Como usar OPENROWSET usando o pool SQL sem servidor no Azure Synapse Analytics
A OPENROWSET(BULK...) função permite que você acesse arquivos no Armazenamento do Azure. OPENROWSET função lê o conteúdo de uma fonte de dados remota (por exemplo, arquivo) e retorna o conteúdo como um conjunto de linhas. Dentro do recurso de pool SQL sem servidor, o provedor de conjunto de linhas em massa OPENROWSET é acessado chamando a função OPENROWSET e especificando a opção MASS.
A OPENROWSET função pode ser referenciada FROM na cláusula de uma consulta como se fosse um nome OPENROWSETde tabela. Ele suporta operações em massa por meio de um provedor BULK interno que permite que os dados de um arquivo sejam lidos e retornados como um conjunto de linhas.
Nota
A função OPENROWSET não é suportada no pool SQL dedicado.
Data source
A função OPENROWSET no Synapse SQL lê o conteúdo dos arquivos de uma fonte de dados. A fonte de dados é uma conta de armazenamento do Azure e pode ser explicitamente referenciada na função ou pode ser inferida dinamicamente a OPENROWSET partir da URL dos arquivos que você deseja ler.
Opcionalmente, a OPENROWSET função pode conter um DATA_SOURCE parâmetro para especificar a fonte de dados que contém arquivos.
OPENROWSETsemDATA_SOURCEpode ser usado para ler diretamente o conteúdo dos arquivos a partir do local URL especificado comoBULKopção:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
Esta é uma maneira rápida e fácil de ler o conteúdo dos arquivos sem pré-configuração. Essa opção permite que você use a opção de autenticação básica para acessar o armazenamento (passagem do Microsoft Entra para logons do Microsoft Entra e token SAS para logons SQL).
OPENROWSETcomDATA_SOURCEpode ser usado para acessar arquivos na conta de armazenamento especificada:SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]Essa opção permite configurar o local da conta de armazenamento na fonte de dados e especificar o método de autenticação que deve ser usado para acessar o armazenamento.
Importante
OPENROWSETsemDATA_SOURCEfornece uma maneira rápida e fácil de acessar os arquivos de armazenamento, mas oferece opções de autenticação limitadas. Por exemplo, os principais do Microsoft Entra podem acessar arquivos somente usando sua identidade do Microsoft Entra ou arquivos disponíveis publicamente. Se você precisar de opções de autenticação mais poderosas, useDATA_SOURCEa opção e defina a credencial que deseja usar para acessar o armazenamento.
Segurança
Um usuário de banco de dados deve ter ADMINISTER BULK OPERATIONS permissão para usar a OPENROWSET função.
O administrador de armazenamento também deve permitir que um usuário acesse os arquivos fornecendo token SAS válido ou habilitando a entidade de segurança do Microsoft Entra para acessar arquivos de armazenamento. Saiba mais sobre o controle de acesso ao armazenamento neste artigo.
OPENROWSET Use as seguintes regras para determinar como autenticar no armazenamento:
- O mecanismo de autenticação sem
OPENROWSETDATA_SOURCEdepende do tipo de chamador.- Qualquer usuário pode usar
OPENROWSETsemDATA_SOURCEler arquivos disponíveis publicamente no armazenamento do Azure. - Os logons do Microsoft Entra podem acessar arquivos protegidos usando sua própria identidade do Microsoft Entra se o armazenamento do Azure permitir que o usuário do Microsoft Entra acesse arquivos subjacentes (por exemplo, se o chamador tiver
Storage Readerpermissão no armazenamento do Azure). - Os logins SQL também podem ser usados
OPENROWSETsemDATA_SOURCEacessar arquivos disponíveis publicamente, arquivos protegidos usando o token SAS ou o espaço de trabalho Identidade Gerenciada da Sinapse. Você precisaria criar credenciais com escopo de servidor para permitir o acesso a arquivos de armazenamento.
- Qualquer usuário pode usar
- Em
OPENROWSETcomDATA_SOURCEo mecanismo de autenticação é definido na credencial de escopo do banco de dados atribuída à fonte de dados referenciada. Essa opção permite que você acesse o armazenamento disponível publicamente ou acesse o armazenamento usando o token SAS, a Identidade Gerenciada do espaço de trabalho ou a identidade do chamador do Microsoft Entra (se o chamador for o principal do Microsoft Entra). SeDATA_SOURCEfizer referência ao armazenamento do Azure que não é público, você precisará criar credenciais com escopo de banco de dados e fazer referência a elasDATA SOURCEpara permitir o acesso a arquivos de armazenamento.
O chamador deve ter REFERENCES permissão na credencial para usá-la para autenticar no armazenamento.
Sintaxe
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
Argumentos
Você tem três opções para arquivos de entrada que contêm os dados de destino para consulta. Os valores válidos são:
'CSV' - Inclui qualquer ficheiro de texto delimitado com separadores de linha/coluna. Qualquer caractere pode ser usado como um separador de campo, como TSV: FIELDTERMINATOR = tab.
'PARQUET' - Arquivo binário em formato Parquet.
'DELTA' - Um conjunto de arquivos Parquet organizados no formato Delta Lake (visualização).
Os valores com espaços em branco não são válidos. Por exemplo, 'CSV' não é um valor válido.
'unstructured_data_path'
O unstructured_data_path que estabelece um caminho para os dados pode ser um caminho absoluto ou relativo:
- Caminho absoluto no formato
\<prefix>://\<storage_account_path>/\<storage_path>permite que um usuário leia diretamente os arquivos. - Caminho relativo no formato
<storage_path>que deve ser usado com oDATA_SOURCEparâmetro e descreve o padrão de arquivo dentro do <local de storage_account_path> definido emEXTERNAL DATA SOURCE.
Abaixo, você encontrará os valores relevantes <do caminho> da conta de armazenamento que serão vinculados à sua fonte de dados externa específica.
| Fonte de dados externa | Prefixo | Caminho da conta de armazenamento |
|---|---|---|
| Armazenamento de Blobs do Azure | Disponível em: | <storage_account.blob.core.windows.net/path/file> |
| Armazenamento de Blobs do Azure | wasb[s] | <contentor>@<storage_account.blob.core.windows.net/path/file> |
| Azure Data Lake Store Gen1 | Disponível em: | <storage_account.azuredatalakestore.net/webhdfs/v1> |
| Azure Data Lake Store Gen2 | Disponível em: | <storage_account.dfs.core.windows.net/path/file> |
| Azure Data Lake Store Gen2 | ABFS[s] | <file_system>@<account_name.dfs.core.windows.net/path/file> |
'<storage_path>'
Especifica um caminho dentro do armazenamento que aponta para a pasta ou arquivo que você deseja ler. Se o caminho apontar para um contêiner ou pasta, todos os arquivos serão lidos desse contêiner ou pasta em particular. Os ficheiros em subpastas não serão incluídos.
Você pode usar curingas para direcionar vários arquivos ou pastas. É permitido o uso de vários curingas não consecutivos.
Abaixo está um exemplo que lê todos os arquivos csv começando com a população de todas as pastas começando com /csv/population:
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
Se você especificar o unstructured_data_path como uma pasta, uma consulta de pool SQL sem servidor recuperará arquivos dessa pasta.
Você pode instruir o pool SQL sem servidor a percorrer pastas especificando /* no final do caminho, como no exemplo: https://sqlondemandstorage.blob.core.windows.net/csv/population/**
Nota
Ao contrário do Hadoop e do PolyBase, o pool SQL sem servidor não retorna subpastas, a menos que você especifique /** no final do caminho. Assim como o Hadoop e o PolyBase, ele não retorna arquivos para os quais o nome do arquivo começa com um sublinhado (_) ou um ponto (.).
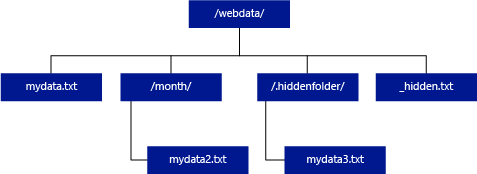
No exemplo abaixo, se o unstructured_data_path=https://mystorageaccount.dfs.core.windows.net/webdata/, uma consulta de pool SQL sem servidor retornará linhas de mydata.txt. Ele não retornará mydata2.txt e mydata3.txt porque eles estão localizados em uma subpasta.
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
A cláusula WITH permite especificar colunas que você deseja ler de arquivos.
Para arquivos de dados CSV, para ler todas as colunas, forneça nomes de colunas e seus tipos de dados. Se desejar um subconjunto de colunas, use números ordinais para escolher as colunas dos arquivos de dados de origem por ordinal. As colunas serão vinculadas pela designação ordinal. Se HEADER_ROW = TRUE for usado, a vinculação de coluna será feita pelo nome da coluna em vez da posição ordinal.
Gorjeta
Você também pode omitir a cláusula WITH para arquivos CSV. Os tipos de dados serão automaticamente inferidos a partir do conteúdo do arquivo. Você pode usar HEADER_ROW argumento para especificar a existência de linha de cabeçalho, caso em que os nomes de coluna serão lidos da linha de cabeçalho. Para obter detalhes, verifique a descoberta automática de esquema.
Para arquivos Parquet ou Delta Lake, forneça nomes de coluna que correspondam aos nomes de coluna nos arquivos de dados de origem. As colunas serão vinculadas pelo nome e diferenciam maiúsculas de minúsculas. Se a cláusula WITH for omitida, todas as colunas dos arquivos do Parquet serão retornadas.
Importante
Os nomes das colunas nos arquivos Parquet e Delta Lake diferenciam maiúsculas de minúsculas. Se você especificar o nome da coluna com caixa diferente da caixa do nome da coluna nos arquivos, os
NULLvalores serão retornados para essa coluna.
column_name = Nome da coluna de saída. Se fornecido, esse nome substitui o nome da coluna no arquivo de origem e o nome da coluna fornecido no caminho JSON, se houver. Se json_path não for fornecida, será automaticamente adicionada como '$.column_name'. Verifique json_path argumento de comportamento.
column_type = Tipo de dados para a coluna de saída. A conversão implícita do tipo de dados ocorrerá aqui.
column_ordinal = Número ordinal da coluna no(s) arquivo(s) de origem. Esse argumento é ignorado para arquivos Parquet, uma vez que a vinculação é feita pelo nome. O exemplo a seguir retornaria uma segunda coluna somente de um arquivo CSV:
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = expressão de caminho JSON para coluna ou propriedade aninhada. O modo de caminho padrão é frouxo.
Nota
No modo estrito, a consulta falhará com erro se o caminho fornecido não existir. No modo lax, a consulta terá êxito e a expressão de caminho JSON será avaliada como NULL.
<bulk_options>
FIELDTERMINATOR ='field_terminator'
Especifica o terminador de campo a ser usado. O terminador de campo padrão é uma vírgula (",").
ROWTERMINATOR ='row_terminator''
Especifica o terminador de linha a ser usado. Se o terminador de linha não for especificado, um dos terminadores padrão será usado. Os terminadores padrão para PARSER_VERSION = '1.0' são \r\n, \n e \r. Os terminadores padrão para PARSER_VERSION = '2.0' são \r\n e \n.
Nota
Quando você usa PARSER_VERSION='1.0' e especifica \n (newline) como o terminador de linha, ele será automaticamente prefixado com um caractere \r (retorno de carro), o que resulta em um terminador de linha de \r\n.
ESCAPE_CHAR = 'char'
Especifica o caractere no arquivo que é usado para escapar de si mesmo e todos os valores do delimitador no arquivo. Se o caractere de escape for seguido por um valor diferente de si mesmo, ou qualquer um dos valores do delimitador, o caractere de escape será descartado ao ler o valor.
O parâmetro ESCAPECHAR será aplicado independentemente de o FIELDQUOTE estar ou não habilitado. Ele não será usado para escapar do personagem citador. O caractere de citação deve ser escapado com outro caractere de citação. O caractere de citação pode aparecer dentro do valor da coluna somente se o valor for encapsulado com caracteres de aspas.
PRIMEIRA LINHA = 'first_row'
Especifica o número da primeira linha a ser carregada. O padrão é 1 e indica a primeira linha no arquivo de dados especificado. Os números das linhas são determinados pela contagem dos terminadores de linha. FIRSTROW é baseado em 1.
FIELDQUOTE = 'field_quote'
Especifica um caractere que será usado como o caractere de aspas no arquivo CSV. Se não for especificado, o caractere de aspas (") será usado.
DATA_COMPRESSION = 'data_compression_method'
Especifica o método de compactação. Suportado apenas em PARSER_VERSION='1.0'. O seguinte método de compressão é suportado:
- GZIP
PARSER_VERSION = 'parser_version'
Especifica a versão do analisador a ser usada ao ler arquivos. As versões do analisador CSV atualmente suportadas são 1.0 e 2.0:
- PARSER_VERSION = '1.0'
- PARSER_VERSION = '2.0'
O analisador CSV versão 1.0 é padrão e rico em recursos. A versão 2.0 foi criada para desempenho e não suporta todas as opções e codificações.
Especificações do analisador CSV versão 1.0:
- As seguintes opções não são suportadas: HEADER_ROW.
- Os terminadores padrão são \r\n, \n e \r.
- Se você especificar \n (newline) como o terminador de linha, ele será automaticamente prefixado com um caractere \r (retorno de carro), o que resulta em um terminador de linha de \r\n.
Especificações do analisador CSV versão 2.0:
- Nem todos os tipos de dados são suportados.
- O comprimento máximo da coluna de caracteres é 8000.
- O limite máximo de tamanho de linha é de 8 MB.
- As seguintes opções não são suportadas: DATA_COMPRESSION.
- String vazia entre aspas ("") é interpretada como string vazia.
- A opção DATEFORMAT SET não é honrada.
- Formato suportado para o tipo de dados DATE: AAAA-MM-DD
- Formato suportado para o tipo de dados TIME: HH:MM:SS[.fractional seconds]
- Formato suportado para DATETIME2 tipo de dados: AAAA-MM-DD HH:MM:SS[.fractional seconds]
- Os terminadores padrão são \r\n e \n.
HEADER_ROW = { VERDADEIRO | FALSO }
Especifica se um arquivo CSV contém linha de cabeçalho. O padrão é FALSE. suportado em PARSER_VERSION='2.0'. Se TRUE, os nomes das colunas serão lidos a partir da primeira linha de acordo com o argumento FIRSTROW. Se TRUE e esquema for especificado usando WITH, a vinculação de nomes de coluna será feita pelo nome da coluna, não por posições ordinais.
DATAFILETYPE = { 'char' | 'widechar' }
Especifica a codificação: char é usado para UTF8, widechar é usado para arquivos UTF16.
CODEPAGE = { 'ACP' | 'OEM' | 'CRU' | 'code_page' }
Especifica a página de código dos dados no arquivo de dados. O valor padrão é 65001 (codificação UTF-8). Veja mais detalhes sobre esta opção aqui.
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}'
Essa opção desabilitará a verificação de modificação de arquivo durante a execução da consulta e lerá os arquivos que são atualizados enquanto a consulta está em execução. Essa opção é útil quando você precisa ler arquivos somente acréscimo que são acrescentados enquanto a consulta está em execução. Nos arquivos anexáveis, o conteúdo existente não é atualizado e apenas novas linhas são adicionadas. Portanto, a probabilidade de resultados errados é minimizada em comparação com os arquivos atualizáveis. Essa opção pode permitir que você leia os arquivos anexados com freqüência sem manipular os erros. Veja mais informações na seção Consultando arquivos CSV anexáveis.
Opções de rejeição
Nota
O recurso de linhas rejeitadas está em Visualização pública. Observe que o recurso de linhas rejeitadas funciona para arquivos de texto delimitados e PARSER_VERSION 1.0.
Você pode especificar parâmetros de rejeição que determinam como o serviço lidará com registros sujos recuperados da fonte de dados externa. Um registro de dados é considerado "sujo" se os tipos de dados reais não corresponderem às definições de coluna da tabela externa.
Quando você não especifica ou altera as opções de rejeição, o serviço usa valores padrão. O serviço usará as opções de rejeição para determinar o número de linhas que podem ser rejeitadas antes que a consulta real falhe. A consulta retornará resultados (parciais) até que o limite de rejeição seja excedido. Em seguida, ele falha com a mensagem de erro apropriada.
MAXERRORS = reject_value
Especifica o número de linhas que podem ser rejeitadas antes que a consulta falhe. MAXERRORS deve ser um número inteiro entre 0 e 2.147.483.647.
ERRORFILE_DATA_SOURCE = fonte de dados
Especifica a fonte de dados onde as linhas rejeitadas e o arquivo de erro correspondente devem ser gravados.
ERRORFILE_LOCATION = Localização do Diretório
Especifica o diretório dentro do DATA_SOURCE, ou ERROR_FILE_DATASOURCE se especificado, que as linhas rejeitadas e o arquivo de erro correspondente devem ser gravados. Se o caminho especificado não existir, o serviço criará um em seu nome. Um diretório filho é criado com o nome "rejectedrows". O caractere "" garante que o diretório seja escapado para outro processamento de dados, a menos que explicitamente nomeado no parâmetro location. Dentro deste diretório, há uma pasta criada com base no tempo de envio de carga no formato YearMonthDay_HourMinuteSecond_StatementID (Ex. 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891). Você pode usar a id da instrução para correlacionar a pasta com a consulta que a gerou. Nesta pasta, dois arquivos são gravados: error.json arquivo e o arquivo de dados.
error.json arquivo contém matriz json com erros encontrados relacionados a linhas rejeitadas. Cada elemento que representa o erro contém os seguintes atributos:
| Atributo | Description |
|---|---|
| Erro | Razão pela qual a linha é rejeitada. |
| Linha | Número ordinal da linha rejeitado no arquivo. |
| Column | Número ordinal da coluna rejeitado. |
| Value | Valor da coluna rejeitado. Se o valor for maior que 100 caracteres, somente os primeiros 100 caracteres serão exibidos. |
| Ficheiro | Caminho para o arquivo ao qual essa linha pertence. |
Análise rápida de texto delimitado
Há duas versões delimitadas do analisador de texto que você pode usar. O analisador CSV versão 1.0 é padrão e rico em recursos, enquanto o analisador versão 2.0 foi criado para desempenho. A melhoria de desempenho no analisador 2.0 vem de técnicas avançadas de análise e multi-threading. A diferença na velocidade será maior à medida que o tamanho do arquivo crescer.
Descoberta automática de esquema
Você pode facilmente consultar arquivos CSV e Parquet sem conhecer ou especificar o esquema omitindo a cláusula WITH. Nomes de colunas e tipos de dados serão inferidos a partir de arquivos.
Os arquivos Parquet contêm metadados de coluna, que serão lidos, mapeamentos de tipo podem ser encontrados em mapeamentos de tipo para Parquet. Verifique a leitura de arquivos do Parquet sem especificar o esquema para amostras.
Para os arquivos CSV, os nomes das colunas podem ser lidos na linha de cabeçalho. Você pode especificar se a linha de cabeçalho existe usando HEADER_ROW argumento. Se HEADER_ROW = FALSE, serão utilizados nomes genéricos de colunas: C1, C2, ... Cn onde n é o número de colunas no arquivo. Os tipos de dados serão inferidos a partir das primeiras 100 linhas de dados. Verifique a leitura de arquivos CSV sem especificar o esquema para amostras.
Tenha em mente que, se você estiver lendo o número de arquivos ao mesmo tempo, o esquema será inferido a partir do primeiro serviço de arquivos obtido do armazenamento. Isso pode significar que algumas das colunas esperadas são omitidas, tudo porque o arquivo usado pelo serviço para definir o esquema não continha essas colunas. Nesse caso, use a cláusula OPENROWSET WITH.
Importante
Há casos em que o tipo de dados apropriado não pode ser inferido devido à falta de informações e o tipo de dados maior será usado. Isso traz sobrecarga de desempenho e é particularmente importante para colunas de caracteres que serão inferidas como varchar(8000). Para um desempenho ideal, verifique os tipos de dados inferidos e use os tipos de dados apropriados.
Mapeamento de tipo para Parquet
Os arquivos Parquet e Delta Lake contêm descrições de tipo para cada coluna. A tabela a seguir descreve como os tipos de Parquet são mapeados para tipos nativos do SQL.
| Tipo de parquet | Tipo lógico de Parquet (anotação) | Tipo de dados SQL |
|---|---|---|
| BOOLEANO | bit | |
| BINÁRIO / BYTE_ARRAY | Varbinary | |
| DUPLO | flutuante | |
| FLUTUAR | real | |
| INT32 | número inteiro | |
| INT64 | bigint | |
| INT96 | datetime2 | |
| FIXED_LEN_BYTE_ARRAY | binário | |
| BINÁRIO | UTF8 | varchar *(agrupamento UTF8) |
| BINÁRIO | STRING | varchar *(agrupamento UTF8) |
| BINÁRIO | ENUM | varchar *(agrupamento UTF8) |
| FIXED_LEN_BYTE_ARRAY | UUID | uniqueidentifier |
| BINÁRIO | DECIMAL | decimal |
| BINÁRIO | JSON | varchar(8000) *(agrupamento UTF8) |
| BINÁRIO | BSON | Não suportado |
| FIXED_LEN_BYTE_ARRAY | DECIMAL | decimal |
| BYTE_ARRAY | INTERVALO | Não suportado |
| INT32 | INT(8, verdadeiro) | smallint |
| INT32 | INT(16, verdadeiro) | smallint |
| INT32 | INT(32, verdadeiro) | número inteiro |
| INT32 | INT(8, falso) | tinyint |
| INT32 | INT(16, falso) | número inteiro |
| INT32 | INT(32, falso) | bigint |
| INT32 | DATE | data |
| INT32 | DECIMAL | decimal |
| INT32 | TEMPO (MILIS) | hora |
| INT64 | INT(64, verdadeiro) | bigint |
| INT64 | INT(64, falso) | decimal(20,0) |
| INT64 | DECIMAL | decimal |
| INT64 | TEMPO (MICROS) | hora |
| INT64 | TEMPO (NANOS) | Não suportado |
| INT64 | TIMESTAMP (normalizado para utc) (MILLIS / MICROS) | datetime2 |
| INT64 | TIMESTAMP (não normalizado para utc) (MILLIS / MICROS) | BIGINT - Certifique-se de ajustar explicitamente bigint o valor com o deslocamento de fuso horário antes de convertê-lo em um valor datetime. |
| INT64 | CARIMBO DE DATA/HORA (NANOS) | Não suportado |
| Tipo complexo | LISTA | varchar(8000), serializado em JSON |
| Tipo complexo | MAPA | varchar(8000), serializado em JSON |
Exemplos
Ler arquivos CSV sem especificar esquema
O exemplo a seguir lê o arquivo CSV que contém a linha de cabeçalho sem especificar nomes de coluna e tipos de dados:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
O exemplo a seguir lê o arquivo CSV que não contém linha de cabeçalho sem especificar nomes de coluna e tipos de dados:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
Ler arquivos do Parquet sem especificar o esquema
O exemplo a seguir retorna todas as colunas da primeira linha do conjunto de dados do censo, no formato Parquet e sem especificar nomes de colunas e tipos de dados:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
Ler arquivos Delta Lake sem especificar esquema
O exemplo a seguir retorna todas as colunas da primeira linha do conjunto de dados do censo, no formato Delta Lake e sem especificar nomes de colunas e tipos de dados:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
Ler colunas específicas do arquivo CSV
O exemplo a seguir retorna apenas duas colunas com números ordinais 1 e 4 dos arquivos population*.csv. Como não há nenhuma linha de cabeçalho nos arquivos, ele começa a ler a partir da primeira linha:
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
Ler colunas específicas do arquivo Parquet
O exemplo a seguir retorna apenas duas colunas da primeira linha do conjunto de dados do censo, no formato Parquet:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
Especificar colunas usando caminhos JSON
O exemplo a seguir mostra como você pode usar expressões de caminho JSON na cláusula WITH e demonstra a diferença entre os modos de caminho estrito e lax:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
Especificar vários arquivos/pastas no caminho BULK
O exemplo a seguir mostra como você pode usar vários caminhos de arquivo/pasta no parâmetro BULL:
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
Próximos passos
Para obter mais exemplos, consulte o início rápido do armazenamento de dados de consulta para saber como usar OPENROWSET para ler formatos de arquivo CSV, PARQUET, DELTA LAKE e JSON. Verifique as melhores práticas para alcançar o desempenho ideal. Você também pode aprender como salvar os resultados da sua consulta no Armazenamento do Azure usando o CETAS.