A geração aumentada de recuperação (RAG) fornece conhecimento de LLM
Este artigo descreve como a geração aumentada de recuperação permite que os LLMs tratem suas fontes de dados como conhecimento sem ter que treinar.
Os LLMs têm amplas bases de conhecimento através de treinamento. Para a maioria dos cenários, você pode selecionar um LLM projetado para suas necessidades, mas esses LLMs ainda exigem treinamento adicional para entender seus dados específicos. A geração aumentada de recuperação permite que você disponibilize seus dados para LLMs sem treiná-los primeiro.
Como funciona o RAG
Para executar a geração aumentada de recuperação, você cria incorporações para seus dados, juntamente com perguntas comuns sobre eles. Você pode fazer isso rapidamente ou pode criar e armazenar as incorporações usando uma solução de banco de dados vetorial.
Quando um usuário faz uma pergunta, o LLM usa suas incorporações para comparar a pergunta do usuário com seus dados e encontrar o contexto mais relevante. Esse contexto e a pergunta do usuário vão para o LLM em um prompt, e o LLM fornece uma resposta com base em seus dados.
Processo RAG básico
Para executar o RAG, você deve processar cada fonte de dados que deseja usar para recuperações. O processo básico é o seguinte:
- Fragmente dados grandes em partes gerenciáveis.
- Converta os blocos em um formato pesquisável.
- Armazene os dados convertidos em um local que permita acesso eficiente. Além disso, é importante armazenar metadados relevantes para citações ou referências quando o LLM fornece respostas.
- Alimente seus dados convertidos para LLMs em prompts.
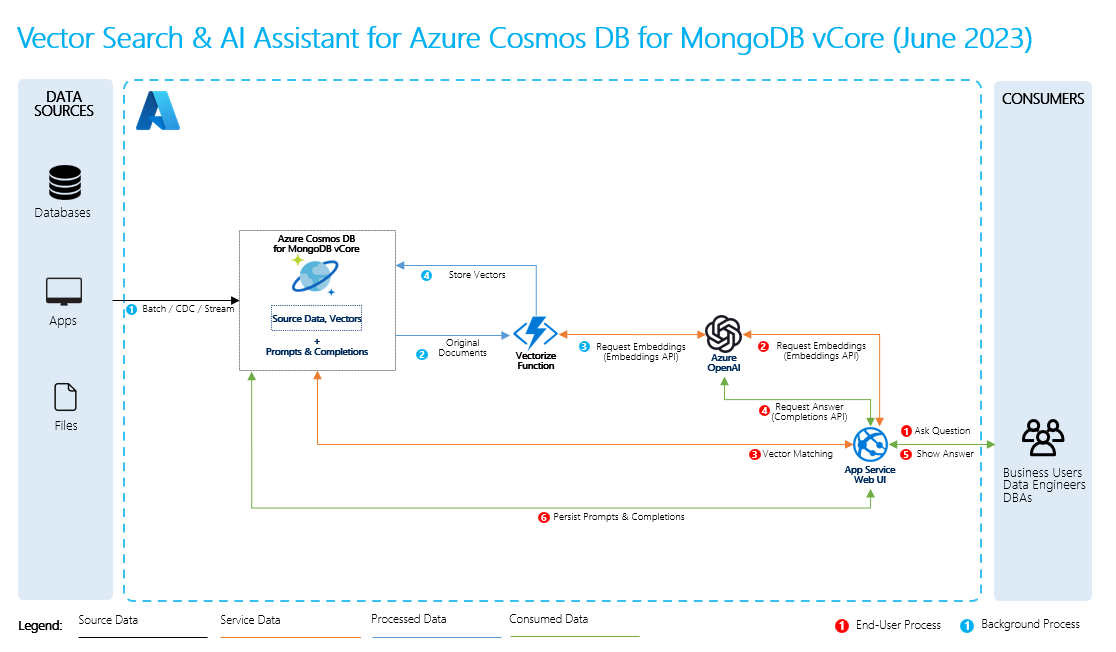
- Dados de origem: é aqui que os seus dados existem. Pode ser um arquivo/pasta em sua máquina, um arquivo no armazenamento em nuvem, um ativo de dados do Azure Machine Learning, um repositório Git ou um banco de dados SQL.
- Fragmentação de dados: os dados em sua fonte precisam ser convertidos em texto sem formatação. Por exemplo, documentos do Word ou PDFs precisam ser abertos e convertidos em texto. O texto é então fragmentado em pedaços menores.
- Convertendo o texto em vetores: são incorporações. Os vetores são representações numéricas de conceitos convertidos em sequências numéricas, o que torna mais fácil para os computadores entenderem as relações entre esses conceitos.
- Links entre dados de origem e incorporações: essas informações são armazenadas como metadados nas partes que você criou, que são usadas para ajudar os LLMs a gerar citações enquanto geram respostas.