Use um bloco de anotações para carregar dados em sua casa do lago
Neste tutorial, aprenda a ler/gravar dados em seu lago de malha com um bloco de anotações. O Fabric suporta a API Spark e a API Pandas deve atingir esse objetivo.
Carregar dados com uma API do Apache Spark
Na célula de código do bloco de anotações, use o exemplo de código a seguir para ler dados da fonte e carregá-los em Arquivos, Tabelas ou em ambas as seções da sua casa do lago.
Para especificar o local de leitura, você pode usar o caminho relativo se os dados forem da casa do lago padrão do seu bloco de anotações atual. Ou, se os dados forem de uma casa de lago diferente, você pode usar o caminho absoluto do Sistema de Arquivos de Blob do Azure (ABFS). Copie esse caminho do menu de contexto dos dados.
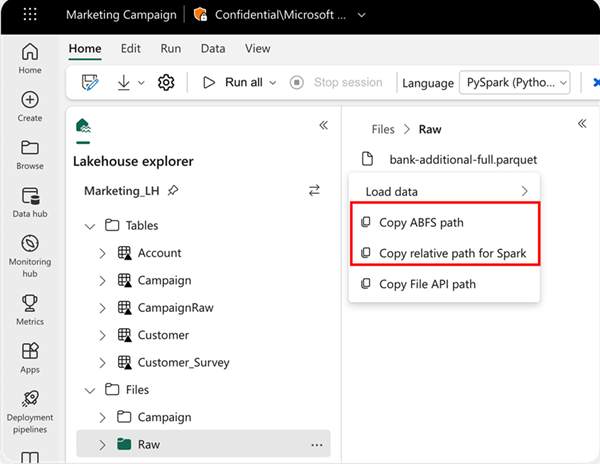
Copiar caminho ABFS: Esta opção retorna o caminho absoluto do arquivo.
Copiar caminho relativo para o Spark: esta opção retorna o caminho relativo do arquivo em sua casa de lago padrão.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Carregar dados com a API Pandas
Para suportar a API Pandas, o lakehouse padrão é montado automaticamente no notebook. O ponto de montagem é '/lakehouse/default/'. Você pode usar esse ponto de montagem para ler/gravar dados de/para a casa do lago padrão. A opção "Copiar caminho da API do arquivo" do menu de contexto retorna o caminho da API do arquivo desse ponto de montagem. O caminho retornado da opção Copiar caminho ABFS também funciona para a API do Pandas.
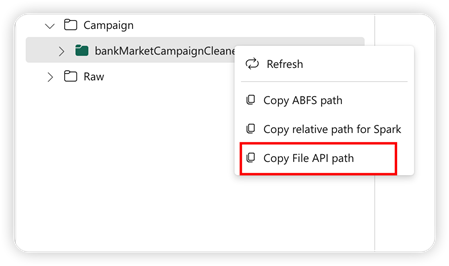
Copiar caminho da API do arquivo: esta opção retorna o caminho sob o ponto de montagem da casa do lago padrão.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Gorjeta
Para a API do Spark, use a opção de Copiar caminho ABFS ou Copiar caminho relativo para o Spark para obter o caminho do arquivo. Para Pandas API, use a opção de Copiar caminho ABFS ou Copiar caminho da API de arquivo para obter o caminho do arquivo.
A maneira mais rápida de ter o código para trabalhar com a API do Spark ou a API do Pandas é usar a opção de Carregar dados e selecionar a API que deseja usar. O código é gerado automaticamente numa nova célula de código do bloco de notas.
