IRs SSIS não existem na malha e, para conectividade de dados local, você usa um componente específico da malha conhecido como de gateway de dados local (OPDG). E para conectividade baseada em rede virtual para redes seguras, utilize o Gateway de Dados de Rede Virtual no Fabric.
Ao migrar do ADF para o Fabric, não é necessário migrar os IRs do Azure (nuvem) de rede pública. Você precisa recriar seus SHIRs como OPDGs e IRs do Azure habilitados para rede virtual como Gateways de Dados de Rede Virtual.

Condutas
Os pipelines são o componente fundamental do ADF, que é usado para o fluxo de trabalho primário e orquestração de seus processos ADF para movimentação de dados, transformação de dados e orquestração de processos. Os pipelines no Fabric Data Factory são quase idênticos ao ADF, mas com componentes extras que se ajustam bem ao modelo SaaS baseado no Power BI. Essa semelhança inclui atividades nativas para e-mails, Teams e atualizações do Modelo Semântico.
A definição JSON de pipelines no Fabric Data Factory difere ligeiramente do ADF devido a diferenças no modelo de aplicativo entre os dois produtos. Devido a esta diferença, não é possível copiar/colar pipeline JSON, importar/exportar pipelines ou referenciar um repositório Git ADF.
Ao reconstruir os seus pipelines do ADF como pipelines do Fabric, utiliza essencialmente os mesmos modelos de fluxo de trabalho e competências que utilizou no ADF. A principal consideração tem a ver com Serviços Vinculados e Conjuntos de Dados, que são conceitos no ADF que não existem no Fabric.
Serviços Vinculados
No ADF, os Serviços Vinculados definem as propriedades de conectividade necessárias para se conectar aos seus armazenamentos de dados para movimentação de dados, transformação de dados e atividades de processamento de dados. No Fabric, você precisa recriar essas definições como Conexões que são propriedades para suas atividades, como Copiar e Fluxos de Dados.
Conjuntos de dados
Os conjuntos de dados definem a forma, o local e o conteúdo dos dados no ADF, mas não existem como entidades no Fabric. Para definir propriedades de dados como tipos de dados, colunas, pastas, tabelas, etc. nos pipelines do Fabric Data Factory, defina essas características inline dentro das atividades do pipeline e dentro do objeto Connection referenciado anteriormente na seção Serviço Vinculado.
Fluxos de dados
No Data Factory for Fabric, o termo fluxos de dados refere-se às atividades de transformação de dados sem código, enquanto no ADF, o mesmo recurso é referido como fluxos de dados . Os fluxos de dados do Fabric Data Factory têm uma interface de utilizador incorporada no Power Query, que é utilizada na atividade do ADF Power Query. A computação usada para executar fluxos de dados no Fabric é um mecanismo de execução nativo que pode ser dimensionado para transformação de dados em grande escala usando o novo mecanismo de computação do Fabric Data Warehouse.
No ADF, os fluxos de dados são criados na infraestrutura do Synapse Spark e definidos usando uma interface de usuário de construção que usa uma linguagem de domínio específica (DSL) subjacente conhecida como script de fluxo de dados . Essa linguagem de definição difere consideravelmente dos fluxos de dados baseados no Power Query na Malha que usam uma linguagem de definição conhecida como M para definir seu comportamento. Devido a essas diferenças nas interfaces de usuário, linguagens e mecanismos de execução, os fluxos de dados do Fabric e os fluxos de dados do ADF não são compatíveis e é necessário recriar os seus fluxos de dados do ADF como fluxos de dados do Fabric ao atualizar as suas soluções para o Fabric.
Gatilhos
Os gatilhos sinalizam o ADF para executar um pipeline com base num horário de relógio, janelas temporais em série, eventos baseados em arquivos ou eventos personalizados. Esses recursos são semelhantes no Fabric, embora a implementação subjacente seja diferente.
No Fabric, acionadores só existir como um conceito de pipeline. A estrutura maior utilizada pelos gatilhos de pipeline no Fabric é conhecida como Data Activator, que é um subsistema de eventos e alertas dos recursos de Inteligência em Tempo Real no Fabric.
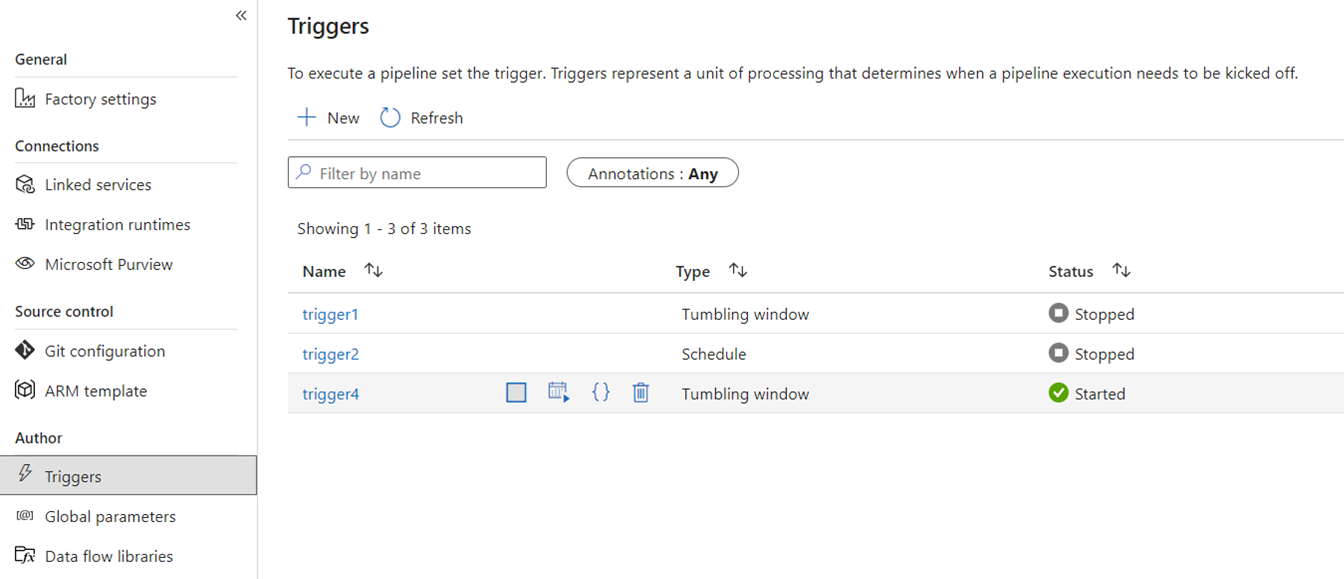
O Fabric Data Activator tem alertas que podem ser usados para criar eventos de arquivo e gatilhos de eventos personalizados. Enquanto os gatilhos de agenda são uma entidade separada no Fabric conhecida como agendas. Essas agendas estão em um nível de plataforma no Fabric, e não são específicas para pipelines. Eles também não são chamados de gatilhos no Fabric.
Para migrar os seus gatilhos do ADF para o Fabric, considere reconstruir os seus gatilhos de agendamento simplesmente como agendamentos que são propriedades dos seus pipelines do Fabric. E para todos os outros tipos de gatilho, use o botão Gatilhos dentro do pipeline do Fabric ou use o Data Activator de forma nativa no Fabric.
Depuração
A depuração de pipelines é mais simples no Fabric do que no ADF. Essa simplicidade ocorre porque os pipelines do Fabric Data Factory não têm um conceito separado de modo de depuração que você encontra em pipelines e fluxos de dados do ADF. Em vez disso, quando você cria o seu pipeline, está sempre no modo interativo. Para testar e depurar seus pipelines, você só precisa selecionar o botão de reprodução na barra de ferramentas do editor de pipeline quando estiver pronto em seu ciclo de desenvolvimento. Os pipelines no Fabric não incluem a depuração interativa até o padrão de depuração passo a passo. Em vez disso, no Fabric, você utiliza o estado da atividade e define apenas as atividades que deseja testar como ativas enquanto define todas as outras atividades como inativas para obter os mesmos padrões de teste e depuração. Consulte o vídeo a seguir que explica como obter essa experiência de depuração no Fabric.
Captura de Alterações de Dados
O Change Data Capture (CDC) no ADF é um recurso em pré-visualização que facilita a movimentação rápida de dados de forma incremental, aplicando as funcionalidades CDC do lado da origem dos seus repositórios de dados. Para migrar os seus artefatos CDC para o Fabric Data Factory, recrie esses artefatos como itens de tarefa de cópia no seu espaço de trabalho de malha. Esse recurso fornece recursos semelhantes de movimentação incremental de dados com uma interface do usuário fácil de usar sem a necessidade de um pipeline, assim como no ADF CDC. Para obter mais informações, consulte o de trabalho de cópia de para o Data Factory na malha.
Azure Synapse Link
Embora não esteja disponível no ADF, os usuários do pipeline Synapse frequentemente utilizam o Azure Synapse Link para replicar dados de bancos de dados SQL para seu data lake em uma abordagem turnkey. No Fabric, você recria os artefatos do Azure Synapse Link como itens de espelhamento em seu espaço de trabalho. Para obter mais informações, consulte o espelhamento de banco de dados Fabric .
SQL Server Integration Services (SSIS)
O SSIS é a ferramenta de integração de dados local e ETL que a Microsoft fornece com o SQL Server. No ADF, você pode elevar e deslocar seus pacotes SSIS para a nuvem usando o ADF SSIS IR. No Fabric, não temos o conceito de IRs, então essa funcionalidade não é possível atualmente. No entanto, estamos trabalhando para permitir a execução de pacotes SSIS nativamente a partir do Fabric, que esperamos trazer para o produto em breve. Enquanto isso, a melhor maneira de executar pacotes SSIS na nuvem com o Fabric Data Factory é iniciar um IR SSIS em sua fábrica do ADF e, em seguida, invocar um pipeline do ADF para chamar seus pacotes SSIS. ** Você pode chamar remotamente um pipeline do ADF a partir dos seus pipelines do Fabric usando a atividade de pipeline invocada, como descrito na seção a seguir.
Invocar atividade de linha de processamento
Uma atividade comum usada em pipelines do ADF é o Execute pipeline activity que permite chamar outro pipeline em sua fábrica. No Fabric, aprimorámos esta atividade como a atividade de pipeline Invoke. Consulte a Invocar atividade de pipeline documentação.
Essa atividade é útil para cenários de migração em que você tem muitos pipelines do ADF que usam recursos específicos do ADF, como mapeamento de fluxos de dados ou SSIS. Você pode manter esses pipelines as-is nos pipelines ADF ou até mesmo nos pipelines Synapse e, em seguida, chamar esse pipeline diretamente a partir do seu novo pipeline no Fabric Data Factory, usando a atividade Invocar pipeline e apontando para o pipeline da fábrica remota.
Exemplos de cenários de migração
Os cenários a seguir são cenários de migração comuns que você pode encontrar ao migrar do ADF para o Fabric Data Factory.
Cenário #1: Pipelines e fluxos de dados do ADF
Os principais casos de uso para migrações de 'factory' são baseados na modernização do ambiente ETL do modelo "PaaS" da fábrica de dados ADF para o novo modelo "SaaS" da plataforma Fabric. Os principais itens de fábrica a serem migrados são pipelines e fluxos de dados. Há vários elementos fundamentais de fábrica que você precisa planejar a migração fora desses dois itens de nível superior: serviços vinculados, tempos de execução de integração, conjuntos de dados e gatilhos.
- Os serviços vinculados precisam ser recriados no Fabric como conexões em suas atividades de pipeline.
- Os conjuntos de dados não existem no Factory. As propriedades de seus conjuntos de dados são representadas como propriedades dentro de atividades de pipeline, como Cópia ou Pesquisa, enquanto Conexões contêm outras propriedades de conjunto de dados.
- Os tempos de execução de integração não existem no Fabric. No entanto, seus IRs auto-hospedados podem ser recriados usando Gateways de Dados Locais (OPDG) no Fabric e IRs de rede virtual do Azure como gateways de rede virtual gerenciados no Fabric.
- Essas atividades de pipeline do ADF não estão incluídas no Fabric Data Factory:
- Data Lake Analytics (U-SQL) - Este recurso é um serviço do Azure preterido.
- Atividade de validação - A atividade de validação no ADF é uma atividade auxiliar que pode ser facilmente reconstruída nos seus pipelines do Fabric usando uma atividade Obter Metadados, um ciclo de pipeline e uma atividade If.
- Power Query - No Fabric, todos os fluxos de dados são criados usando a interface do usuário do Power Query, para que você possa simplesmente copiar e colar seu código M de suas atividades do ADF Power Query e criá-los como fluxos de dados na Malha.
- Se você estiver usando qualquer um dos recursos de pipeline do ADF que não são encontrados no Fabric Data Factory, use a atividade de pipeline Invoke no Fabric para chamar seus pipelines existentes no ADF.
- As seguintes atividades de pipeline do ADF são combinadas em uma única atividade:
- Atividades do Azure Databricks (Notebook, Jar, Python)
- Azure HDInsight (Hive, Pig, MapReduce, Spark, Streaming)
A imagem a seguir mostra a página de configuração do conjunto de dados do ADF, com seu caminho de arquivo e configurações de compactação:
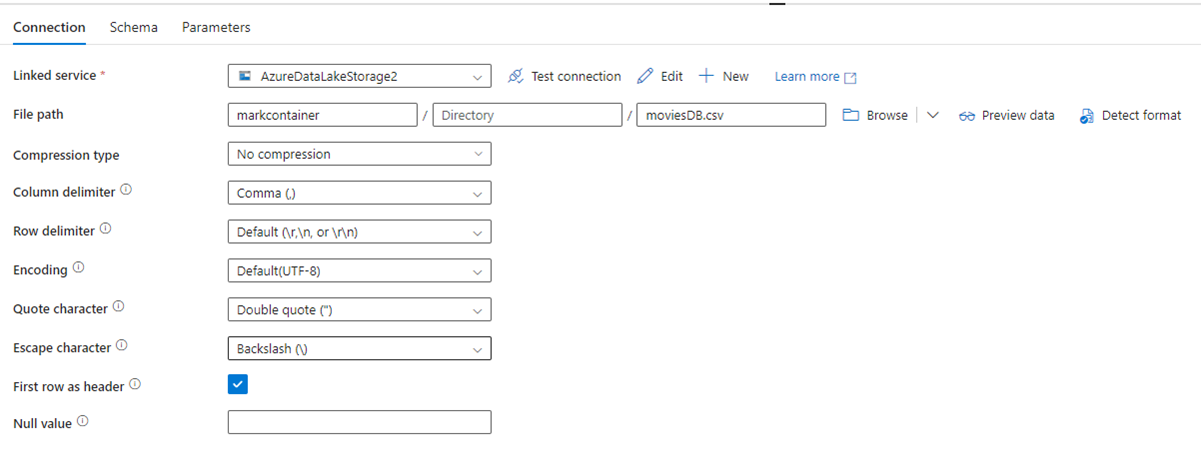
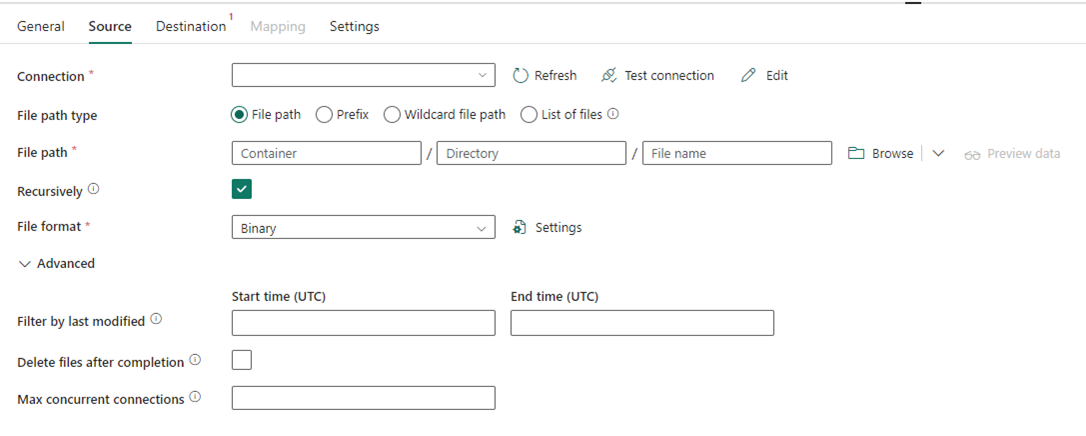
A imagem a seguir mostra a configuração da atividade de Copiar no Data Factory em Fabric, onde a compactação e o caminho do arquivo estão inseridos na atividade.
Cenário #2: ADF com CDC, SSIS e Airflow
CDC & e o Airflow no ADF são funcionalidades em pré-visualização, enquanto o SSIS no ADF é uma funcionalidade geralmente disponível há muitos anos. Cada um desses recursos atende a diferentes necessidades de integração de dados, mas requer atenção especial ao migrar do ADF para o Fabric. O CDC (Change Data Capture) é um conceito de ADF de nível superior, mas no Fabric, você vê esse recurso como o trabalho de cópia .
O Airflow é o recurso Apache Airflow gerenciado na nuvem do ADF e também está disponível no Fabric Data Factory. Você deve ser capaz de usar o mesmo repositório de origem do Airflow ou pegar os seus DAGs e copiar/colar o código na oferta do Airflow do Fabric com pouca ou nenhuma alteração necessária.
Cenário #3: Migração de Fábrica de Dados com suporte para Git para Fabric
É comum, embora não obrigatório, que suas fábricas e espaços de trabalho ADF ou Synapse estejam conectados ao seu próprio provedor Git externo no ADO ou GitHub. Neste cenário, é necessário migrar os seus itens de fábrica e de espaço de trabalho para um espaço de trabalho Fabric e, em seguida, estabelecer a integração do Git no seu espaço de trabalho Fabric.
O Fabric fornece duas maneiras principais de habilitar o CI/CD, ambas ao nível do espaço de trabalho: integração Git, na qual você traz o seu próprio repositório Git para o ADO e se conecta a ele a partir do Fabric, e pipelines de implementação integrados nos quais você pode promover código para ambientes superiores sem a necessidade de trazer o seu próprio Git.
Em ambos os casos, seu repositório Git existente do ADF não funciona com o Fabric. Em vez disso, você precisa apontar para um novo repositório ou iniciar um novo pipeline de implementação no Fabric e reconstruir os seus artefactos do pipeline no Fabric.
Monte as instâncias existentes do ADF diretamente num espaço de trabalho do Fabric
Anteriormente, falamos sobre o uso da atividade Invocar Pipeline do Fabric Data Factory como um mecanismo para manter os investimentos existentes nos pipelines do ADF e invocá-los diretamente a partir do Fabric. No Fabric, você pode levar esse conceito semelhante um passo adiante e montar toda a fábrica dentro do espaço de trabalho do Fabric como um item nativo do Fabric.
Para obter mais informações sobre cenários de uso de montagem, consulte Cenários de colaboração e entrega de conteúdo.
Montar o Azure Data Factory dentro do espaço de trabalho do Fabric traz muitos benefícios a serem considerados. Se você é novo no Fabric e gostaria de manter suas fábricas lado a lado dentro do mesmo painel de vidro, você pode montá-las no Fabric para que você possa gerenciar ambas dentro do Fabric. A interface do usuário completa do ADF agora está disponível para você em sua fábrica montada, onde você pode monitorar, gerenciar e editar seus itens de fábrica do ADF totalmente a partir do espaço de trabalho Fabric. Esse recurso torna muito mais fácil começar a migrar esses itens para o Fabric como artefatos nativos do Fabric. Este recurso é essencialmente para facilitar o uso e torna mais fácil ver as suas fábricas do Azure Data Factory no seu espaço de trabalho do Fabric. No entanto, a execução real dos pipelines, atividades, tempos de execução de integração, etc., ainda ocorre dentro de seus recursos do Azure.
Conteúdo relacionado
Considerações sobre migração do ADF para o Data Factory no Fabric