Tutorial Lakehouse: Preparar e transformar dados na lakehouse
Neste tutorial, você usa blocos de anotações com o tempo de execução do Spark para transformar e preparar dados brutos em sua casa do lago.
Pré-requisitos
Se você não tem uma casa do lago que contém dados, você deve:
- Crie uma casa no lago, e
- Ingerir dados na casa do lago.
Preparar dados
A partir das etapas anteriores do tutorial, temos dados brutos ingeridos da fonte para a seção Arquivos da casa do lago. Agora você pode transformar esses dados e prepará-los para a criação de tabelas Delta.
Baixe os blocos de anotações da pasta Lakehouse Tutorial Source Code .
A partir do espaço de trabalho, selecione Importar>Bloco de Anotações>deste computador.
Selecione Importar bloco de anotações na seção Novo na parte superior da página de destino.
Selecione Carregar no painel Status de importação que é aberto no lado direito da tela.
Selecione todos os blocos de notas que transferiu no primeiro passo desta secção.
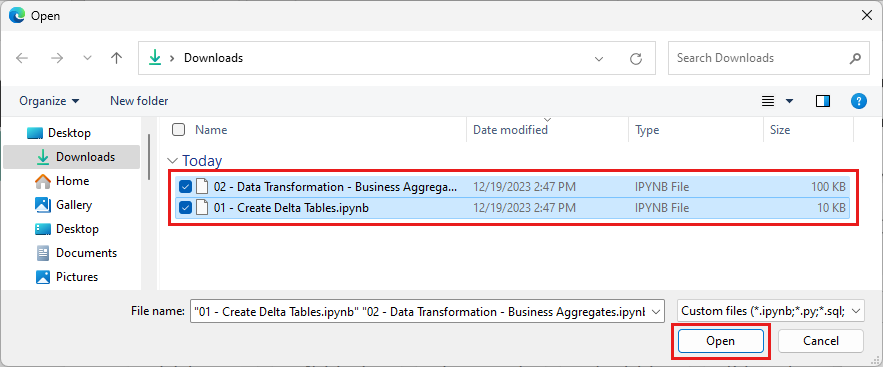
Selecione Abrir. Uma notificação indicando o status da importação aparece no canto superior direito da janela do navegador.
Depois que a importação for bem-sucedida, vá para a exibição de itens do espaço de trabalho e veja os blocos de anotações recém-importados. Selecione wwilakehouse lakehouse para abri-lo.
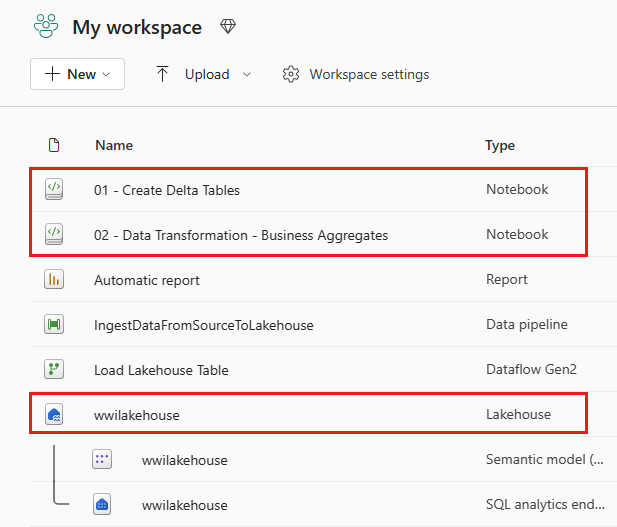
Quando o wwilakehouse lakehouse for aberto, selecione Abrir bloco de anotações Bloco de anotações> existente no menu de navegação superior.
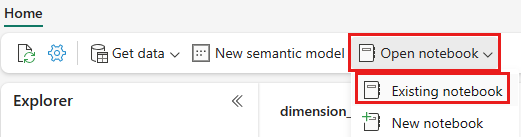
Na lista de blocos de anotações existentes, selecione o bloco de anotações 01 - Criar tabelas delta e selecione Abrir.
No bloco de anotações aberto no lakehouse Explorer, você vê que o notebook já está vinculado à sua lakehouse aberta.
Nota
O Fabric fornece a capacidade de ordem V para gravar arquivos Delta lake otimizados. A ordem V geralmente melhora a compactação em três a quatro vezes, e até 10 vezes, a aceleração de desempenho sobre os arquivos Delta Lake que não são otimizados. O Spark in Fabric otimiza dinamicamente partições enquanto gera arquivos com um tamanho padrão de 128 MB. O tamanho do arquivo de destino pode ser alterado por requisitos de carga de trabalho usando configurações.
Com a capacidade de gravação otimizada, o mecanismo Apache Spark reduz o número de arquivos gravados e visa aumentar o tamanho do arquivo individual dos dados gravados.
Antes de escrever dados como tabelas Delta lake na seção Tabelas da lakehouse, você usa dois recursos de malha (ordem V e Otimizar gravação) para gravação de dados otimizada e melhor desempenho de leitura. Para ativar estas funcionalidades na sua sessão, defina estas configurações na primeira célula do seu bloco de notas.
Para iniciar o bloco de notas e executar todas as células em sequência, selecione Executar tudo no friso superior (em Base). Ou, para executar apenas o código de uma célula específica, selecione o ícone Executar que aparece à esquerda da célula ao passar o mouse ou pressione SHIFT + ENTER no teclado enquanto o controle estiver na célula.
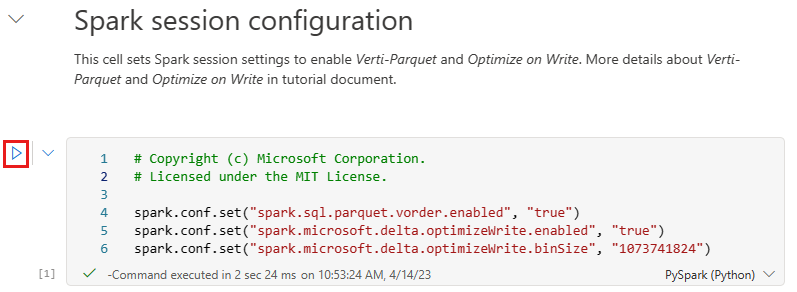
Ao executar uma célula, não era necessário especificar os detalhes subjacentes do pool do Spark ou do cluster porque o Fabric os fornece por meio do Live Pool. Cada espaço de trabalho do Fabric vem com um pool Spark padrão, chamado Live Pool. Isso significa que, ao criar blocos de anotações, você não precisa se preocupar em especificar nenhuma configuração do Spark ou detalhes do cluster. Quando você executa o primeiro comando do bloco de anotações, o pool dinâmico fica pronto e funcionando em poucos segundos. E a sessão do Spark é estabelecida e começa a executar o código. A execução de código subsequente é quase instantânea neste bloco de anotações enquanto a sessão do Spark está ativa.
Em seguida, você lê dados brutos da seção Arquivos da casa do lago e adiciona mais colunas para diferentes partes de data como parte da transformação. Finalmente, você usa a partição By Spark API para particionar os dados antes de gravá-los como formato de tabela Delta com base nas colunas de parte de dados recém-criadas (Ano e Trimestre).
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)Depois que as tabelas de fatos forem carregadas, você poderá passar para o carregamento de dados para o restante das dimensões. A célula a seguir cria uma função para ler dados brutos da seção Arquivos da casa do lago para cada um dos nomes de tabela passados como parâmetro. Em seguida, ele cria uma lista de tabelas de dimensão. Finalmente, ele percorre a lista de tabelas e cria uma tabela Delta para cada nome de tabela lido a partir do parâmetro de entrada. Observe que o script descarta a coluna nomeada
Photoneste exemplo porque a coluna não é usada.from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Para validar as tabelas criadas, clique com o botão direito do mouse e selecione atualizar no wwilakehouse lakehouse. As tabelas aparecem.
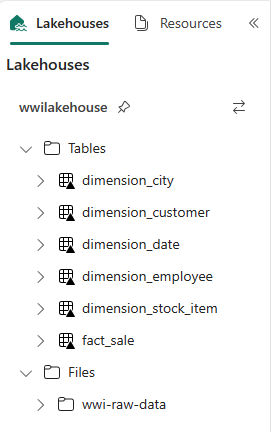
Vá para a visualização de itens do espaço de trabalho novamente e selecione o wwilakehouse lakehouse para abri-lo.
Agora, abra o segundo caderno. Na vista lakehouse, selecione Abrir bloco de notas Bloco de notas> existente no friso.
Na lista de blocos de anotações existentes, selecione o bloco de anotações 02 - Data Transformation - Business para abri-lo.
No bloco de anotações aberto no lakehouse Explorer, você vê que o notebook já está vinculado à sua lakehouse aberta.
Uma organização pode ter engenheiros de dados trabalhando com Scala/Python e outros engenheiros de dados trabalhando com SQL (Spark SQL ou T-SQL), todos trabalhando na mesma cópia dos dados. O Fabric possibilita que estes diferentes grupos, com experiência e preferência variadas, trabalhem e colaborem. As duas abordagens diferentes transformam e geram agregados de negócios. Pode escolher a mais adequada para si ou misturar e combinar estas abordagens com base na sua preferência sem comprometer o desempenho:
Abordagem #1 - Use o PySpark para unir e agregar dados para gerar agregações de negócios. Esta abordagem é preferível a alguém com experiência em programação (Python ou PySpark).
Abordagem #2 - Use o Spark SQL para unir e agregar dados para gerar agregações de negócios. Essa abordagem é preferível a alguém com experiência em SQL, fazendo a transição para o Spark.
Abordagem #1 (sale_by_date_city) - Use o PySpark para unir e agregar dados para gerar agregações de negócios. Com o código a seguir, você cria três dataframes Spark diferentes, cada um fazendo referência a uma tabela Delta existente. Em seguida, você une essas tabelas usando os dataframes, agrupa por para gerar agregação, renomeia algumas das colunas e, finalmente, escreve-a como uma tabela Delta na seção Tabelas da casa do lago para persistir com os dados.
Nesta célula, você cria três dataframes diferentes do Spark, cada um fazendo referência a uma tabela Delta existente.
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")Adicione o código a seguir à mesma célula para unir essas tabelas usando os dataframes criados anteriormente. Agrupe por para gerar agregação, renomeie algumas das colunas e, finalmente, escreva-a como uma tabela Delta na seção Tabelas da casa do lago.
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")Abordagem #2 (sale_by_date_employee) - Use o Spark SQL para unir e agregar dados para gerar agregações de negócios. Com o código a seguir, você cria um modo de exibição temporário do Spark unindo três tabelas, agrupa por para gerar agregação e renomeia algumas das colunas. Finalmente, você lê a partir da visualização temporária Spark e, finalmente, escreve-a como uma tabela Delta na seção Tabelas da casa do lago para persistir com os dados.
Nesta célula, você cria um modo de exibição Spark temporário unindo três tabelas, agrupa por para gerar agregação e renomeia algumas das colunas.
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASCNesta célula, você lê a partir da visualização temporária Faísca criada na célula anterior e, finalmente, escreve-a como uma tabela Delta na seção Tabelas da casa do lago.
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")Para validar as tabelas criadas, clique com o botão direito do mouse e selecione Atualizar no wwilakehouse lakehouse. As tabelas agregadas aparecem.
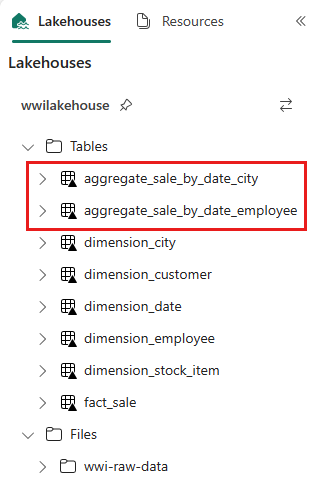
As duas abordagens produzem um resultado semelhante. Para minimizar a necessidade de aprender uma nova tecnologia ou comprometer o desempenho, escolha a abordagem que melhor se adapte à sua experiência e preferência.
Você pode notar que está gravando dados como arquivos Delta lake. O recurso automático de descoberta e registro de tabelas do Fabric as pega e registra no metastore. Você não precisa chamar CREATE TABLE explicitamente instruções para criar tabelas para usar com SQL.