Soberania de dados por microsserviço
Gorjeta
Este conteúdo é um trecho do eBook, .NET Microservices Architecture for Containerized .NET Applications, disponível no .NET Docs ou como um PDF para download gratuito que pode ser lido offline.

Uma regra importante para a arquitetura de microsserviços é que cada microsserviço deve possuir seus dados de domínio e lógica. Assim como um aplicativo completo possui sua lógica e dados, cada microsserviço também deve possuir sua lógica e dados sob um ciclo de vida autônomo, com implantação independente por microsserviço.
Isso significa que o modelo conceitual do domínio será diferente entre subsistemas ou microsserviços. Considere os aplicativos corporativos, onde os aplicativos de gerenciamento de relacionamento com o cliente (CRM), os subsistemas de compra transacional e os subsistemas de suporte ao cliente chamam atributos e dados exclusivos da entidade do cliente e cada um emprega um contexto delimitado (BC) diferente.
Esse princípio é semelhante no DDD (Domain-driven design), onde cada Contexto Delimitado ou subsistema ou serviço autônomo deve possuir seu modelo de domínio (dados mais lógica e comportamento). Cada contexto delimitado DDD se correlaciona a um microsserviço de negócios (um ou vários serviços). Este ponto sobre o padrão de contexto delimitado é expandido na próxima seção.
Por outro lado, a abordagem tradicional (dados monolíticos) usada em muitas aplicações é ter um único banco de dados centralizado ou apenas alguns bancos de dados. Isso geralmente é um banco de dados SQL normalizado que é usado para todo o aplicativo e todos os seus subsistemas internos, como mostra a Figura 4-7.
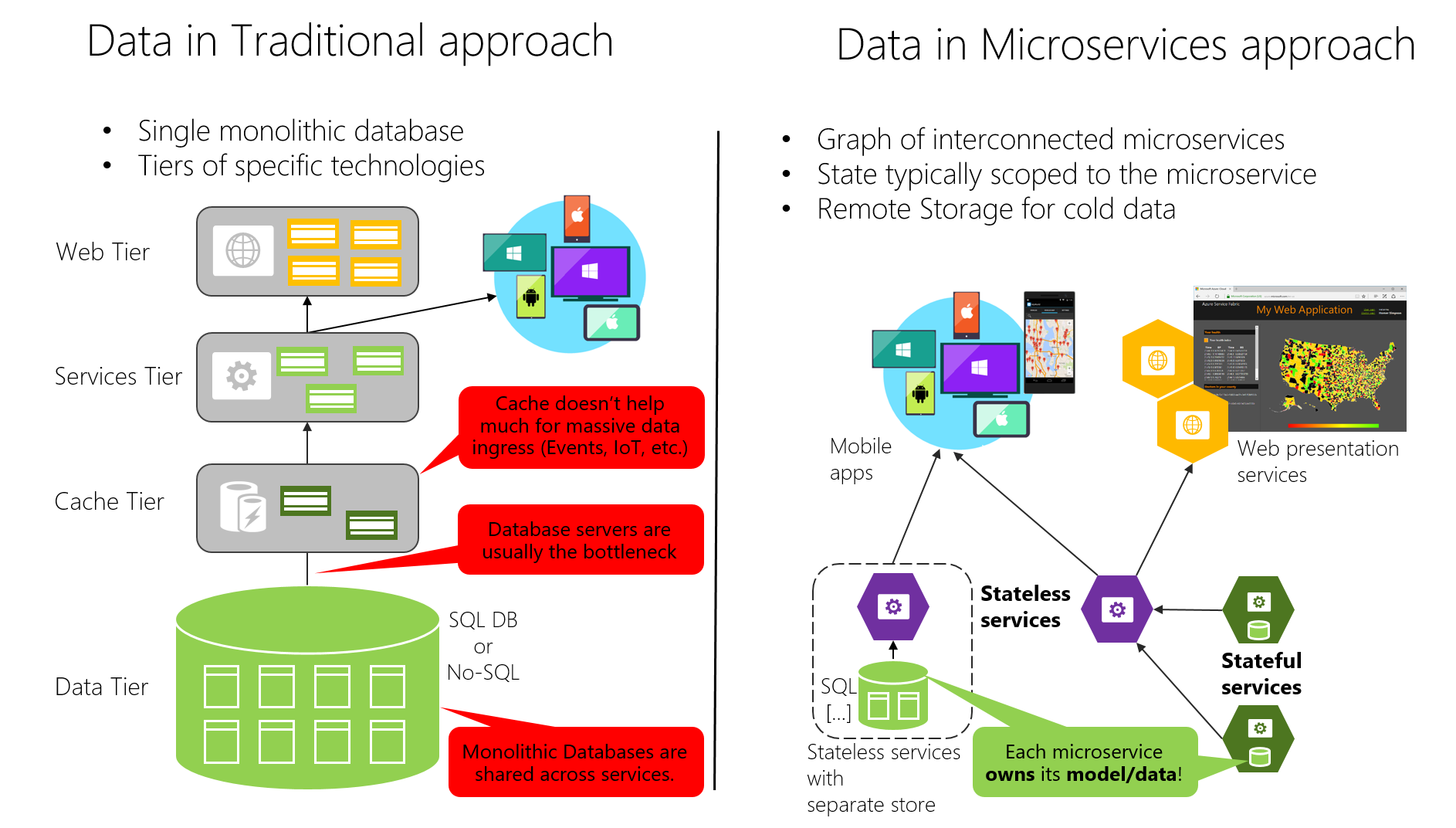
Figura 4-7. Comparação de soberania de dados: banco de dados monolítico versus microsserviços
Na abordagem tradicional, há um único banco de dados compartilhado entre todos os serviços, geralmente em uma arquitetura hierárquica. Na abordagem de microsserviços, cada microsserviço possui seu modelo/dados. A abordagem de banco de dados centralizado inicialmente parece mais simples e parece permitir a reutilização de entidades em diferentes subsistemas para tornar tudo consistente. Mas a realidade é que você acaba com tabelas enormes que servem muitos subsistemas diferentes, e que incluem atributos e colunas que não são necessários na maioria dos casos. É como tentar usar o mesmo mapa físico para caminhar por uma trilha curta, fazer uma viagem de carro de um dia e aprender geografia.
Um aplicativo monolítico com normalmente um único banco de dados relacional tem dois benefícios importantes: transações ACID e a linguagem SQL, ambos trabalhando em todas as tabelas e dados relacionados ao seu aplicativo. Essa abordagem fornece uma maneira de escrever facilmente uma consulta que combina dados de várias tabelas.
No entanto, o acesso aos dados torna-se muito mais complicado quando você muda para uma arquitetura de microsserviços. Mesmo ao usar transações ACID dentro de um microsserviço ou contexto limitado, é crucial considerar que os dados de propriedade de cada microsserviço são privados desse microsserviço e só devem ser acessados de forma síncrona por meio de seus pontos de extremidade de API (REST, gRPC, SOAP, etc) ou de forma assíncrona por meio de mensagens (AMQP ou similar).
O encapsulamento dos dados garante que os microsserviços sejam acoplados de forma flexível e possam evoluir independentemente uns dos outros. Se vários serviços estivessem acessando os mesmos dados, as atualizações de esquema exigiriam atualizações coordenadas para todos os serviços. Isso quebraria a autonomia do ciclo de vida do microsserviço. Mas estruturas de dados distribuídas significam que você não pode fazer uma única transação ACID em microsserviços. Isso, por sua vez, significa que você deve usar consistência eventual quando um processo de negócios abrange vários microsserviços. Isso é muito mais difícil de implementar do que simples junções SQL, porque você não pode criar restrições de integridade ou usar transações distribuídas entre bancos de dados separados, como explicaremos mais adiante. Da mesma forma, muitos outros recursos de banco de dados relacional não estão disponíveis em vários microsserviços.
Indo ainda mais longe, diferentes microsserviços geralmente usam diferentes tipos de bancos de dados. Os aplicativos modernos armazenam e processam diversos tipos de dados, e um banco de dados relacional nem sempre é a melhor escolha. Para alguns casos de uso, um banco de dados NoSQL, como o Azure CosmosDB ou o MongoDB, pode ter um modelo de dados mais conveniente e oferecer melhor desempenho e escalabilidade do que um banco de dados SQL como o SQL Server ou o Banco de Dados SQL do Azure. Em outros casos, um banco de dados relacional ainda é a melhor abordagem. Portanto, os aplicativos baseados em microsserviços geralmente usam uma mistura de bancos de dados SQL e NoSQL, que às vezes é chamada de abordagem de persistência poliglota.
Uma arquitetura particionada e poliglota-persistente para armazenamento de dados tem muitos benefícios. Isso inclui serviços de acoplamento flexível e melhor desempenho, escalabilidade, custos e capacidade de gerenciamento. No entanto, ele pode introduzir alguns desafios de gerenciamento de dados distribuídos, conforme explicado em "Identificando limites de modelo de domínio" mais adiante neste capítulo.
A relação entre microsserviços e o padrão de contexto delimitado
O conceito de microsserviço deriva do padrão de contexto delimitado (BC) no design controlado por domínio (DDD). O DDD lida com grandes modelos, dividindo-os em vários BCs e sendo explícito sobre seus limites. Cada BC deve ter seu próprio modelo e banco de dados; Da mesma forma, cada microsserviço possui seus dados relacionados. Além disso, cada BC geralmente tem sua própria linguagem ubíqua para ajudar na comunicação entre desenvolvedores de software e especialistas em domínio.
Esses termos (principalmente entidades de domínio) na linguagem ubíqua podem ter nomes diferentes em diferentes Contextos Delimitados, mesmo quando entidades de domínio diferentes compartilham a mesma identidade (ou seja, a ID exclusiva usada para ler a entidade do armazenamento). Por exemplo, em um Contexto Delimitado de perfil de usuário, a entidade de domínio Usuário pode compartilhar identidade com a entidade de domínio Comprador no Contexto Delimitado de ordenação.
Um microsserviço é, portanto, como um Contexto Delimitado, mas também especifica que é um serviço distribuído. Ele é criado como um processo separado para cada contexto delimitado e deve usar os protocolos distribuídos observados anteriormente, como HTTP/HTTPS, WebSockets ou AMQP. O padrão Contexto Delimitado, no entanto, não especifica se o Contexto Delimitado é um serviço distribuído ou se é simplesmente um limite lógico (como um subsistema genérico) dentro de um aplicativo de implantação monolítica.
É importante destacar que definir um serviço para cada Contexto Delimitado é um bom ponto de partida. Mas você não precisa restringir seu design a ele. Às vezes, você deve projetar um Contexto Delimitado ou microsserviço de negócios composto por vários serviços físicos. Mas, em última análise, ambos os padrões - Contexto Delimitado e microsserviço - estão intimamente relacionados.
O DDD se beneficia dos microsserviços ao obter limites reais na forma de microsserviços distribuídos. Mas ideias como não compartilhar o modelo entre microsserviços são o que você também quer em um contexto limitado.
Recursos adicionais
Chris Richardson. Padrão: Banco de dados por serviço
https://microservices.io/patterns/data/database-per-service.htmlMartin Fowler. BoundedContext
https://martinfowler.com/bliki/BoundedContext.htmlMartin Fowler. PolyglotPersistence
https://martinfowler.com/bliki/PolyglotPersistence.htmlAlberto Brandolini. Design Estratégico Orientado a Domínios com Mapeamento de Contexto
https://www.infoq.com/articles/ddd-contextmapping