Transformar dados executando uma atividade do Azure HDInsight
A atividade do Azure HDInsight no Data Factory for Microsoft Fabric permite orquestrar os seguintes tipos de trabalho do Azure HDInsight:
- Executar consultas do Hive
- Invoque um programa MapReduce
- Executar consultas do Pig
- Executar um programa Spark
- Executar um programa Hadoop Stream
Este artigo fornece um passo a passo que descreve como criar uma atividade do Azure HDInsight usando a interface do Data Factory.
Pré-requisitos
Para começar, você deve preencher os seguintes pré-requisitos:
- Uma conta de locatário com uma assinatura ativa. Crie uma conta gratuitamente.
- Um espaço de trabalho é criado.
Adicionar uma atividade do Azure HDInsight (HDI) a um pipeline com a interface do usuário
Crie um novo pipeline de dados em seu espaço de trabalho.
Pesquise o Azure HDInsight no cartão da tela inicial e selecione-o ou selecione a atividade na barra Atividades para adicioná-lo à tela do pipeline.
Criando a atividade a partir do cartão da tela inicial:

Criando a atividade a partir da barra de atividades:
Selecione a nova atividade do Azure HDInsight na tela do editor de pipeline se ainda não estiver selecionada.
Consulte as orientações de configurações gerais para configurar as opções encontradas na guia Configurações gerais .

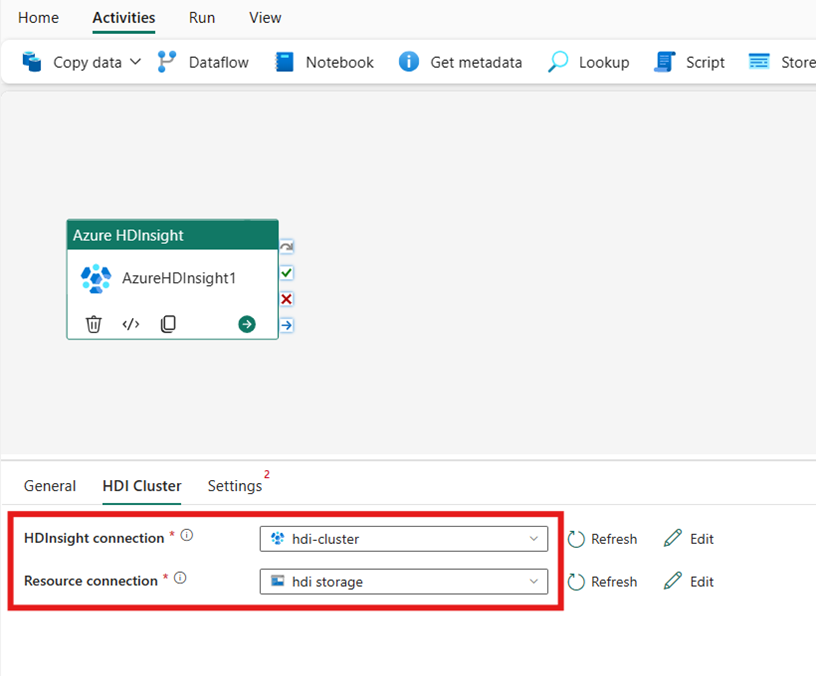
Configurar o cluster HDI
Selecione a guia Cluster HDI. Em seguida, você pode escolher uma conexão HDInsight existente ou criar uma nova.
Para a conexão de Recurso, escolha o Armazenamento de Blob do Azure que faz referência ao cluster do Azure HDInsight. Você pode escolher uma loja de Blob existente ou criar uma nova.
Configurar definições
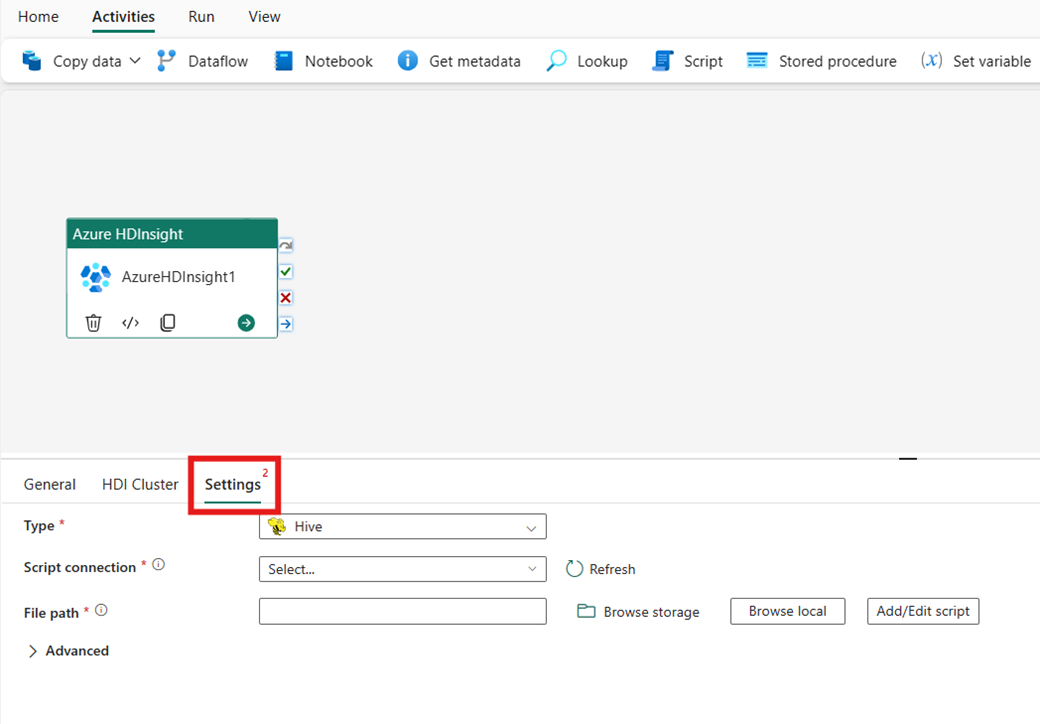
Selecione a guia Configurações para ver as configurações avançadas da atividade.
Todas as propriedades avançadas de cluster e expressões dinâmicas com suporte no serviço vinculado do Azure Data Factory e do Synapse Analytics HDInsight agora também são suportadas na atividade do Azure HDInsight para Data Factory no Microsoft Fabric, na seção Avançado na interface do usuário. Todas essas propriedades suportam expressões parametrizadas personalizadas fáceis de usar com conteúdo dinâmico.
Tipo de cluster
Para definir as configurações do cluster HDInsight, primeiro escolha seu Tipo entre as opções disponíveis, incluindo Hive, Map Reduce, Pig, Spark e Streaming.
Ramo de registo
Se você escolher Hive para Tipo, a atividade executará uma consulta do Hive. Opcionalmente, você pode especificar a conexão Script fazendo referência a uma conta de armazenamento que contém o tipo Hive. Por padrão, a conexão de armazenamento especificada na guia Cluster HDI é usada. Você precisa especificar o caminho do arquivo a ser executado no Azure HDInsight. Opcionalmente, você pode especificar mais configurações na seção Avançado , Informações de depuração, Tempo limite da consulta, Argumentos, Parâmetros e Variáveis.
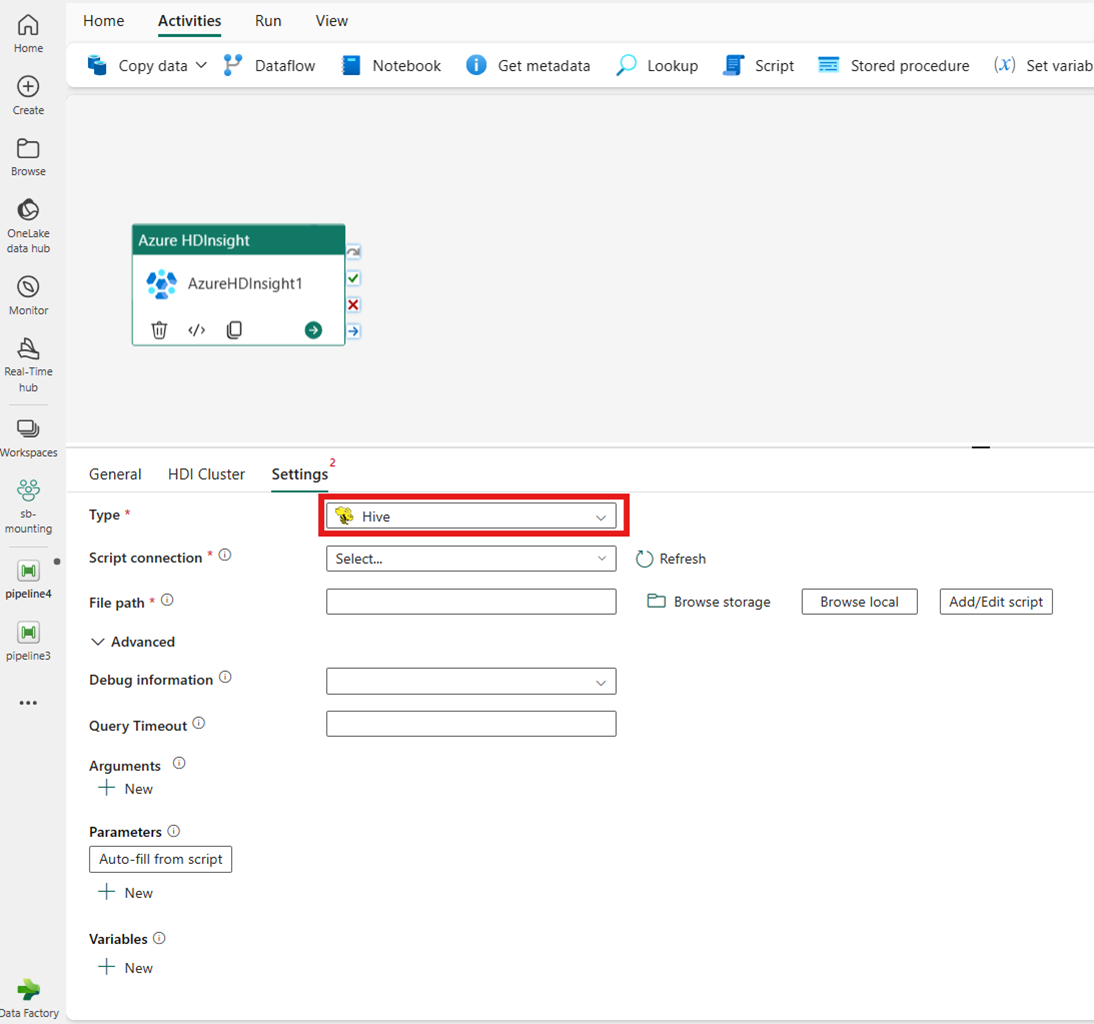
Reduzir Mapa
Se você escolher Map Reduce para Type, a atividade invocará um programa Map Reduce. Opcionalmente, você pode especificar na conexão Jar fazendo referência a uma conta de armazenamento que contém o tipo Map Reduce. Por padrão, a conexão de armazenamento especificada na guia Cluster HDI é usada. Você precisa especificar o nome da classe e o caminho do arquivo a ser executado no Azure HDInsight. Opcionalmente, você pode especificar mais detalhes de configuração, como importar bibliotecas Jar, informações de depuração, argumentos e parâmetros na seção Avançado .
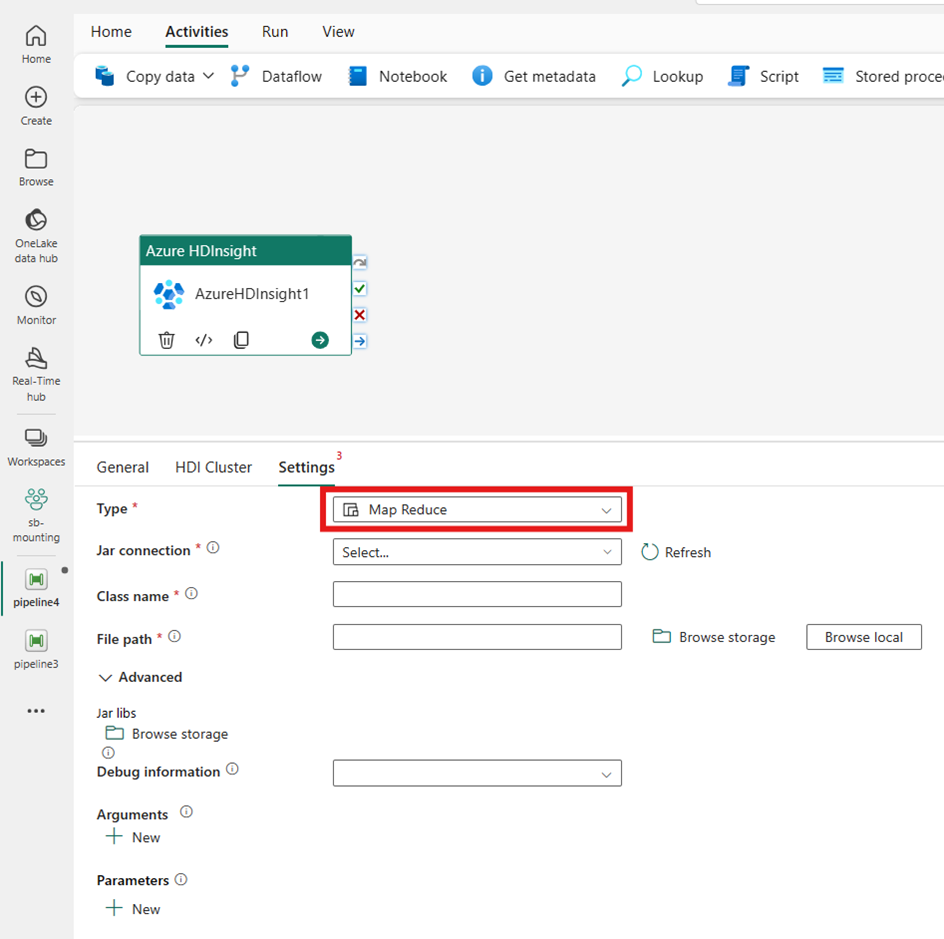
Pig
Se você escolher Pig para Type, a atividade invocará uma consulta Pig. Opcionalmente, você pode especificar a configuração de conexão Script que faz referência à conta de armazenamento que contém o tipo Pig. Por padrão, a conexão de armazenamento especificada na guia Cluster HDI é usada. Você precisa especificar o caminho do arquivo a ser executado no Azure HDInsight. Opcionalmente, você pode especificar mais configurações, como informações de depuração, argumentos, parâmetros e variáveis na seção Avançado .
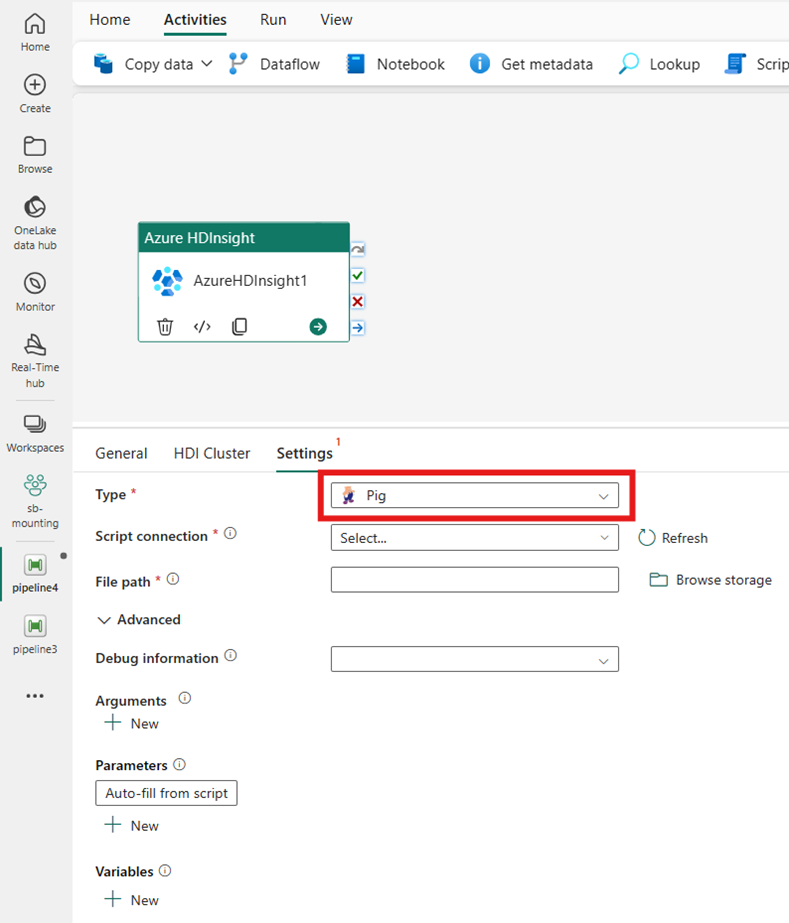
Spark
Se você escolher Spark for Type, a atividade invocará um programa Spark. Selecione Script ou Jar para o tipo Spark. Opcionalmente, você pode especificar a conexão de trabalho fazendo referência à conta de armazenamento que contém o tipo Spark. Por padrão, a conexão de armazenamento especificada na guia Cluster HDI é usada. Você precisa especificar o caminho do arquivo a ser executado no Azure HDInsight. Opcionalmente, você pode especificar mais configurações, como nome da classe, usuário proxy, informações de depuração, argumentos e configuração de faísca na seção Avançado.
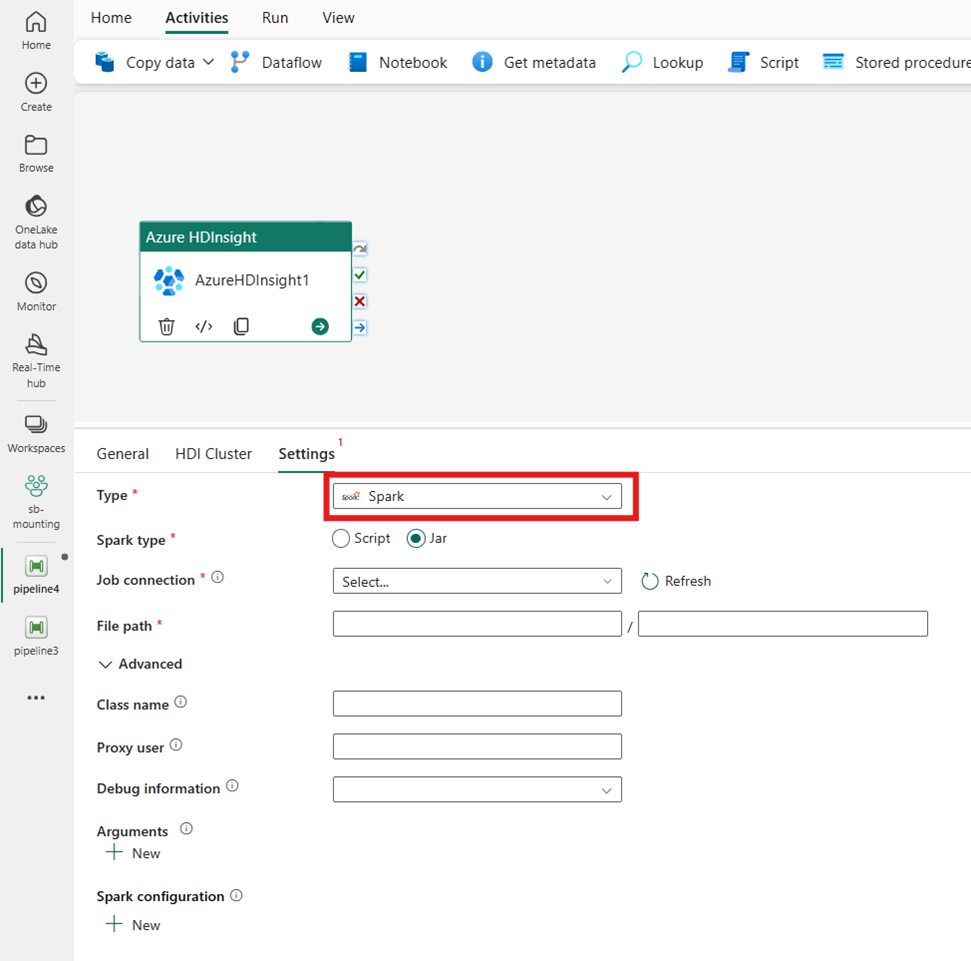
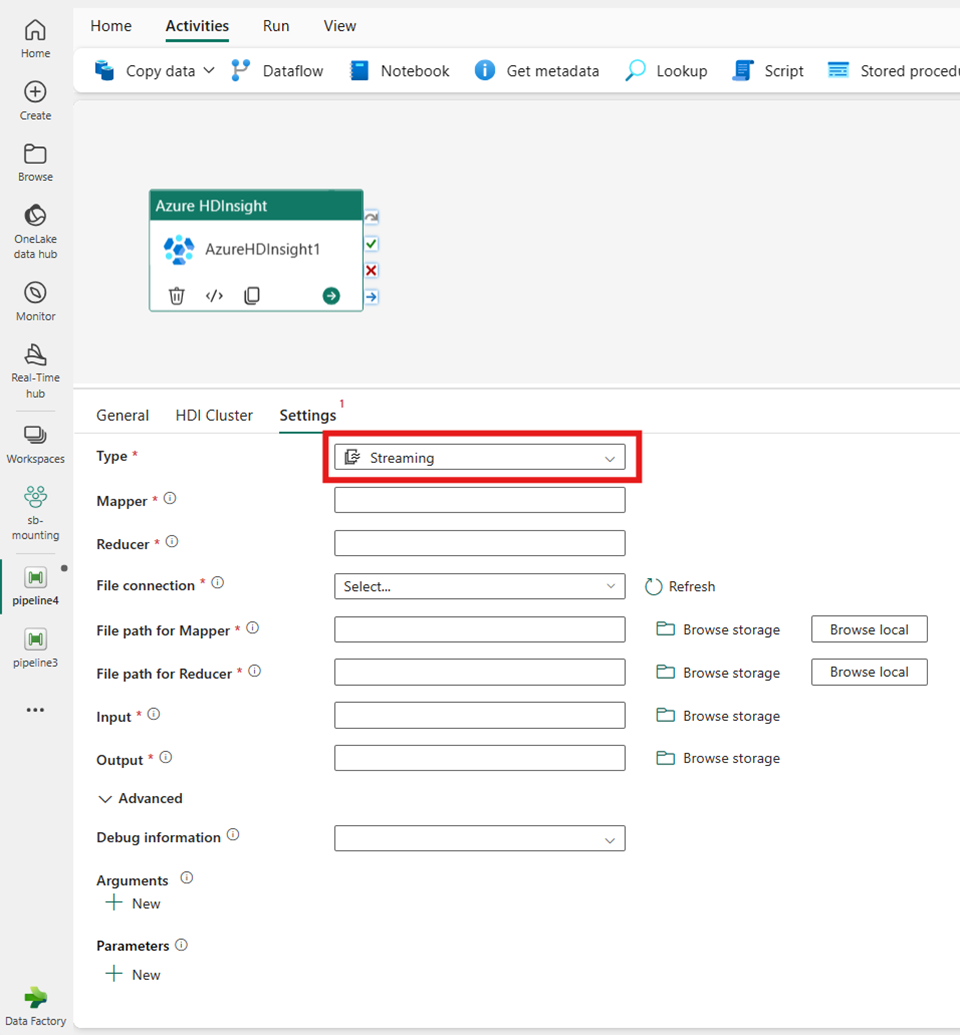
Transmissão
Se você escolher Streaming para Tipo, a atividade invocará um programa de Streaming. Especifique os nomes Mapeador e Redutor e, opcionalmente, você pode especificar a conexão File fazendo referência à conta de armazenamento que contém o tipo Streaming. Por padrão, a conexão de armazenamento especificada na guia Cluster HDI é usada. Você precisa especificar o caminho do arquivo para o Mapeador e o caminho do arquivo para o Reducer a ser executado no Azure HDInsight. Inclua as opções de entrada e saída , bem como para o caminho WASB. Opcionalmente, você pode especificar mais configurações, como informações de depuração, argumentos e parâmetros na seção Avançado.
Referência do imóvel
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | Para Hadoop Streaming Activity, o tipo de atividade é HDInsightStreaming | Sim |
| mapeador | Especifica o nome do executável do mapeador | Sim |
| redutor | Especifica o nome do executável redutor | Sim |
| combinador | Especifica o nome do executável do combinador | Não |
| conexão de arquivo | Referência a um Serviço Vinculado de Armazenamento do Azure usado para armazenar os programas Mapeador, Combinador e Redutor a serem executados. | Não |
| Somente o Armazenamento de Blobs do Azure e as conexões ADLS Gen2 são suportadas aqui. Se você não especificar essa conexão, a conexão de armazenamento definida na conexão HDInsight será usada. | ||
| filePath | Forneça uma matriz de caminho para os programas Mapeador, Combinador e Redutor armazenados no Armazenamento do Azure referidos pela conexão de arquivo. | Sim |
| input | Especifica o caminho WASB para o arquivo de entrada para o Mapeador. | Sim |
| saída | Especifica o caminho WASB para o arquivo de saída para o redutor. | Sim |
| getDebugInfo | Especifica quando os arquivos de log são copiados para o Armazenamento do Azure usado pelo cluster HDInsight (ou) especificado pelo scriptLinkedService. | Não |
| Valores permitidos: Nenhum, Sempre ou Falha. Valor padrão: Nenhum. | ||
| Argumentos | Especifica uma matriz de argumentos para um trabalho Hadoop. Os argumentos são passados como argumentos de linha de comando para cada tarefa. | Não |
| define | Especifique parâmetros como pares chave/valor para referência dentro do script Hive. | Não |
Salvar e executar ou agendar o pipeline
Depois de configurar quaisquer outras atividades necessárias para o pipeline, alterne para a guia Página Inicial na parte superior do editor de pipeline e selecione o botão Salvar para salvar o pipeline. Selecione Executar para executá-lo diretamente ou Agendar para agendá-lo. Você também pode visualizar o histórico de execução aqui ou definir outras configurações.
