Dataflow Gen2 destinos de dados e configurações gerenciadas
Depois de limpar e preparar seus dados com o Dataflow Gen2, você deseja colocar seus dados em um destino. Você pode fazer isso usando os recursos de destino de dados no Dataflow Gen2. Com esse recurso, você pode escolher entre diferentes destinos, como Azure SQL, Fabric Lakehouse e muito mais. O Dataflow Gen2 grava seus dados no destino e, a partir daí, você pode usar seus dados para análises e relatórios adicionais.
A lista a seguir contém os destinos de dados suportados.
- Bancos de dados SQL do Azure
- Azure Data Explorer (Kusto)
- Tecido Lakehouse
- Armazém de Tecidos
- Banco de dados KQL de malha
- Banco de dados SQL de malha
Pontos de entrada
Cada consulta de dados em seu Dataflow Gen2 pode ter um destino de dados. Funções e listas não são suportadas; você só pode aplicá-lo a consultas tabulares. Você pode especificar o destino de dados para cada consulta individualmente e pode usar vários destinos diferentes dentro do fluxo de dados.
Existem três pontos de entrada principais para especificar o destino dos dados:
Através da faixa de opções superior.
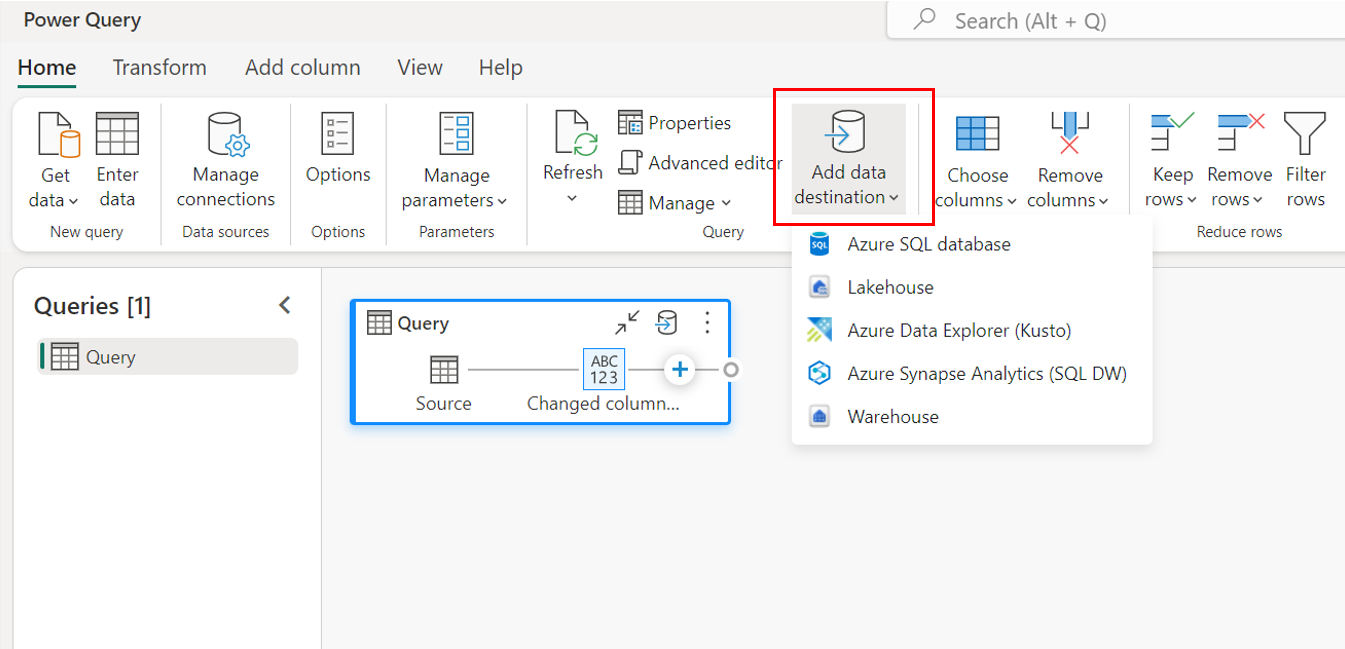
Através de configurações de consulta.
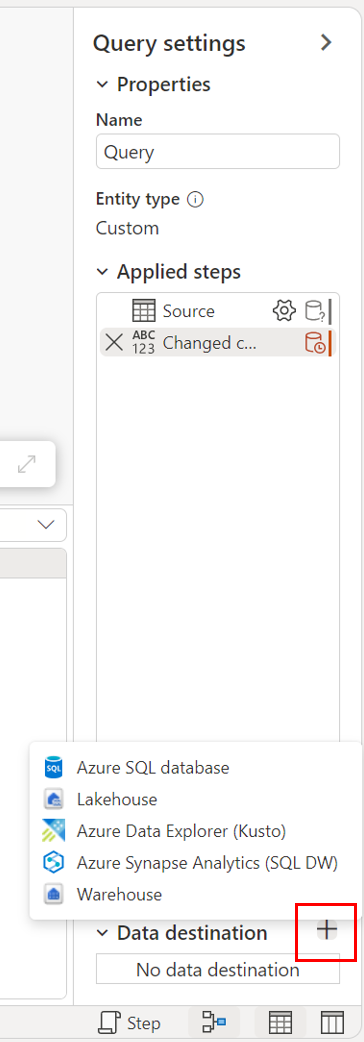
Através da vista de diagrama.
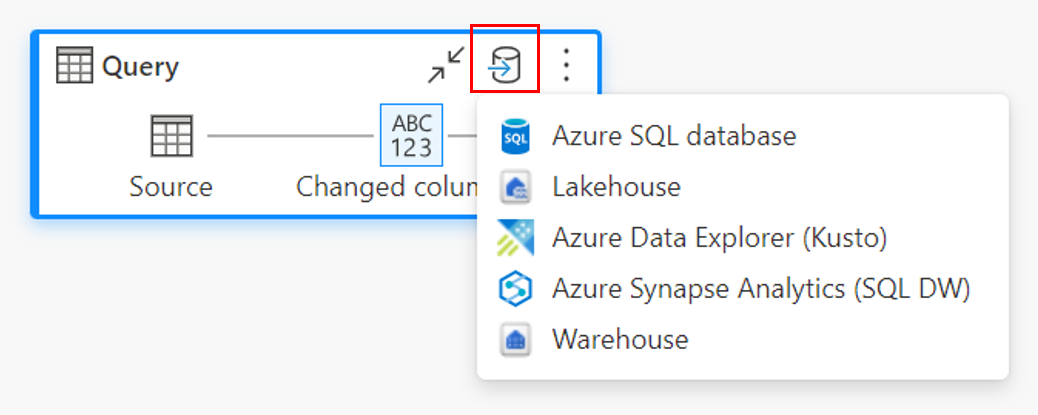
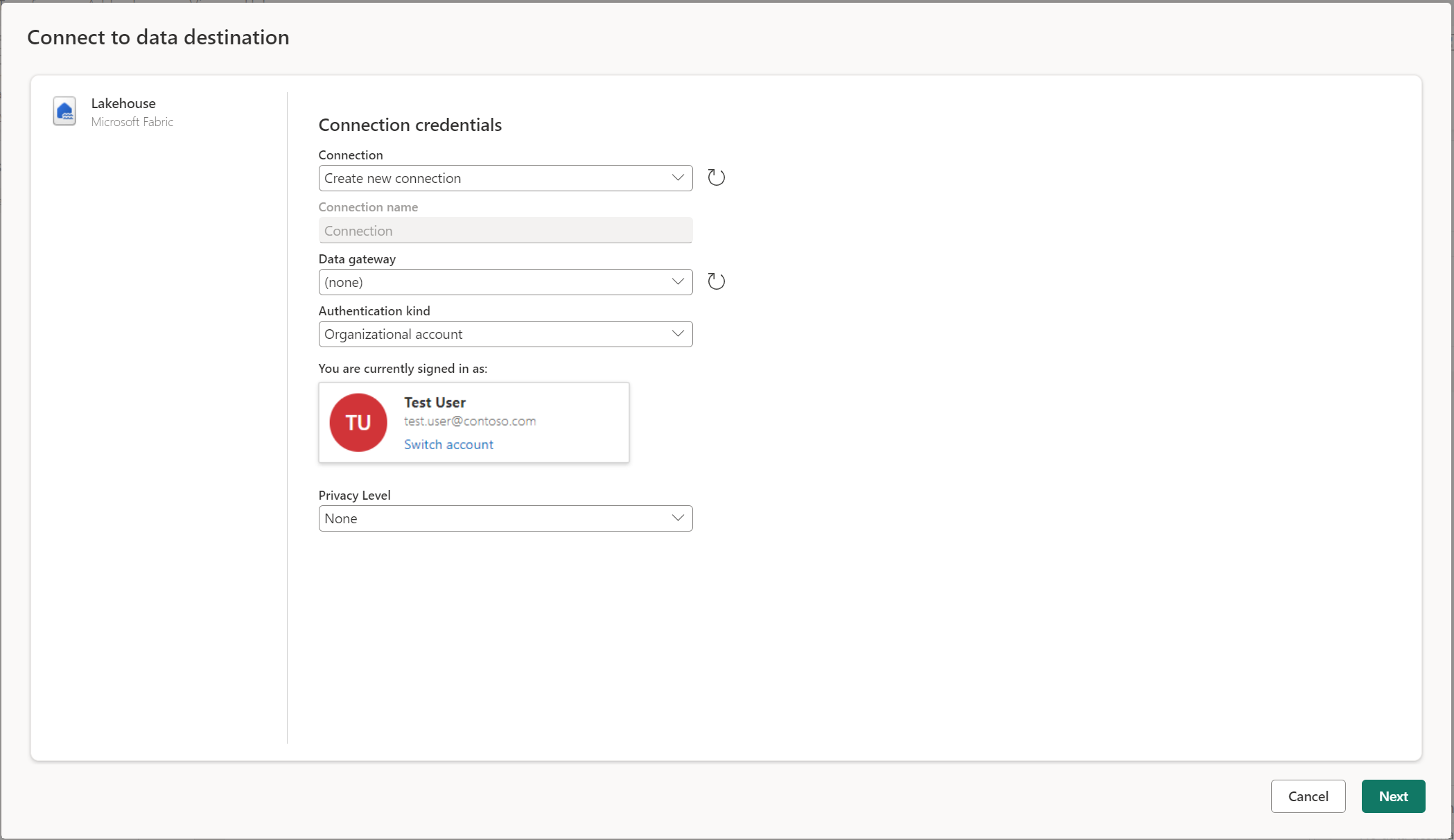
Conectar-se ao destino dos dados
Conectar-se ao destino de dados é semelhante a conectar-se a uma fonte de dados. As conexões podem ser usadas para ler e gravar seus dados, desde que você tenha as permissões certas na fonte de dados. Tem de criar uma nova ligação ou escolher uma ligação existente e, em seguida, selecionar Seguinte.
Criar uma nova tabela ou escolher uma tabela existente
Ao carregar no destino dos dados, você pode criar uma nova tabela ou escolher uma tabela existente.
Criar uma nova tabela
Quando você opta por criar uma nova tabela, durante a atualização do Dataflow Gen2 uma nova tabela é criada no seu destino de dados. Se a tabela for excluída no futuro indo manualmente para o destino, o fluxo de dados recriará a tabela durante a próxima atualização do fluxo de dados.
Por padrão, o nome da tabela tem o mesmo nome que o nome da consulta. Se você tiver caracteres inválidos no nome da tabela que o destino não suporta, o nome da tabela será ajustado automaticamente. Por exemplo, muitos destinos não suportam espaços ou caracteres especiais.
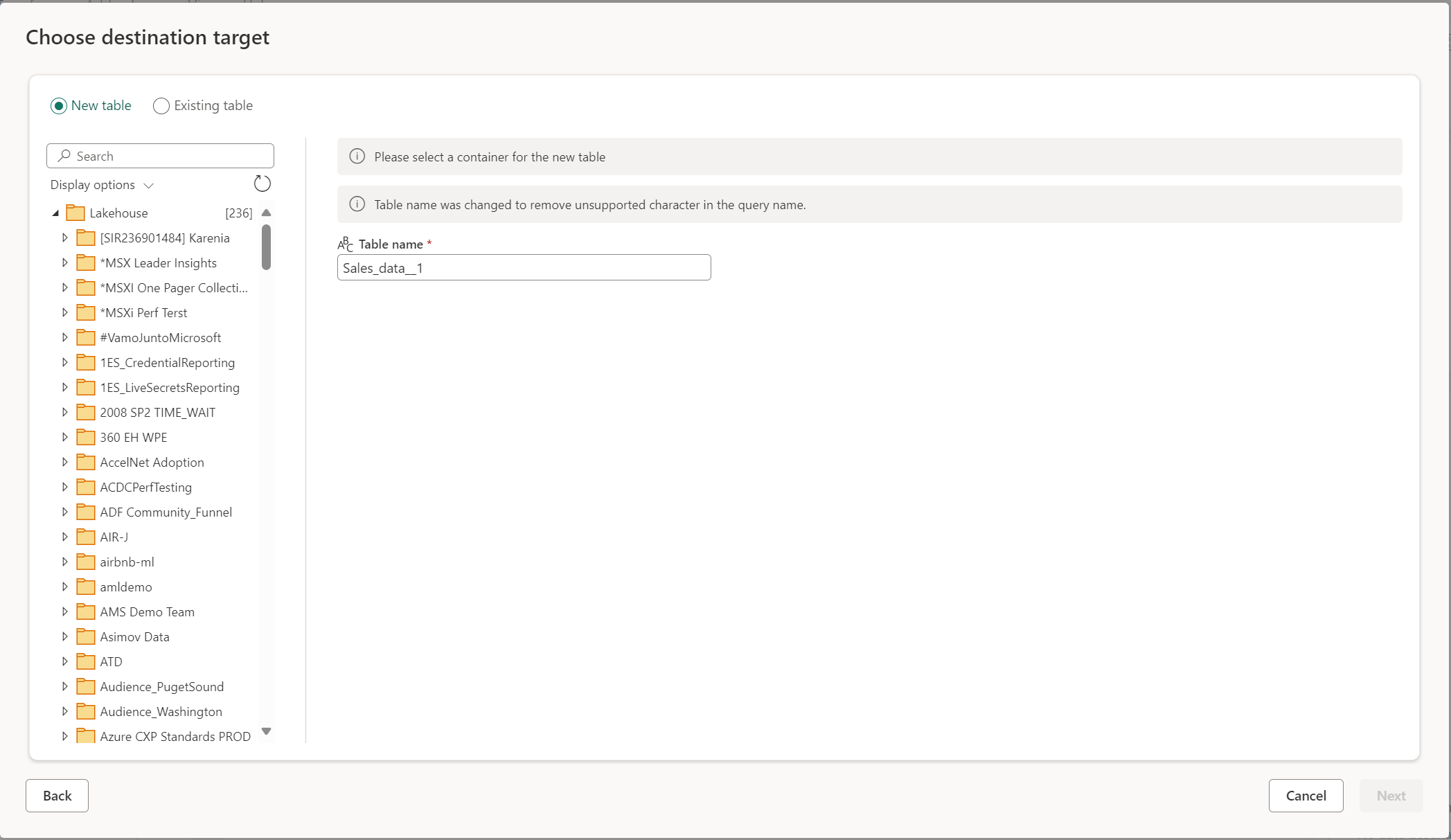
Em seguida, você deve selecionar o contêiner de destino. Se você escolher qualquer um dos destinos de dados de malha, poderá usar o navegador para selecionar o artefato de malha no qual deseja carregar seus dados. Para destinos do Azure, você pode especificar o banco de dados durante a criação da conexão ou selecionar o banco de dados na experiência do navegador.
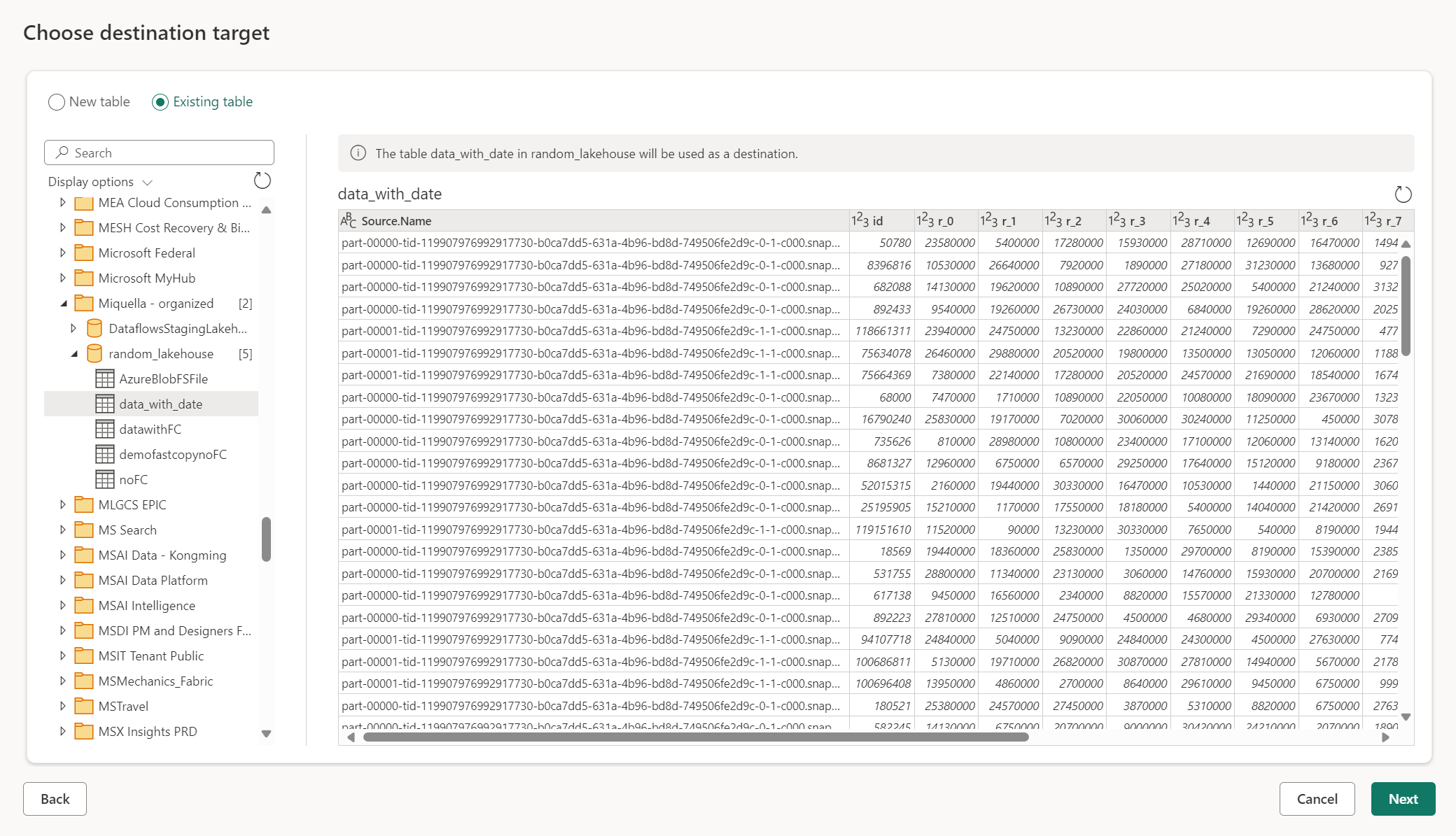
Usar uma tabela existente
Para escolher uma tabela existente, use a alternância na parte superior do navegador. Ao escolher uma tabela existente, você precisa escolher o artefato/banco de dados de malha e a tabela usando o navegador.
Quando você usa uma tabela existente, a tabela não pode ser recriada em nenhum cenário. Se você excluir a tabela manualmente do destino de dados, o Dataflow Gen2 não recriará a tabela na próxima atualização.
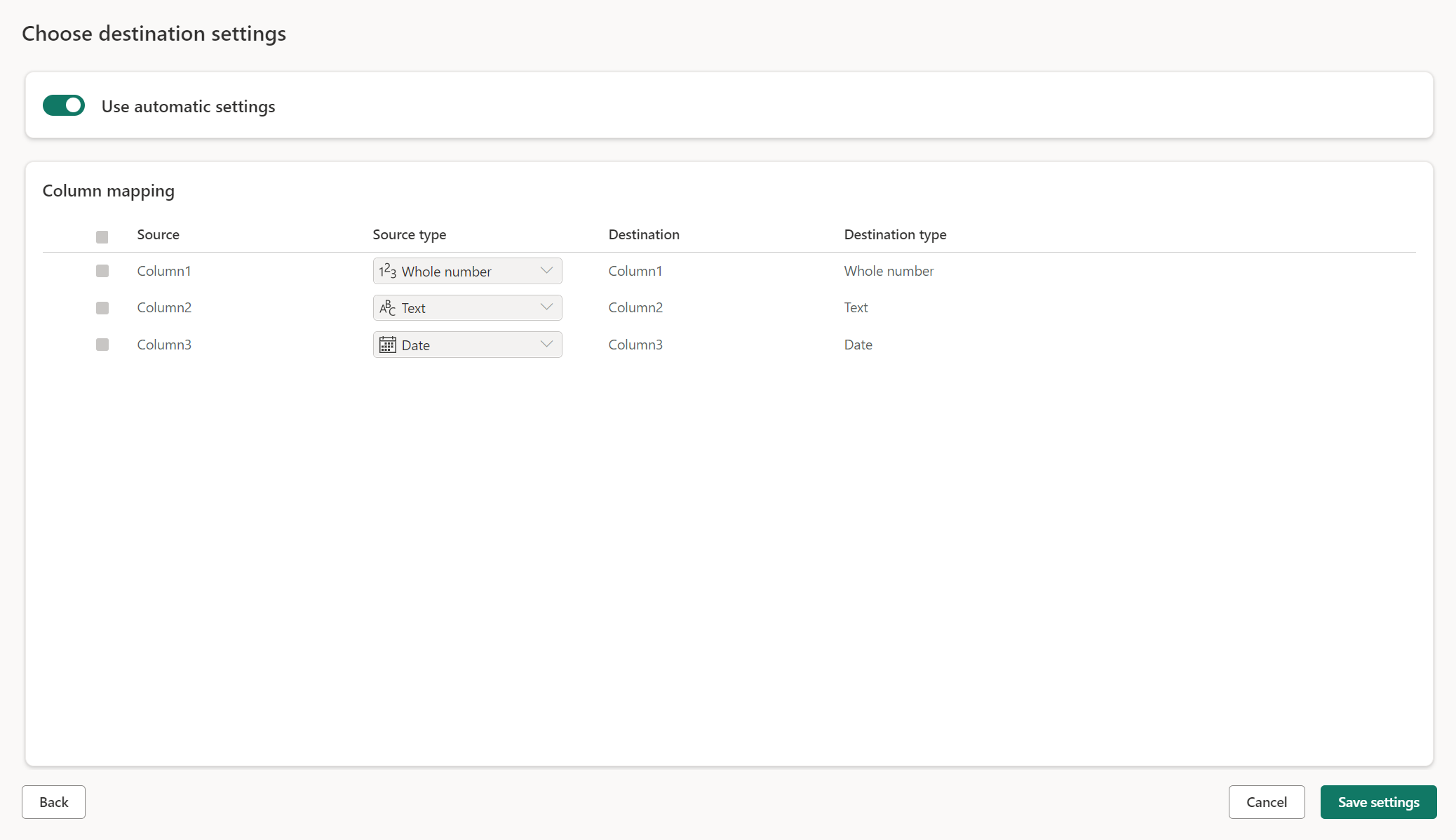
Configurações gerenciadas para novas tabelas
Quando você está carregando em uma nova tabela, as configurações automáticas estão ativadas por padrão. Se você usar as configurações automáticas, o Dataflow Gen2 gerenciará o mapeamento para você. As configurações automáticas fornecem o seguinte comportamento:
Substituição do método de atualização: os dados são substituídos a cada atualização do fluxo de dados. Todos os dados no destino são removidos. Os dados no destino são substituídos pelos dados de saída do fluxo de dados.
Mapeamento gerenciado: o mapeamento é gerenciado para você. Quando você precisa fazer alterações em seus dados/consulta para adicionar outra coluna ou alterar um tipo de dados, o mapeamento é ajustado automaticamente para essa alteração quando você republica seu fluxo de dados. Você não precisa entrar na experiência de destino de dados toda vez que fizer alterações em seu fluxo de dados, permitindo alterações fáceis de esquema quando você republica o fluxo de dados.
Soltar e recriar tabela: para permitir essas alterações de esquema, em cada atualização de fluxo de dados a tabela é descartada e recriada. A atualização do fluxo de dados pode causar a remoção de relações ou medidas que foram adicionadas anteriormente à sua tabela.
Nota
Atualmente, a configuração automática só tem suporte para Lakehouse e banco de dados SQL do Azure como destino de dados.
Configurações manuais
Ao desalternar Usar configurações automáticas, você tem controle total sobre como carregar seus dados no destino dos dados. Você pode fazer alterações no mapeamento de colunas alterando o tipo de origem ou excluindo qualquer coluna que não seja necessária no destino dos dados.
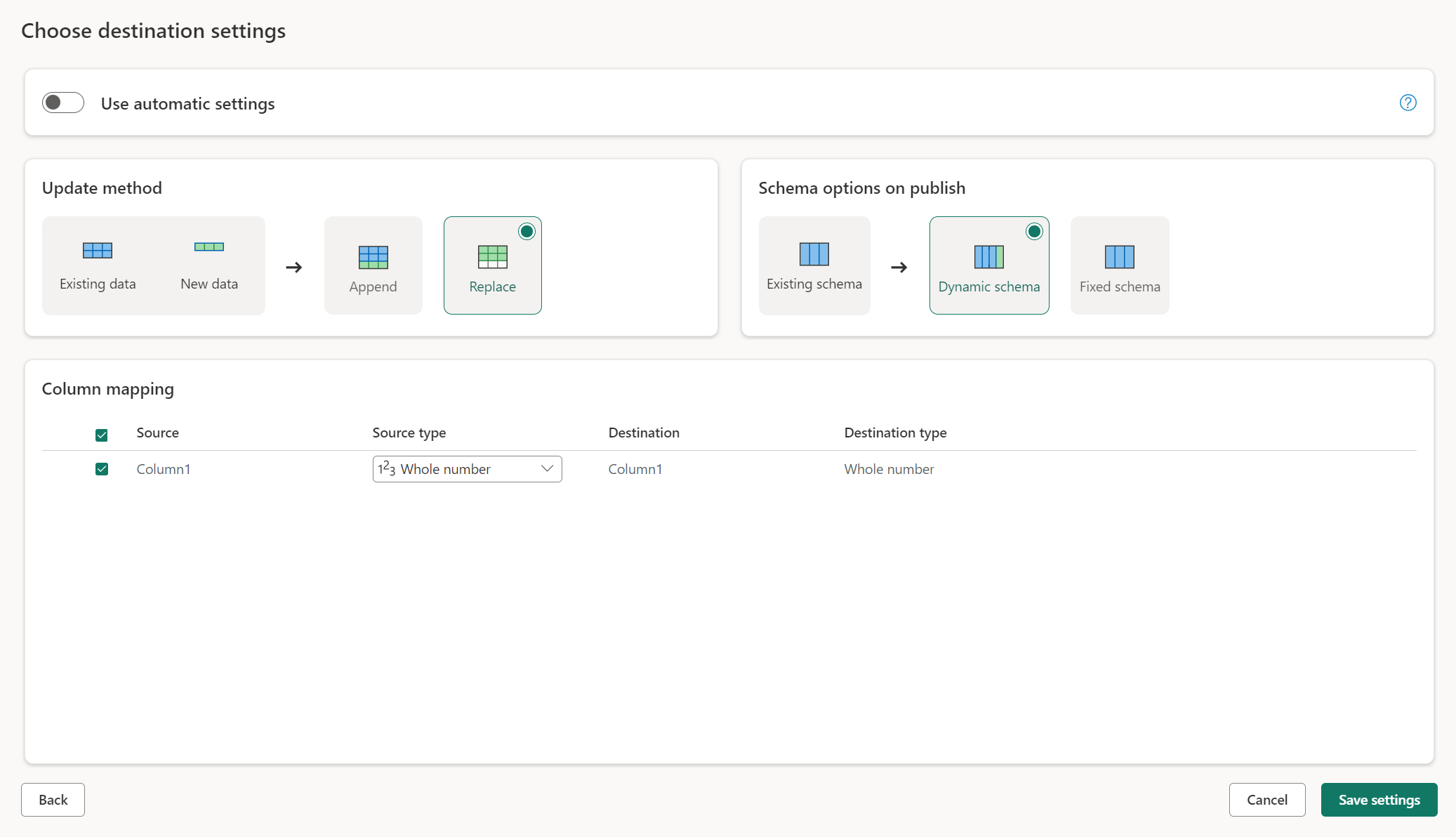
Métodos de atualização
A maioria dos destinos suporta anexar e substituir como métodos de atualização. No entanto, os bancos de dados KQL de malha e o Azure Data Explorer não oferecem suporte à substituição como um método de atualização.
Substituir: em cada atualização de fluxo de dados, seus dados são descartados do destino e substituídos pelos dados de saída do fluxo de dados.
Acrescentar: Em cada atualização de fluxo de dados, os dados de saída do fluxo de dados são acrescentados aos dados existentes na tabela de destino de dados.
Opções de esquema na publicação
As opções de esquema na publicação só se aplicam quando o método de atualização é substituído. Quando você acrescenta dados, as alterações no esquema não são possíveis.
Esquema dinâmico: ao escolher o esquema dinâmico, você permite alterações de esquema no destino dos dados quando republica o fluxo de dados. Como você não está usando o mapeamento gerenciado, ainda precisa atualizar o mapeamento de coluna no fluxo de destino do fluxo de dados quando fizer alterações na consulta. Quando o fluxo de dados é atualizado, sua tabela é descartada e recriada. A atualização do fluxo de dados pode causar a remoção de relações ou medidas que foram adicionadas anteriormente à sua tabela.
Esquema fixo: Quando você escolhe o esquema fixo, as alterações de esquema não são possíveis. Quando o fluxo de dados é atualizado, apenas as linhas na tabela são descartadas e substituídas pelos dados de saída do fluxo de dados. Quaisquer relações ou medidas sobre a mesa permanecem intactas. Se você fizer alterações na consulta no fluxo de dados, a publicação do fluxo de dados falhará se detetar que o esquema de consulta não corresponde ao esquema de destino de dados. Use essa configuração quando não planeja alterar o esquema e ter relações ou medidas adicionadas à sua tabela de destino.
Nota
Ao carregar dados no armazém, apenas o esquema fixo é suportado.
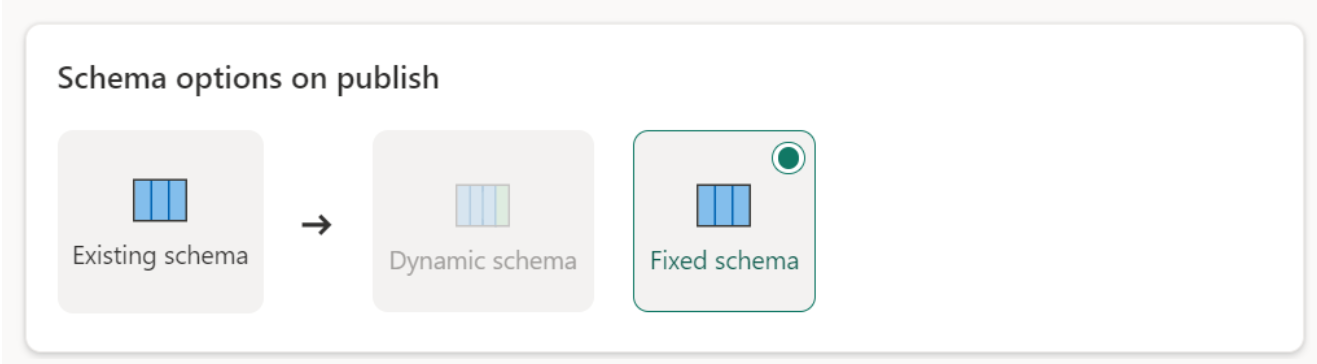
Tipos de fonte de dados suportados por destino
| Tipos de dados suportados por local de armazenamento | DataflowStagingLakehouse | Saída do Azure DB (SQL) | Saída do Azure Data Explorer | Saída Fabric Lakehouse (LH) | Saída de armazém de tecido (WH) | Saída do Banco de Dados SQL de Malha (SQL) |
|---|---|---|---|---|---|---|
| Ação | No | No | No | No | No | Não |
| Qualquer | No | No | No | No | No | Não |
| Binário | No | No | No | No | No | Não |
| Moeda | Sim | Sim | Sim | Sim | No | Sim |
| DateTimeZone | Sim | Sim | Sim | No | No | Sim |
| Duration | No | No | Sim | No | No | Não |
| Function | No | No | No | No | No | Não |
| Nenhuma | No | No | No | No | No | Não |
| Nulo | No | No | No | No | No | Não |
| Hora | Sim | Sim | No | No | No | Sim |
| Type | No | No | No | No | No | Não |
| Estruturado (Lista, Registo, Tabela) | No | No | No | No | No | Não |
Tópicos avançados
Usando o preparo antes de carregar para um destino
Para melhorar o desempenho do processamento de consultas, o preparo pode ser usado no Dataflows Gen2 para usar a computação de malha para executar suas consultas.
Quando o preparo é habilitado em suas consultas (o comportamento padrão), seus dados são carregados no local de preparação, que é um Lakehouse interno acessível apenas pelos próprios fluxos de dados.
O uso de locais de preparo pode melhorar o desempenho em alguns casos em que dobrar a consulta para o ponto de extremidade de análise SQL é mais rápido do que no processamento de memória.
Quando você está carregando dados no Lakehouse ou em outros destinos que não sejam de depósito, por padrão, desativamos o recurso de preparo para melhorar o desempenho. Quando você carrega dados no destino de dados, os dados são gravados diretamente no destino de dados sem usar preparo. Se quiser usar o preparo para sua consulta, você pode habilitá-lo novamente.
Para habilitar o preparo, clique com o botão direito do mouse na consulta e habilite o preparo selecionando o botão Habilitar preparo . Em seguida, a sua consulta fica azul.
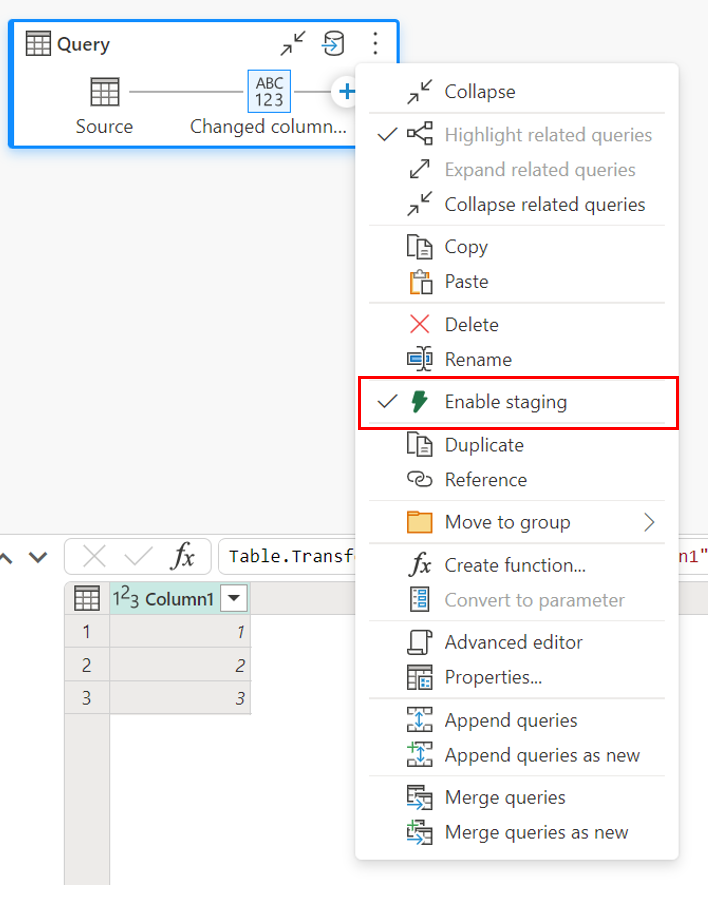
Carregando dados no Armazém
Quando você carrega dados no Warehouse, o preparo é necessário antes da operação de gravação no destino dos dados. Este requisito melhora o desempenho. Atualmente, apenas o carregamento no mesmo espaço de trabalho que o fluxo de dados é suportado. Verifique se o preparo está habilitado para todas as consultas que são carregadas no depósito.
Quando o preparo está desativado e você escolhe Depósito como destino de saída, você recebe um aviso para habilitar o preparo primeiro antes de configurar o destino dos dados.
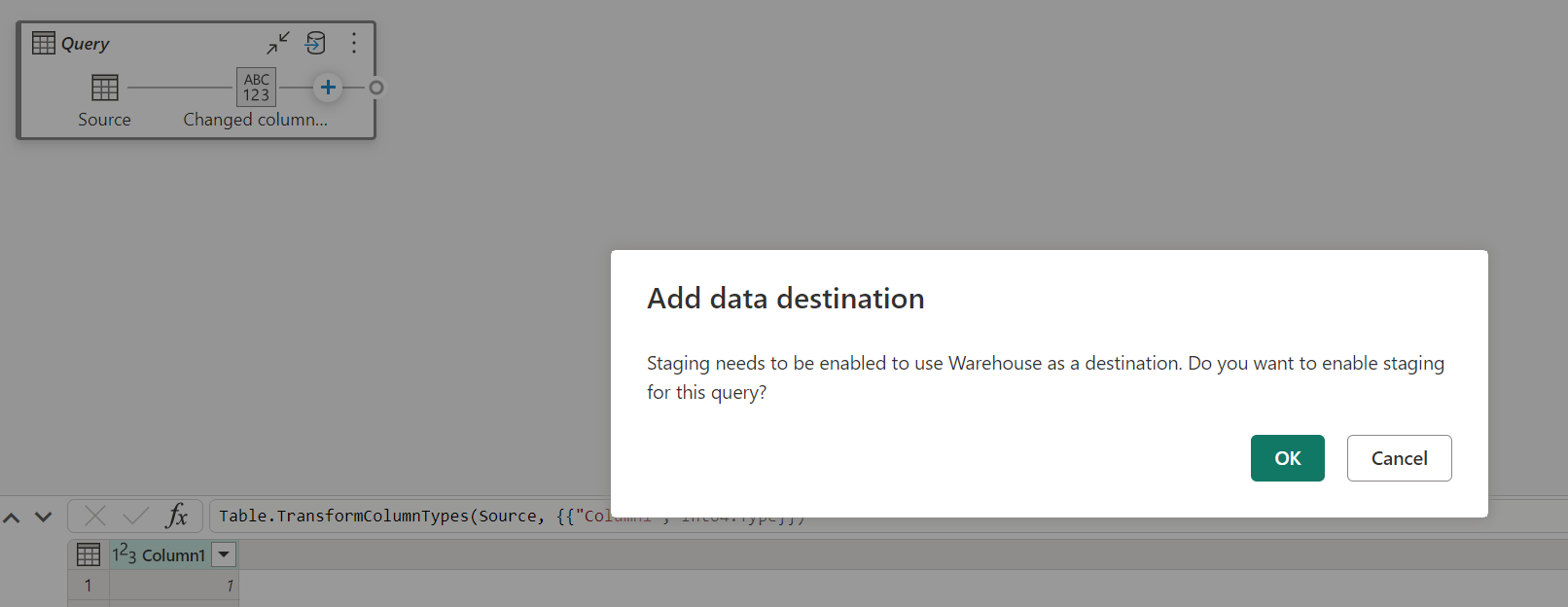
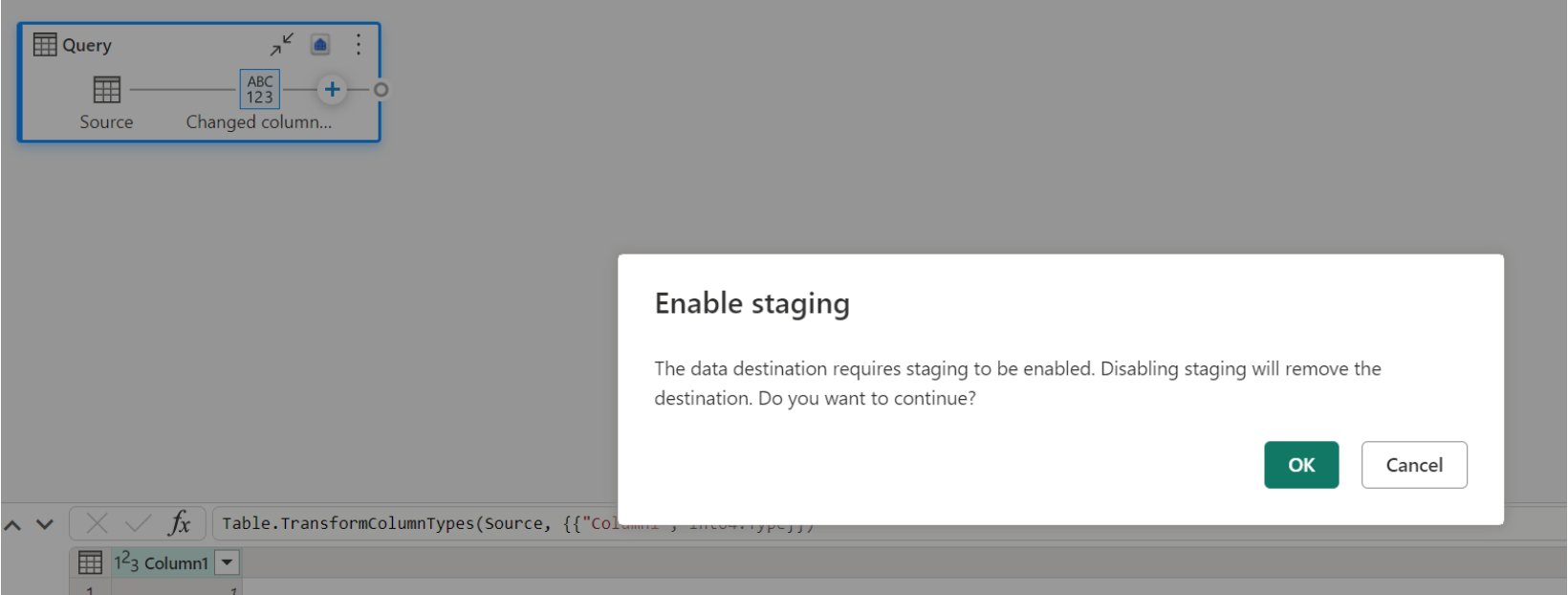
Se você já tiver um depósito como destino e tentar desativar a preparação, um aviso será exibido. Você pode remover o depósito como destino ou descartar a ação de preparação.
Aspirando seu destino de dados Lakehouse
Ao usar o Lakehouse como destino para o Dataflow Gen2 no Microsoft Fabric, é crucial realizar manutenção regular para garantir o desempenho ideal e o gerenciamento eficiente do armazenamento. Uma tarefa de manutenção essencial é aspirar o destino dos seus dados. Esse processo ajuda a remover arquivos antigos que não são mais referenciados pelo log da tabela Delta, otimizando assim os custos de armazenamento e mantendo a integridade dos seus dados.
Por que aspirar é importante
- Otimização de armazenamento: com o tempo, as tabelas Delta acumulam arquivos antigos que não são mais necessários. A aspiração ajuda a limpar esses arquivos, liberando espaço de armazenamento e reduzindo custos.
- Melhoria de desempenho: A remoção de arquivos desnecessários pode melhorar o desempenho da consulta, reduzindo o número de arquivos que precisam ser verificados durante as operações de leitura.
- Integridade dos dados: Garantir que apenas os arquivos relevantes sejam retidos ajuda a manter a integridade dos seus dados, evitando possíveis problemas com arquivos não confirmados que podem levar a falhas de leitura ou corrupção de tabelas.
Como aspirar o destino dos seus dados
Para aspirar suas mesas Delta no Lakehouse, siga estas etapas:
- Navegue até sua Lakehouse: Na sua conta do Microsoft Fabric, vá para a Lakehouse desejada.
- Manutenção da tabela de acesso: No Lakehouse explorer, clique com o botão direito do mouse na tabela que deseja manter ou use as reticências para acessar o menu contextual.
- Selecione as opções de manutenção: Escolha a entrada do menu Manutenção e selecione a opção Vácuo .
- Execute o comando vacuum: defina o limite de retenção (o padrão é sete dias) e execute o comando vacuum selecionando Executar agora.
Melhores práticas
- Período de retenção: defina um intervalo de retenção de pelo menos sete dias para garantir que instantâneos antigos e arquivos não confirmados não sejam removidos prematuramente, o que pode interromper leitores e gravadores de tabelas simultâneos.
- Manutenção regular: Agende aspiradores regulares como parte de sua rotina de manutenção de dados para manter suas tabelas Delta otimizadas e prontas para análises.
Ao incorporar o vácuo em sua estratégia de manutenção de dados, você pode garantir que seu destino Lakehouse permaneça eficiente, econômico e confiável para suas operações de fluxo de dados.
Para obter informações mais detalhadas sobre a manutenção de tabelas em Lakehouse, consulte a documentação de manutenção de tabelas Delta.
Pode ser nulo
Em alguns casos, quando você tem uma coluna anulável, ela é detetada pelo Power Query como não anulável e, ao gravar no destino dos dados, o tipo de coluna não é anulável. Durante a atualização, ocorre o seguinte erro:
E104100 Couldn't refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table's content with new data in a version: #{0}., InnerException: We can't insert null data into a non-nullable column., Underlying error: We can't insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can't insert null data into a non-nullable column.; Message.Format = we can't insert null data into a non-nullable column.
Para forçar colunas anuláveis, você pode tentar as seguintes etapas:
Exclua a tabela do destino dos dados.
Remova o destino dos dados do fluxo de dados.
Vá para o fluxo de dados e atualize os tipos de dados usando o seguinte código do Power Query:
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )Adicione o destino dos dados.
Conversão e escalonamento de tipos de dados
Em alguns casos, o tipo de dados dentro do fluxo de dados difere do que é suportado no destino de dados abaixo estão algumas conversões padrão que implementamos para garantir que você ainda seja capaz de obter seus dados no destino de dados:
| Destino | Tipo de dados de fluxo de dados | Tipo de dados de destino |
|---|---|---|
| Armazém de Tecidos | Int8.Type | Int16.Type |