Gerenciar pacotes com escopo de sessão
Além dos pacotes no nível do pool, você também pode especificar bibliotecas com escopo de sessão no início de uma sessão de bloco de anotações. As bibliotecas com escopo de sessão permitem especificar e usar pacotes Python, jar e R em uma sessão de bloco de anotações.
Ao usar bibliotecas com escopo de sessão, é importante ter em mente os seguintes pontos:
- Quando você instala bibliotecas com escopo de sessão, somente o bloco de anotações atual tem acesso às bibliotecas especificadas.
- Essas bibliotecas não têm impacto em outras sessões ou trabalhos que usam o mesmo pool do Spark.
- Essas bibliotecas são instaladas sobre o tempo de execução básico e as bibliotecas de nível de pool e têm a maior precedência.
- As bibliotecas com escopo de sessão não persistem entre as sessões.
Pacotes Python com escopo de sessão
Gerencie pacotes Python com escopo de sessão por meio environment.yml arquivo
Para especificar pacotes Python com escopo de sessão:
- Navegue até o pool do Spark selecionado e verifique se você habilitou as bibliotecas no nível da sessão. Você pode habilitar essa configuração navegando até a guia Gerenciar>pacotes do pool>do Apache Spark.
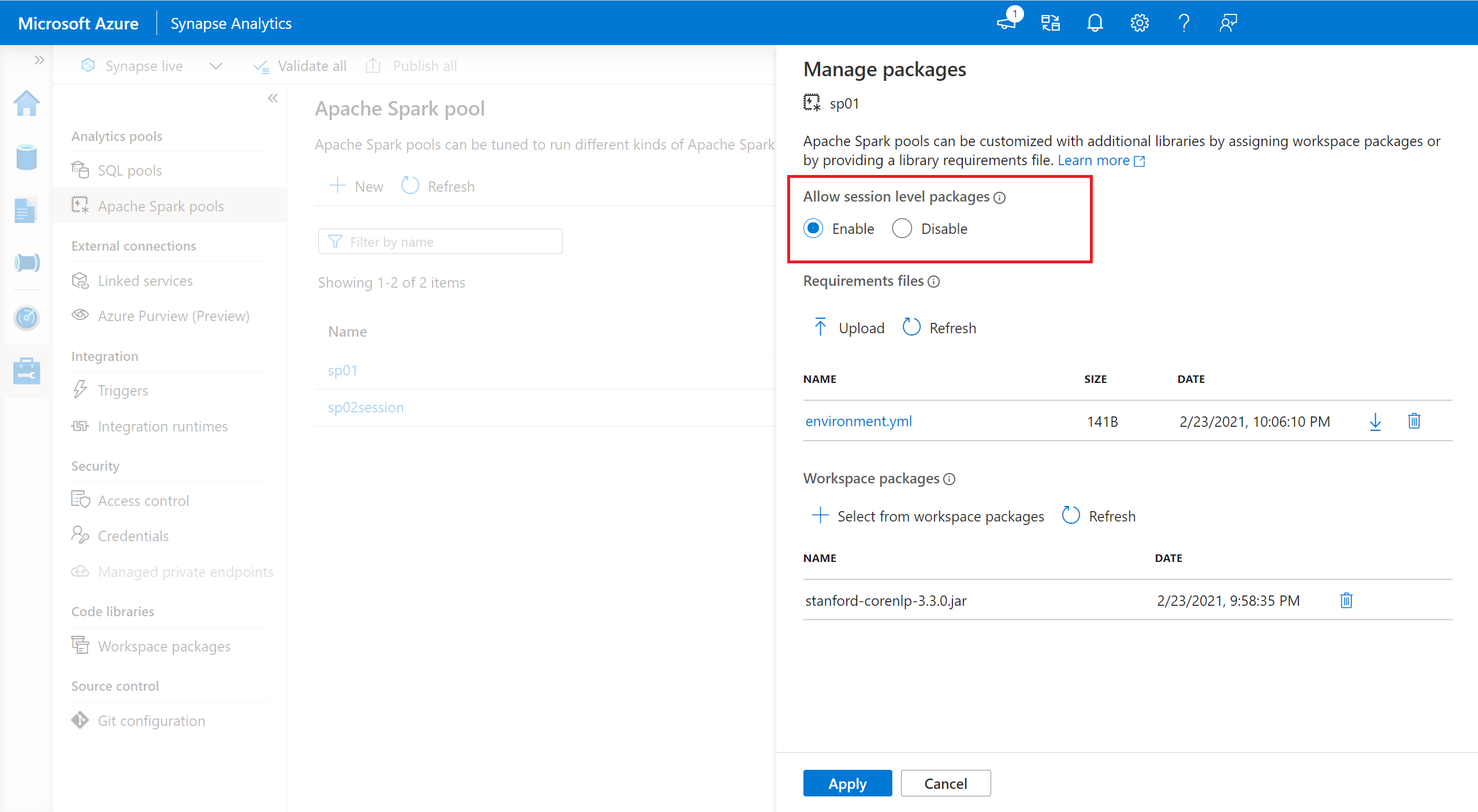
- Quando a configuração se aplicar, você poderá abrir um bloco de anotações e selecionar Configurar Pacotes de Sessão>.

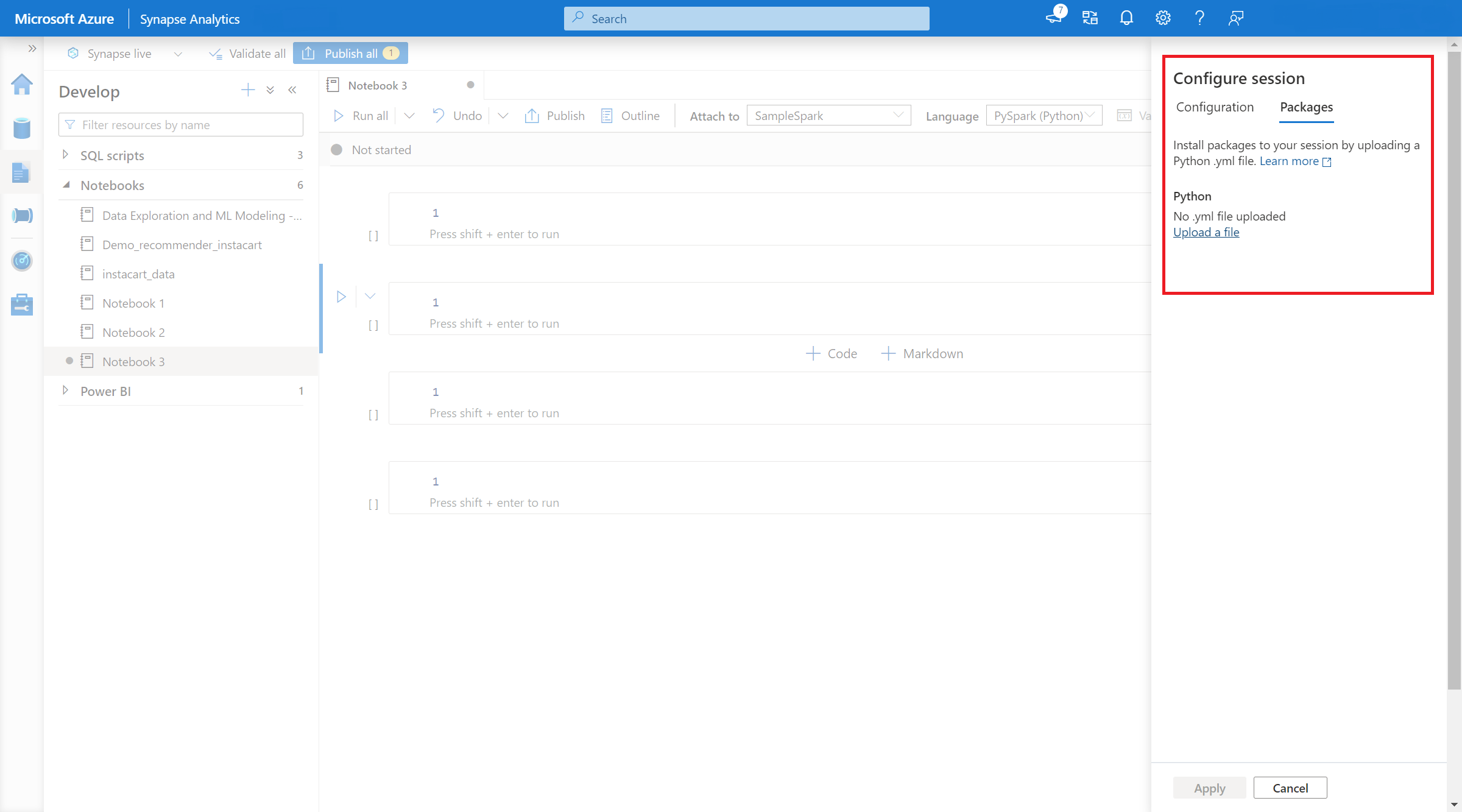
- Aqui, você pode carregar um arquivo Conda environment.yml para instalar ou atualizar pacotes dentro de uma sessão. As bibliotecas especificadas estão presentes quando a sessão é iniciada. Essas bibliotecas não estarão mais disponíveis após o término da sessão.

Gerencie pacotes Python com escopo de sessão por meio dos comandos %pip e %conda
Você pode usar os populares comandos %pip e %conda para instalar bibliotecas de terceiros adicionais ou suas bibliotecas personalizadas durante a sessão do bloco de anotações do Apache Spark. Nesta seção, usamos comandos %pip para demonstrar vários cenários comuns.
Nota
- Recomendamos colocar os comandos %pip e %conda na primeira célula do seu bloco de anotações se quiser instalar novas bibliotecas. O interpretador Python será reiniciado após a biblioteca de nível de sessão ser gerenciada para efetivar as alterações.
- Esses comandos de gerenciamento de bibliotecas Python serão desativados ao executar trabalhos de pipeline. Se quiser instalar um pacote dentro de um pipeline, aproveite os recursos de gerenciamento de biblioteca no nível do pool.
- As bibliotecas Python com escopo de sessão são instaladas automaticamente nos nós de driver e de trabalho.
- Os seguintes comandos %conda não são suportados: create, clean, compare, activate, deactivate, run, package.
- Você pode consultar os comandos %pip e %conda para obter a lista completa de comandos.
Instalar um pacote de terceiros
Você pode instalar facilmente uma biblioteca Python a partir do PyPI.
# Install vega_datasets
%pip install altair vega_datasets
Para verificar o resultado da instalação, você pode executar o código a seguir para visualizar vega_datasets
# Create a scatter plot
# Plot Miles per gallon against the horsepower across different region
import altair as alt
from vega_datasets import data
cars = data.cars()
alt.Chart(cars).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color='Origin',
).interactive()
Instalar um pacote de roda a partir da conta de armazenamento
Para instalar a biblioteca a partir do armazenamento, você precisa montar em sua conta de armazenamento executando os seguintes comandos.
from notebookutils import mssparkutils
mssparkutils.fs.mount(
"abfss://<<file system>>@<<storage account>.dfs.core.windows.net",
"/<<path to wheel file>>",
{"linkedService":"<<storage name>>"}
)
E então, você pode usar o comando %pip install para instalar o pacote wheel necessário
%pip install /<<path to wheel file>>/<<wheel package name>>.whl
Instalar outra versão da biblioteca integrada
Você pode usar o seguinte comando para ver qual é a versão interna de determinado pacote. Usamos os pandas como exemplo
%pip show pandas
O resultado é o seguinte log:
Name: pandas
Version: **1.2.3**
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
... ...
Você pode usar o seguinte comando para alternar pandaspara outra versão, digamos 1.2.4
%pip install pandas==1.2.4
Desinstalar uma biblioteca com escopo de sessão
Se você quiser desinstalar um pacote, que instalado nesta sessão de bloco de anotações, você pode consultar os seguintes comandos. No entanto, não é possível desinstalar os pacotes internos.
%pip uninstall altair vega_datasets --yes
Usando o comando %pip para instalar bibliotecas a partir de um arquivo requirement.txt
%pip install -r /<<path to requirement file>>/requirements.txt
Pacotes Java ou Scala com escopo de sessão
Para especificar pacotes Java ou Scala com escopo de sessão, você pode usar a %%configure opção:
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<file system>>@<<storage account>.dfs.core.windows.net/<<path to JAR file>>",
}
}
Nota
- Recomendamos que execute o %%configure no início do seu bloco de notas. Você pode consultar este documento para obter a lista completa de parâmetros válidos.
Pacotes R com escopo de sessão (Visualização)
Os pools do Azure Synapse Analytics incluem muitas bibliotecas R populares prontas para uso. Você também pode instalar bibliotecas extras de terceiros durante a sessão do seu bloco de anotações Apache Spark.
Nota
- Esses comandos de gerenciamento de bibliotecas R serão desabilitados ao executar trabalhos de pipeline. Se quiser instalar um pacote dentro de um pipeline, aproveite os recursos de gerenciamento de biblioteca no nível do pool.
- As bibliotecas R com escopo de sessão são instaladas automaticamente nos nós de driver e de trabalho.
Instalar um pacote
Você pode facilmente instalar uma biblioteca R a partir do CRAN.
# Install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
Você também pode usar instantâneos de CRAN como o repositório para garantir o download da mesma versão do pacote todas as vezes.
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
Usando devtools para instalar pacotes
A devtools biblioteca simplifica o desenvolvimento de pacotes para agilizar tarefas comuns. Essa biblioteca é instalada dentro do tempo de execução padrão do Azure Synapse Analytics.
Você pode usar devtools para especificar uma versão específica de uma biblioteca para instalar. Essas bibliotecas serão instaladas em todos os nós dentro do cluster.
# Install a specific version.
install_version("caesar", version = "1.0.0")
Da mesma forma, você pode instalar uma biblioteca diretamente do GitHub.
# Install a GitHub library.
install_github("jtilly/matchingR")
Atualmente, as seguintes devtools funções são suportadas no Azure Synapse Analytics:
| Comando | Description |
|---|---|
| install_github() | Instala um pacote R do GitHub |
| install_gitlab() | Instala um pacote R do GitLab |
| install_bitbucket() | Instala um pacote R do Bitbucket |
| install_url() | Instala um pacote R a partir de um URL arbitrário |
| install_git() | Instala a partir de um repositório git arbitrário |
| install_local() | Instala a partir de um arquivo local no disco |
| install_version() | Instala a partir de uma versão específica na CRAN |
Ver bibliotecas instaladas
Você pode consultar todas as bibliotecas instaladas em sua sessão usando o library comando.
library()
Você pode usar a packageVersion função para verificar a versão da biblioteca:
packageVersion("caesar")
Remover um pacote R de uma sessão
Você pode usar a detach função para remover uma biblioteca do namespace. Essas bibliotecas permanecem no disco até serem carregadas novamente.
# detach a library
detach("package: caesar")
Para remover um pacote com escopo de sessão de um bloco de anotações, use o remove.packages() comando. Essa alteração de biblioteca não tem impacto em outras sessões no mesmo cluster. Os usuários não podem desinstalar ou remover bibliotecas internas do tempo de execução padrão do Azure Synapse Analytics.
remove.packages("caesar")
Nota
Não é possível remover pacotes principais como SparkR, SparklyR ou R.
Bibliotecas R com escopo de sessão e SparkR
As bibliotecas com escopo de notebook estão disponíveis nos trabalhadores do SparkR.
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
Bibliotecas R com escopo de sessão e SparklyR
Com spark_apply() no SparklyR, você pode usar qualquer pacote R dentro do Spark. Por padrão, em sparklyr::spark_apply(), o argumento packages é definido como FALSE. Isso copia bibliotecas no libPaths atual para os trabalhadores, permitindo que você as importe e use em trabalhadores. Por exemplo, você pode executar o seguinte para gerar uma mensagem criptografada por césar com sparklyr::spark_apply():
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- "3.2"
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
Próximos passos
- Veja as bibliotecas padrão: Suporte à versão do Apache Spark
- Gerencie os pacotes fora do portal Synapse Studio: gerencie pacotes por meio de comandos Az e APIs REST