Gerenciar estado e dados em aplicativos Docker
Gorjeta
Este conteúdo é um trecho do eBook, .NET Microservices Architecture for Containerized .NET Applications, disponível no .NET Docs ou como um PDF para download gratuito que pode ser lido offline.

Na maioria dos casos, você pode pensar em um contêiner como uma instância de um processo. Um processo não mantém o estado persistente. Embora um contêiner possa gravar em seu armazenamento local, assumir que uma instância estará indefinidamente seria como assumir que um único local na memória será durável. Você deve assumir que as imagens de contêiner, como processos, têm várias instâncias ou serão eventualmente mortas. Se eles forem gerenciados com um orquestrador de contêiner, você deve assumir que eles podem ser movidos de um nó ou VM para outro.
As seguintes soluções são usadas para gerenciar dados em aplicativos Docker:
No host do Docker, como Volumes do Docker:
Os volumes são armazenados em uma área do sistema de arquivos host gerenciada pelo Docker.
As montagens de ligação podem ser mapeadas para qualquer pasta no sistema de arquivos host, portanto, o acesso não pode ser controlado a partir do processo do Docker e pode representar um risco de segurança, pois um contêiner pode acessar pastas confidenciais do sistema operacional.
As montagens tmpfs são como pastas virtuais que só existem na memória do host e nunca são gravadas no sistema de arquivos.
A partir do armazenamento remoto:
Armazenamento do Azure, que fornece armazenamento geodistribuível, fornecendo uma boa solução de persistência de longo prazo para contêineres.
Bancos de dados relacionais remotos, como o Banco de Dados SQL do Azure ou bancos de dados NoSQL, como o Azure Cosmos DB, ou serviços de cache, como Redis.
No contêiner do Docker:
- Sistema de arquivos de sobreposição. Esse recurso do Docker implementa uma tarefa de cópia ao gravar que armazena informações atualizadas no sistema de arquivos raiz do contêiner. Essa informação está "em cima" da imagem original na qual o recipiente se baseia. Se o contêiner for excluído do sistema, essas alterações serão perdidas. Portanto, embora seja possível salvar o estado de um contêiner em seu armazenamento local, projetar um sistema em torno disso entraria em conflito com a premissa do design do contêiner, que por padrão é sem monitoração de estado.
No entanto, usar os Volumes do Docker agora é a maneira preferida de lidar com dados locais no Docker. Se precisar de mais informações sobre armazenamento em contêineres, verifique os drivers de armazenamento do Docker e Sobre os drivers de armazenamento.
O seguinte fornece mais detalhes sobre essas opções:
Os volumes são diretórios mapeados do sistema operacional host para diretórios em contêineres. Quando o código no contêiner tem acesso ao diretório, esse acesso é, na verdade, a um diretório no sistema operacional host. Esse diretório não está vinculado ao tempo de vida do contêiner em si, e o diretório é gerenciado pelo Docker e isolado da funcionalidade principal da máquina host. Assim, os volumes de dados são projetados para manter os dados independentemente da vida útil do contêiner. Se você excluir um contêiner ou uma imagem do host do Docker, os dados persistentes no volume de dados não serão excluídos.
Os volumes podem ser nomeados ou anônimos (o padrão). Os volumes nomeados são a evolução dos Contêineres de Volume de Dados e facilitam o compartilhamento de dados entre contêineres. Os volumes também suportam drivers de volume que permitem armazenar dados em hosts remotos, entre outras opções.
As montagens de ligação estão disponíveis há muito tempo e permitem o mapeamento de qualquer pasta para um ponto de montagem em um contêiner. As montagens de ligação têm mais limitações do que volumes e alguns problemas de segurança importantes, por isso os volumes são a opção recomendada.
As montagens tmpfs são basicamente pastas virtuais que vivem apenas na memória do host e nunca são gravadas no sistema de arquivos. São rápidos e seguros, mas utilizam memória e destinam-se apenas a dados temporários e não persistentes.
Como mostra a Figura 4-5, os volumes regulares do Docker podem ser armazenados fora dos próprios contêineres, mas dentro dos limites físicos do servidor host ou da VM. No entanto, os contêineres do Docker não podem acessar um volume de um servidor host ou VM para outro. Em outras palavras, com esses volumes, não é possível gerenciar dados compartilhados entre contêineres que são executados em hosts Docker diferentes, embora isso possa ser alcançado com um driver de volume que suporte hosts remotos.
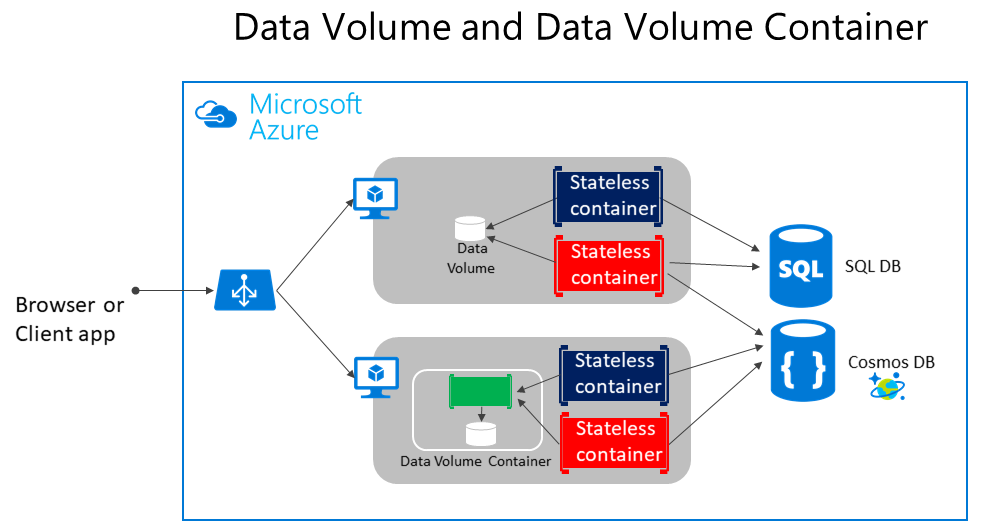
Figura 4-5. Volumes e fontes de dados externas para aplicativos baseados em contêiner
Os volumes podem ser compartilhados entre contêineres, mas somente no mesmo host, a menos que você use um driver remoto que ofereça suporte a hosts remotos. Além disso, quando os contêineres do Docker são gerenciados por um orquestrador, os contêineres podem "se mover" entre hosts, dependendo das otimizações executadas pelo cluster. Portanto, não é recomendável usar volumes de dados para dados corporativos. Mas eles são um bom mecanismo para trabalhar com arquivos de rastreamento, arquivos temporais ou similares que não afetarão a consistência dos dados corporativos.
As fontes de dados remotas e as ferramentas de cache , como o Banco de Dados SQL do Azure, o Azure Cosmos DB ou um cache remoto como o Redis, podem ser usadas em aplicativos em contêineres da mesma forma que são usadas no desenvolvimento sem contêineres. Essa é uma maneira comprovada de armazenar dados de aplicativos de negócios.
Armazenamento do Azure. Normalmente, os dados empresariais terão de ser colocados em recursos ou bases de dados externos, como o Armazenamento do Azure. O Armazenamento do Azure, em concreto, fornece os seguintes serviços na nuvem:
O armazenamento de Blob armazena dados de objetos não estruturados. Um blob pode ser qualquer tipo de texto ou dados binários, como arquivos de documentos ou mídia (arquivos de imagens, áudio e vídeo). O Blob Storage também é referido como um Armazenamento de objetos.
O armazenamento de arquivos oferece armazenamento compartilhado para aplicativos herdados usando o protocolo SMB padrão. As máquinas virtuais e os serviços de nuvem do Azure podem compartilhar dados de arquivos entre componentes de aplicativos por meio de compartilhamentos montados. Os aplicativos locais podem acessar dados de arquivos em um compartilhamento por meio da API REST do serviço de arquivos.
O armazenamento de tabelas armazena conjuntos de dados estruturados. O armazenamento de tabelas é um armazenamento de dados de atributos de chave NoSQL, que permite um desenvolvimento rápido e acesso rápido a grandes quantidades de dados.
Bases de dados relacionais e bases de dados NoSQL. Há muitas opções para bancos de dados externos, desde bancos de dados relacionais como SQL Server, PostgreSQL, Oracle ou bancos de dados NoSQL como Azure Cosmos DB, MongoDB, etc. Estas bases de dados não serão explicadas como parte deste guia, uma vez que estão num assunto completamente diferente.