Obtenha dados de streaming no lakehouse e acesse com o ponto de extremidade de análise SQL
Este guia de início rápido explica como criar uma definição de trabalho do Spark que contém código Python com o Spark Structured Streaming para pousar dados em uma casa de lago e, em seguida, servi-los por meio de um ponto de extremidade de análise SQL. Depois de concluir este início rápido, você terá uma definição de trabalho do Spark que é executada continuamente e o ponto de extremidade de análise SQL pode exibir os dados de entrada.
Criar um script Python
Use o seguinte código Python que usa o streaming estruturado do Spark para obter dados em uma tabela lakehouse.
import sys from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession.builder.appName("MyApp").getOrCreate() tableName = "streamingtable" deltaTablePath = "Tables/" + tableName df = spark.readStream.format("rate").option("rowsPerSecond", 1).load() query = df.writeStream.outputMode("append").format("delta").option("path", deltaTablePath).option("checkpointLocation", deltaTablePath + "/checkpoint").start() query.awaitTermination()Salve seu script como arquivo Python (.py) em seu computador local.
Criar uma casa no lago
Use as seguintes etapas para criar uma casa no lago:
Inicie sessão no portal do Microsoft Fabric.
Navegue até o espaço de trabalho desejado ou crie um novo, se necessário.
Para criar uma Lakehouse, selecione Novo item no espaço de trabalho e, em seguida, selecione Lakehouse no painel que se abre.

Digite o nome da sua casa do lago e selecione Criar.

Criar uma definição de trabalho do Spark
Use as seguintes etapas para criar uma definição de trabalho do Spark:
No mesmo espaço de trabalho em que você criou uma casa no lago, selecione Novo item.
No painel que se abre, em Obter Dados, selecione Definição de Tarefa do Spark.
Digite o nome da sua Definição de Trabalho do Spark e selecione Criar.
Selecione Upload e selecione o arquivo Python que você criou na etapa anterior.
Em Lakehouse Reference escolha a lakehouse que você criou.
Definir política de repetição para definição de trabalho do Spark
Use as seguintes etapas para definir a política de repetição para sua definição de trabalho do Spark:
No menu superior, selecione o ícone Configuração .
Abra a guia Otimização e defina o gatilho Repetir política ativado.
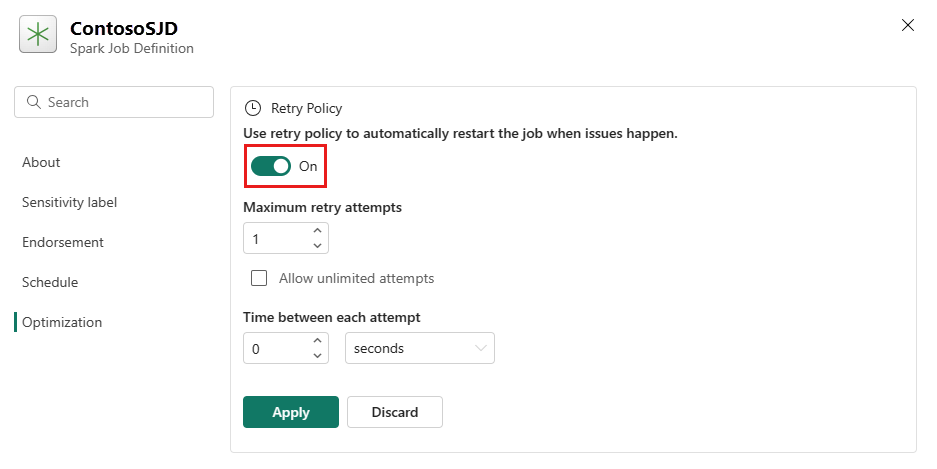
Defina o máximo de tentativas ou marque Permitir tentativas ilimitadas.
Especifique o tempo entre cada tentativa de repetição e selecione Aplicar.
Nota
Há um limite vitalício de 90 dias para a configuração da política de novas tentativas. Quando a política de repetição estiver ativada, o trabalho será reiniciado de acordo com a política dentro de 90 dias. Após esse período, a política de repetição deixará automaticamente de funcionar e o trabalho será encerrado. Os usuários precisarão reiniciar manualmente o trabalho, o que, por sua vez, reativará a política de repetição.
Executar e monitorar a definição de trabalho do Spark
No menu superior, selecione o ícone Executar .
Verifique se a definição do Spark Job foi enviada com êxito e está em execução.
Exibir dados usando um ponto de extremidade de análise SQL
Na visualização do espaço de trabalho, selecione sua Lakehouse.
No canto direito, selecione Lakehouse e selecione SQL analytics endpoint.
Na visualização do ponto de extremidade da análise SQL, em Tabelas, selecione a tabela que o script usa para obter dados. Em seguida, você pode visualizar seus dados a partir do ponto de extremidade de análise SQL.