Monitorar e mitigar a limitação para reduzir a latência no Azure Time Series Insights Gen1
Nota
O serviço Time Series Insights será desativado em 7 de julho de 2024. Considere migrar os ambientes existentes para soluções alternativas o mais rápido possível. Para obter mais informações sobre a substituição e migração, visite nossa documentação.
Atenção
Este é um artigo Gen1.
Quando a quantidade de dados de entrada excede a configuração do seu ambiente, você pode enfrentar latência ou limitação no Azure Time Series Insights.
Você pode evitar latência e limitação configurando corretamente seu ambiente para a quantidade de dados que deseja analisar.
É mais provável que você enfrente latência e limitação quando:
- Adicione uma fonte de eventos que contenha dados antigos que podem exceder sua taxa de entrada alocada (o Azure Time Series Insights precisará se atualizar).
- Adicione mais fontes de eventos a um ambiente, resultando em um pico de eventos adicionais (que podem exceder a capacidade do seu ambiente).
- Envie grandes quantidades de eventos históricos para uma fonte de eventos, resultando em um atraso (o Azure Time Series Insights precisará se atualizar).
- Junte dados de referência com telemetria, resultando em um tamanho de evento maior. O tamanho máximo permitido do pacote é de 32 KB; pacotes de dados maiores que 32 KB são truncados.
Vídeo
Saiba mais sobre o comportamento de entrada de dados do Azure Time Series Insights e como planejá-lo.
Monitore a latência e a limitação com alertas
Os alertas podem ajudá-lo a diagnosticar e mitigar problemas de latência que ocorrem em seu ambiente.
No portal do Azure, selecione seu ambiente do Azure Time Series Insights. Em seguida, selecione Alertas.

Selecione + Nova regra de alerta. O painel Criar regra será exibido. Selecione Adicionar em CONDIÇÃO.

Em seguida, configure as condições exatas para a lógica do sinal.
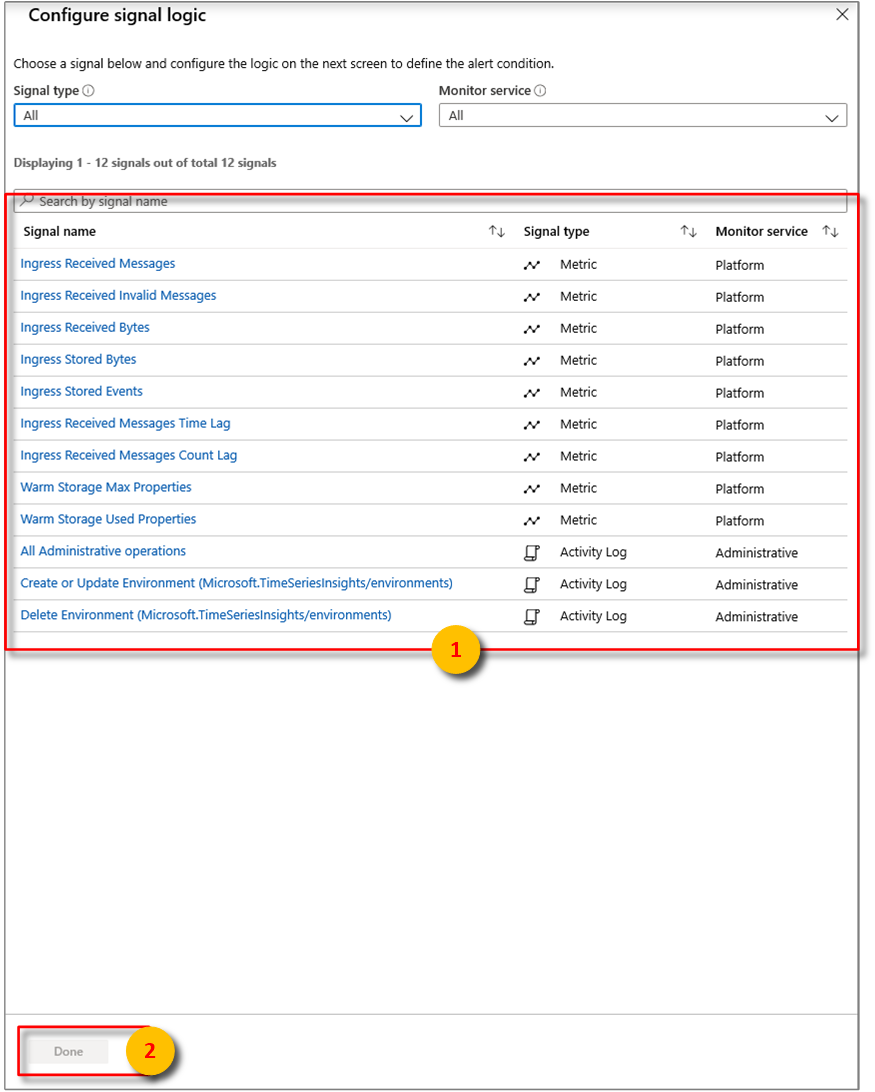
A partir daí, você pode configurar alertas usando algumas das seguintes condições:
Métrico Description Bytes recebidos de entrada Contagem de bytes brutos lidos de fontes de eventos. A contagem bruta geralmente inclui o nome e o valor da propriedade. Mensagens inválidas recebidas de entrada Contagem de mensagens inválidas lidas de todos os Hubs de Eventos do Azure ou fontes de eventos do Hub IoT do Azure. Mensagens recebidas de entrada Contagem de mensagens lidas de todas as fontes de eventos de Hubs de Eventos ou Hubs IoT. Ingressar bytes armazenados Tamanho total dos eventos armazenados e disponíveis para consulta. O tamanho é calculado apenas no valor da propriedade. Ingressar eventos armazenados Contagem de eventos nivelados armazenados e disponíveis para consulta. Atraso de Entrada de Mensagens Recebidas Diferença em segundos entre o tempo em que a mensagem está enfileirada na origem do evento e a hora em que é processada no Ingress. Atraso na contagem de mensagens recebidas de entrada Diferença entre o número de sequência da última mensagem enfileirada na partição de origem do evento e o número de sequência da mensagem que está sendo processada no Ingresso. Selecionar Concluído.
Depois de configurar a lógica de sinal desejada, revise visualmente a regra de alerta escolhida.





Gerenciamento de limitação e ingresso
Se você estiver sendo limitado, um valor para o Ingress Received Message Time Lag será registrado informando quantos segundos atrás do seu ambiente do Azure Time Series Insights está a partir do momento real em que a mensagem atinge a fonte do evento (excluindo o tempo de indexação de appx. 30-60 segundos).
Ingress Received Message Count Lag também deve ter um valor, permitindo que você determine quantas mensagens estão atrás de você. A maneira mais fácil de se envolver é aumentar a capacidade do seu ambiente para um tamanho que lhe permita superar a diferença.
Por exemplo, se o ambiente S1 estiver demonstrando um atraso de 5.000.000 de mensagens, você poderá aumentar o tamanho do ambiente para seis unidades por cerca de um dia para ser capturado. Você pode aumentar ainda mais para recuperar o atraso mais rápido. O período de recuperação é uma ocorrência comum ao provisionar inicialmente um ambiente, especialmente quando você o conecta a uma fonte de eventos que já tem eventos ou quando carrega em massa muitos dados históricos.
Outra técnica é definir um alerta >de Eventos Armazenados de Ingresso = um limite ligeiramente abaixo da capacidade total do ambiente por um período de 2 horas. Esse alerta pode ajudá-lo a entender se você está constantemente na capacidade, o que indica uma alta probabilidade de latência.
Por exemplo, se você tiver três unidades S1 provisionadas (ou capacidade de entrada de 2100 eventos por minuto), poderá definir um alerta de Eventos Armazenados de Entrada para >= 1900 eventos por 2 horas. Se você está constantemente excedendo esse limite e, portanto, acionando seu alerta, é provável que esteja subprovisionado.
Se suspeitar que está a ser limitado, pode comparar as suas Mensagens Recebidas de Entrada com as mensagens de saída da fonte do evento. Se a entrada no Hub de Eventos for maior do que as Mensagens de Entrada Recebidas, é provável que as Informações de Série Temporal do Azure estejam sendo limitadas.
Melhorar o desempenho
Para reduzir a limitação ou experimentar latência, a melhor maneira de corrigi-la é aumentar a capacidade do seu ambiente.
Você pode evitar latência e limitação configurando corretamente seu ambiente para a quantidade de dados que deseja analisar. Para obter mais informações sobre como adicionar capacidade ao seu ambiente, leia Dimensionar seu ambiente.
Próximos passos
Leia sobre Diagnosticar e resolver problemas em seu ambiente do Azure Time Series Insights.
Saiba como dimensionar seu ambiente do Azure Time Series Insights.