Microsoft Entra Connect Sync: Noções básicas sobre a arquitetura
Este artigo aborda a arquitetura básica do Microsoft Entra Connect Sync. Se você estiver familiarizado com tecnologias anteriores de sincronização de identidade, o conteúdo deste artigo também pode ser familiar para você. Se você é novo na sincronização, então este artigo é para você. Não é necessário conhecer os detalhes deste artigo para ter sucesso em fazer personalizações no Microsoft Entra Connect Sync (chamado de mecanismo de sincronização neste artigo).
Arquitetura
O mecanismo de sincronização cria uma exibição integrada de objetos armazenados em várias fontes de dados conectadas e gerencia informações de identidade nessas fontes de dados. As informações de identidade recuperadas de fontes de dados conectadas determinam essa exibição integrada. Um conjunto de regras determina como processar essas informações.
Conectores e fontes de dados conectados
O mecanismo de sincronização processa informações de identidade de diferentes repositórios de dados, como o Ative Directory ou um banco de dados do SQL Server. Cada repositório de dados que organiza seus dados em um formato semelhante a um banco de dados e que fornece métodos padrão de acesso a dados é um potencial candidato a fonte de dados para o mecanismo de sincronização. Os repositórios de dados sincronizados pelo mecanismo de sincronização são chamados fontes de dados conectadas ou diretórios conectados (CD).
O mecanismo de sincronização encapsula a interação com uma fonte de dados conectada dentro de um módulo chamado Connector. Cada tipo de fonte de dados conectada tem um conector específico. O conector traduz uma operação necessária para o formato que a fonte de dados conectada entende.
Os conectores fazem chamadas de API para trocar informações de identidade (leitura e gravação) com uma fonte de dados conectada. Também é possível adicionar um conector personalizado usando a estrutura de conectividade extensível. A ilustração a seguir mostra como um Conector conecta uma fonte de dados conectada ao mecanismo de sincronização.
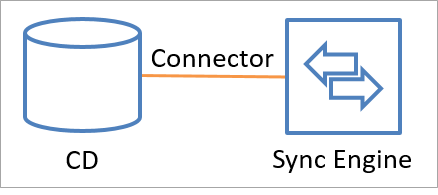
Os dados podem fluir em qualquer direção, mas não podem fluir em ambas as direções simultaneamente. Um conector pode ser configurado para permitir que os dados fluam da fonte de dados conectada para o mecanismo de sincronização ou do mecanismo de sincronização para a fonte de dados conectada. Mas, apenas uma dessas operações pode ocorrer a qualquer momento para um objeto e atributo. A direção pode ser diferente para diferentes objetos e para diferentes atributos.
Para configurar um conector, especifique os tipos de objeto que deseja sincronizar. A especificação dos tipos de objeto define o escopo dos objetos incluídos no processo de sincronização. A próxima etapa é selecionar os atributos a serem sincronizados, o que é conhecido como uma lista de inclusão de atributos. Essas configurações podem ser alteradas a qualquer momento em resposta a alterações nas suas regras de negócios. Quando você usa o assistente de instalação do Microsoft Entra Connect, essas configurações são definidas para você.
Para exportar objetos para uma fonte de dados conectada, a lista de inclusão de atributos deve incluir pelo menos os atributos mínimos necessários para criar um tipo de objeto específico em uma fonte de dados conectada. Por exemplo, o atributo sAMAccountName deve ser incluído na lista de inclusão de atributos para exportar um objeto de usuário para o Ative Directory porque todos os objetos de usuário no Ative Directory devem ter um atributo sAMAccountName definido. Novamente, o assistente de instalação faz essa configuração para você.
Se a fonte de dados conectada usar componentes estruturais, como partições ou contêineres para organizar objetos, você poderá limitar as áreas na fonte de dados conectada que são usadas para uma determinada solução.
Estrutura interna do namespace do mecanismo de sincronização
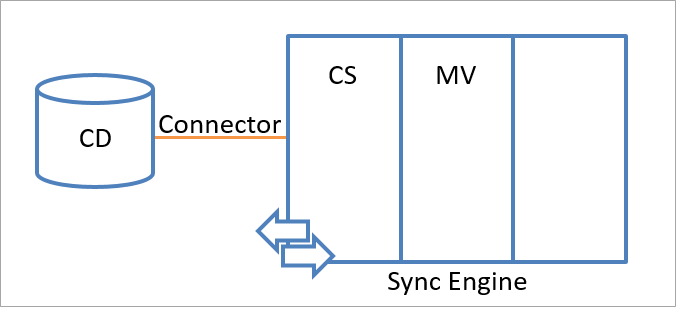
Todo o namespace do mecanismo de sincronização consiste em dois namespaces que armazenam as informações de identidade. Os dois namespaces são:
- O espaço do conector (CS)
- O metaverso (MV)
O espaço do conector é uma área de preparação que contém representações dos objetos designados de uma fonte de dados ligada e os atributos especificados na lista de inclusão de atributos. O mecanismo de sincronização usa o espaço do conector para determinar o que mudou na fonte de dados conectada e para preparar as alterações de entrada. O mecanismo de sincronização também usa o espaço do conector para preparar as alterações de saída que serão exportadas para a fonte de dados ligada. O mecanismo de sincronização mantém um espaço de conector distinto como uma área de preparo para cada conector.
Usando uma área de preparação, o mecanismo de sincronização permanece independente das fontes de dados conectadas e não é afetado por sua disponibilidade e acessibilidade. Como resultado, é possível processar informações de identidade a qualquer momento, utilizando os dados na área de preparação. O mecanismo de sincronização pode solicitar apenas as alterações feitas dentro da fonte de dados conectada desde que a última sessão de comunicação foi encerrada ou enviar por push apenas as alterações nas informações de identidade que a fonte de dados conectada ainda não recebeu, o que reduz o tráfego de rede entre o mecanismo de sincronização e a fonte de dados conectada.
Além disso, o mecanismo de sincronização armazena informações de status sobre todos os objetos que ele processa no espaço do conector. Quando novos dados são recebidos, o mecanismo de sincronização sempre avalia se os dados já foram sincronizados.
O metaverso é uma área de armazenamento que contém as informações de identidade agregadas de várias fontes de dados conectadas, fornecendo uma única visão global e integrada de todos os objetos combinados. Os objetos do metaverso são criados com base nas informações de identidade recuperadas das fontes de dados conectadas e em um conjunto de regras que permitem personalizar o processo de sincronização.
A ilustração a seguir mostra o namespace do espaço do conector e o namespace do metaverso dentro do mecanismo de sincronização.
Objetos de identidade do mecanismo de sincronização
Os objetos no mecanismo de sincronização são representações de objetos na fonte de dados conectada ou a exibição integrada que o mecanismo de sincronização tem desses objetos. Cada objeto do mecanismo de sincronização deve ter um identificador global exclusivo (GUID). Os GUIDs fornecem integridade de dados e expressam relações entre objetos.
Objetos do espaço de conector
Quando o mecanismo de sincronização se comunica com uma fonte de dados conectada, ele lê as informações de identidade na fonte de dados conectada e usa essas informações para criar uma representação do objeto de identidade no espaço do conector. Não é possível criar ou excluir esses objetos individualmente. No entanto, pode-se excluir manualmente todos os objetos num espaço de conector.
Todos os objetos no espaço do conector têm dois atributos:
- Um identificador global exclusivo (GUID)
- Um nome distinto (também conhecido como DN)
Se a fonte de dados conectada atribuir um atributo exclusivo ao objeto, os objetos no espaço do conector também poderão ter um atributo de âncora. O atributo anchor identifica exclusivamente um objeto na fonte de dados conectada. O mecanismo de sincronização usa a âncora para localizar a representação correspondente desse objeto na fonte de dados conectada. O mecanismo de sincronização pressupõe que a âncora de um objeto nunca muda ao longo do tempo de vida do objeto.
Muitos dos conectores usam um identificador exclusivo conhecido para gerar uma âncora automaticamente para cada objeto quando ele é importado. Por exemplo, o Conector do Active Directory usa o atributo objectGUID para uma âncora. Para fontes de dados conectadas que não fornecem um identificador exclusivo claramente definido, você pode especificar a geração de âncora como parte da configuração do Conector.
Nesse caso, a âncora é construída a partir de um ou mais atributos exclusivos de um tipo de objeto, nenhum dos quais muda, e que identifica exclusivamente o objeto no espaço do conector (por exemplo, um número de funcionário ou um ID de usuário).
Um objeto de espaço de conector pode ser um dos seguintes:
- Um objeto de ensaio
- Um espaço reservado
Objetos para Encenação
Um objeto de preparação representa uma instância dos tipos de objeto designados da fonte de dados conectada. Além do GUID e do nome distinto, um objeto de preparação sempre possui um valor que indica o tipo de objeto.
Os objetos de preparação importados sempre têm um valor para o atributo âncora. Os objetos em fase de preparação recém-provisionados pelo mecanismo de sincronização e que estão a ser criados na fonte de dados conectada não têm um valor para o atributo de âncora.
Os objetos de preparação também carregam valores atuais de atributos empresariais e informações operacionais necessárias para que o motor de sincronização execute o processo. As informações operacionais incluem indicadores que indicam o tipo de atualizações aplicadas no objeto de preparação. Se um objeto de staging tiver recebido novas informações de identidade da fonte de dados conectada que ainda não foi processada, o objeto será marcado como pendente de importação. Se um objeto de preparo tiver novas informações de identidade que ainda não foram exportadas para a fonte de dados conectada, ele será sinalizado como de exportação pendente.
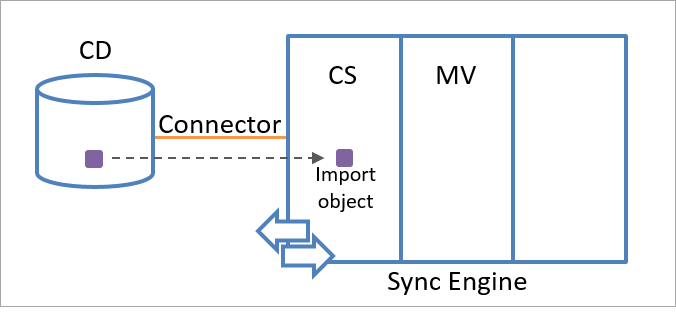
Um objeto de estágio pode ser um objeto de importação ou um objeto de exportação. O mecanismo de sincronização cria um objeto de importação usando informações de objeto recebidas da fonte de dados conectada. Quando o mecanismo de sincronização recebe informações sobre a existência de um novo objeto que corresponde a um dos tipos de objeto selecionados no Conector, ele cria um objeto de importação no espaço do conector como uma representação do objeto na fonte de dados conectada.
A ilustração a seguir mostra um objeto de importação que representa um objeto na fonte de dados conectada.
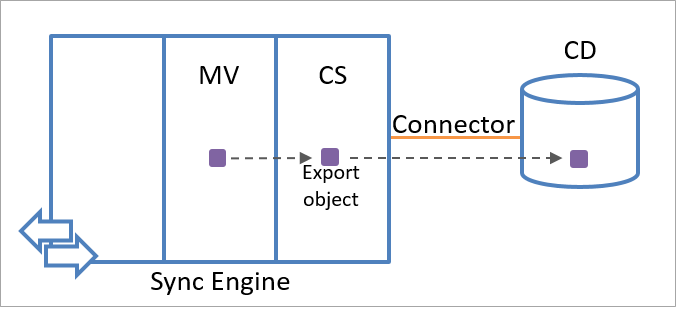
O mecanismo de sincronização cria um objeto de exportação usando informações de objeto no metaverso. Os objetos de exportação são exportados para a fonte de dados conectada durante a próxima sessão de comunicação. Do ponto de vista do mecanismo de sincronização, os objetos de exportação ainda não existem na fonte de dados conectada. Portanto, o atributo anchor para um objeto de exportação não está disponível. Depois de receber o objeto do mecanismo de sincronização, a fonte de dados conectada cria um valor exclusivo para o atributo âncora do objeto.
A ilustração a seguir mostra como um objeto de exportação é criado usando informações de identidade no metaverso.
O mecanismo de sincronização confirma a exportação do objeto reimportando o objeto da fonte de dados conectada. Os objetos de exportação tornam-se objetos de importação quando o mecanismo de sincronização os recebe durante a próxima importação dessa fonte de dados conectada.
Marcadores de posição
O mecanismo de sincronização usa um namespace simples para armazenar objetos. No entanto, algumas fontes de dados conectadas, como o Ative Directory, usam um namespace hierárquico. Para transformar informações de um namespace hierárquico em um namespace simples, o mecanismo de sincronização usa espaços reservados para preservar a hierarquia.
Cada espaço reservado representa um componente, como uma unidade organizacional, do nome hierárquico de um objeto que não é importado para o mecanismo de sincronização, mas é necessário para construir o nome hierárquico. Eles preenchem lacunas criadas por referências na fonte de dados conectada a objetos que não são objetos de preparação no espaço de conexão.
O mecanismo de sincronização também usa espaços reservados para armazenar objetos referenciados que ainda não foram importados. Por exemplo, se a sincronização estiver configurada para incluir o atributo manager para o objeto Abbie Spencer e o valor recebido for um objeto que ainda não foi importado, como CN=Lee Sperry,CN=Users,DC=fabrikam,DC=com, as informações do gestor serão armazenadas como espaços reservados no espaço do conector. Se o objeto gestor for importado posteriormente, o objeto marcador será substituído pelo objeto de preparação que representa o gestor.
Objetos do metaverso
Um objeto de metaverso contém a visão agregada que o motor de sincronização tem dos objetos de preparação no espaço do conector. O mecanismo de sincronização cria objetos de metaverso usando as informações nos objetos de importação. Vários objetos de espaço de conector podem ser vinculados a um único objeto de metaverso, mas um objeto de espaço de conector não pode ser vinculado a mais de um objeto de metaverso.
Os objetos do metaverso não podem ser criados ou excluídos manualmente. O motor de sincronização elimina automaticamente os objetos do metaverso que não têm um link para nenhum objeto no espaço do conector.
Para mapear objetos dentro de uma fonte de dados conectada para um tipo de objeto correspondente no metaverso, o mecanismo de sincronização fornece um esquema extensível com um conjunto predefinido de tipos de objeto e atributos associados. Você pode criar novos tipos de objetos e atributos para objetos do metaverso. Os atributos podem ser de valor único ou multivalorado, e os tipos de atributos podem ser cadeias de caracteres, referências, números e valores booleanos.
Relações entre objetos de preparação e objetos do metaverso
Dentro do namespace do motor de sincronização, o fluxo de dados é habilitado pela relação de ligação entre objetos de preparo e objetos do metaverso. Um objeto de preparação vinculado a um objeto do metaverso é chamado de objeto associado (ou objeto conector ). Um objeto de estágio que não está vinculado a um objeto do metaverso é chamado de objeto separado (ou objeto de desconexão ). Os termos unidos e desunidos são preferidos para não confundir com os conectores responsáveis por importar e exportar dados de um diretório conectado.
Os espaços reservados nunca são vinculados a um objeto do metaverso
Um objeto unido compreende um objeto de preparação e sua relação associada a um único objeto do metaverso. Objetos unidos são usados para sincronizar valores de atributos entre um objeto no espaço de conector e um objeto no metaverso.
Quando um objeto de preparação se torna um objeto associado durante a sincronização, os atributos podem fluir entre o objeto de preparação e o objeto do metaverso. O fluxo de atributos é bidirecional e é configurado usando regras de atributo de importação e regras de atributo de exportação.
Um único objeto de espaço de conector pode ser vinculado a apenas um objeto de metaverso. No entanto, cada objeto do metaverso pode ser vinculado a vários objetos de espaço de conector no mesmo ou em espaços de conector diferentes, conforme mostrado na ilustração a seguir.
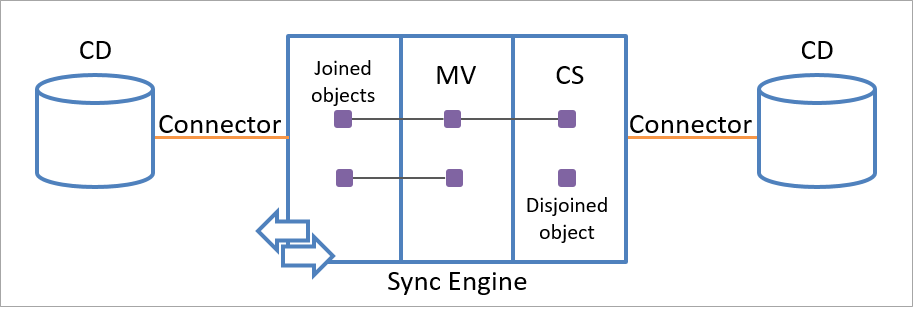
Somente as regras que especificar podem remover a relação vinculada persistente entre o objeto de estágio e um objeto do metaverso.
Um objeto desagregado é um objeto de estágio que não está vinculado a nenhum objeto do metaverso. Os valores de atributo de um objeto separado não são processados mais dentro do metaverso. Os valores de atributo do objeto correspondente na fonte de dados conectada não são atualizados pelo mecanismo de sincronização.
Usando objetos separados, você pode armazenar informações de identidade no mecanismo de sincronização e processá-las posteriormente. Manter um objeto de encenação como um objeto separado no espaço do conector tem muitas vantagens. Como o sistema preparou as informações necessárias sobre esse objeto, não é necessário criar uma representação desse objeto novamente durante a próxima importação da fonte de dados conectada. Dessa forma, o mecanismo de sincronização sempre tem um instantâneo completo da fonte de dados conectada, mesmo que não haja nenhuma conexão atual com a fonte de dados conectada. Os objetos desunidos podem ser convertidos em objetos associados e vice-versa, dependendo das regras especificadas.
Um objeto import é criado como um objeto separado. Um objeto de exportação deve ser um objeto associado. A lógica do sistema impõe essa regra e exclui todos os objetos de exportação que não são um objeto associado.
Processo de gestão de identidade do motor de sincronização
O processo de gerenciamento de identidade controla como as informações de identidade são atualizadas entre diferentes fontes de dados conectadas. O gerenciamento de identidade ocorre em três processos:
- Importação
- Sincronização
- Exportação
Durante o processo de importação, o mecanismo de sincronização avalia as informações de identidade de entrada de uma fonte de dados conectada. Quando as alterações são detetadas, ele cria novos objetos de preparo ou atualiza os objetos de preparo existentes no espaço do conector para sincronização.
Durante o processo de sincronização, o mecanismo de sincronização atualiza o metaverso para refletir as alterações no espaço do conector. Atualiza também o espaço do conector para refletir as mudanças no metaverso.
Durante o processo de exportação, o mecanismo de sincronização envia as alterações que são preparadas em objetos de preparo e que são sinalizadas como exportação pendente.
A ilustração a seguir mostra onde cada um dos processos ocorre à medida que as informações de identidade fluem de uma fonte de dados conectada para outra.

Processo de importação
Durante o processo de importação, o mecanismo de sincronização avalia as atualizações das informações de identidade. O mecanismo de sincronização compara as informações de identidade recebidas da fonte de dados conectada com as informações de identidade sobre um objeto de preparação. Ele determina se o objeto de encenação requer atualizações. Se for necessário atualizar o objeto de preparação com novos dados, o objeto de preparação será sinalizado como importação pendente.
Ao organizar objetos no espaço do conector antes da sincronização, o mecanismo de sincronização pode processar só as informações de identidade alteradas. Este processo proporciona os seguintes benefícios:
- Sincronização eficiente. A quantidade de dados processados durante a sincronização é minimizada.
- Ressincronização eficiente. Você pode alterar a forma como o mecanismo de sincronização processa informações de identidade sem reconectar o mecanismo de sincronização à fonte de dados.
- Oportunidade de visualizar a sincronização. Você pode visualizar a sincronização para verificar se suas suposições sobre o processo de gerenciamento de identidade estão corretas.
Para cada objeto especificado no conector, o mecanismo de sincronização primeiro tenta localizar uma representação do objeto no espaço do conector do conector. O mecanismo de sincronização examina todos os objetos de preparo no espaço do conector e tenta encontrar um objeto de preparo correspondente que tenha um atributo de âncora correspondente. Se nenhum objeto de preparo existente tiver um atributo de âncora correspondente, o mecanismo de sincronização tentará localizar um objeto de preparo correspondente com o mesmo nome distinto.
Quando o mecanismo de sincronização encontra um objeto de preparação que corresponde por nome distinto (distinguished name), mas não por âncora, ocorre o seguinte comportamento especial:
- Se o objeto localizado no espaço do conector não tiver âncora, o mecanismo de sincronização removerá esse objeto do espaço do conector e marcará o objeto do metaverso ao qual ele está vinculado como provisionamento de nova tentativa na próxima execução de sincronização. Em seguida, ele cria o novo objeto de importação.
- Se o objeto localizado no espaço do conector tiver uma âncora, o mecanismo de sincronização assumirá que esse objeto será renomeado ou excluído no diretório conectado. É atribuído um nome distinto temporário ao objeto no espaço do conector para que possa processar o objeto de entrada. O objeto antigo então se torna transitório, aguardando que o Conector importe a renomeação ou exclusão para resolver a situação.
Objetos transitórios nem sempre são um problema, e você pode vê-los mesmo em um ambiente saudável. Com API de ponto de extremidade do Microsoft Entra Connect Sync V2, os objetos transitórios devem ser resolvidos automaticamente nos ciclos de sincronização delta subsequentes. Um exemplo comum em que você pode encontrar objetos transitórios sendo gerados ocorre em servidores Microsoft Entra Connect instalados no modo de preparo. Isso acontece quando um administrador exclui permanentemente um objeto diretamente no Microsoft Entra ID usando o PowerShell e depois sincroniza o objeto novamente.
Se o mecanismo de sincronização localizar um objeto de estágio que corresponda ao objeto especificado no Conector, determinará que tipo de alterações devem ser aplicadas. Por exemplo, o mecanismo de sincronização pode renomear ou excluir o objeto na fonte de dados conectada ou pode atualizar apenas os valores de atributo do objeto.
Os objetos de preparação com dados atualizados são marcados como pendentes de importação. Estão disponíveis diferentes tipos de importações pendentes. Dependendo do resultado do processo de importação, um objeto em preparação no espaço do conector tem um dos seguintes tipos de importação pendentes:
- Nenhum. Nenhuma alteração está disponível em nenhum dos atributos do objeto de preparação. O mecanismo de sincronização não sinaliza esse tipo como importação pendente.
- Adicionar. O objeto de preparação é um novo objeto de importação no espaço do conetor. O mecanismo de sincronização sinaliza esse tipo como importação pendente para processamento adicional no metaverso.
- Atualização. O mecanismo de sincronização localiza um objeto de preparo correspondente no espaço do conector e sinaliza esse tipo como importação pendente para que as atualizações dos atributos possam ser processadas no metaverso. As atualizações incluem renomeação de objetos.
- Excluir. O mecanismo de sincronização localiza um objeto de preparo correspondente no espaço do conector e sinaliza esse tipo como importação pendente para que o objeto associado possa ser excluído.
- Excluir/Adicionar. O mecanismo de sincronização encontra um objeto de preparação correspondente no espaço do conector, mas os tipos de objetos não correspondem. Nesse caso, uma modificação de eliminação-adição é programada. Uma modificação delete-add indica ao mecanismo de sincronização que uma ressincronização completa desse objeto deve ocorrer porque diferentes conjuntos de regras se aplicam a esse objeto quando o tipo de objeto é alterado.
Ao definir o status de importação pendente de um objeto de preparação, é possível reduzir significativamente a quantidade de dados processados durante a sincronização. Isso permite que o sistema processe apenas os objetos que têm dados atualizados.
Processo de sincronização
A sincronização consiste em dois processos relacionados:
- Sincronização de entrada, quando o conteúdo do metaverso é atualizado usando os dados no espaço do conector.
- Sincronização de saída, quando o conteúdo do espaço do conector é atualizado usando dados no metaverso.
Usando as informações preparadas no espaço do conector, o processo de sincronização de entrada cria uma exibição integrada dos dados no metaverso que são armazenados nas fontes de dados conectadas. Todos os objetos de preparação ou apenas aqueles com informações de importação pendentes são agregados, dependendo de como as regras são configuradas.
O processo de sincronização de saída atualiza os objetos de exportação quando os objetos do metaverso são alterados.
A sincronização de entrada cria a exibição integrada no metaverso das informações de identidade recebidas das fontes de dados conectadas. O mecanismo de sincronização pode processar informações de identidade a qualquer momento usando as informações de identidade mais recentes que ele tem da fonte de dados conectada.
Sincronização de entrada
A sincronização de entrada inclui os seguintes processos:
- Provisionamento (também chamado de Projeção se for importante distinguir esse processo do provisionamento de sincronização de saída). O Mecanismo de Sincronização cria um novo objeto do Metaverso partindo de um objeto de estágio e os vincula. A provisão é uma operação no nível do objeto.
- Junte-se a. O motor de sincronização liga um objeto de preparação a um objeto de metaverso existente. Uma junção é uma operação no nível do objeto.
- Fluxo de atributos de importação. O mecanismo de sincronização atualiza os valores de atributo, chamados fluxo de atributos, do objeto no metaverso. O fluxo de atributos de importação é uma operação ao nível de atributo que requer uma ligação entre um objeto de encenação e um objeto de metaverso.
A provisão é o único processo que cria objetos no metaverso. A provisão afeta apenas os objetos de importação que são objetos desassociados. Durante o provisionamento, o mecanismo de sincronização cria um objeto de metaverso que corresponde ao tipo de objeto do objeto de importação e estabelece um vínculo entre ambos os objetos, criando assim um objeto associado.
O processo de junção também estabelece um vínculo entre objetos de importação e um objeto de metaverso. O processo de junção requer que o objeto de importação seja vinculado a um objeto de metaverso existente. No entanto, o processo de provisão cria um novo objeto metaverso.
O mecanismo de sincronização tenta unir um objeto de importação a um objeto de metaverso usando critérios especificados na configuração da Regra de Sincronização.
Durante os processos de provisionamento e junção, o mecanismo de sincronização vincula um objeto separado a um objeto do metaverso, tornando-os unidos. Depois que essas operações no nível do objeto forem concluídas, o mecanismo de sincronização poderá atualizar os valores de atributo do objeto metaverso associado. Esse processo é chamado de fluxo de atributos de importação.
O fluxo de atributos de importação ocorre em todos os objetos de importação que carregam novos dados e estão vinculados a um objeto do metaverso.
de sincronização de saída
As atualizações de sincronização de saída exportam objetos quando um objeto do metaverso é alterado, mas não é excluído. O objetivo da sincronização outbound é avaliar se as alterações nos objetos do metaverso exigem atualizações nos objetos de preparo nos espaços dos conectores. Em alguns casos, as alterações podem exigir que os objetos de preparo em todos os espaços do conector sejam atualizados. Os objetos de preparação alterados são sinalizados como pendentes de exportação, tornando-os objetos de exportação. Esses objetos de exportação são posteriormente enviados para a fonte de dados conectada durante o processo de exportação.
A sincronização de saída tem três processos:
- Provisionamento
- Desprovisionamento
- Fluxo de atributos de exportação
O provisionamento e o desprovisionamento são operações no nível do objeto. O desprovisionamento depende do provisionamento, uma vez que somente o provisionamento pode iniciá-lo. O desprovisionamento é acionado quando o provisionamento remove o vínculo entre um objeto do metaverso e um objeto de exportação.
O provisionamento é sempre acionado quando as alterações são aplicadas a objetos no metaverso. Quando são feitas alterações em objetos do metaverso, o mecanismo de sincronização pode executar qualquer uma das seguintes tarefas como parte do processo de provisionamento:
- Crie objetos associados, onde um objeto do metaverso está vinculado a um objeto de exportação recém-criado.
- Renomeie um objeto associado.
- Desvincule ligações entre um objeto do metaverso e objetos de preparação, criando um objeto desconectado.
Se o provisionamento exigir que o motor de sincronização crie um novo objeto de conector, o objeto de preparação vinculado ao objeto metaverso será sempre exportado. Isso ocorre porque o objeto ainda não existe na fonte de dados conectada.
Se o provisionamento exigir que o mecanismo de sincronização desassocie um objeto associado, criando um objeto desassociado, o desprovisionamento será acionado. O processo de desprovisionamento exclui o objeto.
Durante o desprovisionamento, a exclusão de um objeto de exportação não exclui fisicamente o objeto. O objeto é sinalizado como apagado, o que significa que a operação de eliminação está planeada no objeto.
O fluxo de atributos de exportação também ocorre durante o processo de sincronização de saída, semelhante à maneira como o fluxo de atributos de importação ocorre durante a sincronização de entrada. O fluxo de atributos de exportação ocorre somente entre o metaverso e os objetos de exportação que são unidos.
Processo de exportação
Durante o processo de exportação, o mecanismo de sincronização examina todos os objetos de exportação sinalizados como exportação pendente no espaço do conector e, em seguida, envia atualizações para a fonte de dados conectada.
O mecanismo de sincronização pode determinar o sucesso de uma exportação, mas não pode determinar suficientemente se o processo de gerenciamento de identidade está concluído. Outros processos sempre podem alterar objetos na fonte de dados conectada. Como o mecanismo de sincronização não tem uma conexão persistente com a fonte de dados conectada, não é suficiente fazer suposições sobre as propriedades de um objeto na fonte de dados conectada com base apenas em uma notificação de exportação bem-sucedida.
Por exemplo, um processo na fonte de dados conectada pode alterar os atributos do objeto de volta aos seus valores originais (ou seja, a fonte de dados conectada pode substituir os valores imediatamente após os dados serem enviados pelo mecanismo de sincronização e aplicados com êxito na fonte de dados conectada).
O mecanismo de sincronização armazena informações de status de exportação e importação sobre cada objeto de estágio. Se os valores dos atributos especificados na lista de inclusão de atributos tiverem sido alterados desde a última exportação, o armazenamento do status de importação e exportação permitirá que o mecanismo de sincronização reaja adequadamente. O mecanismo de sincronização usa o processo de importação para confirmar valores de atributos que foram exportados para a fonte de dados conectada. Uma comparação entre as informações importadas e exportadas, conforme mostrado na ilustração a seguir, permite que o mecanismo de sincronização determine se a exportação foi bem-sucedida ou se precisa ser repetida.
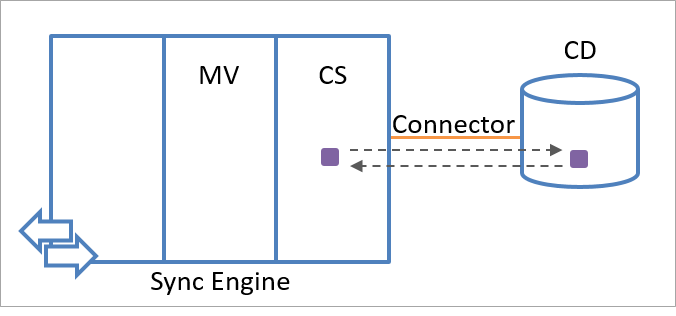
Por exemplo, se o mecanismo de sincronização exportar o atributo C, que tem um valor de 5, para uma fonte de dados conectada, ele armazenará C=5 em sua memória de status de exportação. Cada exportação adicional neste objeto resulta em uma tentativa de exportar C=5 para a fonte de dados conectada novamente porque o mecanismo de sincronização pressupõe que esse valor não tenha sido aplicado persistentemente ao objeto (ou seja, a menos que um valor diferente tenha sido importado recentemente da fonte de dados conectada). A memória de exportação é limpa quando C=5 é recebido durante uma operação de importação no objeto.
Próximos passos
Saiba mais sobre a configuração de Microsoft Entra Connect Sync.
Saiba mais sobre Integrar as suas identidades locais com a Microsoft Entra ID.