Criar e gerenciar definições de trabalho do Apache Spark no Visual Studio Code
A extensão de código do Visual Studio (VS) para Synapse suporta totalmente as operações de definição de trabalho CURD (criar, atualizar, ler e excluir) do Spark na malha. Depois de criar uma definição de trabalho do Spark, você pode carregar mais bibliotecas referenciadas, enviar uma solicitação para executar a definição de trabalho do Spark e verificar o histórico de execução.
Criar uma definição de trabalho do Spark
Para criar uma nova definição de trabalho do Spark:
No VS Code Explorer, selecione a opção Create Spark Job Definition (Criar definição de trabalho do Spark).

Insira os campos iniciais obrigatórios: nome, lakehouse referenciado e lakehouse padrão.
Os processos de solicitação e o nome da definição de trabalho do Spark recém-criada aparecem sob o nó raiz Definição de trabalho do Spark no VS Code Explorer. No nó Nome da definição de trabalho do Spark, você vê três subnós:
- Ficheiros: Lista do ficheiro de definição principal e outras bibliotecas referenciadas. Pode carregar novos ficheiros a partir desta lista.
- Lakehouse: Lista de todas as lakehouses referenciadas por esta definição de trabalho do Spark. A casa do lago padrão está marcada na lista, e você pode acessá-la através do caminho
Files/…, Tables/…relativo. - Executar: Lista do histórico de execução desta definição de trabalho do Spark e o status do trabalho de cada execução.
Carregar um arquivo de definição principal para uma biblioteca referenciada
Para carregar ou substituir o arquivo de definição principal, selecione a opção Adicionar arquivo principal.
Para carregar o arquivo de biblioteca ao qual o arquivo de definição principal faz referência, selecione a opção Adicionar arquivo Lib.
Depois de carregar um ficheiro, pode substituí-lo clicando na opção Atualizar ficheiro e carregando um novo ficheiro, ou pode eliminar o ficheiro através da opção Eliminar .
Enviar uma solicitação de execução
Para enviar uma solicitação para executar a definição de tarefa do Spark a partir do VS Code:
Nas opções à direita do nome da definição de trabalho do Spark que você deseja executar, selecione a opção Executar trabalho do Spark.

Depois de enviar a solicitação, um novo aplicativo Apache Spark aparece no nó Executa na lista Explorer . Você pode cancelar o trabalho em execução selecionando a opção Cancelar trabalho do Spark.
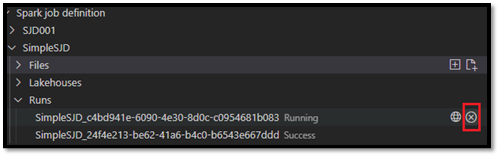
Abrir uma definição de trabalho do Spark no portal do Fabric
Você pode abrir a página de criação de definição de trabalho do Spark no portal do Fabric selecionando a opção Abrir no navegador .
Você também pode selecionar Abrir no navegador ao lado de uma execução concluída para ver a página do monitor de detalhes dessa execução.

Depurar código-fonte de definição de trabalho do Spark (Python)
Se a definição de trabalho do Spark for criada com o PySpark (Python), você poderá baixar o script .py do arquivo de definição principal e do arquivo referenciado e depurar o script de origem no VS Code.
Para baixar o código-fonte, selecione a opção Debug Spark Job Definition à direita da definição de trabalho do Spark.

Após a conclusão do download, a pasta do código-fonte é aberta automaticamente.
Selecione a opção Confiar nos autores quando solicitado. (Esta opção só aparece na primeira vez que abre a pasta. Se você não selecionar essa opção, não poderá depurar ou executar o script de origem. Para obter mais informações, consulte Segurança de confiança do Visual Studio Code Workspace.)
Se você tiver baixado o código-fonte antes, será solicitado que você confirme que deseja substituir a versão local pelo novo download.
Nota
Na pasta raiz do script de origem, o sistema cria uma subpasta chamada conf. Dentro dessa pasta, um arquivo chamado lighter-config.json contém alguns metadados do sistema necessários para a execução remota. NÃO faça nenhuma alteração nele.
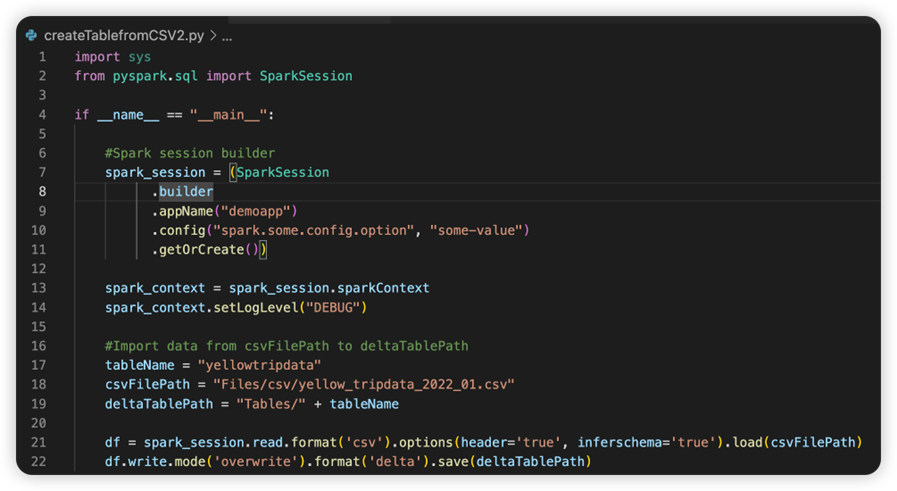
O arquivo chamado sparkconf.py contém um trecho de código que você precisa adicionar para configurar o objeto SparkConf . Para habilitar a depuração remota, verifique se o objeto SparkConf está configurado corretamente. A imagem a seguir mostra a versão original do código-fonte.
A próxima imagem é o código-fonte atualizado depois de copiar e colar o trecho.
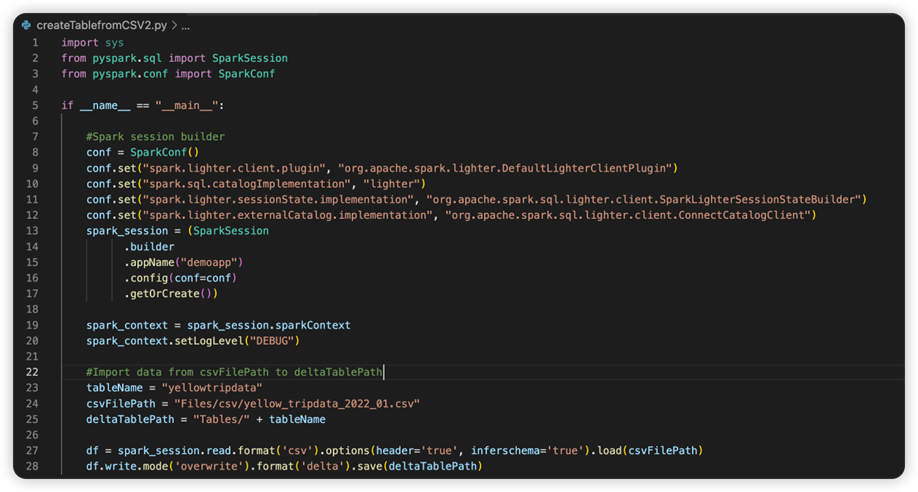
Depois de atualizar o código-fonte com o conf necessário, você deve escolher o Interpretador Python certo. Certifique-se de selecionar o instalado a partir do ambiente synapse-spark-kernel conda.
Editar propriedades de definição de trabalho do Spark
Você pode editar as propriedades detalhadas das definições de trabalho do Spark, como argumentos de linha de comando.
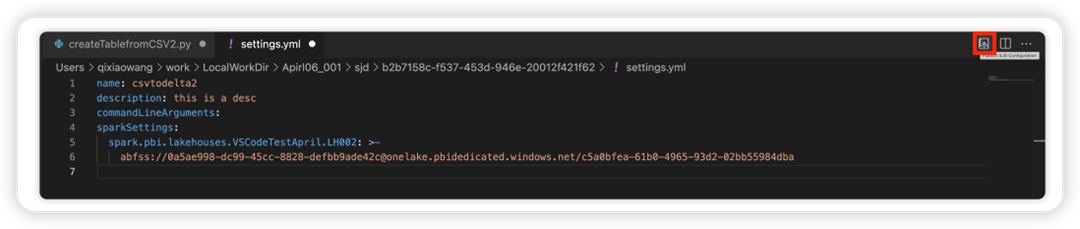
Selecione a opção Atualizar configuração SJD para abrir um arquivo settings.yml . As propriedades existentes preenchem o conteúdo desse arquivo.
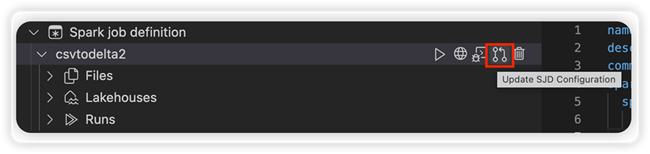
Atualize e salve o arquivo .yml.
Selecione a opção Publicar propriedade SJD no canto superior direito para sincronizar a alteração de volta ao espaço de trabalho remoto.