Carregue dados incrementalmente do Data Warehouse para o Lakehouse
Neste tutorial, você aprenderá a carregar dados incrementalmente do Data Warehouse para o Lakehouse.
Descrição geral
Eis o diagrama de nível elevado da solução:

Eis os passos importantes para criar esta solução:
Selecionar a coluna de limite de tamanho. Selecione uma coluna na tabela de dados de origem, que pode ser usada para fatiar os registros novos ou atualizados para cada execução. Normalmente, os dados nesta coluna selecionada (por exemplo, last_modify_time ou ID) continuam a aumentar quando as linhas são criadas ou atualizadas. O valor máximo nesta coluna é utilizado como limite de tamanho.
Prepare uma tabela para armazenar o último valor de marca d'água no seu Data Warehouse.
Crie um pipeline com o seguinte fluxo de trabalho:
O pipeline nesta solução tem as seguintes atividades:
- Criar duas atividades de pesquisa. Utilize a primeira atividade de pesquisa para obter o último valor de limite de tamanho. Utilize a segunda atividade de pesquisa para obter o novo valor de limite de tamanho. Estes valores de limite de tamanho são transmitidos para a atividade de cópia.
- Crie uma atividade de cópia que copie linhas da tabela de dados de origem com o valor da coluna de marca d'água maior que o valor da marca d'água antiga e menor que o novo valor da marca d'água. Em seguida, ele copia os dados do Data Warehouse para o Lakehouse como um novo arquivo.
- Crie uma atividade de procedimento armazenado que atualize o último valor de marca d'água para a próxima execução de pipeline.
Pré-requisitos
- Armazém de Dados. Você usa o Data Warehouse como o armazenamento de dados de origem. Se você não o tiver, consulte Criar um Data Warehouse para conhecer as etapas para criar um.
- Casa do lago. Você usa o Lakehouse como o armazenamento de dados de destino. Se você não a tiver, consulte Criar uma Lakehouse para conhecer as etapas para criar uma. Crie uma pasta chamada IncrementalCopy para armazenar os dados copiados.
Preparar a fonte
Aqui estão algumas tabelas e procedimentos armazenados que você precisa preparar no Data Warehouse de origem antes de configurar o pipeline de cópia incremental.
1. Crie uma tabela de fonte de dados no seu Data Warehouse
Execute o seguinte comando SQL no seu Data Warehouse para criar uma tabela chamada data_source_table como a tabela da fonte de dados. Neste tutorial, você os usará como os dados de exemplo para fazer a cópia incremental.
create table data_source_table
(
PersonID int,
Name varchar(255),
LastModifytime DATETIME2(6)
);
INSERT INTO data_source_table
(PersonID, Name, LastModifytime)
VALUES
(1, 'aaaa','9/1/2017 12:56:00 AM'),
(2, 'bbbb','9/2/2017 5:23:00 AM'),
(3, 'cccc','9/3/2017 2:36:00 AM'),
(4, 'dddd','9/4/2017 3:21:00 AM'),
(5, 'eeee','9/5/2017 8:06:00 AM');
Os dados na tabela da fonte de dados são mostrados abaixo:
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
Neste tutorial, você usa LastModifytime como a coluna de marca d'água.
2. Crie outra tabela no seu Data Warehouse para armazenar o último valor da marca d'água
Execute o seguinte comando SQL no seu Data Warehouse para criar uma tabela chamada watermarktable para armazenar o último valor da marca d'água:
create table watermarktable ( TableName varchar(255), WatermarkValue DATETIME2(6), );Defina o valor padrão da última marca d'água com o nome da tabela de dados de origem. Neste tutorial, o nome da tabela é data_source_table e o valor padrão é
1/1/2010 12:00:00 AM.INSERT INTO watermarktable VALUES ('data_source_table','1/1/2010 12:00:00 AM')Analise os dados na tabela watermarktable.
Select * from watermarktableSaída:
TableName | WatermarkValue ---------- | -------------- data_source_table | 2010-01-01 00:00:00.000
3. Crie um procedimento armazenado no seu Data Warehouse
Execute o seguinte comando para criar um procedimento armazenado no seu Data Warehouse. Este procedimento armazenado é usado para ajudar a atualizar o último valor de marca d'água após a última execução do pipeline.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Configurar um pipeline para cópia incremental
Etapa 1: Criar um pipeline
Navegue até Power BI.
Selecione o ícone do Power BI no canto inferior esquerdo do ecrã e, em seguida, selecione Data factory para abrir a página inicial do Data Factory.
Navegue até o espaço de trabalho do Microsoft Fabric.
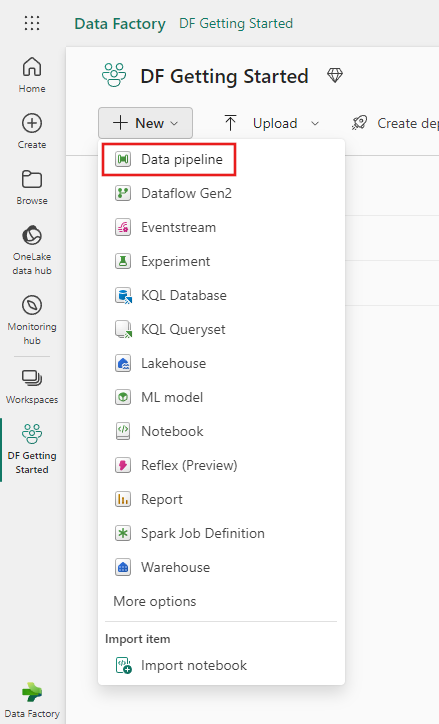
Selecione Pipeline de dados e insira um nome de pipeline para criar um novo pipeline.
Etapa 2: adicionar uma atividade de pesquisa para a última marca d'água
Nesta etapa, você cria uma atividade de pesquisa para obter o último valor de marca d'água. O valor 1/1/2010 12:00:00 AM padrão definido antes será obtido.
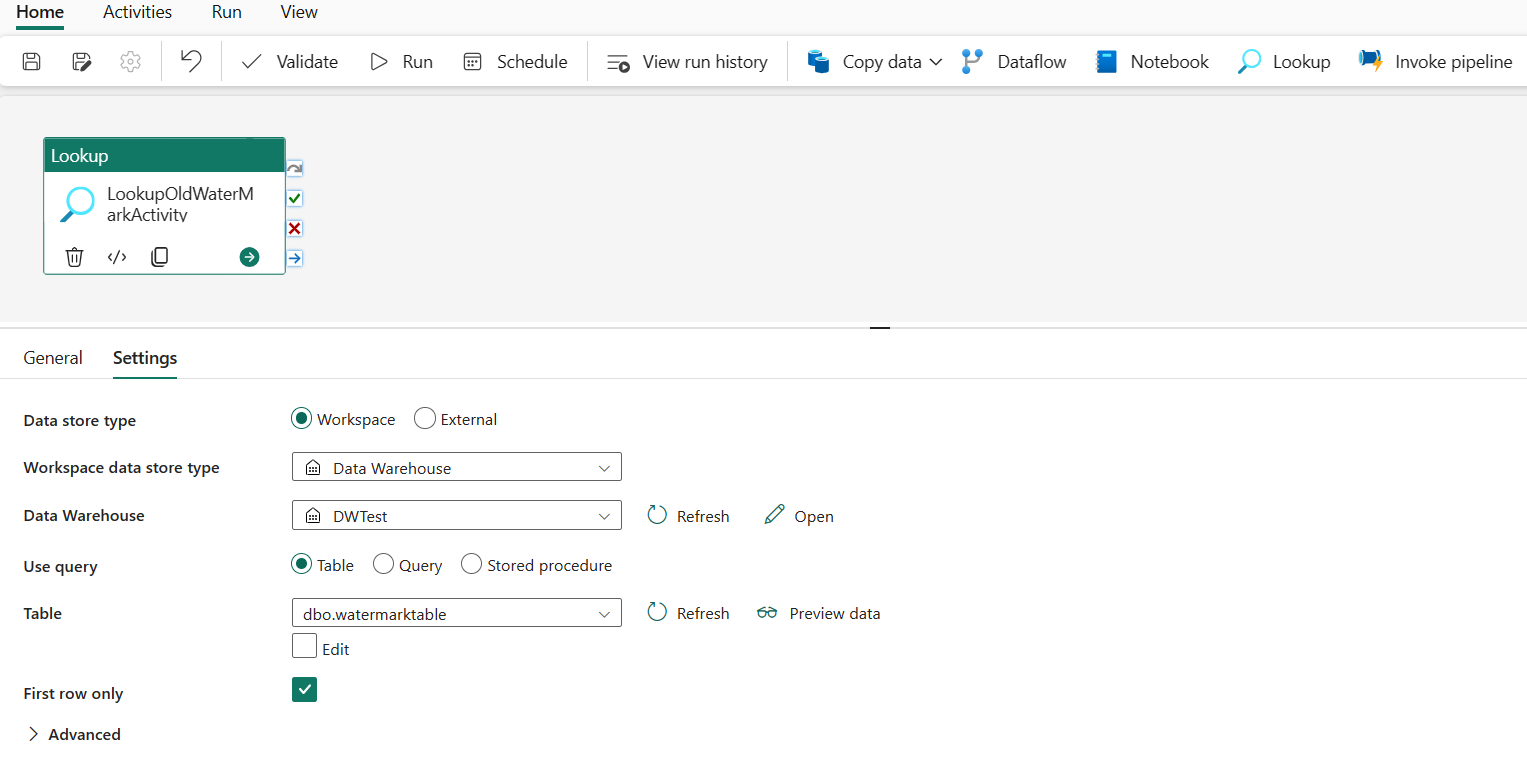
Selecione Adicionar atividade de pipeline e selecione Pesquisa na lista suspensa.
Na guia Geral , renomeie essa atividade para LookupOldWaterMarkActivity.
Na guia Configurações , execute a seguinte configuração:
- Tipo de armazenamento de dados: Selecione Espaço de trabalho.
- Tipo de armazenamento de dados do espaço de trabalho: Selecione Data Warehouse.
- Data Warehouse: Selecione o seu Data Warehouse.
- Usar consulta: escolha Tabela.
- Tabela: Escolha dbo.watermarktable.
- Apenas primeira linha: Selecionado.
Etapa 3: adicionar uma atividade de pesquisa para a nova marca d'água
Nesta etapa, você cria uma atividade de pesquisa para obter o novo valor da marca d'água. Você usará uma consulta para obter a nova marca d'água da tabela de dados de origem. O valor máximo na coluna LastModifytime em data_source_table será obtido.
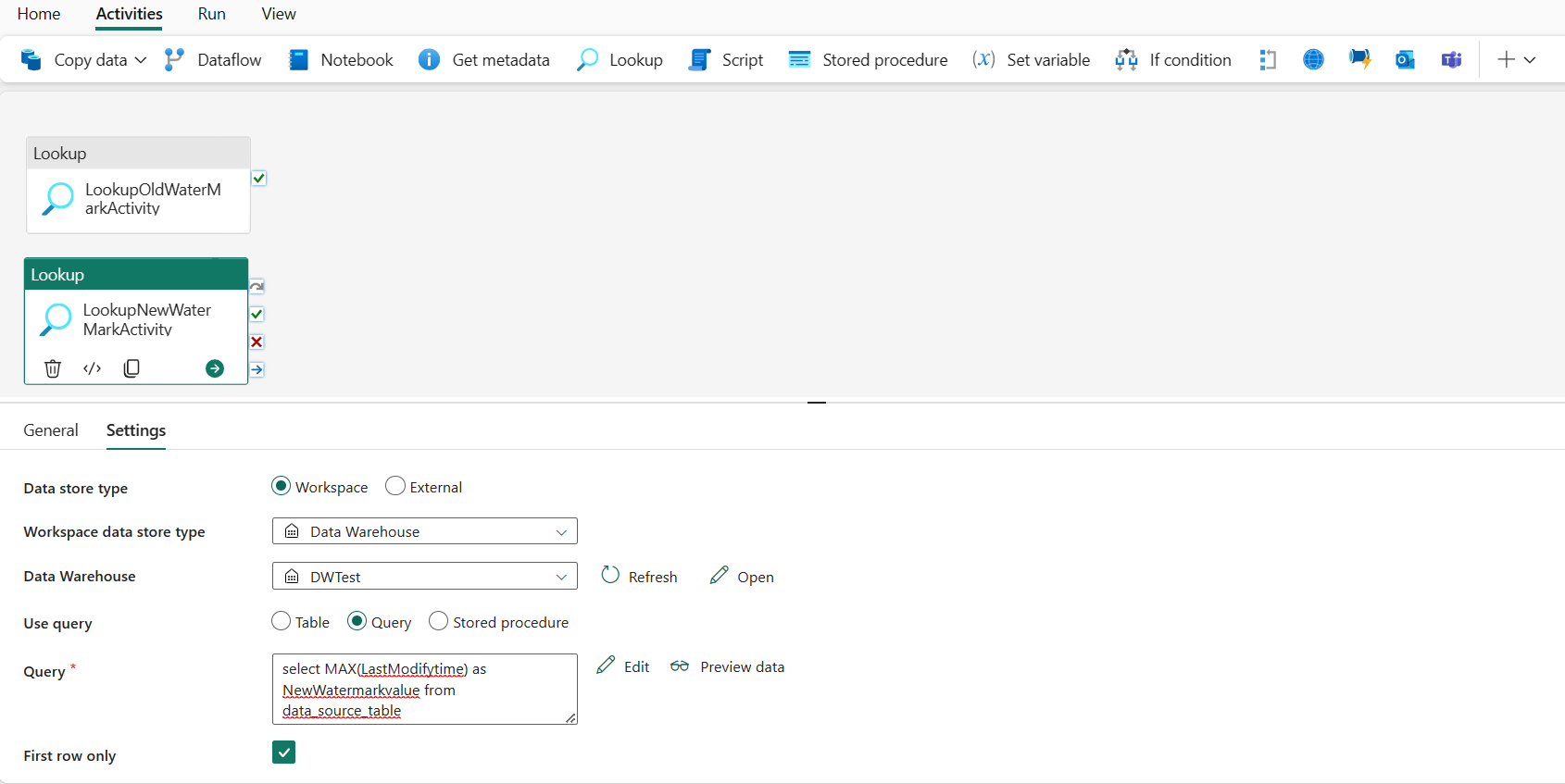
Na barra superior, selecione Pesquisa na guia Atividades para adicionar a segunda atividade de pesquisa.
Na guia Geral , renomeie essa atividade para LookupNewWaterMarkActivity.
Na guia Configurações , execute a seguinte configuração:
Tipo de armazenamento de dados: Selecione Espaço de trabalho.
Tipo de armazenamento de dados do espaço de trabalho: Selecione Data Warehouse.
Data Warehouse: Selecione o seu Data Warehouse.
Usar consulta: escolha Consulta.
Consulta: insira a seguinte consulta para escolher o tempo máximo da última modificação como a nova marca d'água:
select MAX(LastModifytime) as NewWatermarkvalue from data_source_tableApenas primeira linha: Selecionado.
Etapa 4: Adicionar a atividade de cópia para copiar dados incrementais
Nesta etapa, você adiciona uma atividade de cópia para copiar os dados incrementais entre a última marca d'água e a nova marca d'água do Data Warehouse para o Lakehouse.
Selecione Atividades na barra superior e selecione Copiar dados -> Adicionar à tela para obter a atividade de cópia.
Na guia Geral , renomeie essa atividade para IncrementalCopyActivity.
Conecte ambas as atividades de Pesquisa à atividade de cópia arrastando o botão verde (Em êxito) anexado às atividades de pesquisa para a atividade de cópia. Solte o botão do mouse quando vir que a cor da borda da atividade de cópia muda para verde.

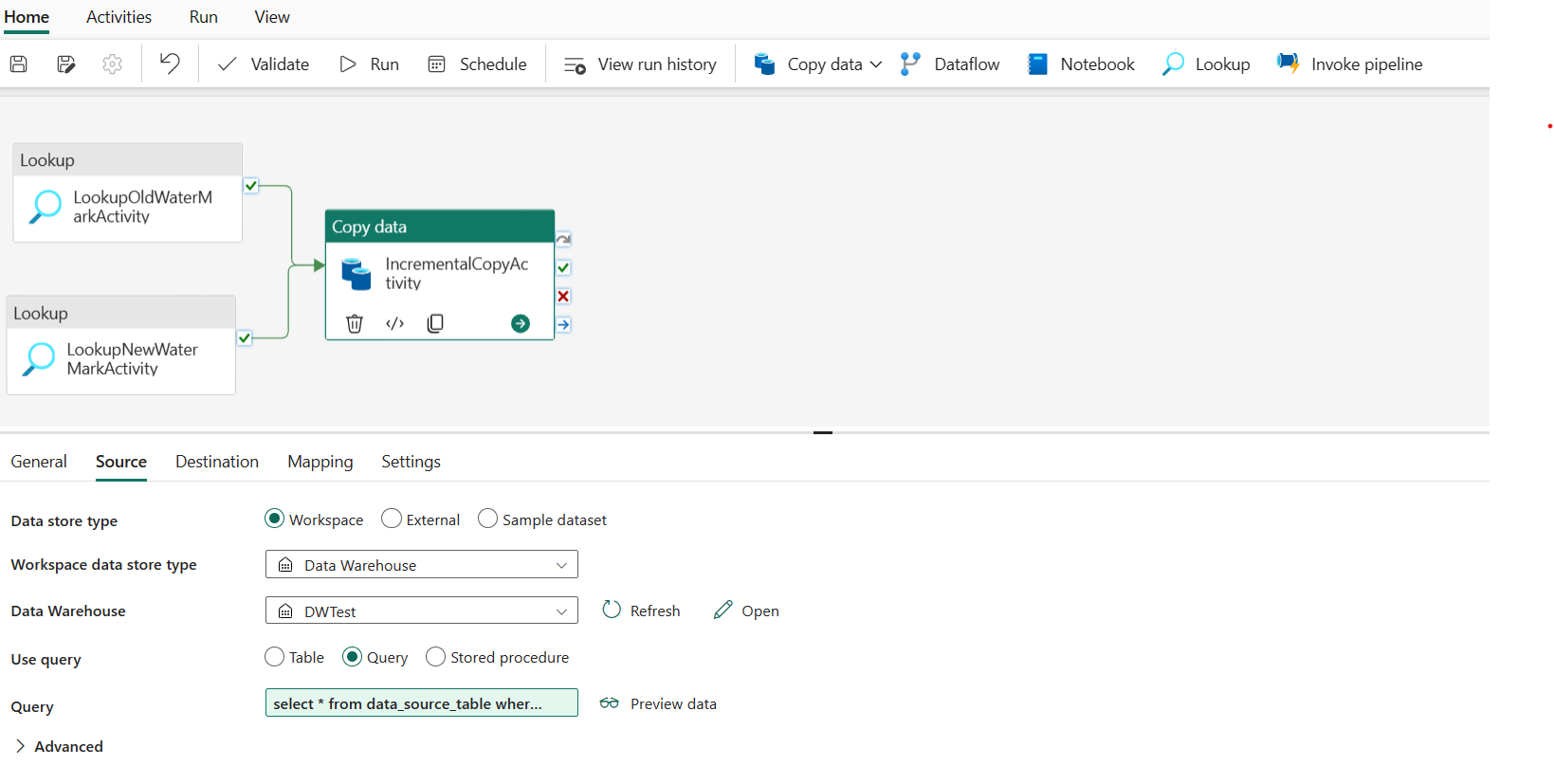
Na guia Origem , execute a seguinte configuração:
Tipo de armazenamento de dados: Selecione Espaço de trabalho.
Tipo de armazenamento de dados do espaço de trabalho: Selecione Data Warehouse.
Data Warehouse: Selecione o seu Data Warehouse.
Usar consulta: escolha Consulta.
Consulta: insira a seguinte consulta para copiar dados incrementais entre a última marca d'água e a nova marca d'água.
select * from data_source_table where LastModifytime > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and LastModifytime <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'
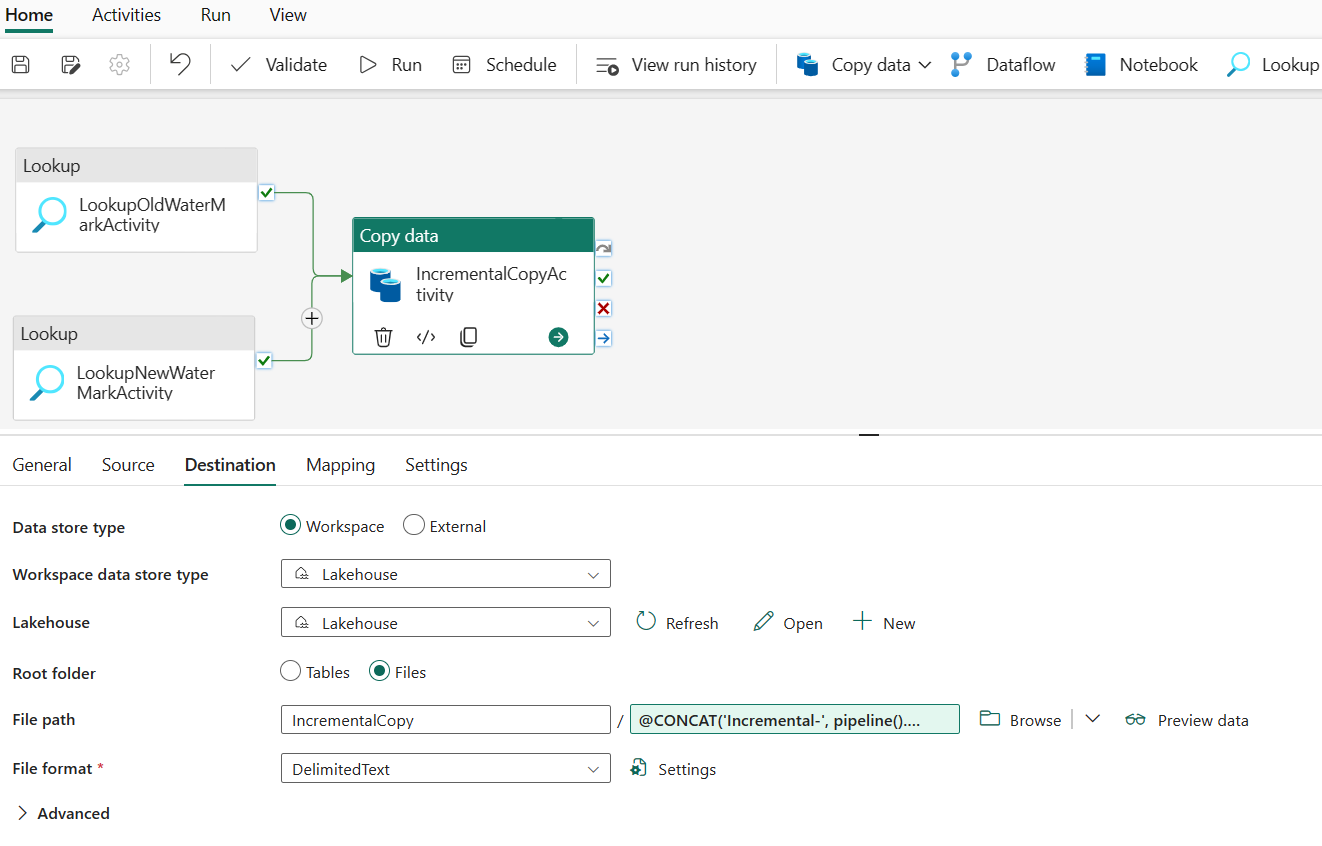
Na guia Destino , execute a seguinte configuração:
- Tipo de armazenamento de dados: Selecione Espaço de trabalho.
- Tipo de armazenamento de dados do espaço de trabalho: Selecione Lakehouse.
- Lakehouse: Selecione sua Lakehouse.
- Pasta raiz: Escolha Arquivos.
- Caminho do arquivo: especifique a pasta que você deseja armazenar os dados copiados. Selecione Procurar para selecionar sua pasta. Para o nome do arquivo, abra Adicionar conteúdo dinâmico e digite
@CONCAT('Incremental-', pipeline().RunId, '.txt')na janela aberta para criar nomes de arquivo para o arquivo de dados copiado no Lakehouse. - Formato de arquivo: Selecione o tipo de formato dos seus dados.
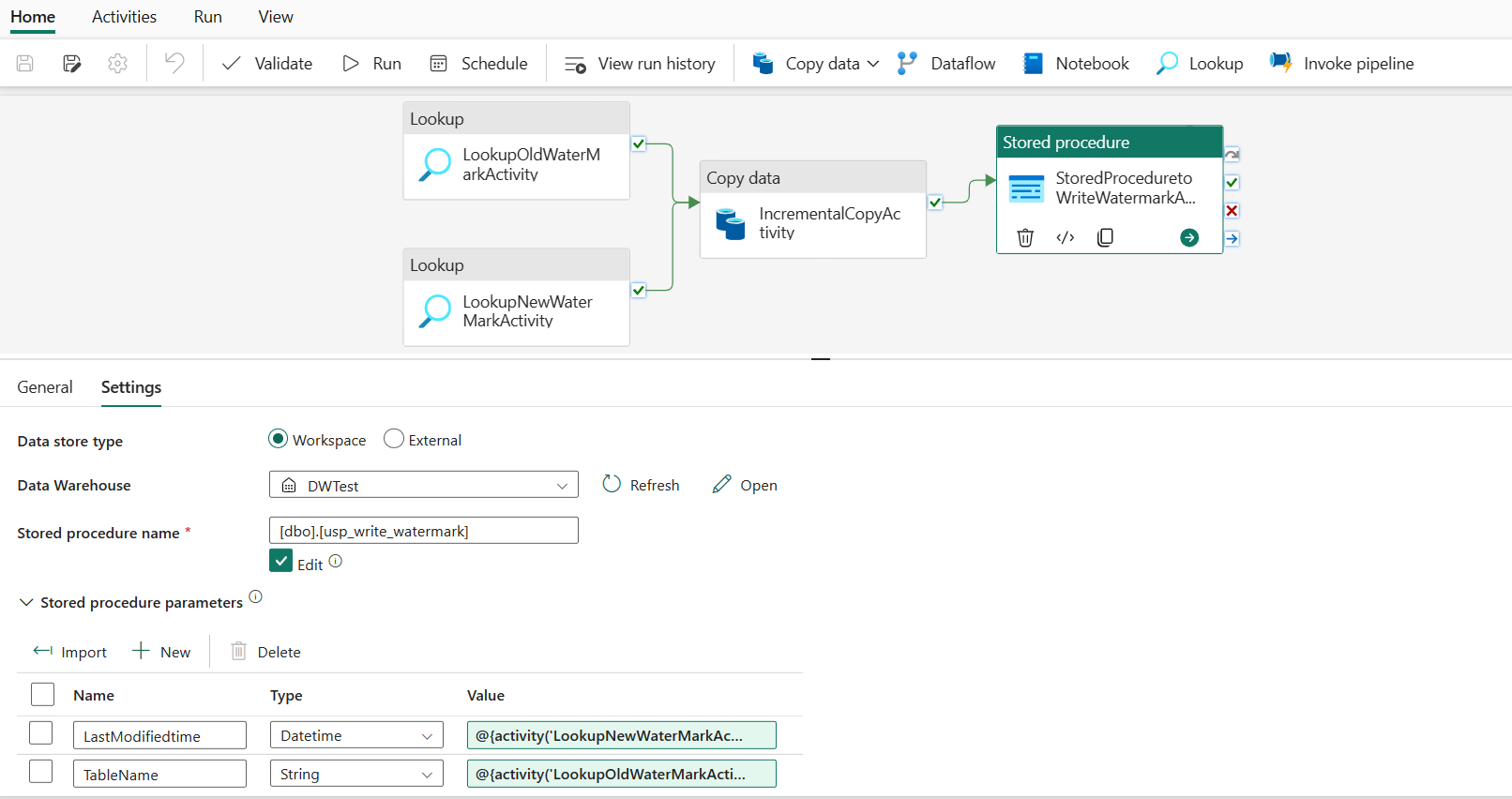
Etapa 5:Adicionar uma atividade de procedimento armazenado
Nesta etapa, você adiciona uma atividade de procedimento armazenado para atualizar o último valor de marca d'água para a próxima execução de pipeline.
Selecione Atividades na barra superior e selecione Procedimento armazenado para adicionar uma atividade de procedimento armazenado.
Na guia Geral , renomeie essa atividade para StoredProceduretoWriteWatermarkActivity.
Conecte a saída verde (Com êxito) da atividade de cópia à atividade de procedimento armazenado.
Na guia Configurações , execute a seguinte configuração:
Tipo de armazenamento de dados: Selecione Espaço de trabalho.
Data Warehouse: Selecione o seu Data Warehouse.
Nome do procedimento armazenado: especifique o procedimento armazenado que você criou no Data Warehouse: [dbo].[ usp_write_watermark].
Expanda Parâmetros de procedimento armazenado. Para especificar valores para os parâmetros do procedimento armazenado, selecione Importar e insira os seguintes valores para os parâmetros:
Nome Tipo valor LastModifiedtime DateTime @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue} TableName String @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}
Etapa 6:Executar o pipeline e monitorar o resultado
Na barra superior, selecione Executar na guia Página Inicial . Em seguida, selecione Salvar e executar. O pipeline começa a ser executado e você pode monitorá-lo na guia Saída .
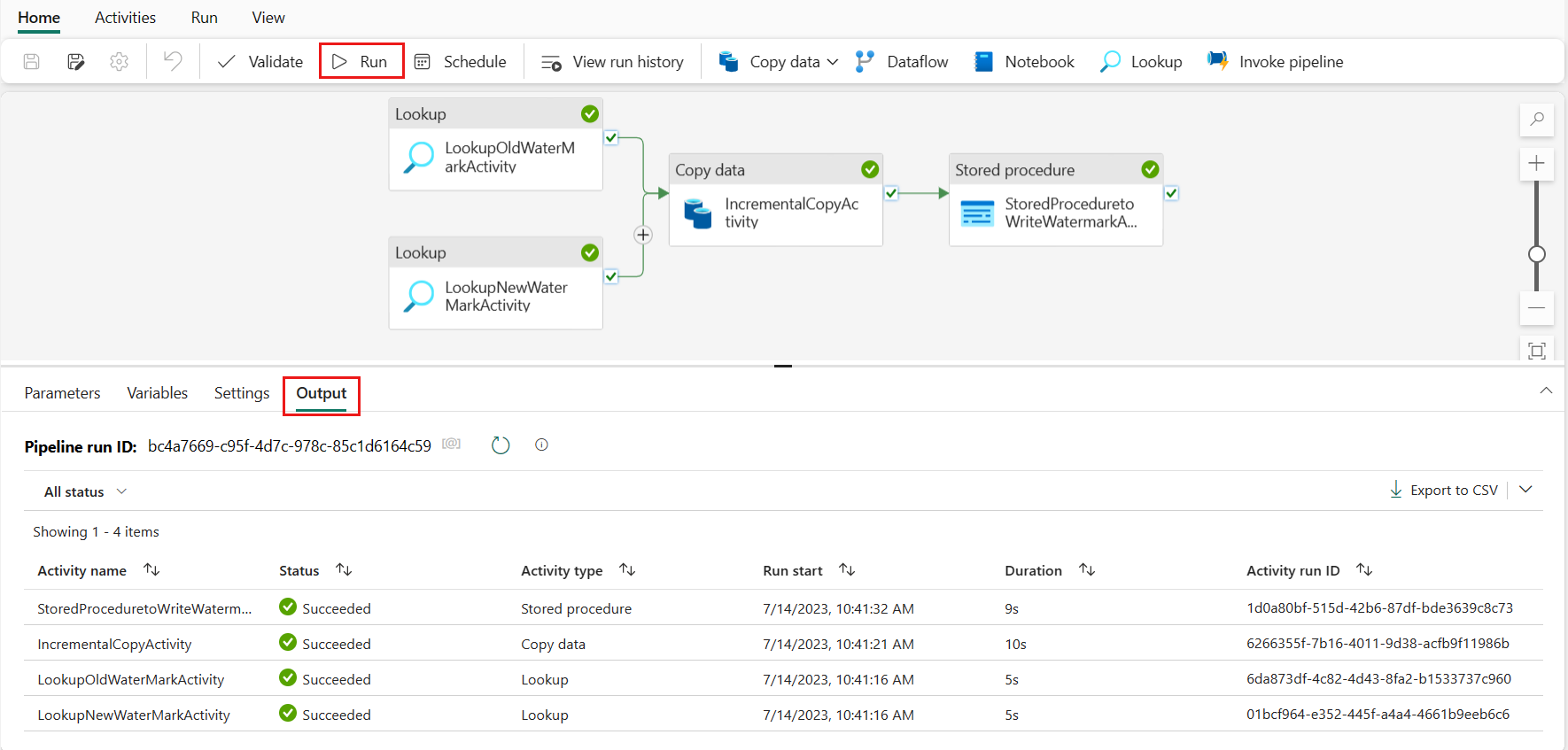
Vá para o seu Lakehouse, você encontra o arquivo de dados está sob a pasta que você especificou e você pode selecionar o arquivo para visualizar os dados copiados.
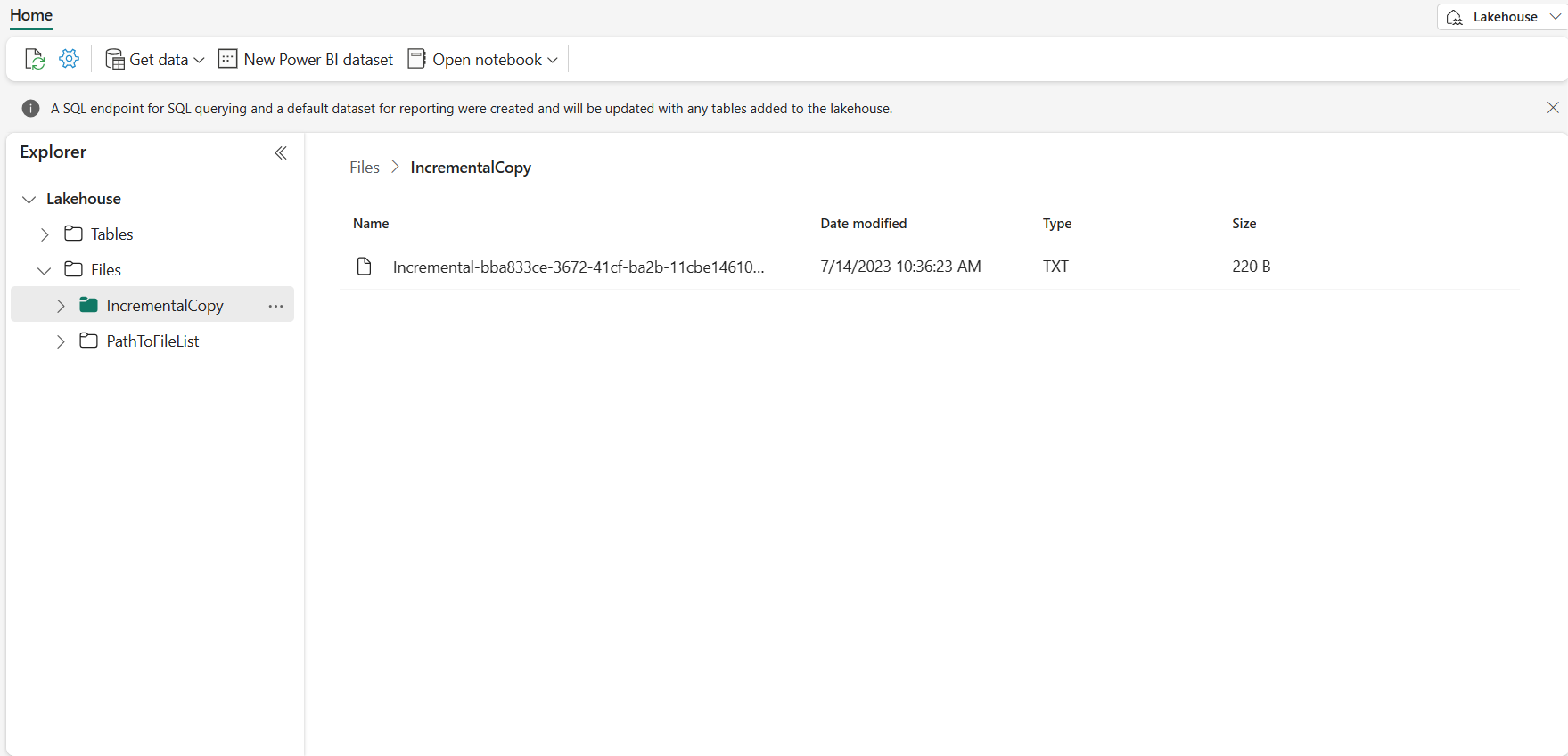
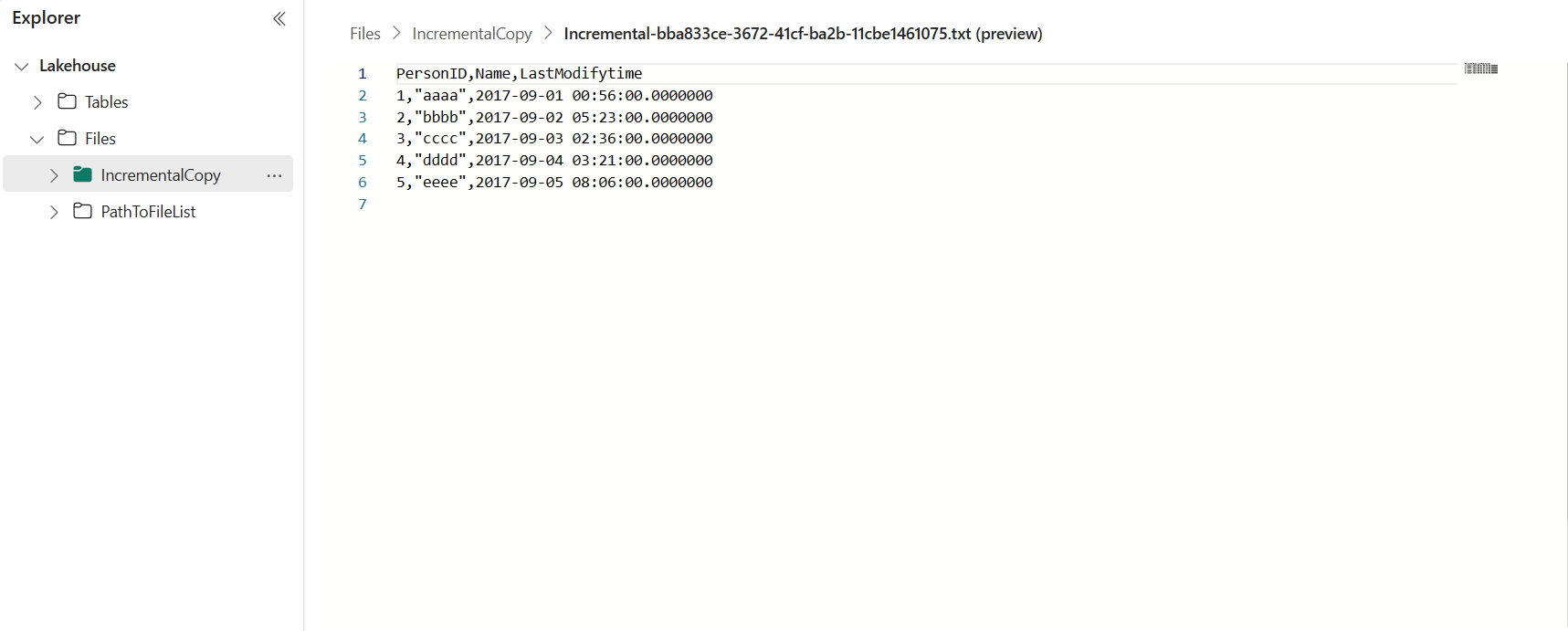
Adicione mais dados para ver os resultados da cópia incremental
Depois de concluir a primeira execução do pipeline, vamos tentar adicionar mais dados na tabela de origem do Data Warehouse para ver se esse pipeline pode copiar seus dados incrementais.
Etapa 1: adicionar mais dados à fonte
Insira novos dados no seu Data Warehouse executando a seguinte consulta:
INSERT INTO data_source_table
VALUES (6, 'newdata','9/6/2017 2:23:00 AM')
INSERT INTO data_source_table
VALUES (7, 'newdata','9/7/2017 9:01:00 AM')
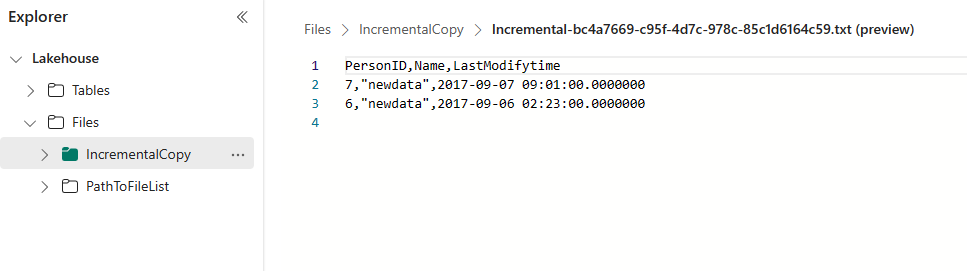
Os dados atualizados para data_source_table são:
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
6 | newdata | 2017-09-06 02:23:00.000
7 | newdata | 2017-09-07 09:01:00.000
Etapa 2:Acionar outra execução de pipeline e monitorar o resultado
Volte para a página do pipeline. Na barra superior, selecione Executar na guia Página Inicial novamente. O pipeline começa a ser executado e você pode monitorá-lo em Saída.
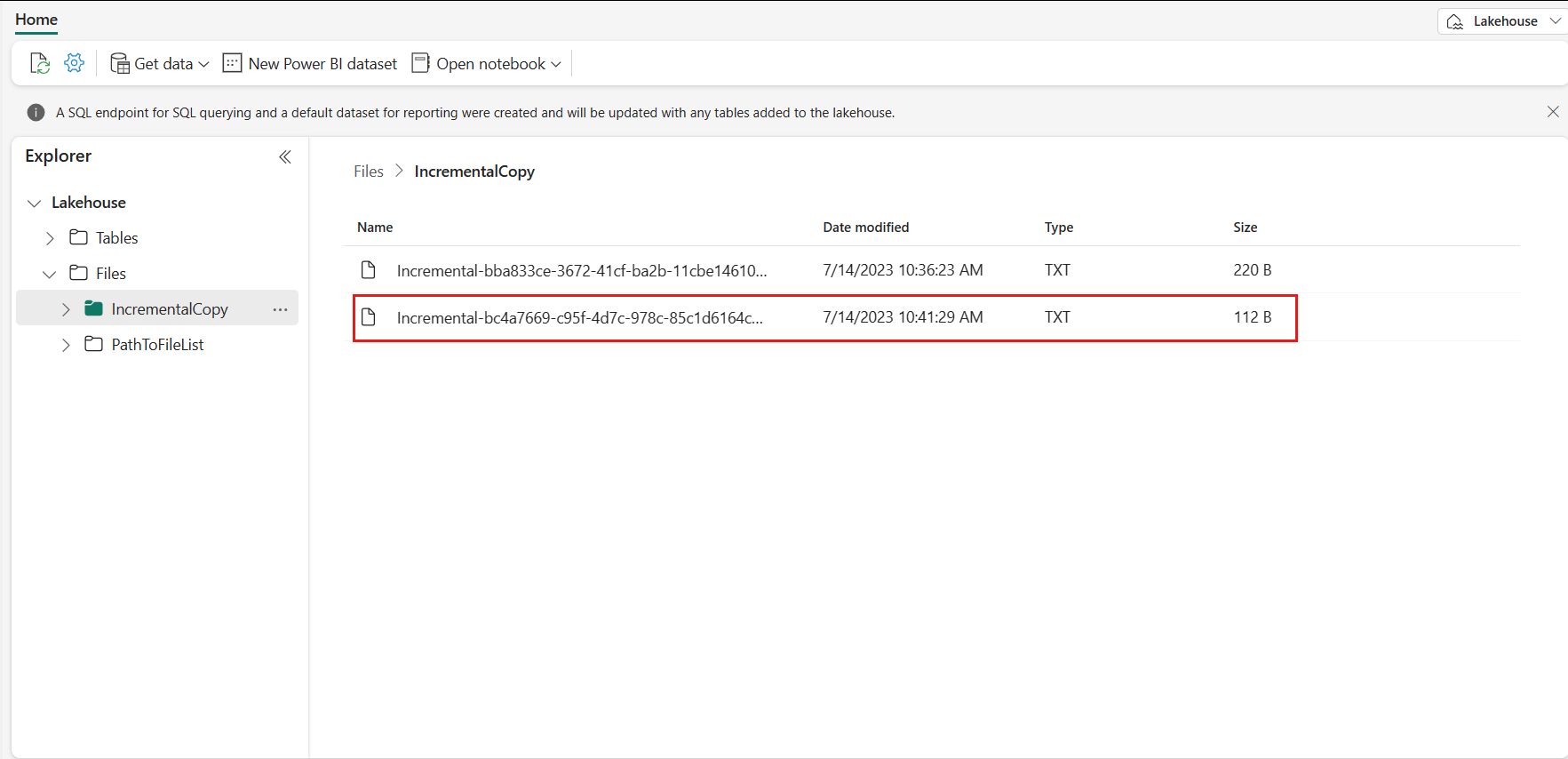
Vá para o seu Lakehouse, você encontra o novo arquivo de dados copiado está sob a pasta que você especificou, e você pode selecionar o arquivo para visualizar os dados copiados. Você vê que seus dados incrementais são mostrados neste arquivo.
Conteúdos relacionados
Em seguida, avance para saber mais sobre a cópia do Armazenamento de Blobs do Azure para o Lakehouse.