Considerações de desempenho para EF 4, 5 e 6
Por David Obando, Eric Dettinger e outros
Publicado em: abril de 2012
Última atualização: maio de 2014
1. Introdução
As estruturas de Mapeamento Relacional de Objeto são uma maneira conveniente de fornecer uma abstração para acesso a dados em um aplicativo orientado a objetos. Para aplicativos .NET, o O/RM recomendado da Microsoft é o Entity Framework. Com qualquer abstração, porém, o desempenho pode se tornar uma preocupação.
Este white paper foi escrito para mostrar as considerações de desempenho ao desenvolver aplicativos usando o Entity Framework, para dar aos desenvolvedores uma ideia dos algoritmos internos do Entity Framework que podem afetar o desempenho e fornecer dicas para investigação e melhoria do desempenho em seus aplicativos que usam o Entity Framework. Há uma série de bons tópicos sobre o desempenho já disponíveis na Web e também tentamos apontar para esses recursos sempre que possível.
O desempenho é um tópico complicado. Esse white paper destina-se a ser a um recurso para ajudar você a tomar decisões relacionadas ao desempenho para seus aplicativos que usam o Entity Framework. Incluímos algumas métricas de teste para demonstrar o desempenho, mas essas métricas não são destinadas como indicadores absolutos do desempenho que você verá em seu aplicativo.
Para fins práticos, este documento pressupõe que o Entity Framework 4 seja executado no .NET 4.0 e o Entity Framework 5 e 6 sejam executados no .NET 4.5. Muitas das melhorias de desempenho feitas para o Entity Framework 5 residem nos componentes principais que são fornecidos com o .NET 4.5.
O Entity Framework 6 é uma versão fora da banda e não depende dos componentes do Entity Framework que são fornecidos com o .NET. O Entity Framework 6 funciona no .NET 4.0 e no .NET 4.5 e pode oferecer um grande benefício de desempenho para aqueles que não atualizaram do .NET 4.0, mas querem os bits mais recentes do Entity Framework em seu aplicativo. Quando este documento menciona o Entity Framework 6, ele se refere à versão mais recente disponível no momento desta gravação: versão 6.1.0.
2. Execução de consulta em armazenamento cold vs. consulta warm
Na primeira vez que qualquer consulta é feita em relação a um determinado modelo, o Entity Framework trabalha muito nos bastidores para carregar e validar o modelo. Frequentemente, nos referimos a essa primeira consulta como uma consulta "cold". Consultas adicionais em um modelo já carregado são conhecidas como consultas "warm" e são muito mais rápidas.
Vamos ter uma visão de alto nível de onde o tempo é gasto ao executar uma consulta usando o Entity Framework e ver onde as coisas estão melhorando no Entity Framework 6.
Primeira execução de consulta – consulta em armazenamento cold
| Gravações do usuário de código | Ação | Impacto no desempenho do EF4 | Impacto no desempenho do EF5 | Impacto no desempenho do EF6 |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Criação de contexto | Médio | Médio | Baixo |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Criação de expressão de consulta | Baixo | Baixo | Baixo |
var c1 = q1.First(); |
Execução da consulta LINQ | - Carregamento de metadados: alto, mas armazenado em cache - Geração de exibição: potencialmente muito alta, mas armazenada em cache - Avaliação de parâmetro: médio - Tradução de consulta: médio - Geração do materializador: médio, mas armazenado em cache - Execução da consulta de banco de dados: potencialmente alta + Connection.Open + Command.ExecuteReader + DataReader.Read Materialização de objetos: médio - Pesquisa de identidade: médio |
- Carregamento de metadados: alto, mas armazenado em cache - Geração de exibição: potencialmente muito alta, mas armazenada em cache - Avaliação de parâmetro: baixo - Tradução de consulta: média, mas armazenada em cache - Geração do materializador: médio, mas armazenado em cache - Execução da consulta de banco de dados: potencialmente alta (melhores consultas em algumas situações) + Connection.Open + Command.ExecuteReader + DataReader.Read Materialização de objetos: médio - Pesquisa de identidade: médio |
- Carregamento de metadados: alto, mas armazenado em cache - Geração de exibição: média, mas armazenada em cache - Avaliação de parâmetro: baixo - Tradução de consulta: média, mas armazenada em cache - Geração do materializador: médio, mas armazenado em cache - Execução da consulta de banco de dados: potencialmente alta (melhores consultas em algumas situações) + Connection.Open + Command.ExecuteReader + DataReader.Read Materialização de objeto: médio (mais rápido que EF5) - Pesquisa de identidade: médio |
} |
Connection.Close | Baixo | Baixo | Baixo |
Segunda Execução de Consulta – consulta warm
| Gravações do usuário de código | Ação | Impacto no desempenho do EF4 | Impacto no desempenho do EF5 | Impacto no desempenho do EF6 |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Criação de contexto | Médio | Médio | Baixo |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Criação de expressão de consulta | Baixo | Baixo | Baixo |
var c1 = q1.First(); |
Execução da consulta LINQ | - Pesquisa de - Exibir - Avaliação de parâmetro: médio - Pesquisa – Pesquisa de - Execução da consulta de banco de dados: potencialmente alta + Connection.Open + Command.ExecuteReader + DataReader.Read Materialização de objetos: médio - Pesquisa de identidade: médio |
- Pesquisa de - Exibir - Avaliação de parâmetro: baixo - Pesquisa de – Pesquisa de - Execução da consulta de banco de dados: potencialmente alta (melhores consultas em algumas situações) + Connection.Open + Command.ExecuteReader + DataReader.Read Materialização de objetos: médio - Pesquisa de identidade: médio |
- Pesquisa de - Exibir pesquisa de - Avaliação de parâmetro: baixo - Pesquisa de – Pesquisa de - Execução da consulta de banco de dados: potencialmente alta (melhores consultas em algumas situações) + Connection.Open + Command.ExecuteReader + DataReader.Read Materialização de objeto: médio (mais rápido que EF5) - Pesquisa de identidade: médio |
} |
Connection.Close | Baixo | Baixo | Baixo |
Há várias maneiras de reduzir o custo de desempenho de consultas em armazenamento cold e consultas warm, e vamos dar uma olhada nelas na seção a seguir. Especificamente, vamos analisar a redução do custo do carregamento do modelo em consultas em armazenamento cold usando exibições pré-geradas, o que deve ajudar a aliviar as dores de desempenho experimentadas durante a geração de exibição. Para consultas warm, abordaremos o cache do plano de consulta, nenhuma consulta de acompanhamento e diferentes opções de execução de consulta.
2.1 O que é Geração de exibição?
Para entender qual é a geração de exibição, primeiro devemos entender o que são "Exibições de mapeamento". Exibições de mapeamento são representações executáveis das transformações especificadas no mapeamento para cada conjunto de entidades e associação. Internamente, essas exibições de mapeamento tomam a forma de CQTs (árvores de consulta canônicas). Há dois tipos de exibições de mapeamento:
- Exibições de consulta: elas representam a transformação necessária para ir do esquema de banco de dados para o modelo conceitual.
- Exibições de atualização: eles representam a transformação necessária para ir do modelo conceitual para o esquema de banco de dados.
Tenha em mente que o modelo conceitual pode ser diferente do esquema de banco de dados de várias maneiras. Por exemplo, uma única tabela pode ser usada para armazenar os dados para dois tipos de entidade diferentes. Os mapeamentos de herança e não triviais desempenham um papel na complexidade das exibições de mapeamento.
O processo de computação dessas exibições com base na especificação do mapeamento é o que chamamos de geração de exibição. A geração de exibição pode ocorrer dinamicamente quando um modelo é carregado ou em tempo de build usando "exibições pré-geradas"; este último é serializado na forma de instruções Entity SQL para um arquivo C# ou VB.
Quando as exibições são geradas, elas também são validadas. Do ponto de vista do desempenho, a grande maioria do custo de geração de exibição é, na verdade, a validação das exibições que garante que as conexões entre as entidades façam sentido e tenham a cardinalidade correta para todas as operações com suporte.
Quando uma consulta em um conjunto de entidades é executada, a consulta é combinada com a exibição de consulta correspondente e o resultado dessa composição é executado por meio do compilador de planos para criar a representação da consulta que o repositório de backup pode entender. Para o SQL Server, o resultado final dessa compilação será uma instrução T-SQL SELECT. Na primeira vez que uma atualização em um conjunto de entidades é executada, a exibição de atualização é executada por meio de um processo semelhante para transformá-la em instruções DML para o banco de dados de destino.
2.2 Fatores que afetam o desempenho de Geração de exibição
O desempenho da etapa de geração de exibição não depende apenas do tamanho do modelo, mas também de como o modelo está interconectado. Se duas entidades estiverem conectadas por meio de uma cadeia de herança ou de uma Associação, elas serão conectadas. Da mesma forma, se duas tabelas estiverem conectadas por meio de uma chave estrangeira, elas serão conectadas. À medida que o número de entidades e tabelas conectadas em seus esquemas aumenta, o custo de geração de exibição aumenta.
O algoritmo que usamos para gerar e validar exibições é exponencial na pior das hipóteses, embora usemos algumas otimizações para melhorar isso. Os maiores fatores que parecem afetar negativamente o desempenho são:
- Tamanho do modelo, referindo-se ao número de entidades e à quantidade de associações entre essas entidades.
- Complexidade do modelo, especificamente herança envolvendo um grande número de tipos.
- Usando associações independentes, em vez de associações de chave estrangeira.
Para modelos pequenos e simples, o custo pode ser pequeno o suficiente para não se preocupar com o uso de exibições pré-geradas. À medida que o tamanho do modelo e a complexidade aumentam, há várias opções disponíveis para reduzir o custo de geração e validação do modo de exibição.
2.3 Usando exibições pré-geradas para diminuir o tempo de carga do modelo
Para obter informações detalhadas sobre como usar exibições pré-geradas no Entity Framework 6, visite exibições de mapeamento pré-geradas
2.3.1 Exibições pré-geradas usando o Entity Framework Power Tools Community Edition
Você pode usar o Entity Framework 6 Power Tools Community Edition para gerar exibições de modelos EDMX e Code First clicando com o botão direito do mouse no arquivo de classe de modelo e usando o menu Entity Framework para selecionar "Gerar exibições". O Entity Framework Power Tools Community Edition funciona apenas em contextos derivados de DbContext.
2.3.2 Como usar exibições pré-geradas com um modelo criado pelo EDMGen
O EDMGen é um utilitário que é fornecido com .NET e funciona com o Entity Framework 4 e 5, mas não com o Entity Framework 6. O EDMGen permite que você gere um arquivo de modelo, a camada de objeto e as exibições da linha de comando. Uma das saídas será um arquivo Exibições em seu idioma de escolha, VB ou C#. Este é um arquivo de código que contém snippets da Entity SQL para cada conjunto de entidades. Para habilitar exibições pré-geradas, basta incluir o arquivo em seu projeto.
Se você fizer edições manualmente nos arquivos de esquema do modelo, precisará gerar novamente o arquivo de exibições. Você pode fazer isso executando EDMGen com o sinalizador /mode:ViewGeneration.
2.3.3 Como usar exibições pré-geradas com um arquivo EDMX
Você também pode usar o EDMGen para gerar exibições para um arquivo EDMX - o tópico MSDN referenciado anteriormente descreve como adicionar um evento de pré-build para fazer isso - mas isso é complicado e há alguns casos em que não é possível. Geralmente, é mais fácil usar um modelo T4 para gerar as exibições quando o modelo está em um arquivo edmx.
O blog da equipe ADO.NET tem uma postagem que descreve como usar um modelo T4 para geração de exibição ( <https://learn.microsoft.com/archive/blogs/adonet/how-to-use-a-t4-template-for-view-generation>). Esta postagem inclui um modelo que pode ser baixado e adicionado ao seu projeto. O modelo foi escrito para a primeira versão do Entity Framework, portanto, eles não têm garantia de trabalhar com as versões mais recentes do Entity Framework. No entanto, você pode baixar um conjunto mais atualizado de modelos de geração de exibição para o Entity Framework 4 e 5 da Galeria do Visual Studio:
- VB.NET: <http://visualstudiogallery.msdn.microsoft.com/118b44f2-1b91-4de2-a584-7a680418941d>
- C#: <http://visualstudiogallery.msdn.microsoft.com/ae7730ce-ddab-470f-8456-1b313cd2c44d>
Se você estiver usando o Entity Framework 6, poderá obter os modelos T4 de geração de exibição da Galeria do Visual Studio em <http://visualstudiogallery.msdn.microsoft.com/18a7db90-6705-4d19-9dd1-0a6c23d0751f>.
2.4 Reduzindo o custo da geração de exibição
O uso de exibições pré-geradas move o custo da geração de exibição do carregamento do modelo (tempo de execução) para o tempo de design. Embora isso melhore o desempenho da inicialização em runtime, você ainda experimentará a dor da geração de exibição enquanto estiver desenvolvendo. Existem vários truques adicionais que podem ajudar a reduzir o custo de geração de exibição, tanto em tempo de compilação quanto em tempo de execução.
2.4.1 Usando associações de chave estrangeira para reduzir o custo de geração de exibição
Vimos uma série de casos em que a mudança das associações no modelo de Associações Independentes para Associações de Chaves Estrangeiras melhorou drasticamente o tempo gasto na geração de exibição.
Para demonstrar essa melhoria, geramos duas versões do modelo Navision usando o EDMGen. Observação: consulte o apêndice C para obter uma descrição do modelo Navision. O modelo Navision é interessante para esse exercício devido à sua grande quantidade de entidades e relações entre elas.
Uma versão desse modelo muito grande foi gerada com Associações de Chaves Estrangeiras e a outra foi gerada com Associações Independentes. Em seguida, cronometramos quanto tempo levou para gerar as exibições para cada modelo. O teste do Entity Framework 5 usou o método GenerateViews() da classe EntityViewGenerator para gerar as exibições, enquanto o teste do Entity Framework 6 usou o método GenerateViews() da classe StorageMappingItemCollection. Isso devido à reestruturação de código que ocorreu na base de código do Entity Framework 6.
Usando o Entity Framework 5, a geração de exibição do modelo com Chaves Estrangeiras levou 65 minutos em um computador de laboratório. Não se sabe quanto tempo levaria para gerar as exibições para o modelo que usava associações independentes. Deixamos o teste em execução por mais de um mês antes de o computador ser reinicializado em nosso laboratório para instalar atualizações mensais.
Usando o Entity Framework 6, a geração de exibição do modelo com Chaves Estrangeiras levou 28 segundos no mesmo computador de laboratório. A geração de exibição do modelo que usa Associações Independentes levou 58 segundos. As melhorias feitas no Entity Framework 6 em seu código de geração de exibição significam que muitos projetos não precisarão de exibições pré-geradas para obter tempos de inicialização mais rápidos.
É importante observar que as exibições de pré-geração no Entity Framework 4 e 5 podem ser feitas com o EDMGen ou o Entity Framework Power Tools. Para a geração de exibição do Entity Framework 6 pode ser feita por meio do Entity Framework Power Tools ou programaticamente, conforme descrito nas exibições de mapeamento pré-geradas.
2.4.1.1 Como usar chaves estrangeiras em vez de associações independentes
Ao usar o EDMGen ou o Designer de Entidade no Visual Studio, você obtém FKs por padrão e é necessário apenas uma única caixa de seleção ou sinalizador de linha de comando para alternar entre FKs e E/S.
Se você tiver um modelo Code First grande, usar Associações Independentes terá o mesmo efeito na geração de exibição. Você pode evitar esse impacto incluindo propriedades de Chave Estrangeira nas classes para seus objetos dependentes, embora alguns desenvolvedores considerem que isso está poluindo seu modelo de objeto. Você pode encontrar mais informações sobre esse assunto em <http://blog.oneunicorn.com/2011/12/11/whats-the-deal-with-mapping-foreign-keys-using-the-entity-framework/>.
| Ao usar | Faça isto |
|---|---|
| Entity Designer | Depois de adicionar uma associação entre duas entidades, verifique se você tem uma restrição referencial. Restrições referenciais dizem ao Entity Framework para usar chaves estrangeiras em vez de associações independentes. Para obter mais detalhes, visite <https://learn.microsoft.com/archive/blogs/efdesign/foreign-keys-in-the-entity-framework>. |
| EDMGen | Ao usar o EDMGen para gerar seus arquivos do banco de dados, suas Chaves Estrangeiras serão respeitadas e adicionadas ao modelo como tal. Para obter mais informações sobre as diferentes opções expostas pelo EDMGen, visite http://msdn.microsoft.com/library/bb387165.aspx. |
| Code First | Consulte a seção "Convenção de Relação" do tópico Code First Conventions para obter informações sobre como incluir propriedades de chave estrangeira em objetos dependentes ao usar o Code First. |
2.4.2 Movendo seu modelo para um assembly separado
Quando o modelo é incluído diretamente no projeto do aplicativo e você gera exibições por meio de um evento de pré-build ou um modelo T4, a geração e a validação de exibição ocorrerão sempre que o projeto for recriado, mesmo que o modelo não tenha sido alterado. Se você mover o modelo para um assembly separado e referenciá-lo do projeto do aplicativo, poderá fazer outras alterações em seu aplicativo sem precisar recriar o projeto que contém o modelo.
Observação: ao mover o modelo para assemblies separados, lembre-se de copiar as cadeias de conexão do modelo para o arquivo de configuração do aplicativo do projeto cliente.
2.4.3 Desabilitar a validação de um modelo baseado em EDMX
Os modelos EDMX são validados em tempo de compilação, mesmo que o modelo não esteja alterado. Se o modelo já tiver sido validado, você poderá suprimir a validação em tempo de compilação definindo a propriedade "Validar no Build" como false na janela de propriedades. Ao alterar seu mapeamento ou modelo, você pode reabilitar temporariamente a validação para verificar suas alterações.
Observe que foram feitas melhorias de desempenho no Entity Framework Designer para o Entity Framework 6 e o custo do "Validar no Build" é muito menor do que nas versões anteriores do designer.
3 Cache no Entity Framework
O Entity Framework tem as seguintes formas de cache internas:
- Cache de objeto – o ObjectStateManager integrado a uma instância ObjectContext mantém o controle na memória dos objetos que foram recuperados usando essa instância. Isso também é conhecido como cache de primeiro nível.
- Cache do Plano de Consulta – reutilizando o comando do repositório gerado quando uma consulta é executada mais de uma vez.
- Cache de metadados – compartilhando os metadados de um modelo em diferentes conexões com o mesmo modelo.
Além dos caches que o EF fornece prontos para uso, um tipo especial de provedor de dados ADO.NET conhecido como um provedor de encapsulamento também pode ser usado para estender o Entity Framework com um cache para os resultados recuperados do banco de dados, também conhecido como cache de segundo nível.
3.1 Cache de objeto
Por padrão, quando uma entidade é retornada nos resultados de uma consulta, pouco antes de o EF materializá-la, o ObjectContext verificará se uma entidade com a mesma chave já foi carregada em seu ObjectStateManager. Se uma entidade com as mesmas chaves já estiver presente, o EF a incluirá nos resultados da consulta. Embora o EF ainda emita a consulta no banco de dados, esse comportamento pode ignorar grande parte do custo de materialização da entidade várias vezes.
3.1.1 Obtendo entidades do cache de objetos usando dbContext Find
Ao contrário de uma consulta regular, o método Find em DbSet (APIs incluídas pela primeira vez no EF 4.1) executará uma pesquisa na memória antes mesmo de emitir a consulta no banco de dados. É importante observar que duas instâncias diferentes de ObjectContext terão duas instâncias objectStateManager diferentes, o que significa que elas têm caches de objeto separados.
O método Find no DbSet usa o valor da chave primária para tentar localizar uma entidade rastreada pelo contexto. Se a entidade não estiver no contexto, uma consulta será executada e avaliada no banco de dados e será retornada em nulo se a entidade não for encontrada no contexto ou no banco de dados. Observe que Find também retorna entidades que foram adicionadas ao contexto, mas ainda não foram salvas no banco de dados.
Há uma consideração de desempenho a ser tomada ao usar o Find. Invocações para esse método por padrão dispararão uma validação do cache de objetos para detectar alterações que ainda estão pendentes no banco de dados. Esse processo pode ser muito caro se houver um número muito grande de objetos no cache de objetos ou em um grafo de objeto grande sendo adicionado ao cache de objetos, mas também pode ser desabilitado. Em determinados casos, você pode perceber uma ordem de magnitude de diferença ao chamar o método Find ao desabilitar alterações de detecção automática. No entanto, uma segunda ordem de magnitude é percebida quando o objeto realmente está no cache versus quando o objeto precisa ser recuperado do banco de dados. Aqui está um grafo de exemplo com medidas feitas usando algumas de nossas marcas de microesferas, expressas em milissegundos, com uma carga de 5.000 entidades:

Exemplo de Find com alterações de detecção automática desabilitadas:
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
context.Configuration.AutoDetectChangesEnabled = true;
...
O que você precisa considerar ao usar o método Find é:
- Se o objeto não estiver no cache, os benefícios de Find serão negados, mas a sintaxe ainda será mais simples do que uma consulta por chave.
- Se as alterações de detecção automática estiverem habilitadas, o custo do método Find poderá aumentar em uma ordem de magnitude ou até mais dependendo da complexidade do seu modelo e da quantidade de entidades no cache de objetos.
Além disso, tenha em mente que Find retorna apenas a entidade que você está procurando e ela não carrega automaticamente suas entidades associadas se elas ainda não estiverem no cache de objetos. Se você precisar recuperar entidades associadas, poderá usar uma consulta por chave com carregamento adiantado. Para obter mais informações, consulte 8.1 Carregamento lento vs. carregamento adiantado.
3.1.2 Problemas de desempenho quando o cache de objetos tem muitas entidades
O cache de objetos ajuda a aumentar a capacidade de resposta geral do Entity Framework. No entanto, quando o cache de objetos tem uma quantidade muito grande de entidades carregadas, ele pode afetar determinadas operações, como Add, Remove, Find, Entry, SaveChanges e muito mais. Em particular, as operações que disparam uma chamada para DetectChanges serão afetadas negativamente por caches de objetos muito grandes. DetectChanges sincroniza o grafo de objeto com o gerenciador de estado do objeto e seu desempenho será determinado diretamente pelo tamanho do grafo do objeto. Para obter mais informações sobre DetectChanges, consulte Controle de alterações em entidades POCO.
Ao usar o Entity Framework 6, os desenvolvedores podem chamar AddRange e RemoveRange diretamente em um DbSet, em vez de iterar em uma coleção e chamar Adicionar uma vez por instância. A vantagem de usar os métodos de intervalo é que o custo de DetectChanges é pago apenas uma vez pelo conjunto inteiro de entidades em vez de uma vez por cada entidade adicionada.
3.2 Cache do Plano de Consulta
Na primeira vez em que uma consulta é executada, ela passa pelo compilador de plano interno para converter a consulta conceitual no comando do repositório (por exemplo, o T-SQL que é executado quando executado no SQL Server). Se o cache do plano de consulta estiver habilitado, na próxima vez que a consulta for executada, o comando do repositório será recuperado diretamente do cache do plano de consulta para execução, ignorando o compilador de planos.
O cache do plano de consulta é compartilhado entre instâncias ObjectContext no mesmo AppDomain. Você não precisa manter uma instância objectContext para se beneficiar do cache do plano de consulta.
3.2.1 Algumas observações sobre o cache do plano de consulta
- O cache do plano de consulta é compartilhado para todos os tipos de consulta: objetos Entity SQL, LINQ to Entities e CompiledQuery.
- Por padrão, o cache do plano de consulta é habilitado para consultas Entity SQL, seja executadas por meio de um EntityCommand ou por meio de um ObjectQuery. Ele também é habilitado por padrão para consultas LINQ to Entities no Entity Framework no .NET 4.5 e no Entity Framework 6
- O cache do plano de consulta pode ser desabilitado definindo a propriedade EnablePlanCaching (em EntityCommand ou ObjectQuery) como false. Por exemplo:
var query = from customer in context.Customer
where customer.CustomerId == id
select new
{
customer.CustomerId,
customer.Name
};
ObjectQuery oQuery = query as ObjectQuery;
oQuery.EnablePlanCaching = false;
- Para consultas parametrizadas, a alteração do valor do parâmetro ainda atingirá a consulta armazenada em cache. Mas alterar as facetas de um parâmetro (por exemplo, tamanho, precisão ou escala) atingirá uma entrada diferente no cache.
- Ao usar o Entity SQL, a cadeia de caracteres de consulta faz parte da chave. Alterar a consulta resultará em entradas de cache diferentes, mesmo que as consultas sejam funcionalmente equivalentes. Isso inclui alterações na caixa ou no espaço em branco.
- Ao usar LINQ, a consulta é processada para gerar uma parte da chave. A alteração da expressão LINQ gerará, portanto, uma chave diferente.
- Outras limitações técnicas podem ser aplicadas; veja Consultas autocompiladas para obter mais detalhes.
3.2.2 Algoritmo de remoção de cache
Entender como o algoritmo interno funciona ajudará você a descobrir quando habilitar ou desabilitar o cache do plano de consulta. O algoritmo de limpeza é o seguinte:
- Depois que o cache contiver um número definido de entradas (800), iniciaremos um temporizador que periodicamente (uma vez por minuto) varre o cache.
- Durante as varreduras de cache, as entradas são removidas do cache em uma base LFRU (menos frequentemente – usada recentemente). Esse algoritmo leva em conta a contagem de ocorrências e a idade ao decidir quais entradas são ejetadas.
- No final de cada varredura de cache, o cache novamente contém 800 entradas.
Todas as entradas de cache são tratadas igualmente ao determinar quais entradas devem ser removidas. Isso significa que o comando de repositório para um CompiledQuery tem a mesma chance de remoção que o comando do repositório para uma consulta Entity SQL.
Observe que o temporizador de remoção de cache é iniciado quando há 800 entidades no cache, mas o cache é varrido apenas 60 segundos após o início desse temporizador. Isso significa que, por até 60 segundos, seu cache pode aumentar, sendo bastante grande.
3.2.3 Métricas de teste que demonstram o desempenho de cache do plano de consulta
Para demonstrar o efeito do cache do plano de consulta no desempenho do aplicativo, executamos um teste em que executamos várias consultas Entity SQL no modelo Navision. Consulte o apêndice para obter uma descrição do modelo Navision e os tipos de consultas que foram executadas. Neste teste, primeiro iteramos pela lista de consultas e executamos cada uma delas uma vez para adicioná-las ao cache (se o cache estiver habilitado). Esta etapa não é cronometrada. Em seguida, dormimos o thread principal por mais de 60 segundos para permitir que a varredura de cache ocorra; por fim, iteramos pela lista uma segunda vez para executar as consultas armazenadas em cache. Além disso, o cache de planos do SQL Server é liberado antes que cada conjunto de consultas seja executado para que as horas que obtemos reflitam com precisão o benefício fornecido pelo cache do plano de consulta.
3.2.3.1 Resultados de teste
| Teste | EF5 sem cache | EF5 armazenado em cache | EF6 sem cache | EF6 armazenado em cache |
|---|---|---|---|---|
| Enumerando todas as 18723 consultas | 124 | 125,4 | 124.3 | 125.3 |
| Evitando a varredura (apenas as primeiras 800 consultas, independentemente da complexidade) | 41.7 | 5.5 | 40,5 | 5.4 |
| Apenas as consultas AggregatingSubtotals (178 no total - o que evita a varredura) | 39,5 | 4.5 | 38,1 | 4.6 |
Todas as vezes em segundos.
Moral – ao executar muitas consultas distintas (por exemplo, consultas criadas dinamicamente), o cache não ajuda e a liberação resultante do cache pode manter as consultas que mais se beneficiariam do cache do plano de realmente usá-lo.
As consultas AggregatingSubtotals são as mais complexas das consultas com as quais testamos. Como esperado, quanto mais complexa for a consulta, mais benefício você verá com o cache do plano de consulta.
Como um CompiledQuery é realmente uma consulta LINQ com seu plano armazenado em cache, a comparação de um CompiledQuery versus a consulta Entity SQL equivalente deve ter resultados semelhantes. Na verdade, se um aplicativo tiver muitas consultas Entity SQL dinâmicas, preencher o cache com consultas também fará com que CompiledQueries "descompile" quando elas forem liberadas do cache. Nesse cenário, o desempenho pode ser melhorado desabilitando o cache nas consultas dinâmicas para priorizar as CompiledQueries. Melhor ainda, é claro, seria reescrever o aplicativo para usar consultas parametrizadas em vez de consultas dinâmicas.
3.3 Usando CompiledQuery para melhorar o desempenho com consultas LINQ
Nossos testes indicam que o uso do CompiledQuery pode trazer um benefício de 7% em relação às consultas LINQ autocompiladas; isso significa que você gastará 7% menos tempo executando o código da pilha do Entity Framework; isso não significa que seu aplicativo será 7% mais rápido. De modo geral, o custo de escrever e manter objetos CompiledQuery no EF 5.0 pode não valer a pena quando comparado com os benefícios. Seus resultados podem variar, portanto, exercite essa opção se o projeto exigir um esforço extra. Observe que CompiledQueries são compatíveis apenas com modelos derivados de ObjectContext e não são compatíveis com modelos derivados de DbContext.
Para obter mais informações sobre como criar e invocar um CompiledQuery, consulte Consultas Compiladas (LINQ to Entities).
Há duas considerações que você precisa levar ao usar um CompiledQuery, ou seja, o requisito de usar instâncias estáticas e os problemas que elas têm com a capacidade de composição. Aqui segue uma explicação detalhada dessas duas considerações.
3.3.1 Usar instâncias compiledQuery estáticas
Como compilar uma consulta LINQ é um processo demorado, não queremos fazer isso sempre que precisarmos buscar dados do banco de dados. As instâncias compiledQuery permitem que você compile uma vez e execute várias vezes, mas você precisa ter cuidado e adquirir para reutilizar a mesma instância compiledQuery todas as vezes em vez de compilá-la várias vezes. O uso de membros estáticos para armazenar as instâncias compiledQuery torna-se necessário; caso contrário, você não verá nenhum benefício.
Por exemplo, suponha que sua página tenha o corpo do método a seguir para manipular a exibição dos produtos para a categoria selecionada:
// Warning: this is the wrong way of using CompiledQuery
using (NorthwindEntities context = new NorthwindEntities())
{
string selectedCategory = this.categoriesList.SelectedValue;
var productsForCategory = CompiledQuery.Compile<NorthwindEntities, string, IQueryable<Product>>(
(NorthwindEntities nwnd, string category) =>
nwnd.Products.Where(p => p.Category.CategoryName == category)
);
this.productsGrid.DataSource = productsForCategory.Invoke(context, selectedCategory).ToList();
this.productsGrid.DataBind();
}
this.productsGrid.Visible = true;
Nesse caso, você criará uma nova instância compiledQuery em tempo real sempre que o método for chamado. Em vez de ver os benefícios de desempenho recuperando o comando do repositório do cache do plano de consulta, o CompiledQuery passará pelo compilador de planos sempre que uma nova instância for criada. Na verdade, você estará poluindo o cache do plano de consulta com uma nova entrada CompiledQuery sempre que o método for chamado.
Em vez disso, você deseja criar uma instância estática da consulta compilada, portanto, você está invocando a mesma consulta compilada sempre que o método é chamado. Uma maneira de fazer isso é adicionando a instância compiledQuery como membro do contexto do objeto. Em seguida, você pode tornar as coisas um pouco mais fáceis acessando o CompiledQuery por meio de um método auxiliar:
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IEnumerable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IEnumerable<Product> GetProductsForCategory(string categoryName)
{
return productsForCategoryCQ.Invoke(this, categoryName).ToList();
}
Esse método auxiliar seria invocado da seguinte maneira:
this.productsGrid.DataSource = context.GetProductsForCategory(selectedCategory);
3.3.2 Compondo sobre um CompiledQuery
A capacidade de redigir sobre qualquer consulta LINQ é extremamente útil; para fazer isso, basta invocar um método após o IQueryable, como Skip() ou Count(). No entanto, fazer isso essencialmente retorna um novo objeto IQueryable. Embora não haja nada que o impeça tecnicamente de redigir sobre um CompiledQuery, isso fará com que a geração de um novo objeto IQueryable exija passar pelo compilador de planos novamente.
Alguns componentes usarão objetos IQueryable compostos para habilitar a funcionalidade avançada. Por exemplo, GridView do ASP.NET pode ser associado a dados a um objeto IQueryable por meio da propriedade SelectMethod. Em seguida, o GridView redigirá esse objeto IQueryable para permitir a classificação e a paginação sobre o modelo de dados. Como você pode ver, o uso de um CompiledQuery para o GridView não atingiria a consulta compilada, mas geraria uma nova consulta autocompilada.
Um lugar em que você pode encontrar isso é ao adicionar filtros progressivos a uma consulta. Por exemplo, suponha que você tenha uma página Clientes com várias listas suspensas para filtros opcionais (por exemplo, País e OrdersCount). Você pode compor esses filtros sobre os resultados IQueryable de um CompiledQuery, mas isso resultará na nova consulta que passa pelo compilador de planos sempre que você executá-lo.
using (NorthwindEntities context = new NorthwindEntities())
{
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployee();
if (this.orderCountFilterList.SelectedItem.Value != defaultFilterText)
{
int orderCount = int.Parse(orderCountFilterList.SelectedValue);
myCustomers = myCustomers.Where(c => c.Orders.Count > orderCount);
}
if (this.countryFilterList.SelectedItem.Value != defaultFilterText)
{
myCustomers = myCustomers.Where(c => c.Address.Country == countryFilterList.SelectedValue);
}
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
Para evitar essa nova compilação, você pode reescrever o CompiledQuery para levar em conta os possíveis filtros:
private static readonly Func<NorthwindEntities, int, int?, string, IQueryable<Customer>> customersForEmployeeWithFiltersCQ = CompiledQuery.Compile(
(NorthwindEntities context, int empId, int? countFilter, string countryFilter) =>
context.Customers.Where(c => c.Orders.Any(o => o.EmployeeID == empId))
.Where(c => countFilter.HasValue == false || c.Orders.Count > countFilter)
.Where(c => countryFilter == null || c.Address.Country == countryFilter)
);
O que seria invocado na interface do usuário, como:
using (NorthwindEntities context = new NorthwindEntities())
{
int? countFilter = (this.orderCountFilterList.SelectedIndex == 0) ?
(int?)null :
int.Parse(this.orderCountFilterList.SelectedValue);
string countryFilter = (this.countryFilterList.SelectedIndex == 0) ?
null :
this.countryFilterList.SelectedValue;
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployeeWithFilters(
countFilter, countryFilter);
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
Uma compensação aqui é que o comando do repositório gerado sempre terá os filtros com as verificações nulas, mas isso deve ser bastante simples para o servidor de banco de dados otimizar:
...
WHERE ((0 = (CASE WHEN (@p__linq__1 IS NOT NULL) THEN cast(1 as bit) WHEN (@p__linq__1 IS NULL) THEN cast(0 as bit) END)) OR ([Project3].[C2] > @p__linq__2)) AND (@p__linq__3 IS NULL OR [Project3].[Country] = @p__linq__4)
3.4 Cache de metadados
O Entity Framework também dá suporte ao cache de metadados. Isso é essencialmente o cache de informações de tipo e informações de mapeamento tipo a banco de dados em diferentes conexões com o mesmo modelo. O cache de metadados é exclusivo por AppDomain.
Algoritmo de cache de metadados 3.4.1
As informações de metadados de um modelo são armazenadas em um ItemCollection para cada EntityConnection.
- Como observação lateral, há diferentes objetos ItemCollection para diferentes partes do modelo. Por exemplo, StoreItemCollections contém as informações sobre o modelo de banco de dados; ObjectItemCollection contém informações sobre o modelo de dados; EdmItemCollection contém informações sobre o modelo conceitual.
Se duas conexões usarem a mesma cadeia de conexão, elas compartilharão a mesma instância de ItemCollection.
Cadeias de conexão funcionalmente equivalentes, mas textuamente diferentes, podem resultar em caches de metadados diferentes. Nós tokenizamos cadeias de conexão, portanto, simplesmente alterar a ordem dos tokens deve resultar em metadados compartilhados. Mas duas cadeias de conexão que parecem funcionais da mesma forma podem não ser avaliadas como idênticas após a tokenização.
O ItemCollection é verificado periodicamente para uso. Se for determinado que um workspace não foi acessado recentemente, ele será marcado para limpeza na próxima varredura de cache.
Apenas a criação de um EntityConnection fará com que um cache de metadados seja criado (embora as coleções de itens nela não sejam inicializadas até que a conexão seja aberta). Esse workspace permanecerá na memória até que o algoritmo de cache determine que ele não está "em uso".
A Equipe de Consultoria do Cliente escreveu uma postagem no blog que descreve a realização de uma referência a um ItemCollection para evitar a "substituição" ao usar modelos grandes: <https://learn.microsoft.com/archive/blogs/appfabriccat/holding-a-reference-to-the-ef-metadataworkspace-for-wcf-services>.
3.4.2 A relação entre o cache de metadados e o cache do plano de consulta
A instância de cache do plano de consulta reside no ItemCollection do MetadataWorkspace dos tipos de repositório. Isso significa que os comandos do repositório armazenado em cache serão usados para consultas em qualquer contexto instanciado usando um determinado MetadataWorkspace. Isso também significa que, se você tiver duas cadeias de conexões ligeiramente diferentes e não corresponderem após a tokenização, você terá instâncias de cache de plano de consulta diferentes.
3.5 Cache de resultados
Com o cache de resultados (também conhecido como "cache de segundo nível"), você mantém os resultados das consultas em um cache local. Ao emitir uma consulta, primeiro você verá se os resultados estão disponíveis localmente antes de consultar no repositório. Embora o cache de resultados não seja compatível diretamente com o Entity Framework, é possível adicionar um cache de segundo nível usando um provedor de encapsulamento. Um provedor de encapsulamento de exemplo com um cache de segundo nível é o Cache de Segundo Nível do Entity Framework da Alachisoft com base no NCache.
Essa implementação do cache de segundo nível é uma funcionalidade injetada que ocorre após a expressão LINQ ter sido avaliada (e funcletizada) e o plano de execução de consulta é computado ou recuperado do cache de primeiro nível. O cache de segundo nível armazenará apenas os resultados brutos do banco de dados, de modo que o pipeline de materialização ainda será executado posteriormente.
3.5.1 Referências adicionais para cache de resultados com o provedor de encapsulamento
- Julie Lerman escreveu um artigo do MSDN "Cache de segundo nível no Entity Framework e no Windows Azure" que inclui como atualizar o provedor de encapsulamento de exemplo para usar o cache appFabric do Windows Server: https://msdn.microsoft.com/magazine/hh394143.aspx
- Se você estiver trabalhando com o Entity Framework 5, o blog da equipe terá uma postagem que descreve como executar as coisas com o provedor de cache do Entity Framework 5: <https://learn.microsoft.com/archive/blogs/adonet/ef-caching-with-jarek-kowalskis-provider>. Ele também inclui um modelo T4 para ajudar a automatizar a adição do cache de 2º nível ao seu projeto.
Quatro consultas autocompiladas
Quando uma consulta é emitida em um banco de dados usando o Entity Framework, ela deve passar por uma série de etapas antes de realmente materializar os resultados; uma dessas etapas é a Compilação de Consulta. As consultas Entity SQL eram conhecidas por terem um bom desempenho, pois são armazenadas automaticamente em cache, portanto, na segunda ou terceira vez que você executa a mesma consulta, ela pode ignorar o compilador de planos e usar o plano armazenado em cache.
O Entity Framework 5 também introduziu o cache automático para consultas LINQ to Entities. Nas edições anteriores do Entity Framework, criar um CompiledQuery para acelerar seu desempenho era uma prática comum, pois isso tornaria a consulta LINQ to Entities em cache. Como o cache agora é feito automaticamente sem o uso de um CompiledQuery, chamamos esse recurso de "consultas autocompiladas". Para obter mais informações sobre o cache do plano de consulta e sua mecânica, consulte Cache do Plano de Consulta.
O Entity Framework detecta quando uma consulta precisa ser recompilada e faz isso quando a consulta é invocada mesmo se ela já havia sido compilada antes. As condições comuns que fazem com que a consulta seja recompilada são:
- Alterar o MergeOption associado à sua consulta. A consulta armazenada em cache não será usada, em vez disso, o compilador de planos será executado novamente e o plano recém-criado será armazenado em cache.
- Alterar o valor de ContextOptions.UseCSharpNullComparisonBehavior. Você obtém o mesmo efeito que alterar o MergeOption.
Outras condições podem impedir que sua consulta use o cache. Alguns exemplos comuns são:
- Usar IEnumerable<T>. Contém<>(valor T).
- Usar funções que produzem consultas com constantes.
- Usar as propriedades de um objeto não mapeado.
- Vincular sua consulta a outra consulta que requer ser recompilada.
4.1 Usar IEnumerable<T>. Contém<T>(valor T)
O Entity Framework não armazena em cache consultas que invocam IEnumerable<T>. Contém<T>(valor T) em relação a uma coleção na memória, uma vez que os valores da coleção são considerados voláteis. A consulta de exemplo a seguir não será armazenada em cache, portanto, ela sempre será processada pelo compilador de planos:
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var query = context.MyEntities
.Where(entity => ids.Contains(entity.Id));
var results = query.ToList();
...
}
Observe que o tamanho do IEnumerable no qual Contains é executado determina a velocidade ou a lentidão da compilação da consulta. O desempenho pode sofrer significativamente ao usar grandes coleções, como a mostrada no exemplo acima.
O Entity Framework 6 contém otimizações para a maneira como o IEnumerable<T>. Contém<T>(valor T) funciona quando as consultas são executadas. O código SQL gerado é muito mais rápido para produzir e mais legível e, na maioria dos casos, também é executado mais rapidamente no servidor.
4.2 Usando funções que produzem consultas com constantes
Os operadores LINQ Skip(), Take(), Contains() e DefautIfEmpty() não produzem consultas SQL com parâmetros, mas colocam os valores passados para eles como constantes. Por isso, consultas que podem ser idênticas acabam poluindo o cache do plano de consulta, tanto na pilha EF quanto no servidor de banco de dados, e não são reutilizadas, a menos que as mesmas constantes sejam usadas em uma execução de consulta subsequente. Por exemplo:
var id = 10;
...
using (var context = new MyContext())
{
var query = context.MyEntities.Select(entity => entity.Id).Contains(id);
var results = query.ToList();
...
}
Neste exemplo, cada vez que essa consulta for executada com um valor diferente para a ID, a consulta será compilada em um novo plano.
Em particular, preste atenção ao uso de Skip and Take ao fazer paginação. No EF6, esses métodos têm uma sobrecarga lambda que efetivamente torna o plano de consulta armazenado em cache reutilizável porque o EF pode capturar variáveis passadas para esses métodos e convertê-las em SQLparameters. Isso também ajuda a manter o cache mais limpo, pois caso contrário, cada consulta com uma constante diferente para Skip e Take obteria sua própria entrada de cache de plano de consulta.
Considere o código a seguir, que é abaixo do ideal, mas destina-se apenas a exemplificar essa classe de consultas:
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
Uma versão mais rápida desse mesmo código envolveria chamar Skip com um lambda:
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(() => i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
O segundo snippet pode ser executado até 11% mais rápido porque o mesmo plano de consulta é usado sempre que a consulta é executada, o que economiza tempo de CPU e evita poluir o cache de consultas. Além disso, como o parâmetro para Skip está em um fechamento, o código pode muito bem ter esta aparência agora:
var i = 0;
var skippyCustomers = context.Customers.OrderBy(c => c.LastName).Skip(() => i);
for (; i < count; ++i)
{
var currentCustomer = skippyCustomers.FirstOrDefault();
ProcessCustomer(currentCustomer);
}
4.3 Usando as propriedades de um objeto não mapeado
Quando uma consulta usa as propriedades de um tipo de objeto não mapeado como um parâmetro, a consulta não será armazenada em cache. Por exemplo:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myObject.MyProperty)
select entity;
var results = query.ToList();
...
}
Neste exemplo, suponha que a classe NonMappedType não faça parte do modelo de entidade. Essa consulta pode ser facilmente alterada para não usar um tipo não mapeado e, em vez disso, usar uma variável local como o parâmetro para a consulta:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var myValue = myObject.MyProperty;
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myValue)
select entity;
var results = query.ToList();
...
}
Nesse caso, a consulta poderá ser armazenada em cache e se beneficiará do cache do plano de consulta.
4.4 Vinculação a consultas que exigem recompilação
Seguindo o mesmo exemplo acima, se você tiver uma segunda consulta que dependa de uma consulta que precise ser recompilada, toda a segunda consulta também será recompilada. Aqui está um exemplo para ilustrar este cenário:
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var firstQuery = from entity in context.MyEntities
where ids.Contains(entity.Id)
select entity;
var secondQuery = from entity in context.MyEntities
where firstQuery.Any(otherEntity => otherEntity.Id == entity.Id)
select entity;
var results = secondQuery.ToList();
...
}
O exemplo é genérico, mas ilustra como a vinculação ao firstQuery está fazendo com que secondQuery não consiga ser armazenado em cache. Se firstQuery não tivesse sido uma consulta que requer recompilação, o secondQuery teria sido armazenado em cache.
5. Consultas NoTracking
5.1 Desabilitando o controle de alterações para reduzir a sobrecarga de gerenciamento de estado
Se você estiver em um cenário somente leitura e quiser evitar a sobrecarga de carregar os objetos no ObjectStateManager, poderá emitir consultas "Sem Acompanhamento". O controle de alterações pode ser desabilitado no nível da consulta.
No entanto, observe que, ao desabilitar o controle de alterações, você está efetivamente desativando o cache de objetos. Quando você consulta uma entidade, não podemos ignorar a materialização puxando os resultados da consulta materializada anteriormente do ObjectStateManager. Se você estiver consultando repetidamente as mesmas entidades no mesmo contexto, poderá realmente ver um benefício de desempenho de habilitar o controle de alterações.
Ao consultar usando ObjectContext, as instâncias ObjectQuery e ObjectSet se lembrarão de um MergeOption quando ele for definido e as consultas compostas nelas herdarão a MergeOption efetiva da consulta pai. Ao usar DbContext, o acompanhamento pode ser desabilitado chamando o modificador AsNoTracking() no DbSet.
5.1.1 Desabilitando o controle de alterações para uma consulta ao usar DbContext
Você pode alternar o modo de uma consulta para NoTracking encadeando uma chamada para o método AsNoTracking() na consulta. Ao contrário de ObjectQuery, as classes DbSet e DbQuery na API DbContext não têm uma propriedade mutável para MergeOption.
var productsForCategory = from p in context.Products.AsNoTracking()
where p.Category.CategoryName == selectedCategory
select p;
5.1.2 Desabilitando o controle de alterações no nível da consulta usando ObjectContext
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
((ObjectQuery)productsForCategory).MergeOption = MergeOption.NoTracking;
5.1.3 Desabilitando o controle de alterações para um conjunto de entidades inteiro usando ObjectContext
context.Products.MergeOption = MergeOption.NoTracking;
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
5.2 Métricas de teste que demonstram o benefício de desempenho de consultas NoTracking
Neste teste, analisamos o custo de preenchimento do ObjectStateManager comparando o acompanhamento com as consultas NoTracking para o modelo Navision. Consulte o apêndice para obter uma descrição do modelo Navision e os tipos de consultas que foram executadas. Neste teste, iteramos pela lista de consultas e executamos cada uma delas uma vez. Fizemos duas variações do teste, uma vez com consultas NoTracking e outra com a opção de mesclagem padrão de "AppendOnly". Executamos cada variação três vezes e usamos o valor médio das execuções. Entre os testes, limpamos o cache de consulta no SQL Server e reduzimos o tempdb executando os seguintes comandos:
- DBCC DROPCLEANBUFFERS
- DBCC FREEPROCCACHE
- DBCC SHRINKDATABASE (tempdb, 0)
Resultados de teste, mediano superior a 3 execuções:
| SEM ACOMPANHAMENTO – CONJUNTO DE TRABALHO | SEM ACOMPANHAMENTO – HORA | SOMENTE ACRÉSCIMO – CONJUNTO DE TRABALHO | SOMENTE ACRÉSCIMO – HORA | |
|---|---|---|---|---|
| Entity Framework 5 | 460361728 | 1163536 ms | 596545536 | 1273042 ms |
| Entity Framework 6 | 647127040 | 190228 ms | 832798720 | 195521 ms |
O Entity Framework 5 terá um volume de memória menor no final da execução do que o Entity Framework 6. A memória adicional consumida pelo Entity Framework 6 é o resultado de estruturas de memória e código adicionais que permitem novos recursos e melhor desempenho.
Há também uma clara diferença no volume de memória ao usar o ObjectStateManager. O Entity Framework 5 aumentou seu volume em 30% ao manter o controle de todas as entidades que materializamos do banco de dados. O Entity Framework 6 aumentou seu volume em 28% ao fazer isso.
Em termos de tempo, o Entity Framework 6 supera o Entity Framework 5 neste teste por uma grande margem. O Entity Framework 6 concluiu o teste em cerca de 16% do tempo consumido pelo Entity Framework 5. Além disso, o Entity Framework 5 leva 9% mais tempo para ser concluído quando o ObjectStateManager está sendo usado. Em comparação, o Entity Framework 6 está usando mais 3% de tempo ao usar o ObjectStateManager.
Seis opções de execução de consulta
O Entity Framework oferece várias maneiras diferentes de consultar. Examinaremos as seguintes opções, compararemos os prós e contras de cada um deles e examinaremos suas características de desempenho:
- LINQ to Entities.
- Sem acompanhamento do LINQ to Entities.
- Entity SQL em um ObjectQuery.
- Entity SQL em um EntityCommand.
- ExecuteStoreQuery.
- SQLQuery.
- Compiledquery.
6.1 Consultas LINQ to Entities
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Prós
- Adequado para operações CUD.
- Objetos totalmente materializados.
- Mais simples de escrever com sintaxe incorporada à linguagem de programação.
- Bom desempenho.
Contras
- Determinadas restrições técnicas, como:
- Os padrões que usam consultas DefaultIfEmpty para OUTER JOIN resultam em consultas mais complexas do que instruções OUTER JOIN simples na Entity SQL.
- Você ainda não pode usar LIKE com correspondência geral de padrões.
6.2 Sem acompanhamento de consultas LINQ to Entities
Quando o contexto deriva ObjectContext:
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Quando o contexto deriva DbContext:
var q = context.Products.AsNoTracking()
.Where(p => p.Category.CategoryName == "Beverages");
Prós
- Melhor desempenho em relação às consultas LINQ regulares.
- Objetos totalmente materializados.
- Mais simples de escrever com sintaxe incorporada à linguagem de programação.
Contras
- Não é adequado para operações de CUD.
- Determinadas restrições técnicas, como:
- Os padrões que usam consultas DefaultIfEmpty para OUTER JOIN resultam em consultas mais complexas do que instruções OUTER JOIN simples na Entity SQL.
- Você ainda não pode usar LIKE com correspondência geral de padrões.
Observe que as consultas que as propriedades escalares do projeto não são controladas mesmo se o NoTracking não for especificado. Por exemplo:
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages").Select(p => new { p.ProductName });
Essa consulta específica não especifica explicitamente ser NoTracking, mas como ela não está materializando um tipo que é conhecido pelo gerenciador de estado do objeto, o resultado materializado não é rastreado.
6.3 Entity SQL em um ObjectQuery
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
Prós
- Adequado para operações CUD.
- Objetos totalmente materializados.
- Dá suporte ao cache do plano de consulta.
Contras
- Envolve cadeias de caracteres de consulta textuais que são mais propensas a erros do usuário do que construções de consulta internas no idioma.
6.4 Entity SQL em um Comando de Entidade
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
while (reader.Read())
{
// manually 'materialize' the product
}
}
Prós
- Dá suporte ao cache de plano de consulta no .NET 4.0 (o cache de planos é compatível com todos os outros tipos de consulta no .NET 4.5).
Contras
- Envolve cadeias de caracteres de consulta textuais que são mais propensas a erros do usuário do que construções de consulta internas no idioma.
- Não é adequado para operações de CUD.
- Os resultados não são materializados automaticamente e devem ser lidos do leitor de dados.
6.5 SQLQuery e ExecuteStoreQuery
SQLQuery no Banco de Dados:
// use this to obtain entities and not track them
var q1 = context.Database.SqlQuery<Product>("select * from products");
SQLQuery no DbSet:
// use this to obtain entities and have them tracked
var q2 = context.Products.SqlQuery("select * from products");
ExecuteStoreQuery:
var beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued, P.DiscontinuedDate
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
Prós
- Geralmente, o desempenho mais rápido desde que o compilador de planos é ignorado.
- Objetos totalmente materializados.
- Adequado para operações CUD quando usado do DbSet.
Contras
- A consulta é textual e propensa a erros.
- A consulta está vinculada a um back-end específico usando semântica de repositório em vez de semântica conceitual.
- Quando a herança está presente, a consulta artesanal precisa considerar as condições de mapeamento para o tipo solicitado.
6.6 CompiledQuery
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
…
var q = context.InvokeProductsForCategoryCQ("Beverages");
Prós
- Fornece uma melhoria de desempenho de até 7% em relação às consultas LINQ regulares.
- Objetos totalmente materializados.
- Adequado para operações CUD.
Contras
- Maior complexidade e sobrecarga de programação.
- A melhoria de desempenho é perdida ao compor sobre uma consulta compilada.
- Algumas consultas LINQ não podem ser gravadas como compiledQuery, por exemplo, projeções de tipos anônimos.
6.7 Comparação de desempenho de diferentes opções de consulta
Marcas simples de microesferas em que a criação de contexto não foi cronometrada foram colocadas à prova. Medimos a consulta 5.000 vezes para um conjunto de entidades não armazenadas em cache em um ambiente controlado. Esses números devem ser tomados com um aviso: eles não refletem números reais produzidos por um aplicativo, mas, em vez disso, são uma medida muito precisa de quanto de diferença de desempenho há quando diferentes opções de consulta são comparadas igualmente, excluindo o custo de criar um novo contexto.
| EF | Teste | Tempo (ms) | Memória |
|---|---|---|---|
| EF5 | ObjectContext ESQL | 2414 | 38801408 |
| EF5 | Consulta Linq ObjectContext | 2692 | 38277120 |
| EF5 | Consulta Linq DbContext sem acompanhamento | 2818 | 41840640 |
| EF5 | Consulta Linq DbContext | 2930 | 41771008 |
| EF5 | ObjectContext Linq Query sem acompanhamento | 3013 | 38412288 |
| EF6 | ObjectContext ESQL | 2059 | 46039040 |
| EF6 | Consulta Linq ObjectContext | 3074 | 45248512 |
| EF6 | Consulta Linq DbContext sem acompanhamento | 3125 | 47575040 |
| EF6 | Consulta Linq DbContext | 3420 | 47652864 |
| EF6 | ObjectContext Linq Query sem acompanhamento | 3593 | 45260800 |
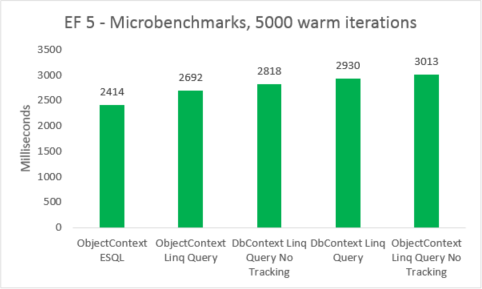
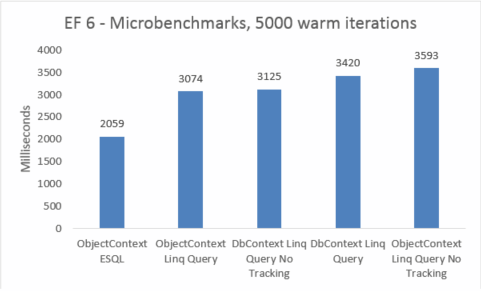
As marcas de microesferas são muito sensíveis a pequenas alterações no código. Nesse caso, a diferença entre os custos do Entity Framework 5 e do Entity Framework 6 deve-se à adição de interceptação e melhorias transacionais. Esses números de marcas de microesferas, no entanto, são uma visão amplificada em um fragmento muito pequeno do que o Entity Framework faz. Cenários reais de consultas quentes não devem ver uma regressão de desempenho ao atualizar do Entity Framework 5 para o Entity Framework 6.
Para comparar o desempenho real das diferentes opções de consulta, criamos cinco variações de teste separadas em que usamos uma opção de consulta diferente para selecionar todos os produtos cujo nome de categoria é "Bebidas". Cada iteração inclui o custo de criação do contexto e o custo de materialização de todas as entidades retornadas. 10 iterações são executadas sem tempo antes de levar a soma de 1000 iterações cronometrada. Os resultados mostrados são a execução mediana obtida de 5 execuções de cada teste. Para obter mais informações, consulte Apêndice B, que inclui o código para o teste.
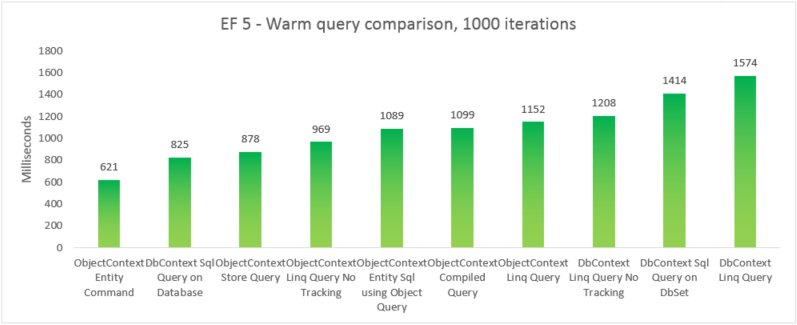
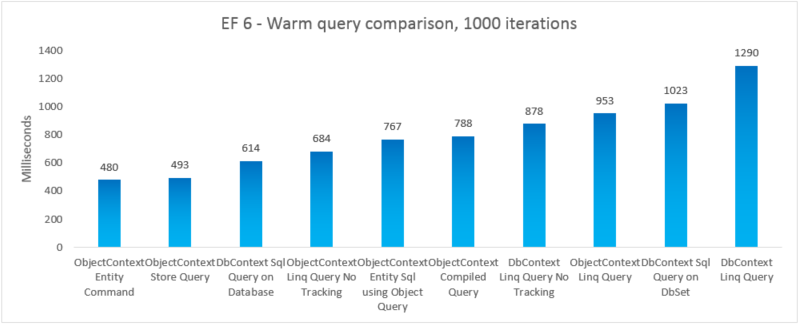
| EF | Teste | Tempo (ms) | Memória |
|---|---|---|---|
| EF5 | Comando da entidade objectContext | 621 | 39350272 |
| EF5 | Consulta SQL DbContext no banco de dados | 825 | 37519360 |
| EF5 | Consulta do Repositório ObjectContext | 878 | 39460864 |
| EF5 | ObjectContext Linq Query sem acompanhamento | 969 | 38293504 |
| EF5 | ObjectContext da Entity SQL usando a Consulta de Objeto | 1089 | 38981632 |
| EF5 | Consulta compilada de ObjectContext | 1099 | 38682624 |
| EF5 | Consulta Linq ObjectContext | 1152 | 38178816 |
| EF5 | Consulta Linq DbContext sem acompanhamento | 1208 | 41803776 |
| EF5 | Consulta SQL DbContext no DbSet | 1414 | 37982208 |
| EF5 | Consulta Linq DbContext | 1.574 | 41738240 |
| EF6 | Comando da entidade objectContext | 480 | 47247360 |
| EF6 | Consulta do Repositório ObjectContext | 493 | 46739456 |
| EF6 | Consulta SQL DbContext no banco de dados | 614 | 41607168 |
| EF6 | ObjectContext Linq Query sem acompanhamento | 684 | 46333952 |
| EF6 | ObjectContext da Entity SQL usando a Consulta de Objeto | 767 | 48865280 |
| EF6 | Consulta compilada de ObjectContext | 788 | 48467968 |
| EF6 | Consulta Linq DbContext sem acompanhamento | 878 | 47554560 |
| EF6 | Consulta Linq ObjectContext | 953 | 47632384 |
| EF6 | Consulta SQL DbContext no DbSet | 1023 | 41992192 |
| EF6 | Consulta Linq DbContext | 1290 | 47529984 |
Observação
Para fins de integridade, incluímos uma variação em que executamos uma consulta Entity SQL em um EntityCommand. No entanto, como os resultados não são materializados para essas consultas, a comparação não é necessariamente igual. O teste inclui uma aproximação próxima à materialização para tentar tornar a comparação mais justa.
Nesse caso de ponta a ponta, o Entity Framework 6 supera o Entity Framework 5 devido a melhorias de desempenho feitas em várias partes da pilha, incluindo uma inicialização DbContext muito mais leve e pesquisas mais rápidas de MetadadosCollection<T>.
Sete considerações sobre o desempenho do tempo de design
7.1 Estratégias de herança
Outra consideração de desempenho ao usar o Entity Framework é a estratégia de herança que você usa. O Entity Framework dá suporte a três tipos básicos de herança e suas combinações:
- Tabela por Hierarquia (TPH) – em que cada conjunto de herança é mapeado para uma tabela com uma coluna discriminatória para indicar qual tipo específico na hierarquia está sendo representado na linha.
- Tabela por Tipo (TPT) – em que cada tipo tem sua própria tabela no banco de dados; as tabelas filho definem apenas as colunas que a tabela pai não contém.
- Tabela por Classe (TPC) – em que cada tipo tem sua própria tabela completa no banco de dados; as tabelas filho definem todos os campos, incluindo aqueles definidos em tipos pai.
Se o modelo usar a herança TPT, as consultas geradas serão mais complexas do que as geradas com as outras estratégias de herança, o que pode resultar em tempos de execução mais longos no repositório. Geralmente, levará mais tempo para gerar consultas em um modelo TPT e materializar os objetos resultantes.
Consulte a postagem no blog "Considerações de desempenho ao usar a herança TPT (Tabela por Tipo) no Entity Framework": <https://learn.microsoft.com/archive/blogs/adonet/performance-considerations-when-using-tpt-table-per-type-inheritance-in-the-entity-framework>.
7.1.1 Evitando TPT em aplicativos Model First ou Code First
Quando você cria um modelo em um banco de dados existente que tem um esquema TPT, você não tem muitas opções. No entanto, ao criar um aplicativo usando o Model First ou o Code First, você deve evitar a herança TPT por questões de desempenho.
Ao usar o Model First no Assistente de Designer de Entidade, você receberá TPT para qualquer herança em seu modelo. Se você quiser mudar para uma estratégia de herança de TPH com o Model First, poderá usar o "Power Pack de Geração de Banco de Dados do Designer de Entidade" disponível na Galeria do Visual Studio (<http://visualstudiogallery.msdn.microsoft.com/df3541c3-d833-4b65-b942-989e7ec74c87/>).
Ao usar o Code First para configurar o mapeamento de um modelo com herança, o EF usará o TPH por padrão, portanto, todas as entidades na hierarquia de herança serão mapeadas para a mesma tabela. Consulte a seção "Mapeamento com a API fluente" do artigo "Code First na Entity Framework4.1" na MSDN Magazine ( http://msdn.microsoft.com/magazine/hh126815.aspx) para obter mais detalhes.
7.2 Atualização do EF4 para melhorar o tempo de geração do modelo
Uma melhoria específica do SQL Server para o algoritmo que gera o SSDL (store-layer) do modelo está disponível no Entity Framework 5 e 6 e como uma atualização para o Entity Framework 4 quando o Visual Studio 2010 SP1 está instalado. Os resultados do teste a seguir demonstram a melhoria ao gerar um modelo muito grande, nesse caso, o modelo Navision. Consulte o Apêndice C para obter mais detalhes sobre ele.
O modelo contém 1.005 conjuntos de entidades e 4.227 conjuntos de associações.
| Configuração | Detalhamento do tempo gasto |
|---|---|
| Visual Studio 2010, Entity Framework 4 | Geração do SSDL: 2h27min Geração de mapeamento: 1 segundo Geração CSDL: 1 segundo Geração ObjectLayer: 1 segundo Geração de exibição: 2h14min |
| Visual Studio 2010 SP1, Entity Framework 4 | Geração SSDL: 1 segundo Geração de mapeamento: 1 segundo Geração CSDL: 1 segundo Geração ObjectLayer: 1 segundo Geração de exibição: 1h53min |
| Visual Studio 2013, Entity Framework 5 | Geração SSDL: 1 segundo Geração de mapeamento: 1 segundo Geração CSDL: 1 segundo Geração ObjectLayer: 1 segundo Geração de exibição: 65 minutos |
| Visual Studio 2013, Entity Framework 6 | Geração SSDL: 1 segundo Geração de mapeamento: 1 segundo Geração CSDL: 1 segundo Geração ObjectLayer: 1 segundo Geração de exibição: 28 segundos. |
Vale a pena observar que, ao gerar o SSDL, a carga é quase inteiramente gasta no SQL Server, enquanto o computador de desenvolvimento do cliente está aguardando que os resultados retornem do servidor. Os DBAs devem apreciar particularmente essa melhoria. Também vale a pena observar que essencialmente todo o custo da geração de modelos ocorre agora na Geração de Exibição.
7.3 Dividir modelos grandes com o Database First e Model First
À medida que o tamanho do modelo aumenta, a superfície do designer fica desordenada e difícil de usar. Normalmente, consideramos um modelo com mais de 300 entidades muito grande para usar efetivamente o designer. A seguinte postagem no blog descreve várias opções para dividir modelos grandes: <https://learn.microsoft.com/archive/blogs/adonet/working-with-large-models-in-entity-framework-part-2>.
A postagem foi gravada para a primeira versão do Entity Framework, mas as etapas ainda se aplicam.
7.4 Considerações de desempenho com o controle da fonte de dados da entidade
Vimos casos em testes de desempenho e estresse de vários threads em que o desempenho de um aplicativo Web usando o Controle EntityDataSource se deteriora significativamente. A causa subjacente é que o EntityDataSource chama repetidamente MetadataWorkspace.LoadFromAssembly nos assemblies referenciados pelo aplicativo Web para descobrir os tipos a serem usados como entidades.
A solução é definir o ContextTypeName do EntityDataSource como o nome de tipo da classe ObjectContext derivada. Isso desativa o mecanismo que verifica todos os assemblies referenciados em busca de tipos de entidade.
Definir o campo ContextTypeName também impede um problema funcional em que o EntityDataSource no .NET 4.0 lança um ReflectionTypeLoadException quando ele não pode carregar um tipo de um assembly por meio de reflexão. Esse problema foi corrigido no .NET 4.5.
7.5 Entidades POCO e proxies de controle de alterações
O Entity Framework permite que você use classes de dados personalizadas junto com seu modelo de dados sem fazer nenhuma modificação nas próprias classes de dados. Isso significa que você pode usar objetos CLR "simples" (POCO), como objetos de domínio existentes, com seu modelo de dados. Essas classes de dados POCO (também conhecidas como objetos ignorantes de persistência), que são mapeadas para entidades definidas em um modelo de dados, dão suporte à maioria dos mesmos comportamentos de consulta, inserção, atualização e exclusão como tipos de entidade gerados pelas ferramentas do Modelo de Dados de Entidade.
O Entity Framework também pode criar classes proxy derivadas de seus tipos poco, que são usados quando você deseja habilitar recursos como carregamento lento e controle automático de alterações em entidades POCO. Suas classes POCO devem atender a determinados requisitos para permitir que o Entity Framework use proxies, conforme descrito aqui: http://msdn.microsoft.com/library/dd468057.aspx.
Os proxies de rastreamento de chance notificarão o gerenciador de estado do objeto sempre que qualquer uma das propriedades de suas entidades tiver seu valor alterado, portanto, o Entity Framework conhece o estado real de suas entidades o tempo todo. Isso é feito adicionando eventos de notificação ao corpo dos métodos setter de suas propriedades e fazendo com que o gerenciador de estado do objeto processe esses eventos. Observe que a criação de uma entidade proxy normalmente será mais cara do que a criação de uma entidade POCO sem proxy devido ao conjunto adicionado de eventos criados pelo Entity Framework.
Quando uma entidade POCO não tem um proxy de controle de alterações, as alterações são encontradas comparando o conteúdo de suas entidades com uma cópia de um estado salvo anterior. Essa comparação profunda se tornará um processo longo quando você tiver muitas entidades em seu contexto ou quando suas entidades tiverem uma quantidade muito grande de propriedades, mesmo que nenhuma delas tenha sido alterada desde a última comparação.
Em resumo: você pagará um alinhamento de desempenho ao criar o proxy de controle de alterações, mas o controle de alterações ajudará você a acelerar o processo de detecção de alterações quando suas entidades tiverem muitas propriedades ou quando você tiver muitas entidades em seu modelo. Para entidades com um pequeno número de propriedades em que a quantidade de entidades não cresce muito, ter proxies de controle de alterações pode não ser de grande benefício.
8. Carregar entidades relacionadas
8.1 Carregamento lento vs. carregamento adiantado
O Entity Framework oferece várias maneiras diferentes de carregar as entidades relacionadas à entidade de destino. Por exemplo, quando você consulta Produtos, há diferentes maneiras pelas quais os Pedidos relacionados serão carregados no Gerenciador de Estado do Objeto. Do ponto de vista do desempenho, a maior questão a ser considerada ao carregar entidades relacionadas será se o carregamento lento ou o carregamento adiantado serão usados.
Ao usar o Carregamento Adiantado, as entidades relacionadas são carregadas junto com o conjunto de entidades de destino. Use uma instrução Include em sua consulta para indicar quais entidades relacionadas você deseja trazer.
Ao usar o Carregamento Lento, sua consulta inicial só traz o conjunto de entidades de destino. Mas sempre que você acessa uma propriedade de navegação, outra consulta é emitida no repositório para carregar a entidade relacionada.
Depois que uma entidade tiver sido carregada, todas as consultas adicionais para a entidade a carregarão diretamente do Gerenciador de Estado do Objeto, seja você usando carregamento lento ou carregamento adiantado.
8.2 Como escolher entre carregamento lento e carregamento adiantado
O importante é que você entenda a diferença entre o Carregamento Lento e o Carregamento Adiantado para que você possa fazer a escolha correta para seu aplicativo. Isso ajudará você a avaliar a compensação entre várias solicitações no banco de dados em relação a uma única solicitação que pode conter uma carga grande. Pode ser apropriado usar o carregamento adiantado em algumas partes do aplicativo e o carregamento lento em outras partes.
Como exemplo do que está acontecendo na vizinhança, suponha que você queira consultar os clientes que vivem no Reino Unido e sua contagem de pedidos.
Usando o carregamento adiantado
using (NorthwindEntities context = new NorthwindEntities())
{
var ukCustomers = context.Customers.Include(c => c.Orders).Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
Usando o carregamento lento
using (NorthwindEntities context = new NorthwindEntities())
{
context.ContextOptions.LazyLoadingEnabled = true;
//Notice that the Include method call is missing in the query
var ukCustomers = context.Customers.Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
Ao usar o carregamento adiantado, você emitirá uma única consulta que retorna todos os clientes e todos os pedidos. O comando de repositório tem a seguinte aparência:
SELECT
[Project1].[C1] AS [C1],
[Project1].[CustomerID] AS [CustomerID],
[Project1].[CompanyName] AS [CompanyName],
[Project1].[ContactName] AS [ContactName],
[Project1].[ContactTitle] AS [ContactTitle],
[Project1].[Address] AS [Address],
[Project1].[City] AS [City],
[Project1].[Region] AS [Region],
[Project1].[PostalCode] AS [PostalCode],
[Project1].[Country] AS [Country],
[Project1].[Phone] AS [Phone],
[Project1].[Fax] AS [Fax],
[Project1].[C2] AS [C2],
[Project1].[OrderID] AS [OrderID],
[Project1].[CustomerID1] AS [CustomerID1],
[Project1].[EmployeeID] AS [EmployeeID],
[Project1].[OrderDate] AS [OrderDate],
[Project1].[RequiredDate] AS [RequiredDate],
[Project1].[ShippedDate] AS [ShippedDate],
[Project1].[ShipVia] AS [ShipVia],
[Project1].[Freight] AS [Freight],
[Project1].[ShipName] AS [ShipName],
[Project1].[ShipAddress] AS [ShipAddress],
[Project1].[ShipCity] AS [ShipCity],
[Project1].[ShipRegion] AS [ShipRegion],
[Project1].[ShipPostalCode] AS [ShipPostalCode],
[Project1].[ShipCountry] AS [ShipCountry]
FROM ( SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax],
1 AS [C1],
[Extent2].[OrderID] AS [OrderID],
[Extent2].[CustomerID] AS [CustomerID1],
[Extent2].[EmployeeID] AS [EmployeeID],
[Extent2].[OrderDate] AS [OrderDate],
[Extent2].[RequiredDate] AS [RequiredDate],
[Extent2].[ShippedDate] AS [ShippedDate],
[Extent2].[ShipVia] AS [ShipVia],
[Extent2].[Freight] AS [Freight],
[Extent2].[ShipName] AS [ShipName],
[Extent2].[ShipAddress] AS [ShipAddress],
[Extent2].[ShipCity] AS [ShipCity],
[Extent2].[ShipRegion] AS [ShipRegion],
[Extent2].[ShipPostalCode] AS [ShipPostalCode],
[Extent2].[ShipCountry] AS [ShipCountry],
CASE WHEN ([Extent2].[OrderID] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C2]
FROM [dbo].[Customers] AS [Extent1]
LEFT OUTER JOIN [dbo].[Orders] AS [Extent2] ON [Extent1].[CustomerID] = [Extent2].[CustomerID]
WHERE N'UK' = [Extent1].[Country]
) AS [Project1]
ORDER BY [Project1].[CustomerID] ASC, [Project1].[C2] ASC
Ao usar o carregamento lento, você emitirá a seguinte consulta inicialmente:
SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax]
FROM [dbo].[Customers] AS [Extent1]
WHERE N'UK' = [Extent1].[Country]
E sempre que você acessa a propriedade de navegação Pedidos de um cliente, outra consulta como a seguinte é emitida no repositório:
exec sp_executesql N'SELECT
[Extent1].[OrderID] AS [OrderID],
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[EmployeeID] AS [EmployeeID],
[Extent1].[OrderDate] AS [OrderDate],
[Extent1].[RequiredDate] AS [RequiredDate],
[Extent1].[ShippedDate] AS [ShippedDate],
[Extent1].[ShipVia] AS [ShipVia],
[Extent1].[Freight] AS [Freight],
[Extent1].[ShipName] AS [ShipName],
[Extent1].[ShipAddress] AS [ShipAddress],
[Extent1].[ShipCity] AS [ShipCity],
[Extent1].[ShipRegion] AS [ShipRegion],
[Extent1].[ShipPostalCode] AS [ShipPostalCode],
[Extent1].[ShipCountry] AS [ShipCountry]
FROM [dbo].[Orders] AS [Extent1]
WHERE [Extent1].[CustomerID] = @EntityKeyValue1',N'@EntityKeyValue1 nchar(5)',@EntityKeyValue1=N'AROUT'
Para obter mais informações, consulte Carregar objetos relacionados.
8.2.1 Carregamento lento versus planilha de cheat de carregamento adiantado
Não existe algo que serve a todos para escolher o carregamento adiantado versus carregamento lento. Tente primeiro entender as diferenças entre ambas as estratégias para que você possa tomar uma decisão bem informada; além disso, considere se o código se encaixa em qualquer um dos seguintes cenários:
| Cenário | Nossa sugestão |
|---|---|
| Você precisa acessar muitas propriedades de navegação das entidades buscadas? | Não - Ambas as opções provavelmente farão. No entanto, se o conteúdo que sua consulta está trazendo não for muito grande, você poderá ter benefícios de desempenho usando o carregamento adiantado, pois isso exigirá menos viagens de ida e volta de rede para materializar seus objetos. Sim – se você precisar acessar muitas propriedades de navegação das entidades, faça isso usando várias instruções de inclusão em sua consulta com o carregamento adiantado. Quanto mais entidades você incluir, maior será o conteúdo que sua consulta retornará. Depois de incluir três ou mais entidades em sua consulta, considere alternar para o carregamento lento. |
| Você sabe exatamente quais dados serão necessários em tempo de execução? | Não - O carregamento lento será melhor para você. Caso contrário, você poderá acabar consultando dados que não precisarão. Sim - O carregamento adiantado provavelmente é a sua melhor aposta; ele ajudará a carregar conjuntos inteiros mais rapidamente. Se a consulta exigir a busca de uma quantidade muito grande de dados, e isso se tornar muito lento, experimente o carregamento lento em vez disso. |
| Seu código está sendo executado longe do banco de dados? (latência de rede aumentada) | Não - quando a latência de rede não é um problema, o uso do carregamento lento pode simplificar seu código. Lembre-se de que a topologia do aplicativo pode mudar, portanto, não use a proximidade do banco de dados como garantida. Sim - quando a rede é um problema, somente você pode decidir o que se encaixa melhor para o seu cenário. Normalmente, o carregamento adiantado será melhor porque requer menos viagens de ida e volta. |
8.2.2 Preocupações de desempenho com várias inclusões
Quando ouvimos perguntas de desempenho que envolvem problemas de tempo de resposta do servidor, a origem do problema é frequentemente consultas com várias instruções Include. Embora a inclusão de entidades relacionadas em uma consulta seja poderosa, é importante entender o que está acontecendo nos bastidores.
Leva um tempo relativamente longo para que uma consulta com várias instruções Include nela passe pelo nosso compilador de plano interno para produzir o comando do repositório. A maior parte desse tempo é gasto tentando otimizar a consulta resultante. O comando do repositório gerado conterá uma Junção Externa ou União para cada Inclusão, dependendo do mapeamento. Consultas como essa trarão grandes grafos conectados do banco de dados em uma única carga, o que irá acerbar quaisquer problemas de largura de banda, especialmente quando houver muita redundância no conteúdo (por exemplo, quando vários níveis de Inclusão são usados para percorrer associações na direção um-para-muitos).
Você pode verificar se há casos em que suas consultas estão retornando cargas excessivamente grandes acessando o TSQL subjacente para a consulta usando ToTraceString e executando o comando de repositório no SQL Server Management Studio para ver o tamanho da carga. Nesses casos, você pode tentar reduzir o número de instruções Include em sua consulta para apenas trazer os dados necessários. Ou você pode dividir sua consulta em uma sequência menor de subconsultas, por exemplo:
Antes de interromper a consulta:
using (NorthwindEntities context = new NorthwindEntities())
{
var customers = from c in context.Customers.Include(c => c.Orders)
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
Depois de interromper a consulta:
using (NorthwindEntities context = new NorthwindEntities())
{
var orders = from o in context.Orders
where o.Customer.LastName.StartsWith(lastNameParameter)
select o;
orders.Load();
var customers = from c in context.Customers
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
Isso funcionará apenas em consultas controladas, pois estamos usando a capacidade que o contexto tem de executar a resolução de identidade e a correção de associação automaticamente.
Assim como com o carregamento lento, a compensação será mais consultas para cargas menores. Você também pode usar projeções de propriedades individuais para selecionar explicitamente apenas os dados necessários de cada entidade, mas não carregará entidades nesse caso e não haverá suporte para atualizações.
8.2.3 Solução alternativa para obter o carregamento lento de propriedades
Atualmente, o Entity Framework não dá suporte ao carregamento lento de propriedades escalares ou complexas. No entanto, nos casos em que você tem uma tabela que inclui um objeto grande, como um BLOB, você pode usar a divisão de tabelas para separar as propriedades grandes em uma entidade separada. Por exemplo, suponha que você tenha uma tabela Product que inclua uma coluna de fotos varbinary. Se você não precisar acessar essa propriedade com frequência em suas consultas, poderá usar a divisão de tabelas para trazer apenas as partes da entidade de que você normalmente precisa. A entidade que representa a foto do produto só será carregada quando você precisar dela explicitamente.
Um bom recurso que mostra como habilitar a divisão de tabelas é a postagem do blog "Divisão de Tabelas no Entity Framework" de Gil Fink: <http://blogs.microsoft.co.il/blogs/gilf/archive/2009/10/13/table-splitting-in-entity-framework.aspx>.
Outras considerações
9.1 Coleta de Lixo do Servidor
Alguns usuários podem enfrentar a contenção de recursos que limita o paralelismo que estão esperando quando o Coletor de Lixo não está configurado corretamente. Sempre que o EF for usado em um cenário multithread ou em qualquer aplicativo semelhante a um sistema do lado do servidor, habilite a Coleta de Lixo do Servidor. Isso é feito por meio de uma configuração simples no arquivo de configuração do aplicativo:
<?xmlversion="1.0" encoding="utf-8" ?>
<configuration>
<runtime>
<gcServer enabled="true" />
</runtime>
</configuration>
Isso deve diminuir a contenção de threads e aumentar sua taxa de transferência em até 30% em cenários saturados de CPU. Em termos gerais, você sempre deve testar como seu aplicativo se comporta usando a Coleta de Lixo clássica (que é melhor ajustada para cenários da interface do usuário e do lado do cliente), bem como a Coleta de Lixo do Servidor.
9.2 AutoDetectChanges
Conforme mencionado anteriormente, o Entity Framework pode mostrar problemas de desempenho quando o cache de objetos tiver muitas entidades. Determinadas operações, como Add, Remove, Find, Entry, SaveChanges, disparam chamadas para DetectChanges que podem consumir uma grande quantidade de CPU com base no tamanho do cache de objetos. O motivo disso é que o cache de objetos e o gerenciador de estado do objeto tentam permanecer o mais sincronizados possível em cada operação executada em um contexto para que os dados produzidos estejam corretos em uma ampla variedade de cenários.
Geralmente, é uma boa prática deixar a detecção automática de alterações do Entity Framework habilitada durante toda a vida útil do aplicativo. Se o cenário estiver sendo afetado negativamente pelo alto uso da CPU e seus perfis indicarem que o culpado é a chamada para DetectChanges, considere desativar temporariamente AutoDetectChanges na parte confidencial do código:
try
{
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
...
}
finally
{
context.Configuration.AutoDetectChangesEnabled = true;
}
Antes de desativar AutoDetectChanges, é bom entender que isso pode fazer com que o Entity Framework perca a capacidade de controlar determinadas informações sobre as alterações que estão ocorrendo nas entidades. Se tratado incorretamente, isso pode causar inconsistência de dados em seu aplicativo. Para obter mais informações sobre como desativar AutoDetectChanges, leia <http://blog.oneunicorn.com/2012/03/12/secrets-of-detectchanges-part-3-switching-off-automatic-detectchanges/>.
9.3 Contexto por solicitação
Os contextos do Entity Framework devem ser usados como instâncias de curta duração para fornecer a experiência de desempenho mais ideal. Espera-se que os contextos sejam de curta duração e descartados e, como tal, tenham sido implementados para serem muito leves e reutilizar metadados sempre que possível. Em cenários da Web, é importante ter isso em mente e não ter um contexto por mais do que a duração de uma única solicitação. Da mesma forma, em cenários não web, o contexto deve ser descartado com base na compreensão dos diferentes níveis de cache no Entity Framework. De modo geral, deve-se evitar ter uma instância de contexto ao longo da vida útil do aplicativo, bem como contextos por thread e contextos estáticos.
9.4 Semântica nula do banco de dados
O Entity Framework, por padrão, gerará código SQL que tem semântica de comparação nula em C#. Considere o exemplo de consulta seguinte:
int? categoryId = 7;
int? supplierId = 8;
decimal? unitPrice = 0;
short? unitsInStock = 100;
short? unitsOnOrder = 20;
short? reorderLevel = null;
var q = from p incontext.Products
where p.Category.CategoryName == "Beverages"
|| (p.CategoryID == categoryId
|| p.SupplierID == supplierId
|| p.UnitPrice == unitPrice
|| p.UnitsInStock == unitsInStock
|| p.UnitsOnOrder == unitsOnOrder
|| p.ReorderLevel == reorderLevel)
select p;
var r = q.ToList();
Neste exemplo, estamos comparando várias variáveis anuláveis com propriedades anuláveis na entidade, como SupplierID e UnitPrice. O SQL gerado para essa consulta perguntará se o valor do parâmetro é o mesmo que o valor da coluna ou se os valores do parâmetro e da coluna são nulos. Isso ocultará a maneira como o servidor de banco de dados lida com nulos e fornecerá uma experiência nula em C# consistente entre diferentes fornecedores de banco de dados. Por outro lado, o código gerado é um pouco complicado e pode não ter um bom desempenho quando a quantidade de comparações na instrução onde a instrução da consulta cresce para um número grande.
Uma maneira de lidar com essa situação é usando a semântica nula do banco de dados. Observe que isso pode se comportar de forma diferente para a semântica nula do C#, pois agora o Entity Framework gerará UM SQL mais simples que expõe a maneira como o mecanismo de banco de dados lida com valores nulos. A semântica nula do banco de dados pode ser ativada por contexto com uma única linha de configuração em relação à configuração de contexto:
context.Configuration.UseDatabaseNullSemantics = true;
Consultas de tamanho pequeno a médio não exibirão uma melhoria de desempenho perceptível ao usar a semântica nula do banco de dados, mas a diferença se tornará mais perceptível em consultas com um grande número de possíveis comparações nulas.
Na consulta de exemplo acima, a diferença de desempenho foi inferior a 2% em uma marca de microesfera em execução em um ambiente controlado.
9.5 Assíncrono
O Entity Framework 6 introduziu suporte a operações assíncronas durante a execução no .NET 4.5 ou posterior. Na maioria das vezes, os aplicativos que têm contenção relacionada à E/S se beneficiarão mais com o uso de operações de consulta e salvamento assíncronas. Se o aplicativo não sofrer de contenção de E/S, o uso de assíncrono, nos melhores casos, será executado de forma síncrona e retornará o resultado na mesma quantidade de tempo que uma chamada síncrona ou, na pior das hipóteses, simplesmente adiará a execução para uma tarefa assíncrona e adicionará tempo extra à conclusão do seu cenário.
Para obter informações sobre como a programação assíncrona funciona que ajudará você a decidir se assíncrono melhorará o desempenho do aplicativo, consulte Programação Assíncrona com Assíncrono e Await. Para obter mais informações sobre o uso de operações assíncronas no Entity Framework, consulte Async Query and Save.
9.6 NGEN
O Entity Framework 6 não vem na instalação padrão do .NET Framework. Assim, os assemblies do Entity Framework não são NGEN'd por padrão, o que significa que todo o código do Entity Framework está sujeito aos mesmos custos JIT'ing que qualquer outro assembly MSIL. Isso pode prejudicar a experiência do F5 durante o desenvolvimento e também a inicialização a frio do aplicativo nos ambientes de produção. Para reduzir os custos de CPU e memória do JIT'ing, é aconselhável para NGEN as imagens da Entity Framework, conforme apropriado. Para obter mais informações sobre como melhorar o desempenho de inicialização do Entity Framework 6 com o NGEN, consulte Como melhorar o desempenho de inicialização com o NGen.
9.7 Code First versus EDMX
Entity Framework considera sobre o problema de incompatibilidade de impedância entre programação orientada a objeto e bancos de dados relacionais por ter uma representação na memória do modelo conceitual (os objetos), o esquema de armazenamento (o banco de dados) e um mapeamento entre os dois. Esses metadados são chamados de modelo de dados de entidade ou EDM para abreviar. Neste EDM, o Entity Framework derivará as exibições para arredondar dados dos objetos na memória para o banco de dados e voltar.
Quando o Entity Framework é usado com um arquivo EDMX que especifica formalmente o modelo conceitual, o esquema de armazenamento e o mapeamento, o estágio de carregamento do modelo só precisa validar se o EDM está correto (por exemplo, verifique se não há mapeamentos ausentes), em seguida, gere as exibições e valide as exibições e tenha esses metadados prontos para uso. Somente então uma consulta pode ser executada ou novos dados podem ser salvos no armazenamento de dados.
A abordagem Code First é, em seu coração, um sofisticado gerador de modelo de dados de entidade. O Entity Framework precisa produzir um EDM do código fornecido; ele faz isso analisando as classes envolvidas no modelo, aplicando convenções e configurando o modelo por meio da API fluente. Depois que o EDM é criado, o Entity Framework se comporta essencialmente da mesma maneira que faria se um arquivo EDMX estivesse presente no projeto. Assim, a criação do modelo do Code First adiciona complexidade extra que se traduz em um tempo de inicialização mais lento para o Entity Framework quando comparado a ter um EDMX. O custo depende completamente do tamanho e da complexidade do modelo que está sendo criado.
Ao optar por usar EDMX versus Code First, é importante saber que a flexibilidade introduzida pelo Code First aumenta o custo de criação do modelo pela primeira vez. Se o aplicativo puder suportar o custo dessa carga pela primeira vez, normalmente o Code First será o caminho preferido.
10. Investigando o desempenho
10.1 Usando o criador de perfil do Visual Studio
Se você estiver tendo problemas de desempenho com o Entity Framework, poderá usar um criador de perfil como aquele integrado ao Visual Studio para ver onde seu aplicativo está gastando seu tempo. Essa é a ferramenta que usamos para gerar os gráficos de pizza na postagem de blog ( <https://learn.microsoft.com/archive/blogs/adonet/exploring-the-performance-of-the-ado-net-entity-framework-part-1>) "Explorando o desempenho do ADO.NET Entity Framework – que mostra onde o Entity Framework passa seu tempo durante consultas em armazenamento cold e consultas warm.
A postagem no blog "Criação de Perfil da Estrutura de Entidades usando o Criador de Perfil do Visual Studio 2010" escrita pela Equipe de Consultoria de Clientes de Dados e Modelagem mostra um exemplo real de como eles usaram o criador de perfil para investigar um problema de desempenho. <https://learn.microsoft.com/archive/blogs/dmcat/profiling-entity-framework-using-the-visual-studio-2010-profiler>. Esta postagem foi gravada para um aplicativo do Windows. Se você precisar criar o perfil de um aplicativo Web, as ferramentas WPR (Windows Performance Recorder) e WPA (Windows Performance Analyzer) poderão funcionar melhor do que trabalhar no Visual Studio. O WPR e o WPA fazem parte do Kit de Ferramentas de Desempenho do Windows que está incluído no Kit de Avaliação e Implantação do Windows.
10.2 Criação de perfil de aplicativo/banco de dados
Ferramentas como o criador de perfil integrado ao Visual Studio informam onde seu aplicativo está gastando tempo. Outro tipo de criador de perfil está disponível que executa a análise dinâmica do aplicativo em execução, seja em produção ou pré-produção, dependendo das necessidades, e procura armadilhas comuns e antipadrões de acesso ao banco de dados.
Dois profilers disponíveis comercialmente são o Entity Framework Profiler ( <http://efprof.com>) e o ORMProfiler ( <http://ormprofiler.com>).
Se o aplicativo for um aplicativo MVC usando o Code First, você poderá usar o MiniProfiler do StackExchange. Scott Hanselman descreve esta ferramenta em seu blog em: <http://www.hanselman.com/blog/NuGetPackageOfTheWeek9ASPNETMiniProfilerFromStackExchangeRocksYourWorld.aspx>.
Para obter mais informações sobre a criação de perfil da atividade de banco de dados do aplicativo, veja o artigo da Revista MSDN de Julie Lerman intitulado Atividade de Banco de Dados de Criação de Perfil no Entity Framework.
10.3 Agente de banco de dados
Se você estiver usando o Entity Framework 6, considere também usar a funcionalidade de log interno. A propriedade Database do contexto pode ser instruída a registrar sua atividade em log por meio de uma configuração simples de uma linha:
using (var context = newQueryComparison.DbC.NorthwindEntities())
{
context.Database.Log = Console.WriteLine;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
Neste exemplo, a atividade do banco de dados será registrada no console, mas a propriedade Log pode ser configurada para chamar qualquer representante de <cadeia de caracteres>de ação.
Se você quiser habilitar o registro em log de banco de dados sem recompilar e estiver usando o Entity Framework 6.1 ou posterior, poderá fazer isso adicionando um interceptor no arquivo web.config ou app.config do seu aplicativo.
<interceptors>
<interceptor type="System.Data.Entity.Infrastructure.Interception.DatabaseLogger, EntityFramework">
<parameters>
<parameter value="C:\Path\To\My\LogOutput.txt"/>
</parameters>
</interceptor>
</interceptors>
Para obter mais informações sobre como adicionar registro em log sem recompilar, vá para <http://blog.oneunicorn.com/2014/02/09/ef-6-1-turning-on-logging-without-recompiling/>.
11. Apêndice
11.1 A. Ambiente de teste
Esse ambiente usa uma configuração de dois computadores com o banco de dados em um computador separado do aplicativo cliente. Os computadores estão no mesmo rack, portanto, a latência de rede é relativamente baixa, mas mais realista do que um ambiente de máquina única.
11.1.1 Servidor de Aplicativos
11.1.1.1 Ambiente de Software
- Ambiente de software do Entity Framework 4
- Nome do sistema operacional: Windows Server 2008 R2 Enterprise SP1.
- Visual Studio 2010 – Ultimate.
- Visual Studio 2010 SP1 (apenas para algumas comparações).
- Entity Framework 5 e 6 Software Environment
- Nome do sistema operacional: Windows 8.1 Enterprise
- Visual Studio 2013 – Ultimate.
11.1.1.2 Ambiente de hardware
- Processador duplo: Intel(R) Xeon(R) CPU L5520 W3530 @ 2.27GHz, 2261 Mhz8 GHz, 4 Core(s), 84 Processadores Lógicos(s).
- 2412 GB de RamRAM.
- 136 GB SCSI250GB unidade SATA 7200 rpm de 3 GB/s dividida em 4 partições.
11.1.2 Servidor de BD
11.1.2.1 Ambiente de Software
- Nome do sistema operacional: Windows Server 2008 R28.1 Enterprise SP1.
- SQL Server 2008 R22012.
11.1.2.2 Ambiente de hardware
- Processador único: Intel(R) Xeon(R) CPU L5520 @ 2.27GHz, 2261 MhzES-1620 0 @ 3.60GHz, 4 Core(s), 8 Processadores Lógicos(s).
- 824 GB de RamRAM.
- 465 GB ATA500GB unidade SATA 7200 rpm de 6 GB/s dividida em 4 partições.
11.2 B. Testes de comparação de desempenho de consulta
O modelo Northwind foi usado para executar esses testes. Ele foi gerado do banco de dados usando o designer do Entity Framework. Em seguida, o código a seguir foi usado para comparar o desempenho das opções de execução da consulta:
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.Common;
using System.Data.Entity.Infrastructure;
using System.Data.EntityClient;
using System.Data.Objects;
using System.Linq;
namespace QueryComparison
{
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IQueryable<Product> InvokeProductsForCategoryCQ(string categoryName)
{
return productsForCategoryCQ(this, categoryName);
}
}
public class QueryTypePerfComparison
{
private static string entityConnectionStr = @"metadata=res://*/Northwind.csdl|res://*/Northwind.ssdl|res://*/Northwind.msl;provider=System.Data.SqlClient;provider connection string='data source=.;initial catalog=Northwind;integrated security=True;multipleactiveresultsets=True;App=EntityFramework'";
public void LINQIncludingContextCreation()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTracking()
{
using (NorthwindEntities context = new NorthwindEntities())
{
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void CompiledQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.InvokeProductsForCategoryCQ("Beverages");
q.ToList();
}
}
public void ObjectQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
products.ToList();
}
}
public void EntityCommand()
{
using (EntityConnection eConn = new EntityConnection(entityConnectionStr))
{
eConn.Open();
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
List<Product> productsList = new List<Product>();
while (reader.Read())
{
DbDataRecord record = (DbDataRecord)reader.GetValue(0);
// 'materialize' the product by accessing each field and value. Because we are materializing products, we won't have any nested data readers or records.
int fieldCount = record.FieldCount;
// Treat all products as Product, even if they are the subtype DiscontinuedProduct.
Product product = new Product();
product.ProductID = record.GetInt32(0);
product.ProductName = record.GetString(1);
product.SupplierID = record.GetInt32(2);
product.CategoryID = record.GetInt32(3);
product.QuantityPerUnit = record.GetString(4);
product.UnitPrice = record.GetDecimal(5);
product.UnitsInStock = record.GetInt16(6);
product.UnitsOnOrder = record.GetInt16(7);
product.ReorderLevel = record.GetInt16(8);
product.Discontinued = record.GetBoolean(9);
productsList.Add(product);
}
}
}
}
public void ExecuteStoreQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectResult<Product> beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Database.SqlQuery\<QueryComparison.DbC.Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbSet()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Products.SqlQuery(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void LINQIncludingContextCreationDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTrackingDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.AsNoTracking().Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
}
}
11.3 C. Modelo de Navision
O banco de dados Navision é um banco de dados grande usado para demonstrar o Microsoft Dynamics – NAV. O modelo conceitual gerado contém 1.005 conjuntos de entidades e 4.227 conjuntos de associações. O modelo usado no teste é "simples" – nenhuma herança foi adicionada a ele.
11.3.1 Consultas usadas para testes Navision
A lista de consultas usada com o modelo Navision contém três categorias de consultas Entity SQL:
11.3.1.1 Pesquisa
Uma consulta de pesquisa simples sem agregações
- Contagem: 16232
- Exemplo:
<Query complexity="Lookup">
<CommandText>Select value distinct top(4) e.Idle_Time From NavisionFKContext.Session as e</CommandText>
</Query>
11.3.1.2 SingleAggregating
Uma consulta de BI normal com várias agregações, mas sem subtotais (consulta única)
- Contagem: 2313
- Exemplo:
<Query complexity="SingleAggregating">
<CommandText>NavisionFK.MDF_SessionLogin_Time_Max()</CommandText>
</Query>
Onde MDF_SessionLogin_Time_Max() é definido no modelo como:
<Function Name="MDF_SessionLogin_Time_Max" ReturnType="Collection(DateTime)">
<DefiningExpression>SELECT VALUE Edm.Min(E.Login_Time) FROM NavisionFKContext.Session as E</DefiningExpression>
</Function>
11.3.1.3 AggregatingSubtotals
Uma consulta de BI com agregações e subtotais (por meio de união de todos)
- Contagem: 178
- Exemplo:
<Query complexity="AggregatingSubtotals">
<CommandText>
using NavisionFK;
function AmountConsumed(entities Collection([CRONUS_International_Ltd__Zone])) as
(
Edm.Sum(select value N.Block_Movement FROM entities as E, E.CRONUS_International_Ltd__Bin as N)
)
function AmountConsumed(P1 Edm.Int32) as
(
AmountConsumed(select value e from NavisionFKContext.CRONUS_International_Ltd__Zone as e where e.Zone_Ranking = P1)
)
----------------------------------------------------------------------------------------------------------------------
(
select top(10) Zone_Ranking, Cross_Dock_Bin_Zone, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking, E.Cross_Dock_Bin_Zone
)
union all
(
select top(10) Zone_Ranking, Cast(null as Edm.Byte) as P2, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking
)
union all
{
Row(Cast(null as Edm.Int32) as P1, Cast(null as Edm.Byte) as P2, AmountConsumed(select value E
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed))
}</CommandText>
<Parameters>
<Parameter Name="MinAmountConsumed" DbType="Int32" Value="10000" />
</Parameters>
</Query>