Configurar a Base de Dados do Azure para PostgreSQL numa atividade de cópia
Este artigo descreve como usar a atividade de cópia no pipeline de dados para copiar dados de e para o Banco de Dados do Azure para PostgreSQL.
Configuração suportada
Para configurar cada separador na atividade de cópia, vá respetivamente para as seções a seguir.
Geral
Consulte as definições orientações sobre Geral do
Fonte
Vá para o separador Source para configurar a sua fonte de atividade de cópia. Consulte o conteúdo a seguir para obter a configuração detalhada.
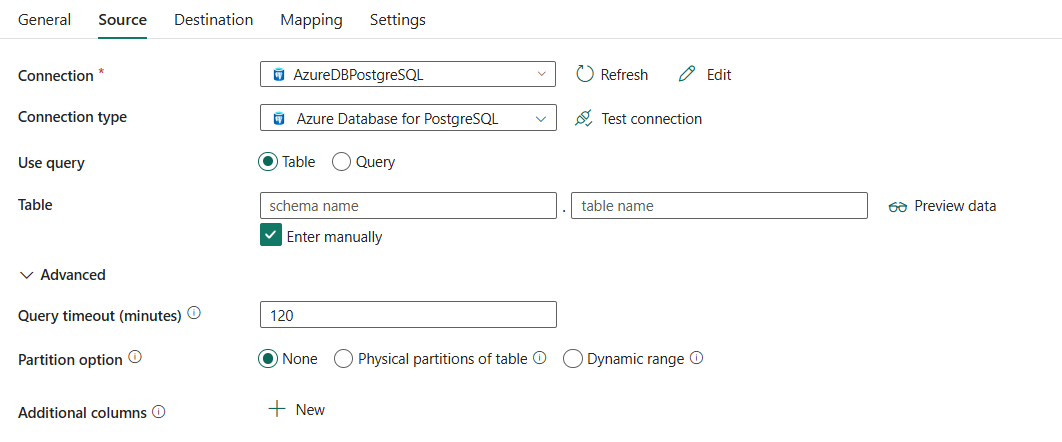
As três propriedades seguintes são obrigatórias:
- Conexão: Selecione um Azure Database para PostgreSQL da lista de conexões. Se não houver conexão, crie um novo Banco de Dados do Azure para conexão PostgreSQL.
- Tipo de conexão: Selecione Banco de Dados do Azure para PostgreSQL.
-
Use a consulta: Selecione a Tabela para ler dados da tabela especificada ou selecione a Consulta para ler dados usando consultas.
Se você selecionar Tabela:
Tabela: Selecione a tabela na lista suspensa ou selecione Introduzir manualmente para introduzi-la manualmente e ler os dados.

Se você selecionar Consulta:
Query: especifique a consulta SQL personalizada para ler dados. Por exemplo:
SELECT * FROM mytableouSELECT * FROM "MyTable".Observação
No PostgreSQL, o nome da entidade é tratado como insensível a maiúsculas e minúsculas se não for citado.

Em Avançado , você pode especificar os seguintes campos:
Tempo limite da consulta (minutos): Especifique o tempo de espera antes de encerrar a tentativa de executar um comando e gerar um erro, o padrão é 120 minutos. Se o parâmetro for definido para essa propriedade, os valores permitidos serão de intervalo de tempo, como "02:00:00" (120 minutos). Para obter mais informações, consulte CommandTimeout.
Opção de Partição: Especifica as opções de particionamento de dados usadas para carregar os dados do Banco de Dados do Azure para PostgreSQL. Quando uma opção de partição está ativada (ou seja, não Nenhum), o grau de paralelismo para carregar dados simultaneamente de uma Base de Dados do Azure para PostgreSQL é controlado pelo Grau de paralelismo de cópia na aba de Configurações da atividade de cópia.
Se você selecionar Nenhum, você opta por não usar a partição.
Se você selecionar partições físicas da tabela:
Nomes de partições: Especifique a lista de partições físicas que precisam ser copiadas.
Se utilizar uma consulta para recuperar os dados de origem, inclua
?AdfTabularPartitionNamena cláusula WHERE. Para obter um exemplo, consulte a seção Cópia paralela do Banco de Dados do Azure para PostgreSQL .
Se selecionares Intervalo dinâmico:
Nome da coluna de partição: Especifique o nome da coluna de origem do tipo inteiro ou data/datetime (
int,smallint,bigint,date,timestamp without time zone,timestamp with time zoneoutime without time zone) que será usado pelo particionamento de intervalo para cópia paralela. Se não for especificado, a chave primária da tabela será detetada automaticamente e usada como coluna de partição.Se utilizar uma consulta para recuperar os dados de origem, insira
?AdfRangePartitionColumnNamena cláusula WHERE. Para obter um exemplo, consulte a seção Cópia Paralela do Azure Database for PostgreSQL.Limite superior da partição: Especifique o valor máximo da coluna de partição para copiar dados para fora.
Se usar uma consulta para recuperar os dados de origem, inclua o
?AdfRangePartitionUpboundna cláusula WHERE. Para obter um exemplo, consulte a seção Cópia Paralela do Banco de Dados do Azure para PostgreSQL. .Partition lower bound: especifique o valor mínimo da coluna de partição para extrair os dados.
Se utilizar uma consulta para recuperar os dados de origem, incorpore
?AdfRangePartitionLowboundna cláusula WHERE. Para obter um exemplo, consulte a seção cópia paralela do Banco de Dados do Azure para PostgreSQL .
Colunas adicionais: Adicione colunas de dados adicionais para armazenar o caminho relativo ou o valor estático dos arquivos de origem. A expressão é suportada para este último.
Destino
Vá para o separador de Destino para configurar o destino da atividade de cópia. Consulte o conteúdo a seguir para obter a configuração detalhada.
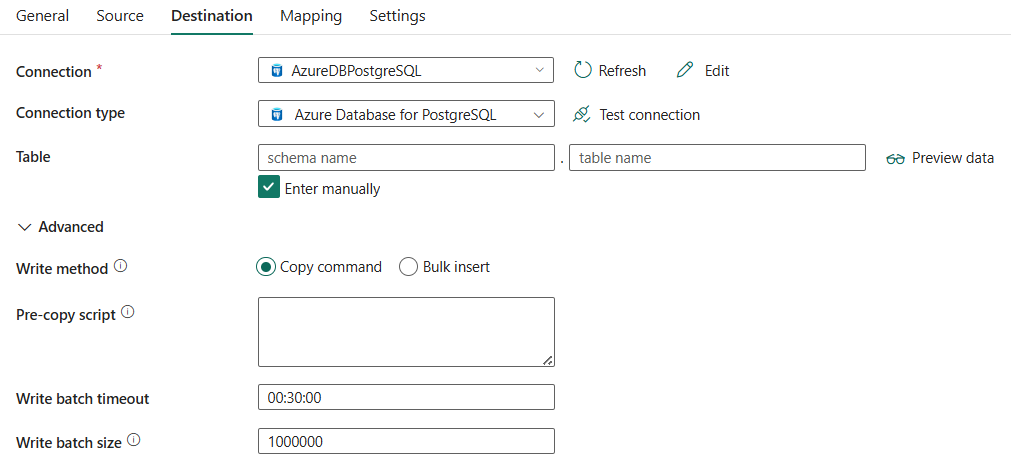
As seguintes três propriedades são necessárias:
- Conexão: Selecione uma conexão do Azure Database para PostgreSQL na lista de conexões. Se não houver conexão, crie um novo Banco de Dados do Azure para conexão PostgreSQL.
- Tipo de conexão: Selecione Banco de Dados do Azure para PostgreSQL.
- Tabela: Selecione a tabela na lista suspensa ou selecione Inserir manualmente para inseri-la e gravar dados.
Em Avançado , você pode especificar os seguintes campos:
Método Write: Selecione o método usado para gravar dados no Banco de Dados do Azure para PostgreSQL. Selecione a partir do comando Copiar (padrão, com melhor desempenho) e Inserção em massa.
de script de pré-cópia: especifique uma consulta SQL para a atividade de cópia que deverá ser executada antes de gravar dados no Azure Database para PostgreSQL em cada execução. Você pode usar essa propriedade para limpar os dados pré-carregados.
Write batch timeout: Especifique o tempo de espera para que a operação de inserção em lote termine antes de atingir o tempo limite. O valor permitido é um intervalo de tempo. O valor padrão é 00:30:00 (30 minutos).
Tamanho do lote de gravação: especifique o número de linhas carregadas no Banco de Dados do Azure para PostgreSQL por lote. O valor permitido é um número inteiro que representa o número de linhas. O valor padrão é 1.000.000.
Mapeamento
Para configuração da guia Mapeamento, consulte Configurar seus mapeamentos na guia Mapeamento.
Configurações
Para a configuração do separador Configurações, vá para Configure as suas outras definições no separador Configurações.
Cópia paralela do Banco de Dados do Azure para PostgreSQL
O conector do Banco de Dados do Azure para PostgreSQL na atividade de cópia fornece particionamento de dados interno para copiar dados em paralelo. Você pode encontrar opções de particionamento de dados no separador Origem da atividade de cópia.
Quando você habilita a cópia particionada, a atividade de cópia executa consultas paralelas no Banco de Dados do Azure para a fonte PostgreSQL para carregar dados por partições. O grau paralelo é controlado pelo Grau de paralelismo de cópia na guia de configurações de atividade de cópia. Por exemplo, se você definir Grau de paralelismo de cópia para quatro, o serviço gerará e executará simultaneamente quatro consultas com base na opção e nas configurações de partição especificadas, e cada consulta recuperará uma parte dos dados do Banco de Dados do Azure para PostgreSQL.
Sugere-se que você habilite a cópia paralela com particionamento de dados, especialmente quando carrega uma grande quantidade de dados do Banco de Dados do Azure para PostgreSQL. A seguir estão sugeridas configurações para diferentes cenários. Ao copiar dados para o armazenamento de dados baseado em arquivo, é recomendável gravar em uma pasta como vários arquivos (especifique apenas o nome da pasta), caso em que o desempenho é melhor do que gravar em um único arquivo.
| Cenário | Configurações sugeridas |
|---|---|
| Carga completa a partir de uma tabela grande, com partições físicas. |
Partition option: Partições físicas da tabela. Durante a execução, o serviço deteta automaticamente as partições físicas e copia os dados por partições. |
| Carga completa de uma tabela grande, sem partições físicas, mas com uma coluna do tipo inteiro para particionamento de dados. |
Opções de partição: Intervalo dinâmico. Coluna de partição: Especifique a coluna usada para particionar dados. Se não for especificado, a coluna de chave primária será usada. |
| Carregue uma grande quantidade de dados usando uma consulta personalizada, com partições físicas. |
Partition option: Partições físicas da tabela. Consulta: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.Nome da partição: Especifique o(s) nome(s) da(s) partição(ões) de onde copiar os dados. Se não for especificado, o serviço detetará automaticamente as partições físicas na tabela especificada no conjunto de dados PostgreSQL. Durante a execução, o serviço substitui ?AdfTabularPartitionName pelo nome real da partição e envia para o Banco de Dados do Azure para PostgreSQL. |
| Carregue uma grande quantidade de dados usando uma consulta personalizada, sem partições físicas, mas utilizando uma coluna de números inteiros para particionamento de dados. |
Opções de partição: Intervalo dinâmico. Consulta: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Coluna de partição: Especifique a coluna usada para particionar dados. Você pode particionar contra a coluna com o tipo de dados inteiro, data ou data/hora. Partition upper bound e Partition lower bound: Especifique se deseja filtrar a coluna de partição para recuperar dados somente entre o intervalo inferior e superior. Durante a execução, o serviço substitui ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbounde ?AdfRangePartitionLowbound pelo nome da coluna real e intervalos de valores para cada partição e envia para o Banco de Dados do Azure para PostgreSQL. Por exemplo, se a coluna de partição "ID" estiver definida com o limite inferior como 1 e o limite superior como 80, com cópia paralela definida como 4, o serviço recuperará dados por 4 partições. Os seus IDs situam-se entre [1,20], [21, 40], [41, 60] e [61, 80], respetivamente. |
Práticas recomendadas para carregar dados com a opção de partição:
- Escolha uma coluna distinta como coluna de partição (como chave primária ou chave exclusiva) para evitar distorção de dados.
- Se a tabela tiver partição incorporada, use a opção de partição "Partições físicas da tabela" para obter um melhor desempenho.
Resumo da tabela
A tabela a seguir contém mais informações sobre a atividade de cópia no Banco de Dados do Azure para PostgreSQL.
Fonte da informação
| Nome | Descrição | Valor | Necessário | Propriedade de script JSON |
|---|---|---|---|---|
| Conexão | A sua conexão à fonte de dados de origem. | < seu Banco de Dados do Azure para conexão PostgreSQL > | Sim | conexão |
| Tipo de ligação | Seu tipo de conexão de origem. | Banco de Dados do Azure para PostgreSQL | Sim | / |
| Usar consulta | A maneira de ler dados. Aplique Tabela para ler dados da tabela especificada ou aplique Consulta para ler dados usando consultas. | • Tabela • Consulta |
Sim | • typeProperties (em typeProperties ->source)- esquema - tabela • consulta |
| Tempo limite da consulta (minutos) | O tempo de espera antes de encerrar a tentativa de executar um comando e gerar um erro, o padrão é de 120 minutos. Se o parâmetro for definido para essa propriedade, os valores permitidos serão de intervalo de tempo, como "02:00:00" (120 minutos). Para obter mais informações, consulte CommandTimeout. | Período de tempo | Não | queryTimeout |
| Nomes de partições | A lista de partições físicas que precisam ser copiadas. Se utilizar uma consulta para recuperar os dados de origem, insira ?AdfTabularPartitionName na cláusula WHERE. |
< os nomes das partições > | Não | nomes de partições |
| Nome da coluna da partição | O nome da coluna de origem no tipo inteiro ou data/data/hora (int, smallint, bigint, date, timestamp without time zone, timestamp with time zone ou time without time zone) que será usado pelo particionamento de intervalo para cópia paralela. Se não for especificado, a chave primária da tabela será detetada automaticamente e usada como coluna de partição. |
< os nomes das colunas de partição > | Não | nomeDaColunaDePartição |
| Partição limite superior | O valor máximo da coluna de partição para copiar dados para fora. Se utilizar uma consulta para recuperar os dados de origem, inclua ?AdfRangePartitionUpbound na cláusula WHERE. |
< o limite superior da partição > | Não | limiteSuperiorDePartição |
| Limite inferior da partição | O valor mínimo da coluna de partição para copiar dados para fora. Se utilizar uma consulta para recuperar os dados de origem, insira o gancho ?AdfRangePartitionLowbound na cláusula WHERE. |
< o limite inferior da sua partição > | Não | limiteInferiorDaPartição |
| Colunas adicionais | Adicione colunas de dados adicionais para armazenar o caminho relativo ou o valor estático dos arquivos de origem. A expressão é suportada para este último. | • Nome • Valor |
Não | colunas adicionais: • nome • valor |
Informações sobre o destino
| Nome | Descrição | Valor | Necessário | Propriedade de script JSON |
|---|---|---|---|---|
| Conexão | A sua ligação ao armazenamento de dados de destino. | < seu Banco de Dados do Azure para conexão PostgreSQL > | Sim | conexão |
| Tipo de ligação | Seu tipo de conexão de destino. | Banco de Dados do Azure para PostgreSQL | Sim | / |
| Tabela | Sua tabela de dados de destino para gravar dados. | < nome da tabela de destino > | Sim | propriedadesTipo (em typeProperties ->sink):- esquema - tabela |
| Método Write | O método usado para gravar dados no Banco de Dados do Azure para PostgreSQL. | • comando Copiar (padrão) • Inserção em massa |
Não | writeMethod: • CopyCommand • BulkInsert |
| Script de pré-cópia | Uma consulta SQL para a atividade de cópia a ser executada antes de gravar dados no Banco de Dados do Azure para PostgreSQL em cada execução. Você pode usar essa propriedade para limpar os dados pré-carregados. | < seu script de pré-cópia > | Não | pré-CopyScript |
| Tempo limite de gravação em lote | O tempo de espera para que a operação de inserção em lote termine antes de atingir o tempo limite. | Período de tempo (o padrão é 00:30:00 - 30 minutos) |
Não | writeBatchTimeout |
| Escrever o tamanho do lote | O número de linhas carregadas no Banco de Dados do Azure para PostgreSQL por lote. | inteiro (o padrão é 1.000.000) |
Não | writeBatchSize |
Conteúdo relacionado
- Visão geral do Azure Database for PostgreSQL connector