Desafios e soluções para o gerenciamento distribuído de dados
Gorjeta
Este conteúdo é um trecho do eBook, .NET Microservices Architecture for Containerized .NET Applications, disponível no .NET Docs ou como um PDF para download gratuito que pode ser lido offline.

Desafio #1: Como definir os limites de cada microsserviço
Definir limites de microsserviços é provavelmente o primeiro desafio que alguém encontra. Cada microsserviço tem de ser uma parte da sua aplicação e cada microsserviço deve ser autónomo com todos os benefícios e desafios que transmite. Mas como identificar esses limites?
Primeiro, você precisa se concentrar nos modelos de domínio lógico do aplicativo e nos dados relacionados. Tente identificar ilhas dissociadas de dados e contextos diferentes dentro do mesmo aplicativo. Cada contexto pode ter uma linguagem de negócios diferente (termos comerciais diferentes). Os contextos devem ser definidos e geridos de forma independente. Os termos e entidades que são usados nesses contextos diferentes podem parecer semelhantes, mas você pode descobrir que, em um contexto específico, um conceito de negócios com um é usado para uma finalidade diferente em outro contexto, e pode até ter um nome diferente. Por exemplo, um usuário pode ser referido como um usuário no contexto de identidade ou associação, como um cliente em um contexto de CRM, como um comprador em um contexto de pedido, e assim por diante.
A maneira como você identifica os limites entre vários contextos de aplicativo com um domínio diferente para cada contexto é exatamente como você pode identificar os limites para cada microsserviço de negócios e seu modelo de domínio e dados relacionados. Você sempre tenta minimizar o acoplamento entre esses microsserviços. Este guia entra em mais detalhes sobre essa identificação e design de modelo de domínio na seção Identificando limites de modelo de domínio para cada microsserviço mais tarde.
Desafio #2: Como criar consultas que recuperam dados de vários microsserviços
Um segundo desafio é como implementar consultas que recuperam dados de vários microsserviços, evitando a comunicação tagarela com os microsserviços a partir de aplicativos cliente remotos. Um exemplo pode ser uma única tela de um aplicativo móvel que precisa mostrar informações do usuário pertencentes à cesta, ao catálogo e aos microsserviços de identidade do usuário. Outro exemplo seria um relatório complexo envolvendo muitas tabelas localizadas em vários microsserviços. A solução certa depende da complexidade das consultas. Mas, em qualquer caso, você precisará de uma maneira de agregar informações se quiser melhorar a eficiência nas comunicações do seu sistema. As soluções mais populares são as seguintes.
Gateway de API. Para agregação de dados simples de vários microsserviços que possuem bancos de dados diferentes, a abordagem recomendada é um microsserviço de agregação conhecido como API Gateway. No entanto, você precisa ter cuidado ao implementar esse padrão, porque ele pode ser um ponto de estrangulamento em seu sistema e pode violar o princípio da autonomia do microsserviço. Para mitigar essa possibilidade, você pode ter vários API Gateways refinados, cada um com foco em uma "fatia" vertical ou área de negócios do sistema. O padrão API Gateway é explicado com mais detalhes na seção API Gateway mais tarde.
Federação GraphQL Uma opção a considerar se seus microsserviços já estão usando o GraphQL é a Federação GraphQL. A federação permite definir "subgráficos" de outros serviços e compô-los em um "supergráfico" agregado que atua como um esquema autônomo.
CQRS com tabelas de consulta/leitura. Outra solução para agregar dados de vários microsserviços é o padrão Materialized View. Nessa abordagem, você gera, com antecedência (prepara dados desnormalizados antes que as consultas reais aconteçam), uma tabela somente leitura com os dados pertencentes a vários microsserviços. A tabela tem um formato adequado às necessidades do aplicativo cliente.
Considere algo como a tela de um aplicativo móvel. Se você tiver um único banco de dados, poderá reunir os dados para essa tela usando uma consulta SQL que executa uma junção complexa envolvendo várias tabelas. No entanto, quando você tem vários bancos de dados e cada banco de dados é de propriedade de um microsserviço diferente, você não pode consultar esses bancos de dados e criar uma junção SQL. A sua consulta complexa torna-se um desafio. Você pode atender ao requisito usando uma abordagem CQRS — você cria uma tabela desnormalizada em um banco de dados diferente que é usado apenas para consultas. A tabela pode ser projetada especificamente para os dados necessários para a consulta complexa, com uma relação um-para-um entre os campos necessários para a tela do seu aplicativo e as colunas na tabela de consulta. Poderia também servir para efeitos de elaboração de relatórios.
Essa abordagem não só resolve o problema original (como consultar e unir em microsserviços), mas também melhora consideravelmente o desempenho quando comparado com uma junção complexa, porque você já tem os dados de que o aplicativo precisa na tabela de consulta. É claro que usar a Segregação de Responsabilidade de Comando e Consulta (CQRS) com tabelas de consulta/leitura significa trabalho de desenvolvimento adicional, e você precisará adotar uma eventual consistência. No entanto, os requisitos de desempenho e alta escalabilidade em cenários colaborativos (ou cenários competitivos, dependendo do ponto de vista) são onde você deve aplicar o CQRS com vários bancos de dados.
"Dados frios" em bases de dados centrais. Para relatórios e consultas complexas que podem não exigir dados em tempo real, uma abordagem comum é exportar seus "dados quentes" (dados transacionais dos microsserviços) como "dados frios" para grandes bancos de dados que são usados apenas para relatórios. Esse sistema de banco de dados central pode ser um sistema baseado em Big Data, como o Hadoop; um armazém de dados como um baseado no SQL Data Warehouse do Azure; ou até mesmo um único banco de dados SQL que é usado apenas para relatórios (se o tamanho não for um problema).
Lembre-se de que esse banco de dados centralizado seria usado apenas para consultas e relatórios que não precisam de dados em tempo real. As atualizações e transações originais, como sua fonte de verdade, devem estar em seus dados de microsserviços. A maneira de sincronizar dados seria usando a comunicação orientada a eventos (abordada nas próximas seções) ou usando outras ferramentas de importação/exportação de infraestrutura de banco de dados. Se você usar a comunicação orientada a eventos, esse processo de integração será semelhante à maneira como você propaga dados, conforme descrito anteriormente para tabelas de consulta CQRS.
No entanto, se o design do aplicativo envolver a agregação constante de informações de vários microsserviços para consultas complexas, isso pode ser um sintoma de um design incorreto - um microsserviço deve ser o mais isolado possível de outros microsserviços. (Isso exclui relatórios/análises que sempre devem usar bancos de dados centrais de dados frios.) Ter esse problema com frequência pode ser um motivo para mesclar microsserviços. Você precisa equilibrar a autonomia de evolução e implantação de cada microsserviço com fortes dependências, coesão e agregação de dados.
Desafio #3: Como alcançar consistência em vários microsserviços
Como dito anteriormente, os dados de propriedade de cada microsserviço são privados desse microsserviço e só podem ser acessados usando sua API de microsserviço. Portanto, um desafio apresentado é como implementar processos de negócios de ponta a ponta, mantendo a consistência em vários microsserviços.
Para analisar esse problema, vejamos um exemplo do aplicativo de referência eShopOnContainers. O microsserviço Catálogo mantém informações sobre todos os produtos, incluindo o preço do produto. O microsserviço Basket gerencia dados temporais sobre itens de produtos que os usuários estão adicionando às suas cestas de compras, o que inclui o preço dos itens no momento em que foram adicionados à cesta. Quando o preço de um produto é atualizado no catálogo, esse preço também deve ser atualizado nas cestas ativas que contêm esse mesmo produto, além de que o sistema provavelmente deve avisar o usuário dizendo que o preço de um determinado item mudou desde que ele o adicionou à sua cesta.
Em uma versão monolítica hipotética deste aplicativo, quando o preço muda na tabela de produtos, o subsistema de catálogo pode simplesmente usar uma transação ACID para atualizar o preço atual na tabela Basket.
No entanto, em um aplicativo baseado em microsserviços, as tabelas Produto e Cesta são de propriedade de seus respetivos microsserviços. Nenhum microsserviço deve incluir tabelas/armazenamento de propriedade de outro microsserviço em suas próprias transações, nem mesmo em consultas diretas, como mostra a Figura 4-9.
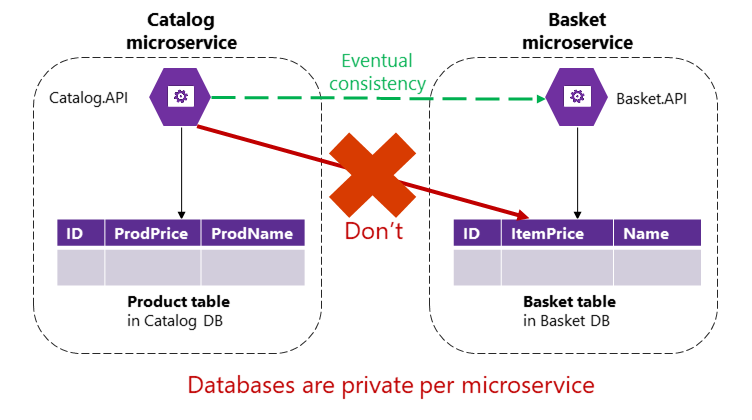
Figura 4-9. Um microsserviço não pode acessar diretamente uma tabela em outro microsserviço
O microsserviço de Catálogo não deve atualizar a tabela de Cesta diretamente, porque a tabela de Cesta é de propriedade do microsserviço de Cesta. Para fazer uma atualização para o microsserviço Basket, o microsserviço Catálogo deve usar consistência eventual provavelmente baseada em comunicação assíncrona, como eventos de integração (mensagem e comunicação baseada em eventos). É assim que o aplicativo de referência eShopOnContainers executa esse tipo de consistência entre microsserviços.
Como afirmado pelo teorema CAP, você precisa escolher entre disponibilidade e consistência forte ACID. A maioria dos cenários baseados em microsserviços exige disponibilidade e alta escalabilidade, em oposição a uma forte consistência. Os aplicativos de missão crítica devem permanecer ativos e em execução, e os desenvolvedores podem contornar uma consistência forte usando técnicas para trabalhar com consistência fraca ou eventual. Essa é a abordagem adotada pela maioria das arquiteturas baseadas em microsserviços.
Além disso, as transações de comprometimento no estilo ACID ou em duas fases não são apenas contra os princípios dos microsserviços; a maioria dos bancos de dados NoSQL (como Azure Cosmos DB, MongoDB, etc.) não oferece suporte a transações de confirmação de duas fases, típicas em cenários de bancos de dados distribuídos. No entanto, manter a consistência dos dados entre serviços e bancos de dados é essencial. Esse desafio também está relacionado à questão de como propagar alterações em vários microsserviços quando determinados dados precisam ser redundantes — por exemplo, quando você precisa ter o nome ou a descrição do produto no microsserviço Catálogo e no microsserviço Cesta.
Uma boa solução para esse problema é usar uma eventual consistência entre microsserviços articulados por meio de comunicação orientada a eventos e um sistema de publicação e assinatura. Esses tópicos são abordados na seção Comunicação assíncrona orientada a eventos mais adiante neste guia.
Desafio #4: Como projetar a comunicação através dos limites do microsserviço
A comunicação através dos limites dos microsserviços é um verdadeiro desafio. Neste contexto, a comunicação não se refere ao protocolo que você deve usar (HTTP e REST, AMQP, mensagens e assim por diante). Em vez disso, ele aborda qual estilo de comunicação você deve usar e, especialmente, quão acoplados seus microsserviços devem ser. Dependendo do nível de acoplamento, quando ocorrer uma falha, o impacto dessa falha no seu sistema variará significativamente.
Em um sistema distribuído como um aplicativo baseado em microsserviços, com tantos artefatos se movendo e com serviços distribuídos em muitos servidores ou hosts, os componentes acabarão falhando. Falhas parciais e interrupções ainda maiores ocorrerão, então você precisa projetar seus microsserviços e a comunicação entre eles, considerando os riscos comuns nesse tipo de sistema distribuído.
Uma abordagem popular é implementar microsserviços baseados em HTTP (REST), devido à sua simplicidade. Uma abordagem baseada em HTTP é perfeitamente aceitável; O problema aqui está relacionado com a forma como o utiliza. Se você usar solicitações e respostas HTTP apenas para interagir com seus microsserviços de aplicativos cliente ou de gateways de API, tudo bem. Mas se você criar longas cadeias de chamadas HTTP síncronas entre microsserviços, comunicando-se através de seus limites como se os microsserviços fossem objetos em um aplicativo monolítico, seu aplicativo acabará tendo problemas.
Por exemplo, imagine que seu aplicativo cliente faz uma chamada de API HTTP para um microsserviço individual, como o microsserviço Ordenando. Se o microsserviço Ordenando, por sua vez, chamar microsserviços adicionais usando HTTP dentro do mesmo ciclo de solicitação/resposta, você estará criando uma cadeia de chamadas HTTP. Pode parecer razoável inicialmente. No entanto, há pontos importantes a considerar ao seguir este caminho:
Bloqueio e baixo desempenho. Devido à natureza síncrona do HTTP, a solicitação original não recebe uma resposta até que todas as chamadas HTTP internas sejam concluídas. Imagine se o número dessas chamadas aumentar significativamente e, ao mesmo tempo, uma das chamadas HTTP intermediárias para um microsserviço for bloqueada. O resultado é que o desempenho é afetado e a escalabilidade geral será exponencialmente afetada à medida que as solicitações HTTP adicionais aumentam.
Acoplamento de microsserviços com HTTP. Os microsserviços empresariais não devem ser associados a outros microsserviços empresariais. Idealmente, eles não deveriam "saber" sobre a existência de outros microsserviços. Se seu aplicativo depende do acoplamento de microsserviços, como no exemplo, alcançar autonomia por microsserviço será quase impossível.
Falha em qualquer microsserviço. Se você implementou uma cadeia de microsserviços vinculados por chamadas HTTP, quando qualquer um dos microsserviços falhar (e eventualmente eles falharão), toda a cadeia de microsserviços falhará. Um sistema baseado em microsserviços deve ser projetado para continuar a funcionar tão bem quanto possível durante falhas parciais. Mesmo se você implementar a lógica do cliente que usa novas tentativas com mecanismos exponenciais de backoff ou disjuntor, quanto mais complexas forem as cadeias de chamadas HTTP, mais complexo será implementar uma estratégia de falha baseada em HTTP.
Na verdade, se seus microsserviços internos estão se comunicando criando cadeias de solicitações HTTP conforme descrito, pode-se argumentar que você tem um aplicativo monolítico, mas baseado em HTTP entre processos em vez de mecanismos de comunicação intraprocesso.
Portanto, para reforçar a autonomia do microsserviço e ter melhor resiliência, você deve minimizar o uso de cadeias de comunicação de solicitação/resposta entre microsserviços. É recomendável usar apenas a interação assíncrona para comunicação entre microsserviços, usando comunicação assíncrona baseada em mensagens e eventos ou usando sondagem HTTP (assíncrona) independentemente do ciclo de solicitação/resposta HTTP original.
O uso da comunicação assíncrona é explicado com detalhes adicionais mais adiante neste guia nas seções A integração assíncrona de microsserviços reforça a autonomia do microsserviço e a comunicação assíncrona baseada em mensagens.
Recursos adicionais
Teorema da PAC
https://en.wikipedia.org/wiki/CAP_theoremEventual consistência
https://en.wikipedia.org/wiki/Eventual_consistencyManual Básico de Consistência de Dados
https://learn.microsoft.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Martin Fowler. CQRS (Segregação de Responsabilidades de Comando e Consulta)
https://martinfowler.com/bliki/CQRS.htmlVista Materializada
https://learn.microsoft.com/azure/architecture/patterns/materialized-viewCharles Row. ACID vs. BASE: O pH variável do processamento de transações de banco de dados
https://www.dataversity.net/acid-vs-base-the-shifting-ph-of-database-transaction-processing/Compensação de Transação
https://learn.microsoft.com/azure/architecture/patterns/compensating-transactionUdi Dahan. Composição Orientada a Serviços
https://udidahan.com/2014/07/30/service-oriented-composition-with-video/