Analise o sentimento usando a ML.NET CLI
Saiba como usar ML.NET CLI para gerar automaticamente um modelo de ML.NET e código C# subjacente. Você fornece seu conjunto de dados e a tarefa de aprendizado de máquina que deseja implementar, e a CLI usa o mecanismo AutoML para criar o código-fonte de geração e implantação do modelo, bem como o modelo de classificação.
Neste tutorial, você fará as seguintes etapas:
- Preparar seus dados para a tarefa de aprendizado de máquina selecionada
- Execute o comando
mlnet classificationa partir da CLI - Rever os resultados da métrica de qualidade
- Compreender o código C# gerado para usar o modelo em seu aplicativo
- Explore o código C# gerado que foi usado para treinar o modelo
Observação
Este artigo refere-se à ferramenta ML.NET CLI, que está atualmente em pré-visualização, e o material está sujeito a alterações. Para obter mais informações, visite a página ML.NET .
A ML.NET CLI faz parte da ML.NET e seu principal objetivo é "democratizar" ML.NET para desenvolvedores .NET ao aprender ML.NET para que você não precise codificar do zero para começar.
Você pode executar a ML.NET CLI em qualquer prompt de comando (Windows, Mac ou Linux) para gerar modelos ML.NET e código-fonte de boa qualidade com base nos conjuntos de dados de treinamento fornecidos.
Pré-requisitos
- SDK do .NET 8 ou posterior
- (Opcional) Visual Studio
- ML.NET CLI
Você pode executar os projetos de código C# gerados do Visual Studio ou com dotnet run (.NET CLI).
Prepare os seus dados
Vamos usar um conjunto de dados existente usado para um cenário de 'Análise de Sentimento', que é uma tarefa de aprendizado de máquina de classificação binária. Você pode usar seu próprio conjunto de dados de maneira semelhante, e o modelo e o código serão gerados para você.
Faça o download do arquivo zip do conjunto de dados UCI Sentiment Labeled Sentences (veja as citações na nota a seguir)e descompacte-o em qualquer pasta que tu escolheres.
Observação
Os conjuntos de dados deste tutorial usam um conjunto de dados do 'From Group to Individual Labels using Deep Features', de Kotzias et al,. KDD 2015, e hospedado no UCI Machine Learning Repository - Dua, D. e Karra Taniskidou, E. (2017). Repositório UCI Machine Learning [http://archive.ics.uci.edu/ml]. Irvine, CA: Universidade da Califórnia, Escola de Informação e Ciência da Computação.
Copie o arquivo
yelp_labelled.txtpara qualquer pasta criada anteriormente (como/cli-test).Abra o prompt de comando preferido e vá para a pasta onde você copiou o arquivo do conjunto de dados. Por exemplo:
cd /cli-testUsando qualquer editor de texto, como o Visual Studio Code, você pode abrir e explorar o arquivo de conjunto de dados
yelp_labelled.txt. Você pode ver que a estrutura é:O arquivo não tem cabeçalho. Você usará o índice da coluna.
Existem apenas duas colunas:
Texto (Índice da coluna 0) Rótulo (índice da coluna 1) Uau... Adorei esse lugar. 1 Crosta não é boa. 0 Não é saboroso ea textura era apenas desagradável. 0 ... MUITAS MAIS LINHAS DE TEXTO... ... (1 ou 0)...
Certifique-se de fechar o arquivo de conjunto de dados do editor.
Agora, você está pronto para começar a usar a CLI para esse cenário de 'Análise de sentimento'.
Observação
Depois de terminar este tutorial, você também pode tentar com seus próprios conjuntos de dados, desde que eles estejam prontos para serem usados para qualquer uma das tarefas de ML atualmente suportadas pelo ML.NET CLI Preview, que são 'Classificação Binária', 'Classificação', 'Regressão', e 'Recomendação'.
Execute o comando 'mlnet classification'
Execute o seguinte comando ML.NET CLI:
mlnet classification --dataset "yelp_labelled.txt" --label-col 1 --has-header false --train-time 10Este comando executa o comando
mlnet classification:- para a tarefa de ML de classificação
- usa o arquivo de conjunto de dados
yelp_labelled.txtcomo conjunto de dados de treinamento e teste (internamente, a CLI usará validação cruzada ou dividi-lo-á em dois conjuntos de dados, um para treinamento e outro para teste) - onde a coluna objetivo/destino que deseja prever (comumente chamada de "rótulo") é a coluna com índice 1 (que é a segunda coluna, já que o índice é iniciado em zero)
- não utiliza um cabeçalho de arquivo com nomes de coluna, uma vez que este ficheiro de dados específico não possui um cabeçalho
- O de tempo de exploração/comboio direcionado para a experiência é de 10 segundos
Você verá a saída da CLI, semelhante a:
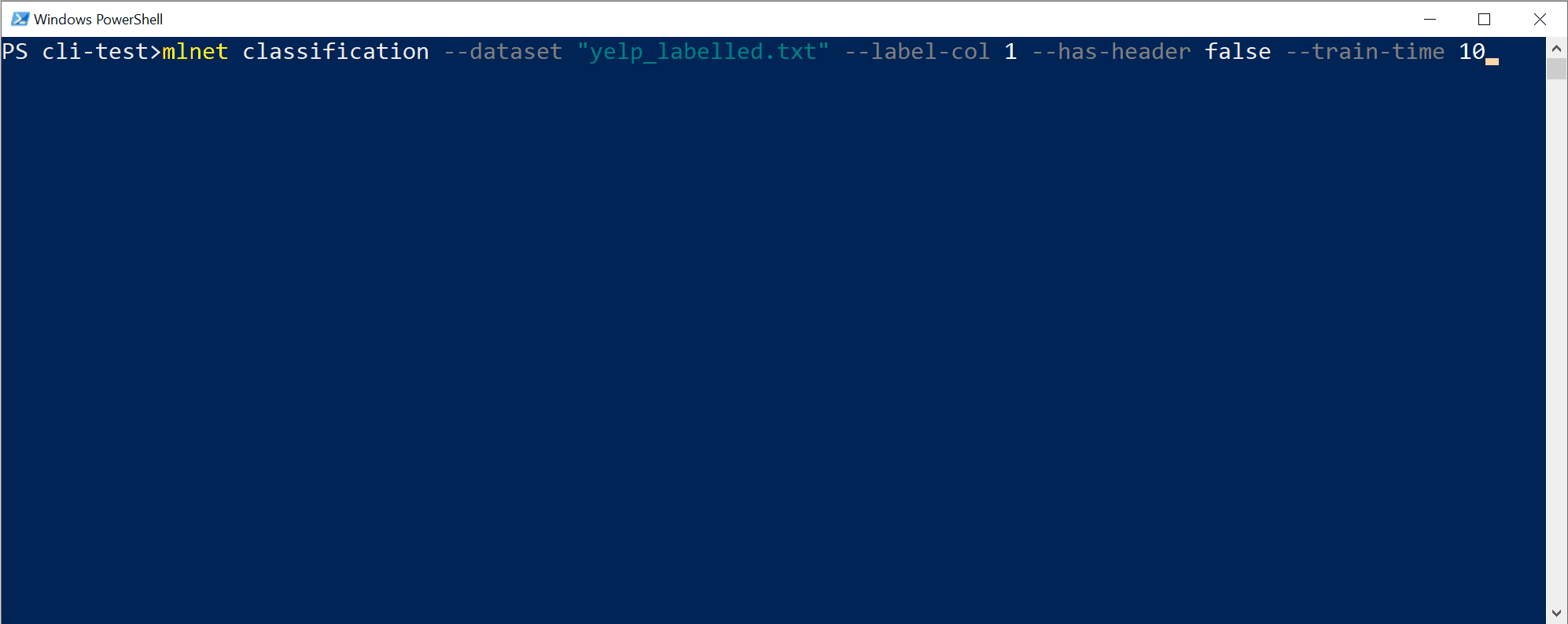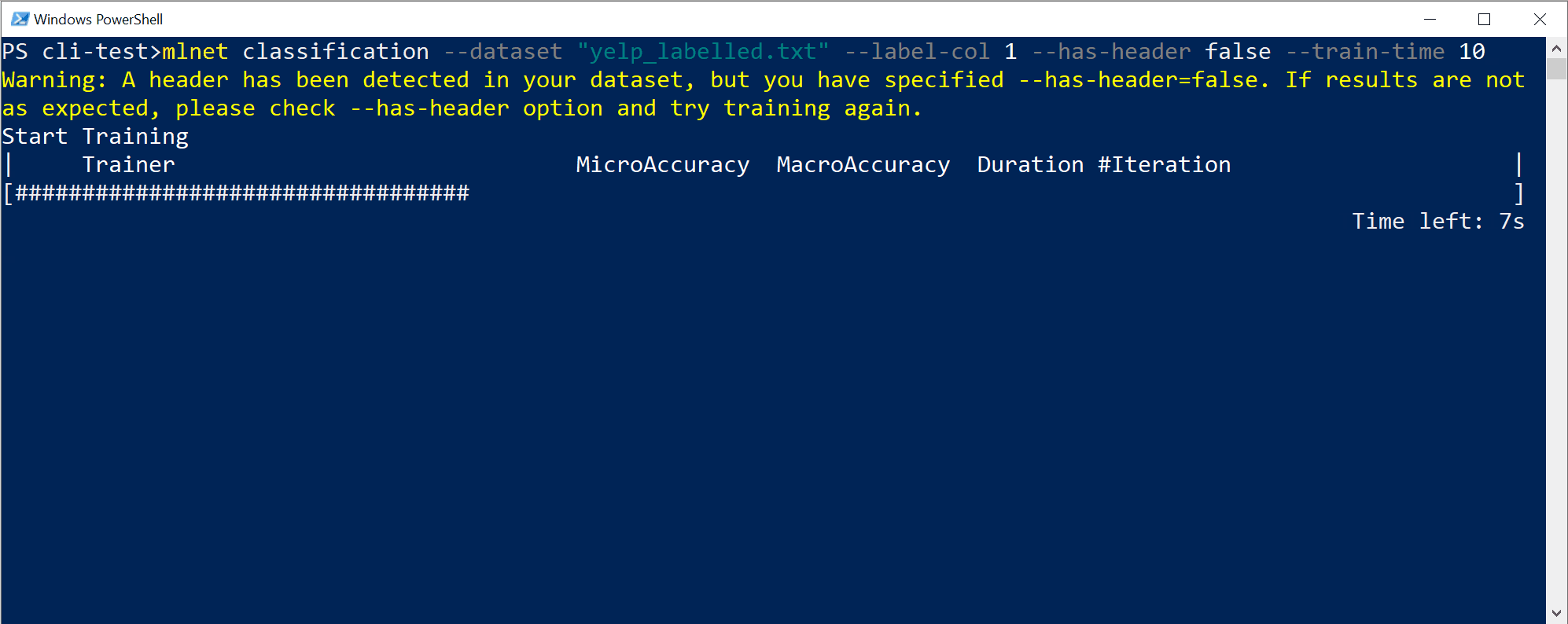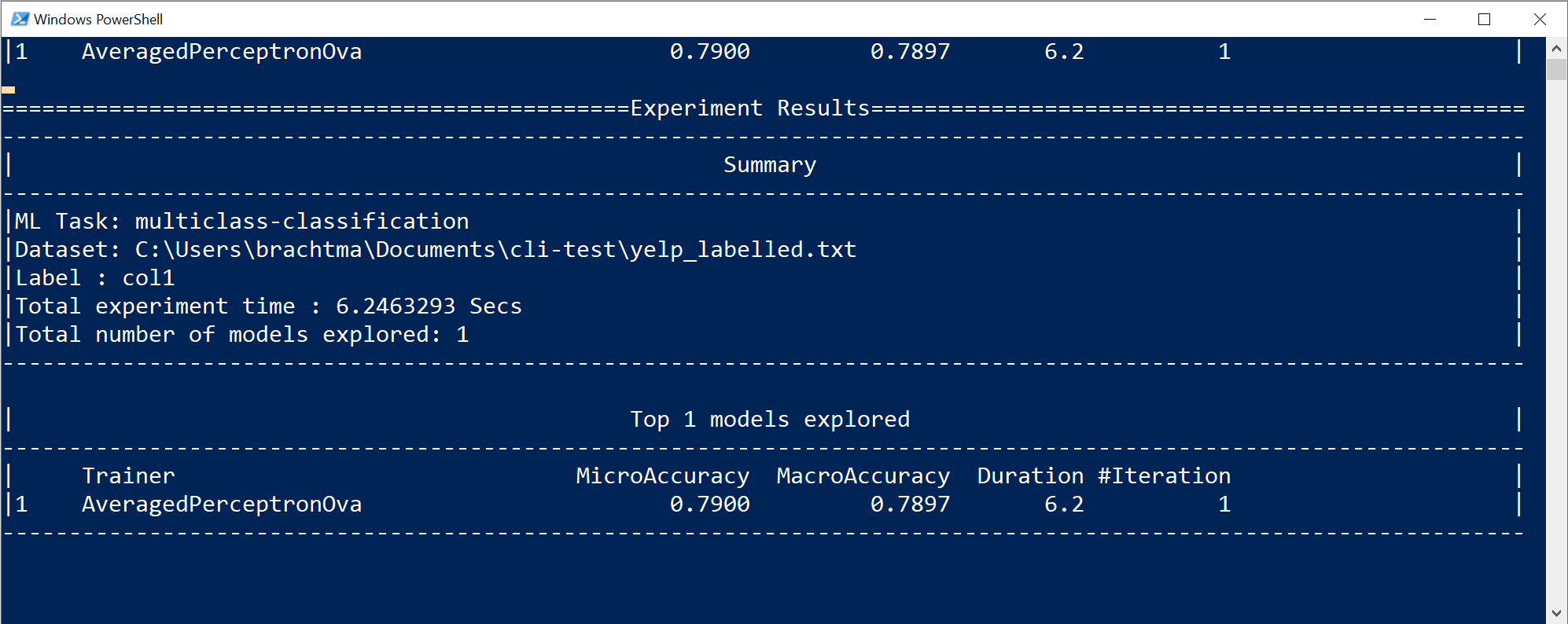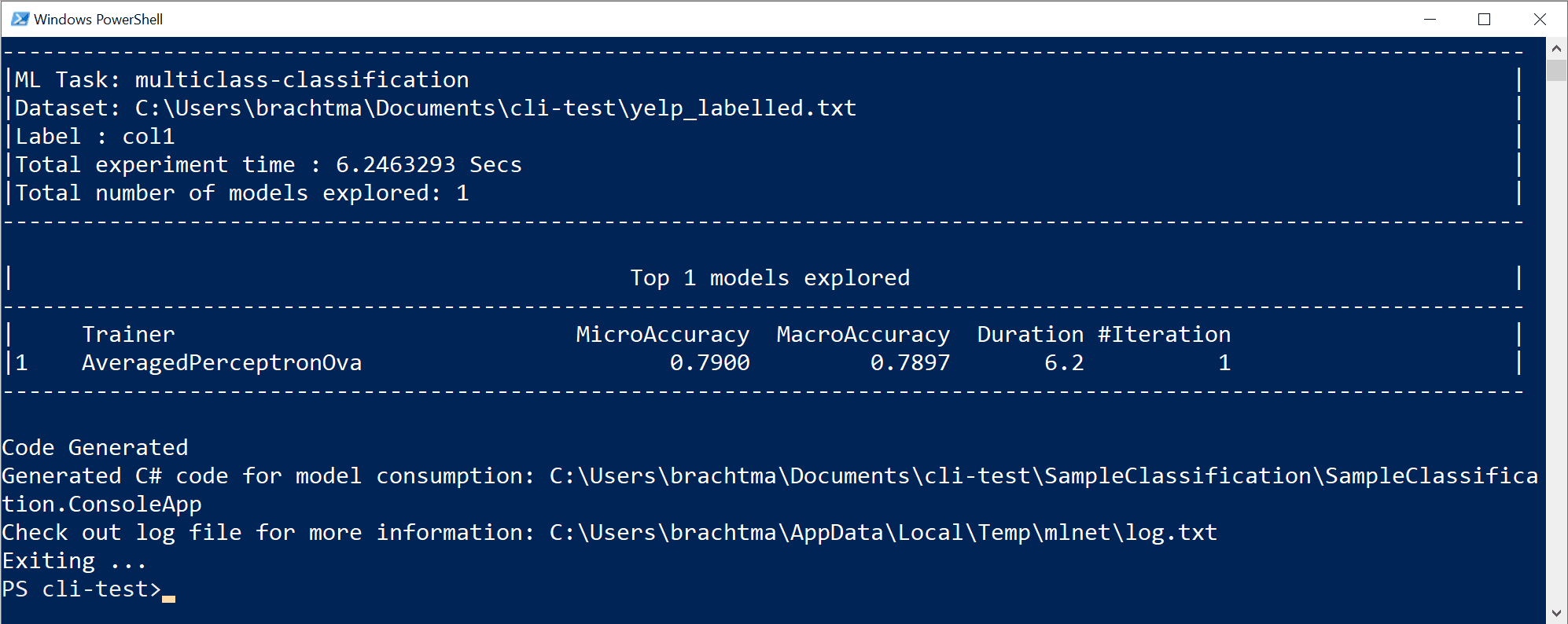
Neste caso em particular, em apenas 10 segundos e com o pequeno conjunto de dados fornecido, a ferramenta CLI foi capaz de executar algumas iterações, o que significa treinar várias vezes com base em diferentes combinações de algoritmos/configurações com diferentes transformações de dados internos e hiperparâmetros do algoritmo.
Finalmente, o modelo de "melhor qualidade" encontrado em 10 segundos é um modelo que usa um determinado treinador/algoritmo com qualquer configuração específica. Dependendo do tempo de exploração, o comando pode produzir um resultado diferente. A seleção é baseada nas várias métricas mostradas, como
Accuracy.Compreender as métricas de qualidade do modelo
A primeira e mais fácil métrica para avaliar um modelo de classificação binária é a precisão, que é simples de entender. "Precisão é a proporção de previsões corretas com um conjunto de dados de teste.". Quanto mais próximo de 100% (1,00), melhor.
No entanto, há casos em que apenas medir com a métrica Precisão não é suficiente, especialmente quando o rótulo (0 e 1 neste caso) está desequilibrado no conjunto de dados de teste.
Para obter métricas adicionais e informações mais detalhadas sobre as métricas como Precisão, AUC, AUCPR e pontuação F1 usadas para avaliar os diferentes modelos, consulte Noções básicas sobre métricas ML.NET.
Observação
Você pode tentar esse mesmo conjunto de dados e especificar alguns minutos para
--max-exploration-time(por exemplo, três minutos para especificar 180 segundos), o que encontrará um "melhor modelo" melhor para você com uma configuração de pipeline de treinamento diferente para esse conjunto de dados (que é muito pequeno, 1000 linhas).Para encontrar um modelo de "melhor/boa qualidade" que seja um "modelo pronto para produção" destinado a conjuntos de dados maiores, você deve fazer experimentos com a CLI geralmente especificando muito mais tempo de exploração, dependendo do tamanho do conjunto de dados. Na verdade, em muitos casos, você pode precisar de várias horas de tempo de exploração, especialmente se o conjunto de dados for grande em linhas e colunas.
A execução do comando anterior gerou os seguintes ativos:
- Um modelo serializado .zip ("melhor modelo") pronto para uso.
- Código C# para executar/pontuar o modelo gerado (Para fazer previsões em seus aplicativos de usuário final com esse modelo).
- Código de treinamento em C# usado para gerar esse modelo (fins de aprendizagem).
- Um arquivo de log com todas as iterações exploradas com informações detalhadas específicas sobre cada algoritmo tentado com sua combinação de hiperparâmetros e transformações de dados.
Os dois primeiros ativos (modelo de arquivo .ZIP e código C# para executar esse modelo) podem ser usados diretamente em seus aplicativos de usuário final (aplicativo Web ASP.NET Core, serviços, aplicativo de área de trabalho, etc.) para fazer previsões com esse modelo de ML gerado.
O terceiro ativo, o código de treinamento, mostra qual ML.NET código de API foi usado pela CLI para treinar o modelo gerado, para que você possa investigar quais treinadores/algoritmos específicos e hiperparâmetros foram selecionados pela CLI.
Esses ativos enumerados são explicados nas etapas a seguir do tutorial.
Explore o código C# gerado a ser usado para executar o modelo para fazer previsões
No Visual Studio, abra a solução gerada na pasta chamada
SampleClassificationdentro da pasta de destino original (ela foi nomeada/cli-testno tutorial). Deverá ver uma solução semelhante a:
Observação
O tutorial sugere o uso do Visual Studio, mas você também pode explorar o código C# gerado (dois projetos) com qualquer editor de texto e executar o aplicativo de console gerado com o
dotnet CLIem uma máquina macOS, Linux ou Windows.- O aplicativo de console gerado contém código de execução que você deve revisar e, em seguida, você geralmente reutiliza o 'código de pontuação' (código que executa o modelo de ML para fazer previsões) movendo esse código simples (apenas algumas linhas) para seu aplicativo de usuário final onde você deseja fazer as previsões.
- O ficheiro mbconfig gerado é um ficheiro de configuração que pode ser usado para re-treinar o seu modelo, seja através da CLI ou do Model Builder. Isso também terá dois arquivos de código associados a ele e um arquivo zip.
- O arquivo de de treinamento
contém o código para criar o pipeline de modelo usando a API ML.NET. - O arquivo consumo
contém o código para consumir o modelo. - O ficheiro zip que é o modelo gerado pela CLI.
- O arquivo de de treinamento
Abra o ficheiro SampleClassification.consumption.cs dentro do ficheiro mbconfig. Você verá que há classes de entrada e saída. Estas são classes de dados, ou classes POCO, usadas para armazenar dados. As classes contêm código clichê que é útil se seu conjunto de dados tiver dezenas ou até centenas de colunas.
- A classe
ModelInputé usada ao ler dados do conjunto de dados. - A classe
ModelOutputé usada para obter o resultado da previsão (dados de previsão).
- A classe
Abra o arquivo Program.cs e explore o código. Em apenas algumas linhas, você é capaz de executar o modelo e fazer uma previsão de amostra.
static void Main(string[] args) { // Create single instance of sample data from first line of dataset for model input ModelInput sampleData = new ModelInput() { Col0 = @"Wow... Loved this place.", }; // Make a single prediction on the sample data and print results var predictionResult = SampleClassification.Predict(sampleData); Console.WriteLine("Using model to make single prediction -- Comparing actual Col1 with predicted Col1 from sample data...\n\n"); Console.WriteLine($"Col0: {sampleData.Col0}"); Console.WriteLine($"\n\nPredicted Col1 value {predictionResult.PredictedLabel} \nPredicted Col1 scores: [{String.Join(",", predictionResult.Score)}]\n\n"); Console.WriteLine("=============== End of process, hit any key to finish ==============="); Console.ReadKey(); }As primeiras linhas de código criam uma amostra única de dados. Nesse caso, os dados de amostra única são baseados na primeira linha do conjunto de dados a ser usado para a previsão. Você também pode criar seus próprios dados 'codificados' atualizando o código:
ModelInput sampleData = new ModelInput() { Col0 = "The ML.NET CLI is great for getting started. Very cool!" };A próxima linha de código usa o método
SampleClassification.Predict()nos dados de entrada especificados para fazer uma previsão e retornar os resultados (com base no esquema ModelOutput.cs).As últimas linhas de código imprimem as propriedades dos dados de amostra (neste caso, o Comentário), bem como a previsão de Sentimento e as pontuações correspondentes para sentimento positivo (1) e sentimento negativo (2).
Execute o projeto, usando os dados de exemplo originais carregados da primeira linha do conjunto de dados ou fornecendo seus próprios dados de exemplo personalizados codificados. Você deve obter uma previsão comparável a:
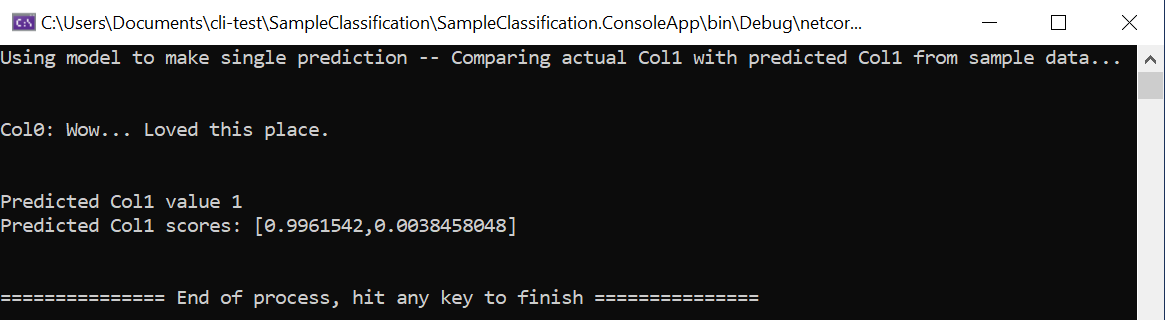
Tente alterar os dados de amostra codificados para outras frases com sentimentos diferentes e veja como o modelo prevê sentimentos positivos ou negativos.
Incorpore os seus aplicativos de utilizador final com previsões de modelos de Aprendizagem Automática
Você pode usar um "código de pontuação de modelo de ML" semelhante para executar o modelo em seu aplicativo de usuário final e fazer previsões.
Por exemplo, você pode mover diretamente esse código para qualquer aplicativo da área de trabalho do Windows, como WPF e WinForms e executar o modelo da mesma maneira que foi feito no aplicativo de console.
No entanto, a maneira como você implementa essas linhas de código para executar um modelo de ML deve ser otimizada (ou seja, armazenar em cache o arquivo de .zip do modelo e carregá-lo uma vez) e ter objetos singleton em vez de criá-los em todas as solicitações, especialmente se seu aplicativo precisar ser escalável, como um aplicativo Web ou serviço distribuído, conforme explicado na seção a seguir.
Executando modelos ML.NET em aplicativos e serviços Web escaláveis ASP.NET Core (aplicativos multithreaded)
A criação do objeto de modelo (ITransformer carregado a partir do arquivo .zip de um modelo) e o objeto PredictionEngine devem ser otimizados, especialmente quando executados em aplicativos Web escaláveis e serviços distribuídos. Para o primeiro caso, o objeto modelo (ITransformer) a otimização é simples. Como o objeto ITransformer é thread-safe, você pode armazenar o objeto em cache como um objeto singleton ou estático para carregar o modelo uma vez.
Para o segundo objeto, o objeto PredictionEngine, não é tão fácil porque o objeto PredictionEngine não é thread-safe, portanto, você não pode instanciar esse objeto como singleton ou objeto estático em um aplicativo ASP.NET Core. Esse problema de thread-safe e de escalabilidade é profundamente discutido neste post do blog .
No entanto, as coisas ficaram muito mais fáceis para você do que o que é explicado nessa postagem do blog. Trabalhámos numa abordagem mais simples para si e criámos um '.NET Integration Package' que pode utilizar facilmente nas suas aplicações e serviços ASP.NET Core, registando-o nos serviços de DI da aplicação (serviços de injeção de dependência) e, em seguida, utilizá-lo diretamente a partir do seu código. Verifique o seguinte tutorial e exemplo para fazer isso:
- Tutorial: Executando modelos ML.NET em aplicativos Web ASP.NET Core escaláveis e WebAPIs
- Exemplo: Modelo de ML.NET escalável em ASP.NET Core WebAPI
Explore o código C# gerado que foi usado para treinar o modelo de "melhor qualidade"
Para fins de aprendizagem mais avançados, você também pode explorar o código C# gerado que foi usado pela ferramenta CLI para treinar o modelo gerado.
Esse código de modelo de treinamento é gerado no arquivo chamado SampleClassification.training.cs, para que você possa investigar esse código de treinamento.
Mais importante, para este cenário específico (modelo de Análise de Sentimento), você também pode comparar o código de treinamento gerado com o código explicado no tutorial a seguir:
É interessante comparar o algoritmo escolhido e a configuração do pipeline no tutorial com o código gerado pela ferramenta CLI. Dependendo de quanto tempo você gasta iterando e procurando modelos melhores, o algoritmo escolhido pode ser diferente, juntamente com seus hiperparâmetros específicos e configuração de pipeline.
Neste tutorial, você aprendeu como:
- Preparar seus dados para a tarefa de ML selecionada (problema a ser resolvido)
- Execute o comando 'mlnet classification' na ferramenta CLI
- Rever os resultados da métrica de qualidade
- Compreender o código C# gerado para executar o modelo (Código a ser usado em seu aplicativo de usuário final)
- Explore o código C# gerado que foi usado para treinar o modelo de "melhor qualidade" (fins de ganho)