Subscrever eventos
Gorjeta
Este conteúdo é um trecho do eBook, .NET Microservices Architecture for Containerized .NET Applications, disponível no .NET Docs ou como um PDF para download gratuito que pode ser lido offline.

O primeiro passo para usar o barramento de eventos é inscrever os microsserviços nos eventos que desejam receber. Essa funcionalidade deve ser feita nos microsserviços do recetor.
O código simples a seguir mostra o que cada microsserviço recetor precisa implementar ao iniciar o serviço (ou seja, na classe) para que ele se inscreva nos Startup eventos de que precisa. Nesse caso, o basket-api microsserviço precisa se inscrever ProductPriceChangedIntegrationEvent e as OrderStartedIntegrationEvent mensagens.
Por exemplo, ao subscrever o ProductPriceChangedIntegrationEvent evento, isso torna o microsserviço do cesto de compras ciente de quaisquer alterações no preço do produto e permite avisar o utilizador sobre a alteração se esse produto estiver no cesto do utilizador.
var eventBus = app.ApplicationServices.GetRequiredService<IEventBus>();
eventBus.Subscribe<ProductPriceChangedIntegrationEvent,
ProductPriceChangedIntegrationEventHandler>();
eventBus.Subscribe<OrderStartedIntegrationEvent,
OrderStartedIntegrationEventHandler>();
Depois que esse código for executado, o microsserviço do assinante estará ouvindo através dos canais RabbitMQ. Quando qualquer mensagem do tipo ProductPriceChangedIntegrationEvent chega, o código invoca o manipulador de eventos que é passado para ele e processa o evento.
Publicação de eventos através do barramento de eventos
Finalmente, o remetente da mensagem (microsserviço de origem) publica os eventos de integração com código semelhante ao exemplo a seguir. (Esta abordagem é um exemplo simplificado que não leva em conta a atomicidade.) Você implementaria um código semelhante sempre que um evento precisasse ser propagado por vários microsserviços, geralmente logo após confirmar dados ou transações do microsserviço de origem.
Primeiro, o objeto de implementação do barramento de eventos (baseado em RabbitMQ ou baseado em um barramento de serviço) seria injetado no construtor do controlador, como no código a seguir:
[Route("api/v1/[controller]")]
public class CatalogController : ControllerBase
{
private readonly CatalogContext _context;
private readonly IOptionsSnapshot<Settings> _settings;
private readonly IEventBus _eventBus;
public CatalogController(CatalogContext context,
IOptionsSnapshot<Settings> settings,
IEventBus eventBus)
{
_context = context;
_settings = settings;
_eventBus = eventBus;
}
// ...
}
Em seguida, você usá-lo a partir dos métodos do controlador, como no método UpdateProduct:
[Route("items")]
[HttpPost]
public async Task<IActionResult> UpdateProduct([FromBody]CatalogItem product)
{
var item = await _context.CatalogItems.SingleOrDefaultAsync(
i => i.Id == product.Id);
// ...
if (item.Price != product.Price)
{
var oldPrice = item.Price;
item.Price = product.Price;
_context.CatalogItems.Update(item);
var @event = new ProductPriceChangedIntegrationEvent(item.Id,
item.Price,
oldPrice);
// Commit changes in original transaction
await _context.SaveChangesAsync();
// Publish integration event to the event bus
// (RabbitMQ or a service bus underneath)
_eventBus.Publish(@event);
// ...
}
// ...
}
Nesse caso, como o microsserviço de origem é um microsserviço CRUD simples, esse código é colocado diretamente em um controlador de API da Web.
Em microsserviços mais avançados, como ao usar abordagens CQRS, ele pode ser implementado na CommandHandler classe, dentro do Handle() método.
Projetando atomicidade e resiliência ao publicar no barramento do evento
Quando você publica eventos de integração por meio de um sistema de mensagens distribuído, como o barramento de eventos, você tem o problema de atualizar atomicamente o banco de dados original e publicar um evento (ou seja, ambas as operações são concluídas ou nenhuma delas). Por exemplo, no exemplo simplificado mostrado anteriormente, o código confirma dados no banco de dados quando o preço do produto é alterado e, em seguida, publica uma mensagem ProductPriceChangedIntegrationEvent. Inicialmente, pode parecer essencial que essas duas operações sejam realizadas atomicamente. No entanto, se você estiver usando uma transação distribuída envolvendo o banco de dados e o agente de mensagens, como faz em sistemas mais antigos, como o Microsoft Message Queuing (MSMQ), essa abordagem não é recomendada pelas razões descritas pelo teorema CAP.
Basicamente, você usa microsserviços para criar sistemas escaláveis e altamente disponíveis. Simplificando um pouco, o teorema CAP diz que você não pode construir um banco de dados (distribuído) (ou um microsserviço que possui seu modelo) que esteja continuamente disponível, fortemente consistente e tolerante a qualquer partição. Você deve escolher duas dessas três propriedades.
Em arquiteturas baseadas em microsserviços, você deve escolher disponibilidade e tolerância, e deve desenfatizar a consistência forte. Portanto, na maioria dos aplicativos modernos baseados em microsserviços, você geralmente não deseja usar transações distribuídas em mensagens, como faz quando implementa transações distribuídas com base no DTC (Coordenador de Transações Distribuídas) do Windows com MSMQ.
Voltemos à questão inicial e ao seu exemplo. Se o serviço falhar depois que o banco de dados for atualizado (neste caso, logo após a linha de código com _context.SaveChangesAsync()), mas antes que o evento de integração seja publicado, o sistema geral poderá se tornar inconsistente. Essa abordagem pode ser crítica para os negócios, dependendo da operação de negócios específica com a qual você está lidando.
Como mencionado anteriormente na seção de arquitetura, você pode ter várias abordagens para lidar com esse problema:
Usando o padrão completo de Event Sourcing.
Usando a mineração de log de transações.
Usando o padrão Caixa de saída. Esta é uma tabela transacional para armazenar os eventos de integração (estendendo a transação local).
Para esse cenário, usar o padrão completo de Event Sourcing (ES) é uma das melhores abordagens, se não a melhor. No entanto, em muitos cenários de aplicativos, talvez não seja possível implementar um sistema ES completo. ES significa armazenar apenas eventos de domínio em seu banco de dados transacional, em vez de armazenar dados de estado atual. Armazenar apenas eventos de domínio pode ter grandes benefícios, como ter o histórico do seu sistema disponível e ser capaz de determinar o estado do seu sistema a qualquer momento no passado. No entanto, a implementação de um sistema ES completo requer que você rearquitete a maior parte do seu sistema e introduz muitas outras complexidades e requisitos. Por exemplo, convém usar um banco de dados criado especificamente para o fornecimento de eventos, como o Repositório de Eventos, ou um banco de dados orientado a documentos, como o Azure Cosmos DB, MongoDB, Cassandra, CouchDB ou RavenDB. ES é uma ótima abordagem para esse problema, mas não a solução mais fácil, a menos que você já esteja familiarizado com o fornecimento de eventos.
A opção de usar a mineração de log de transações inicialmente parece transparente. No entanto, para usar essa abordagem, o microsserviço deve ser acoplado ao log de transações RDBMS, como o log de transações do SQL Server. Esta abordagem provavelmente não é desejável. Outra desvantagem é que as atualizações de baixo nível registradas no log de transações podem não estar no mesmo nível dos eventos de integração de alto nível. Nesse caso, o processo de engenharia reversa dessas operações de log de transações pode ser difícil.
Uma abordagem equilibrada é uma combinação de uma tabela de banco de dados transacional e um padrão ES simplificado. Você pode usar um estado como "pronto para publicar o evento", que você define no evento original ao confirmá-lo na tabela de eventos de integração. Em seguida, tente publicar o evento no barramento do evento. Se a ação publish-event for bem-sucedida, inicie outra transação no serviço de origem e mova o estado de "pronto para publicar o evento" para "evento já publicado".
Se a ação publish-event no barramento de eventos falhar, os dados ainda não serão inconsistentes dentro do microsserviço de origem — eles ainda estão marcados como "pronto para publicar o evento" e, com relação ao restante dos serviços, acabarão sendo consistentes. Você sempre pode ter trabalhos em segundo plano verificando o estado das transações ou eventos de integração. Se o trabalho encontrar um evento no estado "pronto para publicar o evento", ele poderá tentar republicá-lo no barramento do evento.
Observe que, com essa abordagem, você está persistindo apenas os eventos de integração para cada microsserviço de origem e somente os eventos que deseja comunicar a outros microsserviços ou sistemas externos. Em contraste, em um sistema ES completo, você armazena todos os eventos de domínio também.
Por conseguinte, esta abordagem equilibrada é um sistema simplificado de ES. Você precisa de uma lista de eventos de integração com seu estado atual ("pronto para publicar" versus "publicado"). Mas você só precisa implementar esses estados para os eventos de integração. E nessa abordagem, você não precisa armazenar todos os seus dados de domínio como eventos no banco de dados transacional, como faria em um sistema ES completo.
Se você já estiver usando um banco de dados relacional, poderá usar uma tabela transacional para armazenar eventos de integração. Para obter atomicidade em seu aplicativo, use um processo de duas etapas com base em transações locais. Basicamente, você tem uma tabela IntegrationEvent no mesmo banco de dados onde você tem suas entidades de domínio. Essa tabela funciona como um seguro para alcançar a atomicidade para que você inclua eventos de integração persistentes nas mesmas transações que estão comprometendo seus dados de domínio.
Passo a passo, o processo é assim:
O aplicativo inicia uma transação de banco de dados local.
Em seguida, atualiza o estado das entidades de domínio e insere um evento na tabela de eventos de integração.
Finalmente, ele confirma a transação, para que você obtenha a atomicidade desejada e, em seguida,
Você publica o evento de alguma forma (próximo).
Ao implementar as etapas de publicação dos eventos, você tem estas opções:
Publique o evento de integração logo após confirmar a transação e use outra transação local para marcar os eventos na tabela como sendo publicados. Em seguida, use a tabela apenas como um artefato para rastrear os eventos de integração em caso de problemas nos microsserviços remotos e execute ações compensatórias com base nos eventos de integração armazenados.
Use a tabela como uma espécie de fila. Um thread de aplicativo ou processo separado consulta a tabela de eventos de integração, publica os eventos no barramento de eventos e usa uma transação local para marcar os eventos como publicados.
A Figura 6-22 mostra a arquitetura para a primeira dessas abordagens.
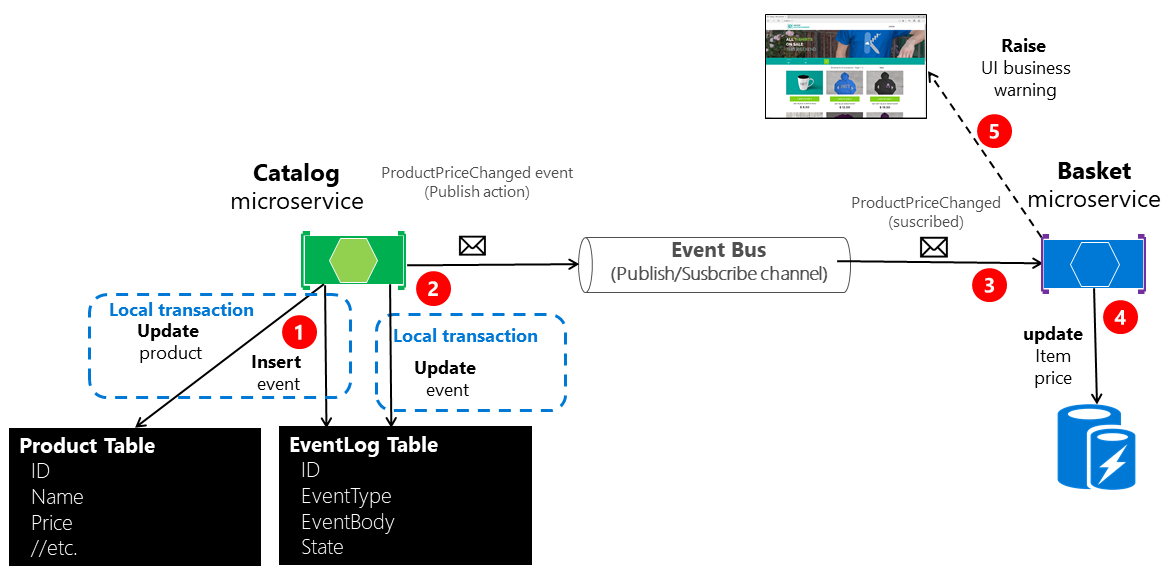
Figura 6-22. Atomicidade ao publicar eventos no ônibus do evento
A abordagem ilustrada na Figura 6-22 está faltando um microsserviço de trabalhador adicional encarregado de verificar e confirmar o sucesso dos eventos de integração publicados. Em caso de falha, esse microsserviço de verificador adicional pode ler eventos da tabela e republicá-los, ou seja, repetir a etapa número 2.
Sobre a segunda abordagem: você usa a tabela EventLog como uma fila e sempre usa um microsserviço de trabalho para publicar as mensagens. Nesse caso, o processo é como o mostrado na Figura 6-23. Isso mostra um microsserviço adicional e a tabela é a única fonte ao publicar eventos.
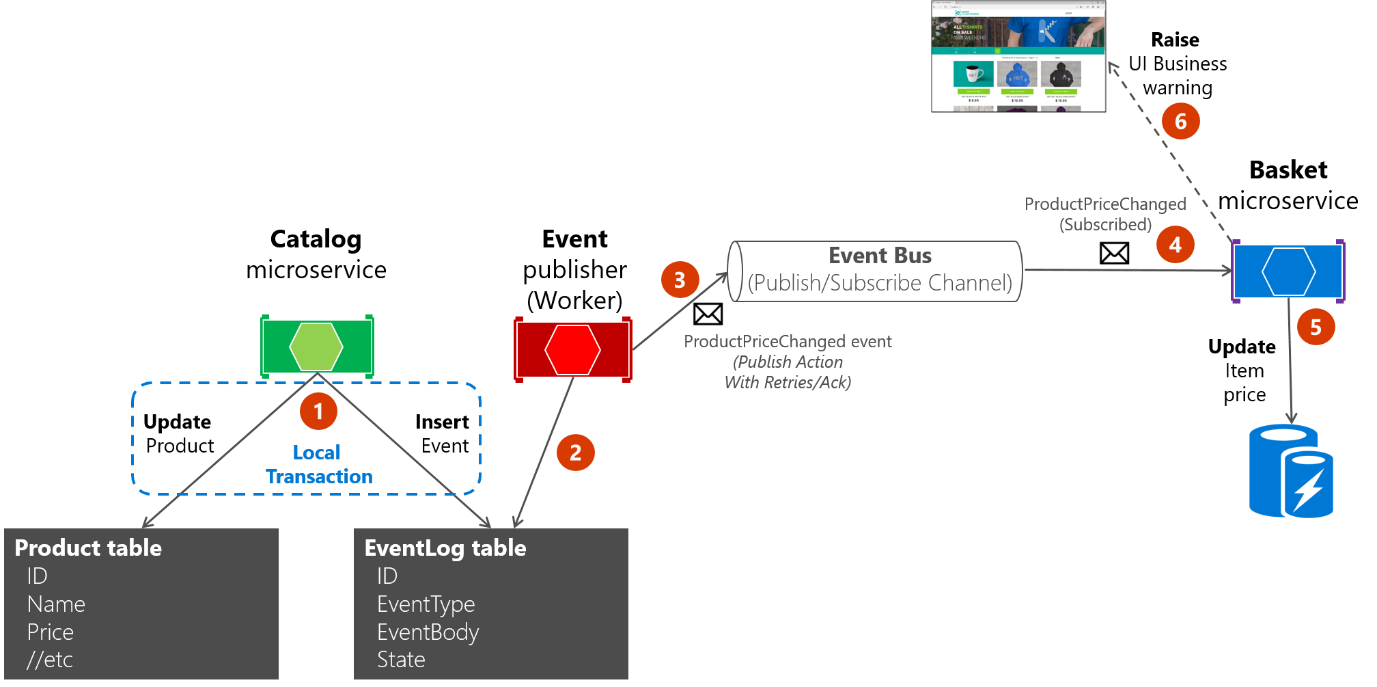
Figura 6-23. Atomicidade ao publicar eventos no ônibus de eventos com um microsserviço de trabalhador
Para simplificar, o exemplo eShopOnContainers usa a primeira abordagem (sem processos adicionais ou microsserviços de verificação) mais o barramento de eventos. No entanto, o exemplo eShopOnContainers não está lidando com todos os possíveis casos de falha. Em um aplicativo real implantado na nuvem, você deve abraçar o fato de que os problemas surgirão eventualmente, e você deve implementar essa lógica de verificação e reenvio. Usar a tabela como uma fila pode ser mais eficaz do que a primeira abordagem se você tiver essa tabela como uma única fonte de eventos ao publicá-los (com o trabalhador) através do barramento de eventos.
Implementando atomicidade ao publicar eventos de integração através do barramento de eventos
O código a seguir mostra como você pode criar uma única transação envolvendo vários objetos DbContext — um contexto relacionado aos dados originais que estão sendo atualizados e o segundo contexto relacionado à tabela IntegrationEventLog.
A transação no código de exemplo abaixo não será resiliente se as conexões com o banco de dados tiverem qualquer problema no momento em que o código estiver em execução. Isso pode acontecer em sistemas baseados em nuvem, como o Banco de Dados SQL do Azure, que pode mover bancos de dados entre servidores. Para implementar transações resilientes em vários contextos, consulte a seção Implementando conexões SQL principais resilientes do Entity Framework mais adiante neste guia.
Para maior clareza, o exemplo a seguir mostra todo o processo em um único pedaço de código. No entanto, a implementação do eShopOnContainers é refatorada e divide essa lógica em várias classes para que seja mais fácil de manter.
// Update Product from the Catalog microservice
//
public async Task<IActionResult> UpdateProduct([FromBody]CatalogItem productToUpdate)
{
var catalogItem =
await _catalogContext.CatalogItems.SingleOrDefaultAsync(i => i.Id ==
productToUpdate.Id);
if (catalogItem == null) return NotFound();
bool raiseProductPriceChangedEvent = false;
IntegrationEvent priceChangedEvent = null;
if (catalogItem.Price != productToUpdate.Price)
raiseProductPriceChangedEvent = true;
if (raiseProductPriceChangedEvent) // Create event if price has changed
{
var oldPrice = catalogItem.Price;
priceChangedEvent = new ProductPriceChangedIntegrationEvent(catalogItem.Id,
productToUpdate.Price,
oldPrice);
}
// Update current product
catalogItem = productToUpdate;
// Just save the updated product if the Product's Price hasn't changed.
if (!raiseProductPriceChangedEvent)
{
await _catalogContext.SaveChangesAsync();
}
else // Publish to event bus only if product price changed
{
// Achieving atomicity between original DB and the IntegrationEventLog
// with a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
// Publish the integration event through the event bus
_eventBus.Publish(priceChangedEvent);
_integrationEventLogService.MarkEventAsPublishedAsync(
priceChangedEvent);
}
return Ok();
}
Depois que o evento de integração ProductPriceChangedIntegrationEvent é criado, a transação que armazena a operação de domínio original (atualizar o item de catálogo) também inclui a persistência do evento na tabela EventLog. Isso faz com que seja uma única transação, e você sempre poderá verificar se as mensagens de evento foram enviadas.
A tabela de log de eventos é atualizada atomicamente com a operação de banco de dados original, usando uma transação local no mesmo banco de dados. Se qualquer uma das operações falhar, uma exceção será lançada e a transação reverterá qualquer operação concluída, mantendo assim a consistência entre as operações de domínio e as mensagens de evento salvas na tabela.
Recebendo mensagens de assinaturas: manipuladores de eventos em microsserviços de recetor
Além da lógica de assinatura de eventos, você precisa implementar o código interno para os manipuladores de eventos de integração (como um método de retorno de chamada). O manipulador de eventos é onde você especifica onde as mensagens de evento de um determinado tipo serão recebidas e processadas.
Um manipulador de eventos recebe primeiro uma instância de evento do barramento de eventos. Em seguida, ele localiza o componente a ser processado relacionado a esse evento de integração, propagando e persistindo o evento como uma mudança de estado no microsserviço do recetor. Por exemplo, se um evento ProductPriceChanged se originar no microsserviço de catálogo, ele será manipulado no microsserviço da cesta e também alterará o estado nesse microsserviço da cesta do recetor, conforme mostrado no código a seguir.
namespace Microsoft.eShopOnContainers.Services.Basket.API.IntegrationEvents.EventHandling
{
public class ProductPriceChangedIntegrationEventHandler :
IIntegrationEventHandler<ProductPriceChangedIntegrationEvent>
{
private readonly IBasketRepository _repository;
public ProductPriceChangedIntegrationEventHandler(
IBasketRepository repository)
{
_repository = repository;
}
public async Task Handle(ProductPriceChangedIntegrationEvent @event)
{
var userIds = await _repository.GetUsers();
foreach (var id in userIds)
{
var basket = await _repository.GetBasket(id);
await UpdatePriceInBasketItems(@event.ProductId, @event.NewPrice, basket);
}
}
private async Task UpdatePriceInBasketItems(int productId, decimal newPrice,
CustomerBasket basket)
{
var itemsToUpdate = basket?.Items?.Where(x => int.Parse(x.ProductId) ==
productId).ToList();
if (itemsToUpdate != null)
{
foreach (var item in itemsToUpdate)
{
if(item.UnitPrice != newPrice)
{
var originalPrice = item.UnitPrice;
item.UnitPrice = newPrice;
item.OldUnitPrice = originalPrice;
}
}
await _repository.UpdateBasket(basket);
}
}
}
}
O manipulador de eventos precisa verificar se o produto existe em alguma das instâncias da cesta. Ele também atualiza o preço do item para cada item de linha de cesta relacionado. Finalmente, ele cria um alerta a ser exibido ao usuário sobre a alteração de preço, como mostra a Figura 6-24.
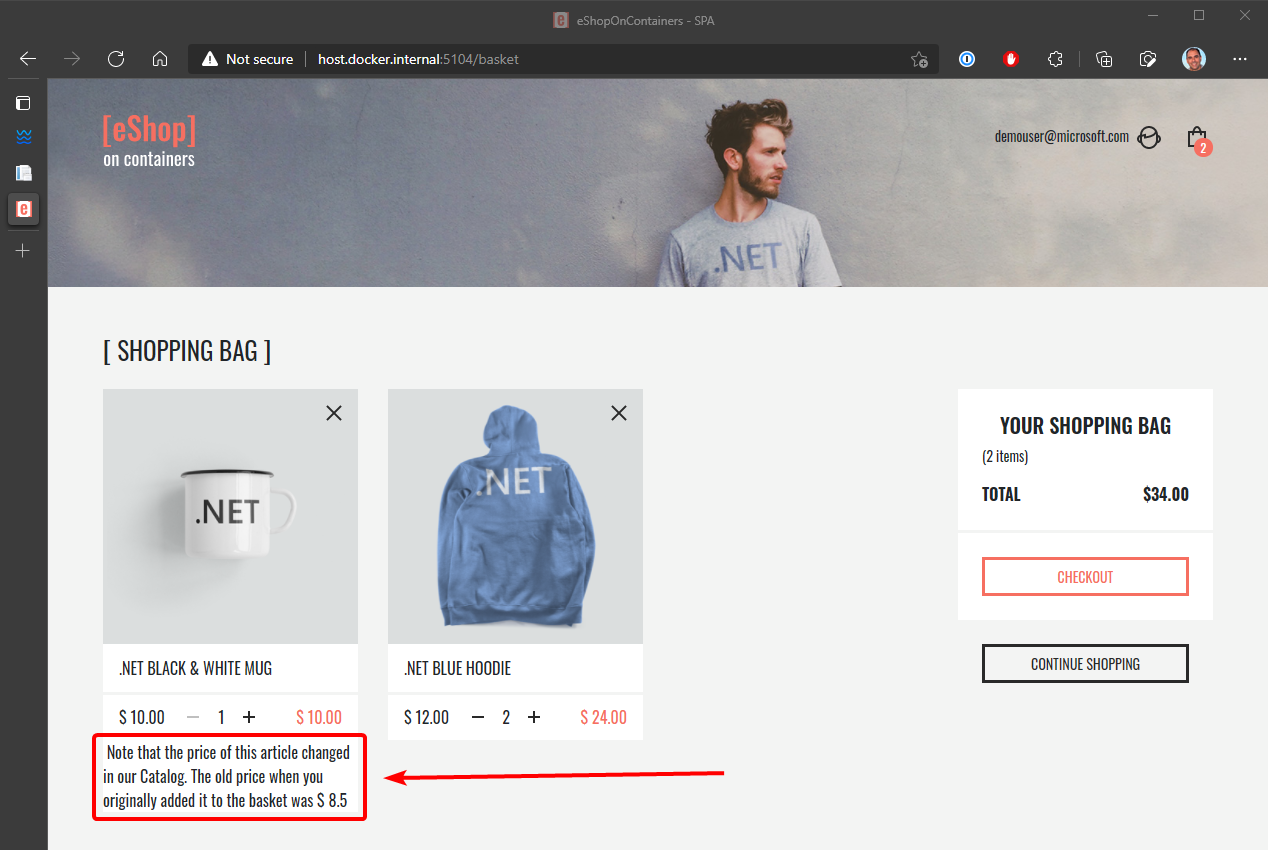
Figura 6-24. Exibição de uma alteração de preço de item em uma cesta, conforme comunicado por eventos de integração
Idempotência em eventos de mensagem de atualização
Um aspeto importante dos eventos de mensagem de atualização é que uma falha em qualquer ponto da comunicação deve fazer com que a mensagem seja repetida. Caso contrário, uma tarefa em segundo plano pode tentar publicar um evento que já foi publicado, criando uma condição de corrida. Certifique-se de que as atualizações são idempotentes ou que fornecem informações suficientes para garantir que você possa detetar uma duplicata, descartá-la e enviar de volta apenas uma resposta.
Como observado anteriormente, idempotência significa que uma operação pode ser executada várias vezes sem alterar o resultado. Em um ambiente de mensagens, como ao comunicar eventos, um evento é idempotente se puder ser entregue várias vezes sem alterar o resultado para o microsserviço recetor. Isso pode ser necessário devido à natureza do evento em si ou devido à maneira como o sistema lida com o evento. A idempotência de mensagens é importante em qualquer aplicativo que usa mensagens, não apenas em aplicativos que implementam o padrão de barramento de eventos.
Um exemplo de uma operação idempotente é uma instrução SQL que insere dados em uma tabela somente se esses dados ainda não estiverem na tabela. Não importa quantas vezes você executa essa instrução insert SQL; O resultado será o mesmo — a tabela conterá esses dados. Idempotência como esta também pode ser necessária ao lidar com mensagens se as mensagens poderiam ser potencialmente enviadas e, portanto, processadas mais de uma vez. Por exemplo, se a lógica de repetição fizer com que um remetente envie exatamente a mesma mensagem mais de uma vez, você precisa ter certeza de que ela é idempotente.
É possível projetar mensagens idempotentes. Por exemplo, você pode criar um evento que diga "defina o preço do produto para US$ 25" em vez de "adicione US$ 5 ao preço do produto". Você pode processar com segurança a primeira mensagem qualquer número de vezes e o resultado será o mesmo. Isso não é verdade para a segunda mensagem. Mas mesmo no primeiro caso, você pode não querer processar o primeiro evento, porque o sistema também poderia ter enviado um evento de alteração de preço mais recente e você estaria substituindo o novo preço.
Outro exemplo pode ser um evento de pedido concluído que é propagado para vários assinantes. O aplicativo deve garantir que as informações do pedido sejam atualizadas em outros sistemas apenas uma vez, mesmo que haja eventos de mensagem duplicados para o mesmo evento de pedido concluído.
É conveniente ter algum tipo de identidade por evento para que você possa criar uma lógica que imponha que cada evento seja processado apenas uma vez por recetor.
Alguns processamentos de mensagens são inerentemente idempotentes. Por exemplo, se um sistema gera miniaturas de imagem, pode não importar quantas vezes a mensagem sobre a miniatura gerada é processada; O resultado é que as miniaturas são geradas e são sempre as mesmas. Por outro lado, operações como ligar para um gateway de pagamento para cobrar um cartão de crédito podem não ser idempotentes. Nesses casos, você precisa garantir que o processamento de uma mensagem várias vezes tenha o efeito esperado.
Recursos adicionais
- Honrando a idempotência da mensagem
https://learn.microsoft.com/previous-versions/msp-n-p/jj591565(v=pandp.10)#honoring-message-idempotency
Desduplicação de mensagens de eventos de integração
Você pode garantir que os eventos de mensagem sejam enviados e processados apenas uma vez por assinante em diferentes níveis. Uma maneira é usar um recurso de desduplicação oferecido pela infraestrutura de mensagens que você está usando. Outra é implementar lógica personalizada no seu microsserviço de destino. Ter validações tanto ao nível do transporte como ao nível da aplicação é a sua melhor aposta.
Desduplicação de eventos de mensagem no nível EventHandler
Uma maneira de garantir que um evento seja processado apenas uma vez por qualquer recetor é implementando determinada lógica ao processar os eventos de mensagem em manipuladores de eventos. Por exemplo, essa é a abordagem usada no aplicativo eShopOnContainers, como você pode ver no código-fonte da classe UserCheckoutAcceptedIntegrationEventHandler quando ela recebe um UserCheckoutAcceptedIntegrationEvent evento de integração. (Neste caso, o CreateOrderCommand é encapsulado com um IdentifiedCommand, usando o eventMsg.RequestId como um identificador, antes de enviá-lo para o manipulador de comandos).
Desduplicação de mensagens ao usar RabbitMQ
Quando ocorrem falhas de rede intermitentes, as mensagens podem ser duplicadas e o recetor da mensagem deve estar pronto para lidar com essas mensagens duplicadas. Se possível, os recetores devem lidar com as mensagens de forma idempotente, o que é melhor do que tratá-las explicitamente com desduplicação.
De acordo com a documentação do RabbitMQ, "Se uma mensagem for entregue a um consumidor e, em seguida, colocada novamente na fila (porque não foi reconhecida antes da conexão do consumidor cair, por exemplo), o RabbitMQ definirá o sinalizador reentregue nela quando for entregue novamente (seja para o mesmo consumidor ou para um diferente).
Se o sinalizador "reentregue" estiver definido, o recetor deve levar isso em consideração, porque a mensagem pode já ter sido processada. Mas isso não é garantido; A mensagem pode nunca ter chegado ao recetor depois que deixou o agente de mensagens, talvez por causa de problemas de rede. Por outro lado, se o sinalizador "reentregue" não estiver definido, é garantido que a mensagem não foi enviada mais de uma vez. Portanto, o recetor precisa desduplicar mensagens ou processar mensagens de forma idempotente somente se o sinalizador "reentregue" estiver definido na mensagem.
Recursos adicionais
Forked eShopOnContainers usando NServiceBus (Software particular)
https://go.particular.net/eShopOnContainersMensagens orientadas a eventos
https://patterns.arcitura.com/soa-patterns/design_patterns/event_driven_messagingJimmy Bogard. Refactoring Towards Resilience: Assessing Coupling
https://jimmybogard.com/refactoring-towards-resilience-evaluating-coupling/Publicar-Subscrever canal
https://www.enterpriseintegrationpatterns.com/patterns/messaging/PublishSubscribeChannel.htmlComunicação entre contextos limitados
https://learn.microsoft.com/previous-versions/msp-n-p/jj591572(v=pandp.10)Eventual consistência
https://en.wikipedia.org/wiki/Eventual_consistencyFilipe Castanho. Estratégias para integrar contextos delimitados
https://www.culttt.com/2014/11/26/strategies-integrating-bounded-contexts/Chris Richardson. Desenvolvendo microsserviços transacionais usando agregados, fornecimento de eventos e CQRS - Parte 2
https://www.infoq.com/articles/microservices-aggregates-events-cqrs-part-2-richardsonChris Richardson. Padrão de Origem do Evento
https://microservices.io/patterns/data/event-sourcing.htmlApresentando o Event Sourcing
https://learn.microsoft.com/previous-versions/msp-n-p/jj591559(v=pandp.10)Banco de dados do Repositório de Eventos. Site oficial.
https://geteventstore.com/Patrick Nommensen. Gerenciamento de dados orientado a eventos para microsserviços
https://dzone.com/articles/event-driven-data-management-for-microservices-1O teorema da PAC
https://en.wikipedia.org/wiki/CAP_theoremO que é o Teorema da PAC?
https://www.quora.com/What-Is-CAP-Theorem-1Manual Básico de Consistência de Dados
https://learn.microsoft.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Rick Saling. O teorema da PAC: Por que "tudo é diferente" com a nuvem e a Internet
https://learn.microsoft.com/archive/blogs/rickatmicrosoft/the-cap-theorem-why-everything-is-different-with-the-cloud-and-internet/Eric Brewer. A PAC doze anos depois: como as "regras" mudaram
https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changedCAP, PACELC e Microsserviços
https://ardalis.com/cap-pacelc-and-microservices/Barramento de Serviço do Azure. Mensagens intermediadas: deteção de duplicados
https://github.com/microsoftarchive/msdn-code-gallery-microsoft/tree/master/Windows%20Azure%20Product%20Team/Brokered%20Messaging%20Duplicate%20DetectionGuia de confiabilidade (documentação do RabbitMQ)
https://www.rabbitmq.com/reliability.html#consumer