Trabalhando com dados em ASP.NET aplicativos principais
Gorjeta
Este conteúdo é um excerto do eBook, Architect Modern Web Applications with ASP.NET Core e Azure, disponível no .NET Docs ou como um PDF transferível gratuito que pode ser lido offline.

"Os dados são uma coisa preciosa e durarão mais do que os próprios sistemas."
Tim Berners-Lee
O acesso aos dados é uma parte importante de quase todas as aplicações de software. O ASP.NET Core suporta várias opções de acesso a dados, incluindo o Entity Framework Core (e também o Entity Framework 6), e pode funcionar com qualquer estrutura de acesso a dados .NET. A escolha de qual estrutura de acesso a dados usar depende das necessidades do aplicativo. Abstrair essas opções dos projetos ApplicationCore e UI e encapsular detalhes de implementação em Infraestrutura ajuda a produzir software fracamente acoplado e testável.
Entity Framework Core (para bancos de dados relacionais)
Se você estiver escrevendo um novo aplicativo ASP.NET Core que precisa trabalhar com dados relacionais, o Entity Framework Core (EF Core) é a maneira recomendada para seu aplicativo acessar seus dados. O EF Core é um mapeador objeto-relacional (O/RM) que permite que os desenvolvedores do .NET persistam objetos de e para uma fonte de dados. Ele elimina a necessidade da maioria dos códigos de acesso a dados que os desenvolvedores normalmente precisariam escrever. Tal como o ASP.NET Core, o EF Core foi reescrito de raiz para suportar aplicações modulares multiplataforma. Você o adiciona ao seu aplicativo como um pacote NuGet, configura-o durante a inicialização do aplicativo e solicita-o por meio de injeção de dependência sempre que precisar.
Para usar o EF Core com um banco de dados do SQL Server, execute o seguinte comando dotnet CLI:
dotnet add package Microsoft.EntityFrameworkCore.SqlServer
Para adicionar suporte para uma fonte de dados InMemory, para teste:
dotnet add package Microsoft.EntityFrameworkCore.InMemory
O DbContext
Para trabalhar com o EF Core, você precisa de uma subclasse de DbContext. Essa classe contém propriedades que representam coleções das entidades com as quais seu aplicativo trabalhará. O exemplo eShopOnWeb inclui um CatalogContext com coleções para itens, marcas e tipos:
public class CatalogContext : DbContext
{
public CatalogContext(DbContextOptions<CatalogContext> options) : base(options)
{
}
public DbSet<CatalogItem> CatalogItems { get; set; }
public DbSet<CatalogBrand> CatalogBrands { get; set; }
public DbSet<CatalogType> CatalogTypes { get; set; }
}
Seu DbContext deve ter um construtor que aceita DbContextOptions e passa esse argumento para o construtor base DbContext . Se você tiver apenas um DbContext em seu aplicativo, poderá passar uma instância de , mas se tiver mais de DbContextOptionsum, deverá usar o tipo genérico DbContextOptions<T> , passando o tipo DbContext como o parâmetro genérico.
Configurando o EF Core
No aplicativo ASP.NET Core, você normalmente configurará o EF Core em Program.cs com as outras dependências do aplicativo. O EF Core usa um DbContextOptionsBuilder, que suporta vários métodos de extensão úteis para simplificar sua configuração. Para configurar CatalogContext para usar um banco de dados do SQL Server com uma cadeia de conexão definida em Configuration, você adicionaria o seguinte código:
builder.Services.AddDbContext<CatalogContext>(
options => options.UseSqlServer(
builder.Configuration.GetConnectionString("DefaultConnection")));
Para usar o banco de dados na memória:
builder.Services.AddDbContext<CatalogContext>(options =>
options.UseInMemoryDatabase());
Depois de instalar o EF Core, criar um tipo filho DbContext e adicionar o tipo aos serviços do aplicativo, você estará pronto para usar o EF Core. Você pode solicitar uma instância do seu tipo DbContext em qualquer serviço que precise dela e começar a trabalhar com suas entidades persistentes usando LINQ como se estivessem simplesmente em uma coleção. O EF Core faz o trabalho de traduzir suas expressões LINQ em consultas SQL para armazenar e recuperar seus dados.
Você pode ver as consultas que o EF Core está executando configurando um registrador e garantindo que seu nível esteja definido como pelo menos Informações, como mostra a Figura 8-1.
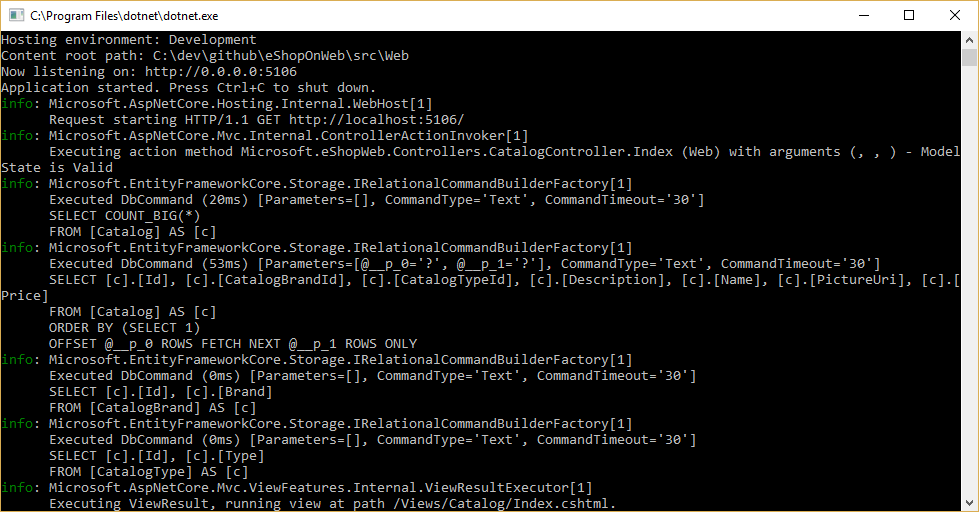
Figura 8-1. Registrando consultas do EF Core no console
Obtenção e armazenamento de dados
Para recuperar dados do EF Core, acesse a propriedade apropriada e use o LINQ para filtrar o resultado. Você também pode usar o LINQ para realizar projeção, transformando o resultado de um tipo para outro. O exemplo a seguir recuperaria CatalogBrands, ordenado por nome, filtrado por sua propriedade Enabled e projetado em um SelectListItem tipo:
var brandItems = await _context.CatalogBrands
.Where(b => b.Enabled)
.OrderBy(b => b.Name)
.Select(b => new SelectListItem {
Value = b.Id, Text = b.Name })
.ToListAsync();
É importante, no exemplo acima, adicionar a chamada para ToListAsync executar a consulta imediatamente. Caso contrário, a instrução atribuirá um IQueryable<SelectListItem> a brandItems, que não será executado até que seja enumerado. Há prós e contras em retornar IQueryable resultados de métodos. Ele permite que a consulta que o EF Core construirá seja modificada posteriormente, mas também pode resultar em erros que ocorrem apenas em tempo de execução, se as operações forem adicionadas à consulta que o EF Core não pode traduzir. Geralmente, é mais seguro passar quaisquer filtros para o método que executa o acesso aos dados e retornar uma coleção na memória (por exemplo, List<T>) como resultado.
O EF Core rastreia as alterações nas entidades que obtém da persistência. Para salvar as alterações em uma entidade controlada, basta chamar o SaveChangesAsync método no DbContext, certificando-se de que é a mesma instância DbContext que foi usada para buscar a entidade. Adicionar e remover entidades é feito diretamente na propriedade DbSet apropriada, novamente com uma chamada para SaveChangesAsync executar os comandos do banco de dados. O exemplo a seguir demonstra a adição, atualização e remoção de entidades da persistência.
// create
var newBrand = new CatalogBrand() { Brand = "Acme" };
_context.Add(newBrand);
await _context.SaveChangesAsync();
// read and update
var existingBrand = _context.CatalogBrands.Find(1);
existingBrand.Brand = "Updated Brand";
await _context.SaveChangesAsync();
// read and delete (alternate Find syntax)
var brandToDelete = _context.Find<CatalogBrand>(2);
_context.CatalogBrands.Remove(brandToDelete);
await _context.SaveChangesAsync();
O EF Core suporta métodos síncronos e assíncronos para buscar e salvar. Em aplicativos Web, é recomendável usar o padrão async/await com os métodos async, para que os threads do servidor Web não sejam bloqueados enquanto aguardam a conclusão das operações de acesso a dados.
Para obter mais informações, consulte Buffering e streaming.
Obtenção de dados relacionados
Quando o EF Core recupera entidades, ele preenche todas as propriedades armazenadas diretamente com essa entidade no banco de dados. As propriedades de navegação, como listas de entidades relacionadas, não são preenchidas e podem ter seu valor definido como null. Esse processo garante que o EF Core não esteja buscando mais dados do que o necessário, o que é especialmente importante para aplicativos Web, que devem processar rapidamente solicitações e retornar respostas de maneira eficiente. Para incluir relacionamentos com uma entidade usando carregamento ansioso, especifique a propriedade usando o método de extensão Include na consulta, conforme mostrado:
// .Include requires using Microsoft.EntityFrameworkCore
var brandsWithItems = await _context.CatalogBrands
.Include(b => b.Items)
.ToListAsync();
Você pode incluir vários relacionamentos e também pode incluir sub-relacionamentos usando ThenInclude. O EF Core executará uma única consulta para recuperar o conjunto de entidades resultante. Como alternativa, você pode incluir propriedades de navegação de propriedades de navegação passando um '.' -cadeia de caracteres separada para o .Include() método de extensão, assim:
.Include("Items.Products")
Além de encapsular a lógica de filtragem, uma especificação pode especificar a forma dos dados a serem retornados, incluindo quais propriedades preencher. O exemplo eShopOnWeb inclui várias especificações que demonstram o encapsulamento de informações de carregamento ansioso dentro da especificação. Você pode ver como a especificação é usada como parte de uma consulta aqui:
// Includes all expression-based includes
query = specification.Includes.Aggregate(query,
(current, include) => current.Include(include));
// Include any string-based include statements
query = specification.IncludeStrings.Aggregate(query,
(current, include) => current.Include(include));
Outra opção para carregar dados relacionados é usar o carregamento explícito. O carregamento explícito permite carregar dados adicionais em uma entidade que já foi recuperada. Como essa abordagem envolve uma solicitação separada para o banco de dados, ela não é recomendada para aplicativos Web, o que deve minimizar o número de viagens de ida e volta do banco de dados feitas por solicitação.
O carregamento lento é um recurso que carrega automaticamente os dados relacionados à medida que são referenciados pelo aplicativo. O EF Core adicionou suporte para carregamento lento na versão 2.1. O carregamento lento não está habilitado por padrão e requer a instalação do Microsoft.EntityFrameworkCore.Proxies. Tal como acontece com o carregamento explícito, o carregamento lento normalmente deve ser desativado para aplicativos da Web, uma vez que seu uso resultará em consultas de banco de dados adicionais sendo feitas dentro de cada solicitação da Web. Infelizmente, a sobrecarga incorrida pelo carregamento lento muitas vezes passa despercebida no momento do desenvolvimento, quando a latência é pequena e, muitas vezes, os conjuntos de dados usados para testes são pequenos. No entanto, na produção, com mais usuários, mais dados e mais latência, as solicitações adicionais de banco de dados muitas vezes podem resultar em baixo desempenho para aplicativos Web que fazem uso intensivo de carregamento lento.
Evite o carregamento lento de entidades em aplicativos Web
É uma boa ideia testar seu aplicativo enquanto examina as consultas reais do banco de dados que ele faz. Em determinadas circunstâncias, o EF Core pode fazer muito mais consultas ou uma consulta mais cara do que o ideal para o aplicativo. Um desses problemas é conhecido como explosão cartesiana. A equipe do EF Core disponibiliza o método AsSplitQuery como uma das várias maneiras de ajustar o comportamento do tempo de execução.
Encapsulamento de dados
O EF Core suporta vários recursos que permitem que seu modelo encapsular corretamente seu estado. Um problema comum em modelos de domínio é que eles expõem propriedades de navegação de coleção como tipos de lista acessíveis publicamente. Esse problema permite que qualquer colaborador manipule o conteúdo desses tipos de coleção, o que pode ignorar regras de negócios importantes relacionadas à coleção, possivelmente deixando o objeto em um estado inválido. A solução para esse problema é expor o acesso somente leitura a coleções relacionadas e fornecer explicitamente métodos que definem maneiras pelas quais os clientes podem manipulá-los, como neste exemplo:
public class Basket : BaseEntity
{
public string BuyerId { get; set; }
private readonly List<BasketItem> _items = new List<BasketItem>();
public IReadOnlyCollection<BasketItem> Items => _items.AsReadOnly();
public void AddItem(int catalogItemId, decimal unitPrice, int quantity = 1)
{
var existingItem = Items.FirstOrDefault(i => i.CatalogItemId == catalogItemId);
if (existingItem == null)
{
_items.Add(new BasketItem()
{
CatalogItemId = catalogItemId,
Quantity = quantity,
UnitPrice = unitPrice
});
}
else existingItem.Quantity += quantity;
}
}
Esse tipo de entidade não expõe um público List ou ICollection propriedade, mas expõe um IReadOnlyCollection tipo que encapsula o tipo List subjacente. Ao usar esse padrão, você pode indicar ao Entity Framework Core para usar o campo de suporte da seguinte forma:
private void ConfigureBasket(EntityTypeBuilder<Basket> builder)
{
var navigation = builder.Metadata.FindNavigation(nameof(Basket.Items));
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
}
Outra maneira de melhorar seu modelo de domínio é usando objetos de valor para tipos que não têm identidade e são distinguidos apenas por suas propriedades. O uso de tipos como propriedades de suas entidades pode ajudar a manter a lógica específica para o objeto de valor ao qual ele pertence e pode evitar lógica duplicada entre várias entidades que usam o mesmo conceito. No Entity Framework Core, você pode persistir objetos de valor na mesma tabela que sua entidade proprietária configurando o tipo como uma entidade de propriedade, da seguinte forma:
private void ConfigureOrder(EntityTypeBuilder<Order> builder)
{
builder.OwnsOne(o => o.ShipToAddress);
}
Neste exemplo, a ShipToAddress propriedade é do tipo Address. Address é um objeto value com várias propriedades, como Street e City. O EF Core mapeia o Order objeto para sua tabela com uma coluna por Address propriedade, prefixando cada nome de coluna com o nome da propriedade. Neste exemplo, a Order tabela incluiria colunas como ShipToAddress_Street e ShipToAddress_City. Também é possível armazenar tipos próprios em tabelas separadas, se desejado.
Saiba mais sobre o suporte a entidades próprias no EF Core.
Conexões resilientes
Recursos externos, como bancos de dados SQL, podem ocasionalmente não estar disponíveis. Em casos de indisponibilidade temporária, os aplicativos podem usar a lógica de repetição para evitar gerar uma exceção. Essa técnica é comumente chamada de resiliência de conexão. Você pode implementar sua própria tentativa com a técnica de backoff exponencial tentando repetir com um tempo de espera exponencialmente crescente, até que uma contagem máxima de tentativas tenha sido atingida. Essa técnica abrange o fato de que os recursos de nuvem podem estar intermitentemente indisponíveis por curtos períodos de tempo, resultando na falha de algumas solicitações.
Para o Banco de Dados SQL do Azure, o Entity Framework Core já fornece resiliência de conexão de banco de dados interno e lógica de repetição. Mas você precisa habilitar a estratégia de execução do Entity Framework para cada conexão DbContext se quiser ter conexões EF Core resilientes.
Por exemplo, o código a seguir no nível de conexão EF Core permite conexões SQL resilientes que são repetidas se a conexão falhar.
builder.Services.AddDbContext<OrderingContext>(options =>
{
options.UseSqlServer(builder.Configuration["ConnectionString"],
sqlServerOptionsAction: sqlOptions =>
{
sqlOptions.EnableRetryOnFailure(
maxRetryCount: 5,
maxRetryDelay: TimeSpan.FromSeconds(30),
errorNumbersToAdd: null);
}
);
});
Estratégias de execução e transações explícitas usando BeginTransaction e vários DbContexts
Quando novas tentativas são habilitadas em conexões EF Core, cada operação executada usando o EF Core se torna sua própria operação retryable. Cada consulta e cada chamada para SaveChangesAsync será repetida como uma unidade se ocorrer uma falha transitória.
No entanto, se o seu código inicia uma transação usando BeginTransaction, você está definindo seu próprio grupo de operações que precisam ser tratadas como uma unidade; Tudo dentro da transação tem que ser revertido se ocorrer uma falha. Você verá uma exceção como a seguinte se tentar executar essa transação ao usar uma estratégia de execução do EF (política de repetição) e incluir vários SaveChangesAsync de vários DbContexts nela.
System.InvalidOperationException: A estratégia SqlServerRetryingExecutionStrategy de execução configurada não suporta transações iniciadas pelo usuário. Use a estratégia de execução retornada por DbContext.Database.CreateExecutionStrategy() para executar todas as operações na transação como uma unidade retryable.
A solução é invocar manualmente a estratégia de execução do EF com um delegado representando tudo o que precisa ser executado. Se ocorrer uma falha transitória, a estratégia de execução invocará o delegado novamente. O código a seguir mostra como implementar essa abordagem:
// Use of an EF Core resiliency strategy when using multiple DbContexts
// within an explicit transaction
// See:
// https://learn.microsoft.com/ef/core/miscellaneous/connection-resiliency
var strategy = _catalogContext.Database.CreateExecutionStrategy();
await strategy.ExecuteAsync(async () =>
{
// Achieving atomicity between original Catalog database operation and the
// IntegrationEventLog thanks to a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
// Save to EventLog only if product price changed
if (raiseProductPriceChangedEvent)
{
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
}
});
O primeiro DbContext é o _catalogContext e o segundo DbContext está dentro do _integrationEventLogService objeto. Finalmente, a ação Commit seria executada em vários DbContexts e usando uma Estratégia de Execução do EF.
Referências – Entity Framework Core
- Documentos principais do EFhttps://learn.microsoft.com/ef/
- EF Core: Dados relacionadoshttps://learn.microsoft.com/ef/core/querying/related-data
- Evite o carregamento lento de entidades em aplicativos ASPNEThttps://ardalis.com/avoid-lazy-loading-entities-in-asp-net-applications
EF Core ou micro-ORM?
Embora o EF Core seja uma ótima opção para gerenciar a persistência e, na maioria das vezes, encapsula detalhes do banco de dados de desenvolvedores de aplicativos, não é a única opção. Outra alternativa popular de código aberto é o Dapper, um chamado micro-ORM. Um micro-ORM é uma ferramenta leve e menos completa para mapear objetos para estruturas de dados. No caso do Dapper, seus objetivos de design se concentram no desempenho, em vez de encapsular totalmente as consultas subjacentes que ele usa para recuperar e atualizar dados. Como não abstrai o SQL do desenvolvedor, o Dapper está "mais perto do metal" e permite que os desenvolvedores escrevam as consultas exatas que desejam usar para uma determinada operação de acesso a dados.
O EF Core tem dois recursos significativos que ele fornece que o separam do Dapper mas também aumentam sua sobrecarga de desempenho. A primeira é a tradução de expressões LINQ para SQL. Essas traduções são armazenadas em cache, mas mesmo assim há sobrecarga em realizá-las pela primeira vez. O segundo é o controle de alterações em entidades (para que instruções de atualização eficientes possam ser geradas). Esse comportamento pode ser desativado para consultas específicas usando a AsNoTracking extensão. O EF Core também gera consultas SQL que geralmente são muito eficientes e, em qualquer caso, perfeitamente aceitáveis do ponto de vista do desempenho, mas se você precisar de um bom controle sobre a consulta precisa a ser executada, você também pode passar SQL personalizado (ou executar um procedimento armazenado) usando o EF Core. Neste caso, o Dapper ainda supera o EF Core, mas apenas muito ligeiramente. Os dados de referência de desempenho atuais para uma variedade de métodos de acesso a dados podem ser encontrados no site do Dapper.
Para ver como a sintaxe do Dapper varia do EF Core, considere estas duas versões do mesmo método para recuperar uma lista de itens:
// EF Core
private readonly CatalogContext _context;
public async Task<IEnumerable<CatalogType>> GetCatalogTypes()
{
return await _context.CatalogTypes.ToListAsync();
}
// Dapper
private readonly SqlConnection _conn;
public async Task<IEnumerable<CatalogType>> GetCatalogTypesWithDapper()
{
return await _conn.QueryAsync<CatalogType>("SELECT * FROM CatalogType");
}
Se você precisar criar gráficos de objetos mais complexos com o Dapper, precisará escrever as consultas associadas por conta própria (em vez de adicionar um Include como faria no EF Core). Essa funcionalidade é suportada por meio de várias sintaxes, incluindo um recurso chamado Multi Mapping que permite mapear linhas individuais para vários objetos mapeados. Por exemplo, dada uma classe Post com um proprietário de propriedade do tipo User, o SQL a seguir retornaria todos os dados necessários:
select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id
Cada linha retornada inclui dados de usuário e postagem. Uma vez que os dados do Utilizador devem ser anexados aos dados do Post através da sua propriedade de Proprietário, é utilizada a seguinte função:
(post, user) => { post.Owner = user; return post; }
A listagem de código completo para retornar uma coleção de postagens com sua propriedade Proprietário preenchida com os dados de usuário associados seria:
var sql = @"select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id";
var data = connection.Query<Post, User, Post>(sql,
(post, user) => { post.Owner = user; return post;});
Como oferece menos encapsulamento, o Dapper exige que os desenvolvedores saibam mais sobre como seus dados são armazenados, como consultá-los de forma eficiente e escrever mais código para buscá-los. Quando o modelo muda, em vez de simplesmente criar uma nova migração (outro recurso EF Core) e/ou atualizar informações de mapeamento em um lugar em um DbContext, cada consulta afetada deve ser atualizada. Essas consultas não têm garantias de tempo de compilação, portanto, podem quebrar em tempo de execução em resposta a alterações no modelo ou banco de dados, tornando os erros mais difíceis de detetar rapidamente. Em troca dessas compensações, o Dapper oferece um desempenho extremamente rápido.
Para a maioria dos aplicativos e a maioria das partes de quase todos os aplicativos, o EF Core oferece um desempenho aceitável. Assim, é provável que seus benefícios de produtividade para desenvolvedores superem suas despesas gerais de desempenho. Para consultas que podem se beneficiar do cache, a consulta real só pode ser executada uma pequena porcentagem do tempo, tornando as diferenças de desempenho de consulta relativamente pequenas discutíveis.
SQL ou NoSQL
Tradicionalmente, bancos de dados relacionais como o SQL Server têm dominado o mercado de armazenamento de dados persistente, mas não são a única solução disponível. Bancos de dados NoSQL como o MongoDB oferecem uma abordagem diferente para armazenar objetos. Em vez de mapear objetos para tabelas e linhas, outra opção é serializar todo o gráfico de objetos e armazenar o resultado. Os benefícios desta abordagem, pelo menos inicialmente, são a simplicidade e o desempenho. É mais simples armazenar um único objeto serializado com uma chave do que decompor o objeto em muitas tabelas com relações e linhas de atualização que podem ter sido alteradas desde que o objeto foi recuperado pela última vez do banco de dados. Da mesma forma, buscar e desserializar um único objeto de um armazenamento baseado em chave é normalmente muito mais rápido e fácil do que junções complexas ou várias consultas de banco de dados necessárias para compor totalmente o mesmo objeto de um banco de dados relacional. A falta de bloqueios ou transações ou um esquema fixo também torna os bancos de dados NoSQL passíveis de escalabilidade em muitas máquinas, suportando conjuntos de dados muito grandes.
Por outro lado, os bancos de dados NoSQL (como são normalmente chamados) têm suas desvantagens. Os bancos de dados relacionais usam a normalização para impor consistência e evitar a duplicação de dados. Essa abordagem reduz o tamanho total do banco de dados e garante que as atualizações dos dados compartilhados estejam disponíveis imediatamente em todo o banco de dados. Em um banco de dados relacional, uma tabela de endereços pode fazer referência a uma tabela de países por ID, de modo que, se o nome de um país/região fosse alterado, os registros de endereço se beneficiariam da atualização sem precisar ser atualizados. No entanto, em um banco de dados NoSQL, o endereço e seu país associado podem ser serializados como parte de muitos objetos armazenados. Uma atualização para um nome de país/região exigiria que todos esses objetos fossem atualizados, em vez de uma única linha. Os bancos de dados relacionais também podem garantir a integridade relacional aplicando regras como chaves estrangeiras. Os bancos de dados NoSQL normalmente não oferecem tais restrições em seus dados.
Outra complexidade com a qual os bancos de dados NoSQL devem lidar é o controle de versão. Quando as propriedades de um objeto são alteradas, talvez não seja possível desserializá-lo de versões anteriores que foram armazenadas. Assim, todos os objetos existentes que têm uma versão serializada (anterior) do objeto devem ser atualizados para estar em conformidade com seu novo esquema. Essa abordagem não é conceitualmente diferente de um banco de dados relacional, onde as alterações de esquema às vezes exigem scripts de atualização ou atualizações de mapeamento. No entanto, o número de entradas que devem ser modificadas é muitas vezes muito maior na abordagem NoSQL, porque há mais duplicação de dados.
É possível em bancos de dados NoSQL armazenar várias versões de objetos, algo que os bancos de dados relacionais de esquema fixo normalmente não suportam. No entanto, nesse caso, o código do aplicativo precisará levar em conta a existência de versões anteriores de objetos, adicionando complexidade adicional.
Os bancos de dados NoSQL normalmente não impõem ACID, o que significa que eles têm benefícios de desempenho e escalabilidade em relação aos bancos de dados relacionais. Eles são adequados para conjuntos de dados extremamente grandes e objetos que não são adequados para armazenamento em estruturas de tabela normalizadas. Não há razão para que um único aplicativo não possa aproveitar os bancos de dados relacionais e NoSQL, usando cada um onde for mais adequado.
Azure Cosmos DB
O Azure Cosmos DB é um serviço de banco de dados NoSQL totalmente gerenciado que oferece armazenamento de dados sem esquema baseado em nuvem. O Azure Cosmos DB foi criado para desempenho rápido e previsível, alta disponibilidade, dimensionamento elástico e distribuição global. Apesar de ser um banco de dados NoSQL, os desenvolvedores podem usar recursos de consulta SQL avançados e familiares em dados JSON. Todos os recursos no Azure Cosmos DB são armazenados como documentos JSON. Os recursos são gerenciados como itens, que são documentos que contêm metadados, e feeds, que são coleções de itens. A Figura 8-2 mostra a relação entre diferentes recursos do Azure Cosmos DB.
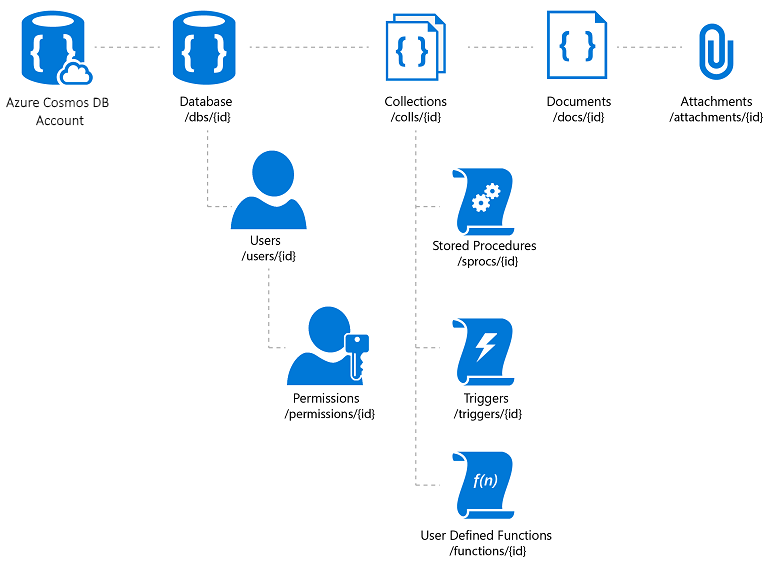
Figura 8-2. Organização de recursos do Azure Cosmos DB.
A linguagem de consulta do Azure Cosmos DB é uma interface simples, mas poderosa, para consultar documentos JSON. A linguagem suporta um subconjunto de gramática ANSI SQL e adiciona uma integração profunda do objeto JavaScript, matrizes, construção de objeto e invocação de função.
Referências – Azure Cosmos DB
- Introdução ao Azure Cosmos DB https://learn.microsoft.com/azure/cosmos-db/introduction
Outras opções de persistência
Além das opções de armazenamento relacional e NoSQL, os aplicativos ASP.NET Core podem usar o Armazenamento do Azure para armazenar vários formatos de dados e arquivos de forma escalável e baseada em nuvem. O Armazenamento do Azure é massivamente escalável, para que possa começar a armazenar pequenas quantidades de dados e escalar para armazenar centenas ou terabytes se a sua aplicação o exigir. O Armazenamento do Azure dá suporte a quatro tipos de dados:
Armazenamento de Blob para texto não estruturado ou armazenamento binário, também conhecido como armazenamento de objetos.
Armazenamento de tabelas para conjuntos de dados estruturados, acessível através de chaves de linha.
Armazenamento em fila para mensagens confiáveis baseadas em filas.
Armazenamento de arquivos para acesso a arquivos compartilhados entre máquinas virtuais do Azure e aplicativos locais.
Referências – Armazenamento do Azure
- Introdução ao Armazenamento do Azure https://learn.microsoft.com/azure/storage/common/storage-introduction
Colocação em cache
Em aplicações web, cada solicitação web deve ser concluída no menor tempo possível. Uma maneira de conseguir essa funcionalidade é limitar o número de chamadas externas que o servidor deve fazer para concluir a solicitação. O armazenamento em cache envolve o armazenamento de uma cópia dos dados no servidor (ou em outro armazenamento de dados que seja mais facilmente consultado do que a fonte dos dados). Os aplicativos Web, e especialmente os aplicativos Web tradicionais não SPA, precisam criar toda a interface do usuário com cada solicitação. Essa abordagem frequentemente envolve fazer muitas das mesmas consultas de banco de dados repetidamente de uma solicitação de usuário para outra. Na maioria dos casos, esses dados mudam raramente, portanto, há poucas razões para solicitá-los constantemente do banco de dados. O ASP.NET Core oferece suporte ao cache de resposta, para armazenar em cache páginas inteiras, e ao cache de dados, que oferece suporte a um comportamento de cache mais granular.
Ao implementar o cache, é importante ter em mente a separação de preocupações. Evite implementar a lógica de cache na lógica de acesso aos dados ou na interface do usuário. Em vez disso, encapsular o cache em suas próprias classes e usar a configuração para gerenciar seu comportamento. Essa abordagem segue os princípios de Responsabilidade Aberta/Fechada e Única e facilitará o gerenciamento de como você usa o cache em seu aplicativo à medida que ele cresce.
ASP.NET Cache de resposta principal
O ASP.NET Core suporta dois níveis de cache de resposta. O primeiro nível não armazena em cache nada no servidor, mas adiciona cabeçalhos HTTP que instruem clientes e servidores proxy a armazenar respostas em cache. Essa funcionalidade é implementada adicionando o atributo ResponseCache a controladores ou ações individuais:
[ResponseCache(Duration = 60)]
public IActionResult Contact()
{
ViewData["Message"] = "Your contact page.";
return View();
}
O exemplo anterior resultará na adição do cabeçalho a seguir à resposta, instruindo os clientes a armazenar o resultado em cache por até 60 segundos.
Cache-Control: public,max-age=60
Para adicionar cache na memória do lado do servidor ao aplicativo, você deve fazer referência ao Microsoft.AspNetCore.ResponseCaching pacote NuGet e, em seguida, adicionar o middleware de Cache de Resposta. Este middleware é configurado com serviços e middleware durante a inicialização do aplicativo:
builder.Services.AddResponseCaching();
// other code omitted, including building the app
app.UseResponseCaching();
O middleware de cache de resposta armazenará automaticamente em cache as respostas com base em um conjunto de condições, que você pode personalizar. Por padrão, apenas 200 respostas (OK) solicitadas por meio dos métodos GET ou HEAD são armazenadas em cache. Além disso, as solicitações devem ter uma resposta com um cabeçalho público Cache-Control: e não podem incluir cabeçalhos para Autorização ou Set-Cookie. Veja uma lista completa das condições de cache usadas pelo middleware de cache de resposta.
Colocação de dados em cache
Em vez de (ou além de) armazenar em cache respostas completas da Web, você pode armazenar em cache os resultados de consultas de dados individuais. Para essa funcionalidade, você pode usar o cache de memória no servidor Web ou usar um cache distribuído. Esta seção demonstrará como implementar no cache de memória.
Adicione suporte para cache de memória (ou distribuído) com o seguinte código:
builder.Services.AddMemoryCache();
builder.Services.AddMvc();
Certifique-se de adicionar o Microsoft.Extensions.Caching.Memory pacote NuGet também.
Depois de adicionar o serviço, você solicita IMemoryCache por injeção de dependência sempre que precisar acessar o cache. Neste exemplo, o CachedCatalogService está usando o padrão de design Proxy (ou Decorator), fornecendo uma implementação alternativa que ICatalogService controla o acesso (ou adiciona comportamento a) a implementação subjacente CatalogService .
public class CachedCatalogService : ICatalogService
{
private readonly IMemoryCache _cache;
private readonly CatalogService _catalogService;
private static readonly string _brandsKey = "brands";
private static readonly string _typesKey = "types";
private static readonly TimeSpan _defaultCacheDuration = TimeSpan.FromSeconds(30);
public CachedCatalogService(
IMemoryCache cache,
CatalogService catalogService)
{
_cache = cache;
_catalogService = catalogService;
}
public async Task<IEnumerable<SelectListItem>> GetBrands()
{
return await _cache.GetOrCreateAsync(_brandsKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetBrands();
});
}
public async Task<Catalog> GetCatalogItems(int pageIndex, int itemsPage, int? brandID, int? typeId)
{
string cacheKey = $"items-{pageIndex}-{itemsPage}-{brandID}-{typeId}";
return await _cache.GetOrCreateAsync(cacheKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetCatalogItems(pageIndex, itemsPage, brandID, typeId);
});
}
public async Task<IEnumerable<SelectListItem>> GetTypes()
{
return await _cache.GetOrCreateAsync(_typesKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetTypes();
});
}
}
Para configurar o aplicativo para usar a versão em cache do serviço, mas ainda permitir que o serviço obtenha a instância de CatalogService de que precisa em seu construtor, você adicionaria as seguintes linhas em Program.cs:
builder.Services.AddMemoryCache();
builder.Services.AddScoped<ICatalogService, CachedCatalogService>();
builder.Services.AddScoped<CatalogService>();
Com esse código em vigor, as chamadas do banco de dados para buscar os dados do catálogo serão feitas apenas uma vez por minuto, e não em todas as solicitações. Dependendo do tráfego para o site, isso pode ter um impacto significativo no número de consultas feitas ao banco de dados e no tempo médio de carregamento da página inicial que atualmente depende de todas as três consultas expostas por esse serviço.
Um problema que surge quando o cache é implementado são dados obsoletos – ou seja, dados que foram alterados na origem, mas uma versão desatualizada permanece no cache. Uma maneira simples de mitigar esse problema é usar durações de cache pequenas, já que para um aplicativo ocupado há um benefício adicional limitado em estender o comprimento em que os dados são armazenados em cache. Por exemplo, considere uma página que faz uma única consulta de banco de dados e é solicitada 10 vezes por segundo. Se essa página for armazenada em cache por um minuto, o número de consultas de banco de dados feitas por minuto cairá de 600 para 1, uma redução de 99,8%. Se, em vez disso, a duração do cache fosse feita uma hora, a redução geral seria de 99,997%, mas agora a probabilidade e a idade potencial dos dados obsoletos aumentaram drasticamente.
Outra abordagem é remover proativamente as entradas de cache quando os dados que elas contêm são atualizados. Qualquer entrada individual pode ser removida se a sua chave for conhecida:
_cache.Remove(cacheKey);
Se o seu aplicativo expõe a funcionalidade para atualizar as entradas que ele armazena em cache, você pode remover as entradas de cache correspondentes no código que executa as atualizações. Às vezes, pode haver muitas entradas diferentes que dependem de um determinado conjunto de dados. Nesse caso, pode ser útil criar dependências entre entradas de cache, usando um CancellationChangeToken. Com um CancellationChangeToken, você pode expirar várias entradas de cache de uma só vez cancelando o token.
// configure CancellationToken and add entry to cache
var cts = new CancellationTokenSource();
_cache.Set("cts", cts);
_cache.Set(cacheKey, itemToCache, new CancellationChangeToken(cts.Token));
// elsewhere, expire the cache by cancelling the token\
_cache.Get<CancellationTokenSource>("cts").Cancel();
O cache pode melhorar drasticamente o desempenho de páginas da Web que solicitam repetidamente os mesmos valores do banco de dados. Certifique-se de medir o acesso aos dados e o desempenho da página antes de aplicar o cache e só aplique o cache quando achar necessário melhorá-lo. O cache consome recursos de memória do servidor Web e aumenta a complexidade do aplicativo, por isso é importante que você não otimize prematuramente usando essa técnica.
Como obter dados para BlazorWebAssembly aplicativos
Se você estiver criando aplicativos que usam Blazor o Servidor, poderá usar o Entity Framework e outras tecnologias de acesso direto a dados, conforme discutido até agora neste capítulo. No entanto, ao criar BlazorWebAssembly aplicativos, como outras estruturas de SPA, você precisará de uma estratégia diferente para o acesso aos dados. Normalmente, esses aplicativos acessam dados e interagem com o servidor por meio de pontos de extremidade de API da Web.
Se os dados ou operações que estão sendo executados forem confidenciais, revise a seção sobre segurança no capítulo anterior e proteja suas APIs contra acesso não autorizado.
Você encontrará um exemplo de um BlazorWebAssembly aplicativo no aplicativo de referência eShopOnWeb, no projeto BlazorAdmin. Este projeto está hospedado no projeto Web eShopOnWeb e permite que os usuários do grupo Administradores gerenciem os itens na loja. Você pode ver uma captura de tela do aplicativo na Figura 8-3.
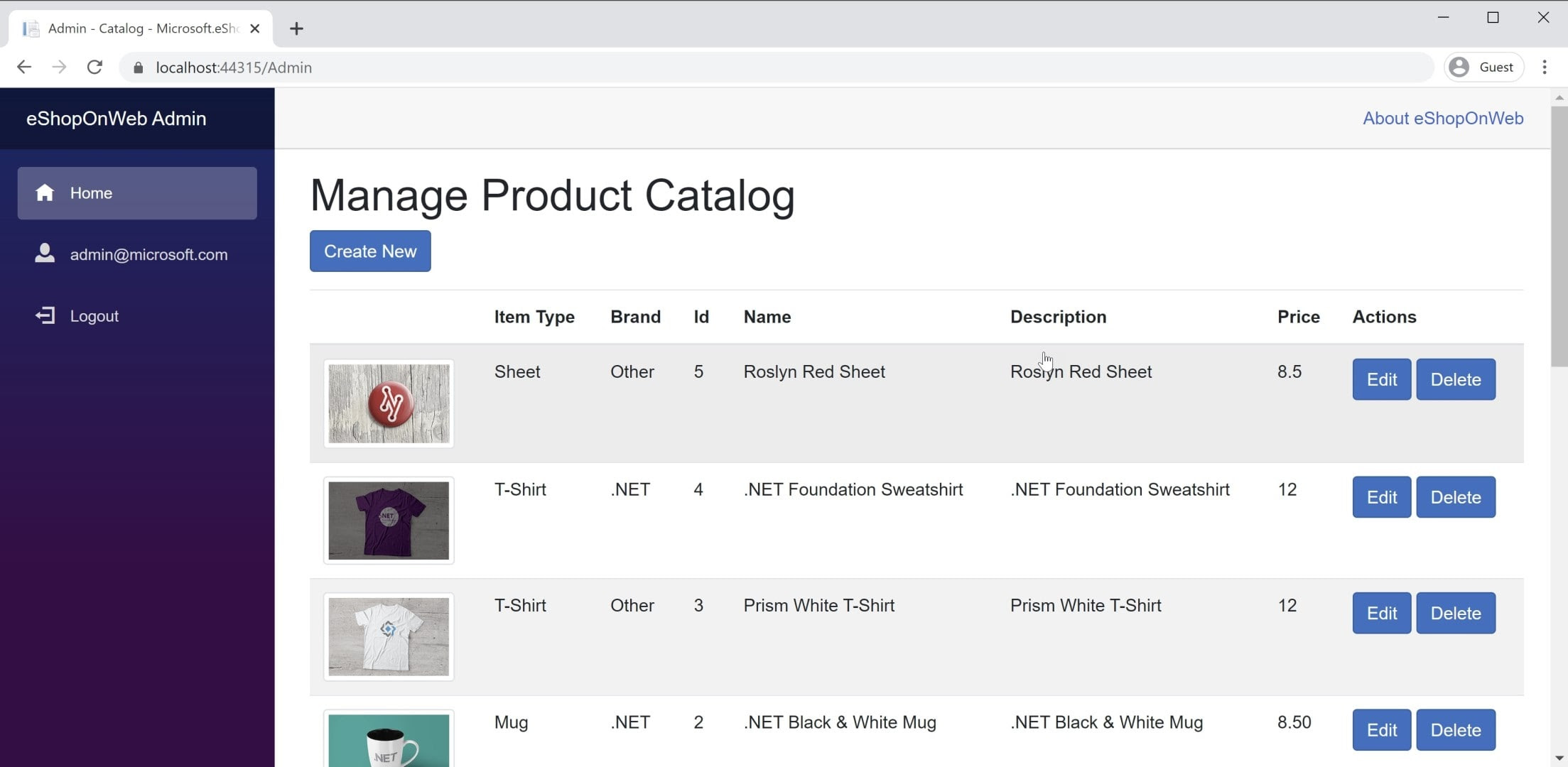
Figura 8-3. Captura de tela do administrador do catálogo eShopOnWeb.
Ao buscar dados de APIs da Web em um BlazorWebAssembly aplicativo, basta usar uma instância de HttpClient como faria em qualquer aplicativo .NET. As etapas básicas envolvidas são criar a solicitação para enviar (se necessário, geralmente para solicitações POST ou PUT), aguardar a solicitação em si, verificar o código de status e desserializar a resposta. Se você vai fazer muitas solicitações para um determinado conjunto de APIs, é uma boa ideia encapsular suas APIs e configurar o HttpClient endereço base centralmente. Dessa forma, se você precisar ajustar qualquer uma dessas configurações entre ambientes, poderá fazer as alterações em apenas um lugar. Você deve adicionar suporte para este serviço em seu Program.Main:
builder.Services.AddScoped(sp => new HttpClient
{
BaseAddress = new Uri(builder.HostEnvironment.BaseAddress)
});
Se você precisar acessar os serviços com segurança, deverá acessar um token seguro e configurar o HttpClient para passar esse token como um cabeçalho de Autenticação a cada solicitação:
_httpClient.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", token);
Essa atividade pode ser feita a partir de qualquer componente que tenha o injetado HttpClient nele, desde que HttpClient não tenha sido adicionado aos serviços do aplicativo com uma Transient vida útil. Cada referência a HttpClient no aplicativo faz referência à mesma instância, portanto, as alterações nela em um componente fluem através de todo o aplicativo. Um bom lugar para executar essa verificação de autenticação (seguida da especificação do token) é em um componente compartilhado, como a navegação principal do site. Saiba mais sobre essa abordagem no BlazorAdmin projeto no aplicativo de referência eShopOnWeb.
Um benefício dos BlazorWebAssembly SPAs JavaScript tradicionais é que você não precisa manter cópias de seus objetos de transferência de dados (DTOs) sincronizadas. Seu BlazorWebAssembly projeto e seu projeto de API da Web podem compartilhar os mesmos DTOs em um projeto compartilhado comum. Esta abordagem elimina alguns dos atritos envolvidos no desenvolvimento de ZPE.
Para obter dados rapidamente de um ponto de extremidade de API, você pode usar o método auxiliar interno, GetFromJsonAsync. Existem métodos semelhantes para POST, PUT, etc. A seguir mostra como obter um CatalogItem de um ponto de extremidade de API usando um configurado HttpClient em um BlazorWebAssembly aplicativo:
var item = await _httpClient.GetFromJsonAsync<CatalogItem>($"catalog-items/{id}");
Depois de ter os dados de que precisa, normalmente controlará as alterações localmente. Quando quiser fazer atualizações no armazenamento de dados de back-end, você chamará APIs da Web adicionais para essa finalidade.
Referências – Blazor Dados
- Chamar uma API da Web do ASP.NET Core Blazorhttps://learn.microsoft.com/aspnet/core/blazor/call-web-api