Utilizar .NET para Apache Spark com o Azure Synapse Analytics
O .NET para Apache Spark fornece suporte .NET gratuito, de código aberto e multiplataforma para o Spark.
Ele fornece ligações .NET para o Spark, que permite acessar APIs do Spark por meio de C# e F#. Com o .NET para Apache Spark, você também pode escrever e executar funções definidas pelo usuário para o Spark escritas em .NET. As APIs do .NET para Spark permitem que você acesse todos os aspetos do Spark DataFrames que ajudam a analisar seus dados, incluindo Spark SQL, Delta Lake e Structured Streaming.
Você pode analisar dados com o .NET para Apache Spark por meio de definições de trabalho em lote do Spark ou com blocos de anotações interativos do Azure Synapse Analytics. Neste artigo, você aprenderá a usar o .NET para Apache Spark com o Azure Synapse usando ambas as técnicas.
Importante
O .NET para Apache Spark é um projeto de código aberto sob o .NET Foundation que atualmente requer a biblioteca .NET 3.1, que atingiu o status de fora do suporte. Gostaríamos de informar os usuários do Azure Synapse Spark sobre a remoção da biblioteca .NET for Apache Spark no Azure Synapse Runtime for Apache Spark versão 3.3. Os usuários podem consultar a Política de Suporte do .NET para obter mais detalhes sobre esse assunto.
Como resultado, não será mais possível para os usuários utilizar APIs do Apache Spark via C# e F#, ou executar código C# em notebooks dentro do Synapse ou através de definições do Apache Spark Job no Synapse. É importante observar que essa alteração afeta apenas o Azure Synapse Runtime para Apache Spark 3.3 e superior.
Continuaremos a oferecer suporte ao .NET para Apache Spark em todas as versões anteriores do Azure Synapse Runtime de acordo com seus estágios de ciclo de vida. No entanto, não temos planos de oferecer suporte ao .NET para Apache Spark no Azure Synapse Runtime para Apache Spark 3.3 e versões futuras. Recomendamos que os usuários com cargas de trabalho existentes escritas em C# ou F# migrem para Python ou Scala. Os utilizadores são aconselhados a tomar nota desta informação e planear em conformidade.
Enviar trabalhos em lote usando a definição de trabalho do Spark
Visite o tutorial para saber como usar o Azure Synapse Analytics para criar definições de trabalho do Apache Spark para pools do Synapse Spark. Se você não empacotou seu aplicativo para enviar ao Azure Synapse, conclua as etapas a seguir.
Configure as dependências do aplicativo para compatibilidade com o
dotnetSynapse Spark. A versão necessária do .NET Spark será anotada na interface do Synapse Studio na configuração do Apache Spark Pool, na caixa de ferramentas Gerenciar.
Crie seu projeto como um aplicativo de console .NET que produz um executável Ubuntu x86.
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>netcoreapp3.1</TargetFramework> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.Spark" Version="2.1.0" /> </ItemGroup> </Project>Execute os seguintes comandos para publicar seu aplicativo. Certifique-se de substituir mySparkApp pelo caminho para seu aplicativo.
cd mySparkApp dotnet publish -c Release -f netcoreapp3.1 -r ubuntu.18.04-x64Compacte o conteúdo da pasta de publicação, por exemplo,
publish.zipque foi criada como resultado da Etapa 1. Todos os assemblies devem estar na raiz do arquivo ZIP e não deve haver nenhuma camada de pasta intermediária. Isso significa que, quando você descompactapublish.zip, todos os assemblies são extraídos para o diretório de trabalho atual.No Windows:
Usando o Windows PowerShell ou o PowerShell 7, crie um .zip a partir do conteúdo do diretório de publicação.
Compress-Archive publish/* publish.zip -UpdateNo Linux:
Abra um shell bash e cd no diretório bin com todos os binários publicados e execute o seguinte comando.
zip -r publish.zip
.NET para Apache Spark em blocos de anotações do Azure Synapse Analytics
Os notebooks são uma ótima opção para prototipar seus pipelines e cenários do .NET para Apache Spark. Você pode começar a trabalhar, entender, filtrar, exibir e visualizar seus dados de forma rápida e eficiente.
Engenheiros de dados, cientistas de dados, analistas de negócios e engenheiros de aprendizado de máquina podem colaborar em um documento compartilhado e interativo. Você vê os resultados imediatos da exploração de dados e pode visualizar seus dados no mesmo bloco de anotações.
Como usar o .NET para notebooks Apache Spark
Ao criar um novo bloco de anotações, você escolhe um kernel de linguagem que deseja expressar sua lógica de negócios. O suporte ao kernel está disponível para várias linguagens, incluindo C#.
Para usar o .NET para Apache Spark em seu bloco de anotações do Azure Synapse Analytics, selecione .NET Spark (C#) como seu kernel e anexe o bloco de anotações a um pool Apache Spark sem servidor existente.
O bloco de anotações do .NET Spark é baseado nas experiências interativas do .NET e fornece experiências interativas em C# com a capacidade de usar o .NET para Spark pronto para uso com a variável spark de sessão do Spark já predefinida.
Instalar pacotes NuGet em blocos de anotações
Você pode instalar pacotes NuGet de sua escolha em seu bloco de anotações usando o #r nuget comando magic antes do nome do pacote NuGet. O diagrama a seguir mostra um exemplo:
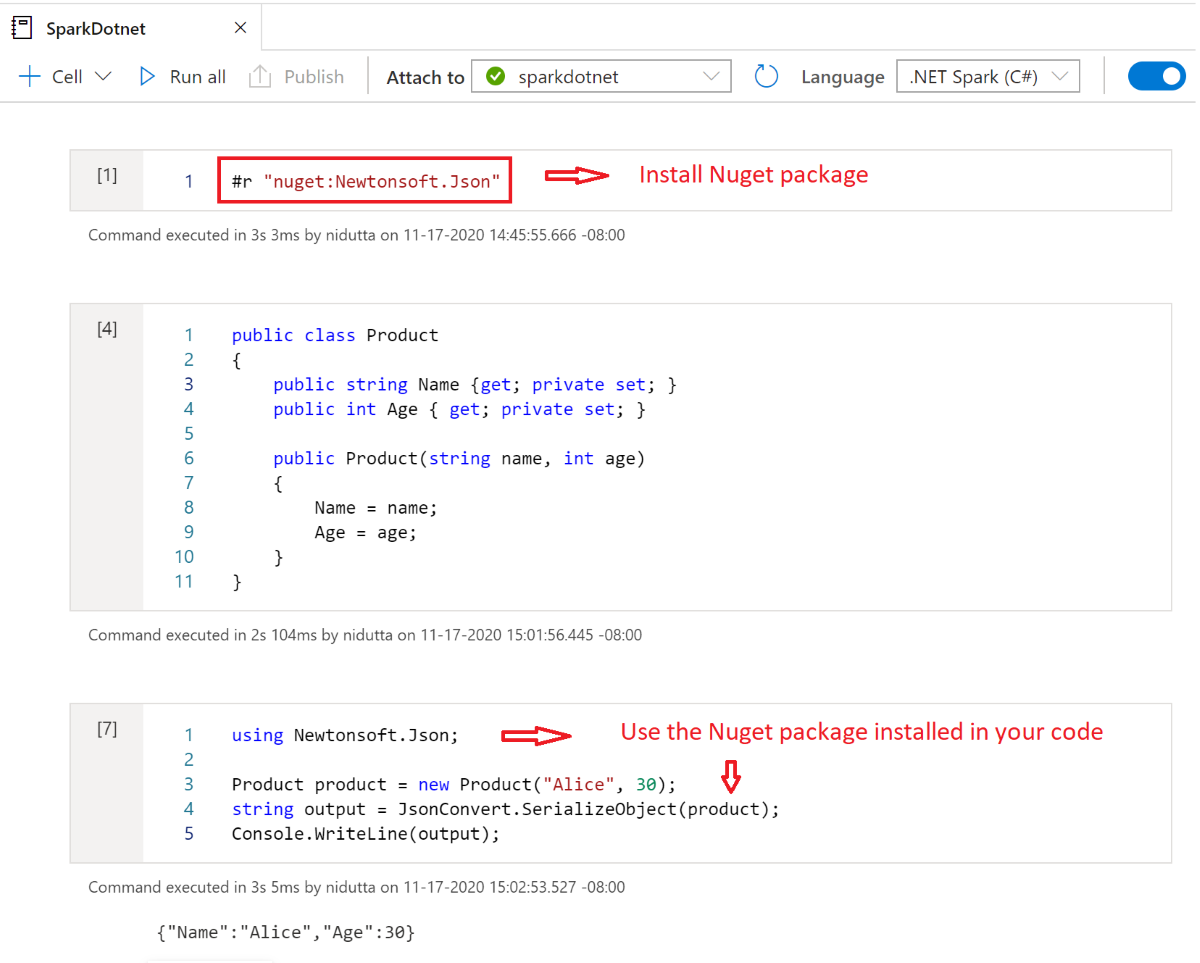
Para saber mais sobre como trabalhar com pacotes NuGet em blocos de anotações, consulte a Documentação interativa do .NET.
Funcionalidades do kernel em C# do .NET para Apache Spark
Os seguintes recursos estão disponíveis quando você usa o .NET para Apache Spark no bloco de anotações do Azure Synapse Analytics:
- HTML declarativo: gere saída de suas células usando sintaxe HTML, como cabeçalhos, listas com marcadores e até mesmo exibição de imagens.
- Instruções C# simples (como atribuições, impressão no console, lançamento de exceções e assim por diante).
- Blocos de código C# de várias linhas (como instruções if, loops foreach, definições de classe e assim por diante).
- Acesso à biblioteca C# padrão (como System, LINQ, Enumerables e assim por diante).
- Suporte para recursos de linguagem C# 8.0.
sparkcomo uma variável predefinida para lhe dar acesso à sua sessão do Apache Spark.- Suporte para definir funções definidas pelo usuário .NET que podem ser executadas no Apache Spark. Recomendamos escrever e chamar UDFs no .NET para ambientes Apache Spark Interactive para aprender a usar UDFs no .NET para experiências do Apache Spark Interactive.
- Suporte para visualizar a saída de seus trabalhos do Spark usando gráficos diferentes (como linha, barra ou histograma) e layouts (como único, sobreposto e assim por diante) usando a
XPlot.Plotlybiblioteca. - Capacidade de incluir pacotes NuGet em seu bloco de anotações C#.
Resolução de problemas
DotNetRunner: null / Futures timeout em Synapse Spark Job Definition Run
As definições de trabalho do Synapse Spark em pools de faíscas usando o Spark 2.4 exigem Microsoft.Spark 1.0.0. Limpe seus bin diretórios e obj publique o projeto usando 1.0.0.
OutOfMemoryError: espaço de heap java em org.apache.spark
O Dotnet Spark 1.0.0 usa uma arquitetura de depuração diferente da 1.1.1+. Você terá que usar 1.0.0 para sua versão publicada e 1.1.1+ para depuração local.