Segurança, acesso e operações para migrações Teradata
Este artigo é a terceira parte de uma série de sete partes que fornece orientação sobre como migrar do Teradata para o Azure Synapse Analytics. O foco deste artigo são as práticas recomendadas para operações de acesso de segurança.
Considerações de segurança
Este artigo discute os métodos de conexão para ambientes Teradata herdados existentes e como eles podem ser migrados para o Azure Synapse Analytics com risco mínimo e impacto no usuário.
Este artigo pressupõe que há um requisito para migrar os métodos existentes de conexão e estrutura de usuário/função/permissão no estado em que se encontram. Caso contrário, use o portal do Azure para criar e gerenciar um novo regime de segurança.
Para obter mais informações sobre as opções de segurança do Azure Synapse, consulte Whitepaper de segurança.
Conexão e autenticação
Opções de autorização Teradata
Gorjeta
A autenticação no Teradata e no Azure Synapse pode ser "no banco de dados" ou por meio de métodos externos.
O Teradata suporta vários mecanismos de conexão e autorização. Os valores válidos do mecanismo são:
TD1, que seleciona Teradata 1 como o mecanismo de autenticação. Nome de usuário e senha são necessários.
TD2, que seleciona Teradata 2 como o mecanismo de autenticação. Nome de usuário e senha são necessários.
TDNEGO, que seleciona um dos mecanismos de autenticação automaticamente com base na política, sem envolvimento do usuário.
LDAP, que seleciona o protocolo LDAP (Lightweight Directory Access Protocol) como o mecanismo de autenticação. O aplicativo fornece o nome de usuário e senha.
KRB5, que seleciona Kerberos (KRB5) em clientes Windows que trabalham com servidores Windows. Para iniciar sessão utilizando KRB5, o utilizador tem de fornecer um domínio, nome de utilizador e palavra-passe. O domínio é especificado definindo o nome de usuário como
MyUserName@MyDomain.NTLM, que seleciona NTLM em clientes Windows que trabalham com servidores Windows. O aplicativo fornece o nome de usuário e senha.
Kerberos (KRB5), Kerberos Compatibility (KRB5C), NT LAN Manager (NTLM) e NT LAN Manager Compatibility (NTLMC) são apenas para Windows.
Opções de autorização do Azure Synapse
O Azure Synapse dá suporte a duas opções básicas de conexão e autorização:
Autenticação SQL: A autenticação SQL é feita por meio de uma conexão de banco de dados que inclui um identificador de banco de dados, ID de usuário e senha, além de outros parâmetros opcionais. Isso é funcionalmente equivalente a Teradata TD1, TD2 e conexões padrão.
Autenticação do Microsoft Entra: com a autenticação do Microsoft Entra, você pode gerenciar centralmente as identidades dos usuários do banco de dados e outros serviços da Microsoft em um local central. O gerenciamento central de ID fornece um único local para gerenciar usuários do SQL Data Warehouse e simplifica o gerenciamento de permissões. O Microsoft Entra ID também pode suportar conexões com serviços LDAP e Kerberos — por exemplo, o Microsoft Entra ID pode ser usado para se conectar a diretórios LDAP existentes se eles permanecerem em vigor após a migração do banco de dados.
Usuários, funções e permissões
Descrição geral
Gorjeta
Um planeamento de alto nível é essencial para um projeto de migração bem-sucedido.
Tanto o Teradata quanto o Azure Synapse implementam o controle de acesso ao banco de dados por meio de uma combinação de usuários, funções e permissões. Ambos usam SQL CREATE USER padrão e CREATE ROLE instruções para definir usuários e funções, e GRANT REVOKE instruções para atribuir ou remover permissões a esses usuários e/ou funções.
Gorjeta
Recomenda-se a automatização dos processos de migração para reduzir o tempo decorrido e a margem de erro.
Conceitualmente, os dois bancos de dados são semelhantes, e pode ser possível automatizar a migração de IDs, funções e permissões de usuário existentes em algum grau. Migre esses dados extraindo as informações de usuário e função herdadas existentes das tabelas de catálogo do sistema Teradata e gerando equivalentes CREATE USER correspondentes e CREATE ROLE instruções a serem executadas no Azure Synapse para recriar a mesma hierarquia de usuário/função.
Após a extração de dados, use tabelas de catálogo do sistema Teradata para gerar instruções equivalentes GRANT para atribuir permissões (onde existir uma equivalente). O diagrama a seguir mostra como usar metadados existentes para gerar o SQL necessário.
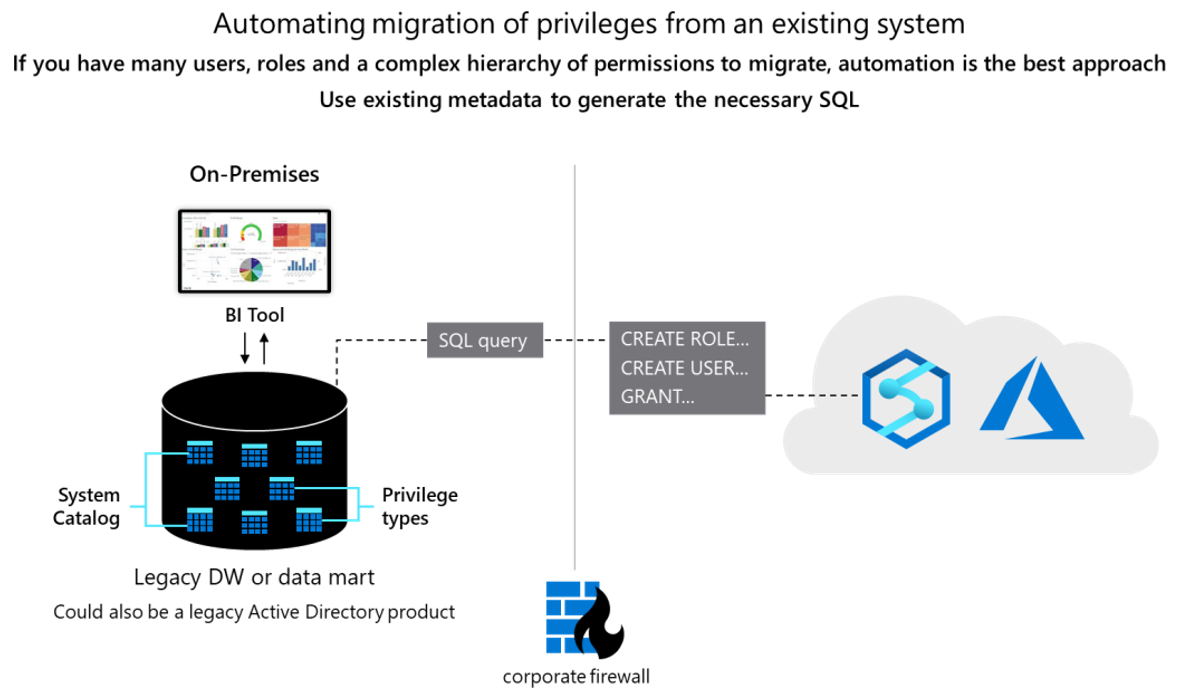
Utilizadores e funções
Gorjeta
A migração de um data warehouse requer mais do que apenas tabelas, exibições e instruções SQL.
As informações sobre usuários e funções atuais em um sistema Teradata são encontradas nas tabelas DBC.USERS de catálogo do sistema (ou DBC.DATABASES) e DBC.ROLEMEMBERS. Consulte essas tabelas (se o usuário tiver SELECT acesso a essas tabelas) para obter listas atuais de usuários e funções definidas no sistema. A seguir estão exemplos de consultas para fazer isso para usuários individuais:
/***SQL to find all users***/
SELECT
DatabaseName AS UserName
FROM DBC.Databases
WHERE dbkind = 'u';
/***SQL to find all roles***/
SELECT A.ROLENAME, A.GRANTEE, A.GRANTOR,
A.DefaultRole,
A.WithAdmin,
B.DATABASENAME,
B.TABLENAME,
B.COLUMNNAME,
B.GRANTORNAME,
B.AccessRight
FROM DBC.ROLEMEMBERS A
JOIN DBC.ALLROLERIGHTS B
ON A.ROLENAME = B.ROLENAME
GROUP BY 1,2,3,4,5,6,7
ORDER BY 2,1,6;
Esses exemplos modificam SELECT instruções para produzir um conjunto de resultados, que é uma série de CREATE USER e CREATE ROLE instruções, incluindo o texto apropriado como um literal dentro da SELECT instrução.
Não há como recuperar senhas existentes, portanto, você precisa implementar um esquema para alocar novas senhas iniciais no Azure Synapse.
Permissões
Gorjeta
Há permissões equivalentes do Azure Synapse para operações básicas de banco de dados, como DML e DDL.
Em um sistema Teradata, o sistema tabelas DBC.ALLRIGHTS e DBC.ALLROLERIGHTS detém os direitos de acesso para usuários e funções. Consulte essas tabelas (se o usuário tiver SELECT acesso a essas tabelas) para obter listas atuais de direitos de acesso definidos no sistema. Seguem-se exemplos de consultas para utilizadores individuais:
/**SQL for AccessRights held by a USER***/
SELECT UserName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantAuthority, GrantorName, AllnessFlag, CreatorName, CreateTimeStamp
FROM DBC.ALLRIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE UserName='UserXYZ'
Order By 2,3,4,5;
/**SQL for AccessRights held by a ROLE***/
SELECT RoleName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantorName, CreateTimeStamp
FROM DBC.ALLROLERIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv
Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE RoleName='BI_DEVELOPER'
Order By 2,3,4,5;
Modifique essas instruções de exemplo SELECT para produzir um conjunto de resultados que seja uma série de GRANT instruções incluindo o texto apropriado como um literal dentro da SELECT instrução.
Use a tabela AccessRightsAbbv para procurar o texto completo do direito de acesso, pois a chave de junção é um campo abreviado 'tipo'. Consulte a tabela a seguir para obter uma lista de direitos de acesso Teradata e seu equivalente no Azure Synapse.
| Nome da permissão Teradata | Tipo de Teradata | Equivalente ao Azure Synapse |
|---|---|---|
| CANCELAR SESSÃO | AS | MATAR CONEXÃO DE BANCO DE DADOS |
| ALTERAR PROCEDIMENTO EXTERNO | AE | 4 |
| FUNÇÃO ALTER | AF | FUNÇÃO ALTER |
| PROCEDIMENTO ALTER | AP | PROCEDIMENTO ALTER |
| PONTO DE VERIFICAÇÃO | CP | PONTO DE VERIFICAÇÃO |
| CRIAR AUTORIZAÇÃO | CA | CRIAR INÍCIO DE SESSÃO |
| CREATE DATABASE | CD | CREATE DATABASE |
| CRIAR PROCEDIMENTO EXTERNO | CE | 4 |
| CREATE FUNCTION | CF | CREATE FUNCTION |
| CRIAR GLOP | GC | 3 |
| CRIAR MACRO | CM | CRIAR PROCEDIMENTO 2 |
| PROCEDIMENTO DE CRIAÇÃO DE PROPRIETÁRIO | PO | CRIAR PROCEDIMENTO |
| CRIAR PROCEDIMENTO | PC | CRIAR PROCEDIMENTO |
| CRIAR PERFIL | CO | CRIAR LOGIN 1 |
| CRIAR FUNÇÃO | CR | CRIAR FUNÇÃO |
| DROP DATABASE | DD | DROP DATABASE |
| DROP FUNCTION | DF | DROP FUNCTION |
| GOTA DE GLOP | GD | 3 |
| SOLTAR MACRO | DM | PROCEDIMENTO DE QUEDA 2 |
| PROCEDIMENTO DE QUEDA | DP | SUPRIMIR O PROCEDIMENTO |
| PERFIL DE QUEDA | DO | LARGAR LOGIN 1 |
| DROP ROLE | DR | EXCLUIR FUNÇÃO |
| DROP TABLE | DT | DROP TABLE |
| GATILHO DE QUEDA | DG | 3 |
| DROP USUÁRIO | DU | DROP USUÁRIO |
| DROP VIEW | DV | DROP VIEW |
| DESPEJO | DP | 4 |
| EXECUTAR | E | EXECUTAR |
| EXECUTAR FUNÇÃO | EF | EXECUTAR |
| PROCEDIMENTO DE EXECUÇÃO | PE | EXECUTAR |
| MEMBRO GLOP | GM | 3 |
| ÍNDICE | IX | CREATE INDEX |
| INSERT | I | INSERT |
| MONRESOURCE | MR | 5 |
| SEGUNDA-FEIRA | MS | 5 |
| SUBSTITUIR RESTRIÇÃO DE DESPEJO | OA | 4 |
| SUBSTITUIR RESTRIÇÃO DE RESTAURAÇÃO | OU | 4 |
| REFERÊNCIAS | RF | REFERÊNCIAS |
| REPLCONTROL | RO | 5 |
| RESTAURAR | RS | 4 |
| SELECT | R | SELECIONAR |
| SETRESRATE | SR | 5 |
| SETSESSRATE | SS | 5 |
| PROGRAMA | SH | 3 |
| UPDATE | U | ATUALIZAR |
AccessRightsAbbv Notas da tabela:
Teradata
PROFILEé funcionalmente equivalente aoLOGINAzure Synapse.A tabela a seguir resume as diferenças entre macros e procedimentos armazenados no Teradata. No Azure Synapse, os procedimentos fornecem a funcionalidade descrita na tabela.
Macro Procedimento armazenado Contém SQL Contém SQL Pode conter comandos de ponto BTEQ Contém SPL abrangente Pode receber valores de parâmetros passados para ele Pode receber valores de parâmetros passados para ele Pode recuperar uma ou mais linhas Deve usar um cursor para recuperar mais de uma linha Armazenado no espaço DBC PERM Armazenado em DATABASE ou USER PERM Retorna linhas para o cliente Pode retornar um ou mais valores para o cliente como parâmetros SHOW,GLOPeTRIGGERnão têm equivalente direto no Azure Synapse.Esses recursos são gerenciados automaticamente pelo sistema no Azure Synapse. Consulte Considerações operacionais.
No Azure Synapse, esses recursos são manipulados fora do banco de dados.
Para obter mais informações sobre direitos de acesso no Azure Synapse, consulte Permissões de segurança do Azure Synapse Analytics.
Considerações operacionais
Gorjeta
As tarefas operacionais são necessárias para manter qualquer armazém de dados a funcionar de forma eficiente.
Esta seção discute como implementar tarefas operacionais típicas do Teradata no Azure Synapse com risco e impacto mínimos para os usuários.
Tal como acontece com todos os produtos de armazém de dados, uma vez em produção, há tarefas de gestão contínuas que são necessárias para manter o sistema a funcionar de forma eficiente e para fornecer dados para monitorização e auditoria. A utilização de recursos e o planejamento de capacidade para crescimento futuro também se enquadram nessa categoria, assim como o backup/restauração de dados.
Embora conceitualmente as tarefas de gerenciamento e operações para diferentes armazéns de dados sejam semelhantes, as implementações individuais podem diferir. Em geral, os produtos modernos baseados na nuvem, como o Azure Synapse, tendem a incorporar uma abordagem mais automatizada e "gerenciada pelo sistema" (em oposição a uma abordagem mais "manual" em data warehouses herdados, como o Teradata).
As seções a seguir comparam as opções do Teradata e do Azure Synapse para várias tarefas operacionais.
Tarefas domésticas
Gorjeta
As tarefas de limpeza mantêm um armazém de produção a funcionar de forma eficiente e otimizam a utilização de recursos como o armazenamento.
Na maioria dos ambientes de data warehouse legados, há um requisito para executar tarefas regulares de "limpeza", como recuperar espaço de armazenamento em disco que pode ser liberado removendo versões antigas de linhas atualizadas ou excluídas ou reorganizando arquivos de log de dados ou blocos de índice para eficiência. A recolha de estatísticas é também uma tarefa potencialmente demorada. A coleta de estatísticas é necessária após a ingestão de dados em massa para fornecer ao otimizador de consulta dados atualizados para a geração base de planos de execução de consulta.
A Teradata recomenda a recolha de estatísticas da seguinte forma:
Colete estatísticas em tabelas não preenchidas para configurar o histograma de intervalo usado no processamento interno. Esta recolha inicial torna as recolhas de estatísticas subsequentes mais rápidas. Certifique-se de que recolhe novamente as estatísticas depois de os dados serem adicionados.
Colete estatísticas de fase de protótipo para tabelas recém-preenchidas.
Colete estatísticas da fase de produção após uma porcentagem significativa de alteração na tabela ou partição (~10% das linhas). Para grandes volumes de valores não exclusivos, como datas ou carimbos de data/hora, pode ser vantajoso relembrar a 7%.
Colete estatísticas da fase de produção depois de criar usuários e aplicar cargas de consulta do mundo real ao banco de dados (até cerca de três meses de consulta).
Colete estatísticas nas primeiras semanas após uma atualização ou migração durante períodos de baixa utilização da CPU.
A coleta de estatísticas pode ser gerenciada manualmente usando APIs abertas do Automated Statistics Management ou automaticamente usando o portlet Teradata Viewpoint Stats Manager.
Gorjeta
Automatize e monitore tarefas de limpeza no Azure.
O Banco de Dados Teradata contém muitas tabelas de log no Dicionário de Dados que acumulam dados, automaticamente ou depois que determinados recursos são habilitados. Como os dados de log crescem com o tempo, limpe as informações mais antigas para evitar o uso de espaço permanente. Há opções disponíveis para automatizar a manutenção desses logs. As tabelas do dicionário Teradata que requerem manutenção são discutidas a seguir.
Tabelas de dicionário para manter
Redefina acumuladores e valores de pico usando a DBC.AMPUsage visualização e a ClearPeakDisk macro fornecidas com o software:
DBC.Acctg: utilização de recursos por conta/utilizadorDBC.DataBaseSpace: contabilidade de banco de dados e espaço de tabela
O Teradata mantém automaticamente essas tabelas, mas as boas práticas podem reduzir seu tamanho:
DBC.AccessRights: direitos de usuário sobre objetosDBC.RoleGrants: direitos de função em objetosDBC.Roles: funções definidasDBC.Accounts: códigos de conta por utilizador
Arquive essas tabelas de registro (se desejar) e limpe as informações de 60 a 90 dias de idade. A retenção depende dos requisitos do cliente:
DBC.SW_Event_Log: log do console do banco de dadosDBC.ResUsage: tabelas de monitoramento de recursosDBC.EventLog: histórico de logon/logoff da sessãoDBC.AccLogTbl: eventos de usuário/objeto registradosDBC.DBQL tables: usuário registrado/atividade SQL.NETSecPolicyLogTbl: registra trilhas de auditoria de políticas de segurança dinâmicas.NETSecPolicyLogRuleTbl: Controla quando e como a diretiva de segurança dinâmica é registrada
Limpe estas tabelas quando a mídia removível associada expirar e for substituída:
DBC.RCEvent: Eventos de arquivamento/recuperaçãoDBC.RCConfiguration: configuração de arquivamento/recuperaçãoDBC.RCMedia: VolSerial para arquivamento/recuperação
O Azure Synapse tem uma opção para criar estatísticas automaticamente para que elas possam ser usadas conforme necessário. Execute a desfragmentação de índices e blocos de dados manualmente, de forma programada ou automaticamente. Aproveitar os recursos internos nativos do Azure pode reduzir o esforço necessário em um exercício de migração.
Monitorização e auditoria
Gorjeta
Ao longo do tempo, várias ferramentas diferentes foram implementadas para permitir o monitoramento e registro de sistemas Teradata.
A Teradata fornece várias ferramentas para monitorar a operação, incluindo o Teradata Viewpoint e o Ecosystem Manager. Para registrar o histórico de consultas, o DBQL (Database Query Log) é um recurso de banco de dados Teradata que fornece uma série de tabelas predefinidas que podem armazenar registros históricos de consultas e sua duração, desempenho e atividade de destino com base em regras definidas pelo usuário.
Os administradores de banco de dados podem usar o Teradata Viewpoint para determinar o status do sistema, as tendências e o status da consulta individual. Ao observar as tendências no uso do sistema, os administradores de sistema são mais capazes de planejar implementações de projetos, trabalhos em lote e manutenção para evitar períodos de pico de uso. Os usuários corporativos podem usar o Teradata Viewpoint para acessar rapidamente o status de relatórios e consultas e detalhar detalhes.
Gorjeta
O portal do Azure fornece uma interface do usuário para gerenciar tarefas de monitoramento e auditoria para todos os dados e processos do Azure.
Da mesma forma, o Azure Synapse fornece uma experiência de monitoramento avançada no portal do Azure para fornecer informações sobre sua carga de trabalho de data warehouse. O portal do Azure é a ferramenta recomendada ao monitorar seu data warehouse, pois fornece períodos de retenção configuráveis, alertas, recomendações e gráficos e painéis personalizáveis para métricas e logs.
O portal também permite a integração com outros serviços de monitoramento do Azure, como o Operations Management Suite (OMS) e o Azure Monitor (logs), para fornecer uma experiência de monitoramento holística não apenas para o data warehouse, mas também para toda a plataforma de análise do Azure para uma experiência de monitoramento integrada.
Gorjeta
As métricas de baixo nível e em todo o sistema são automaticamente registradas no Azure Synapse.
As estatísticas de utilização de recursos para o Azure Synapse são automaticamente registradas no sistema. As métricas para cada consulta incluem estatísticas de uso para CPU, memória, cache, E/S e espaço de trabalho temporário, bem como informações de conectividade, como tentativas de conexão com falha.
O Azure Synapse fornece um conjunto de Exibições de Gerenciamento Dinâmico (DMVs). Essas exibições são úteis ao solucionar ativamente a solução de problemas e identificar gargalos de desempenho com sua carga de trabalho.
Para obter mais informações, consulte Opções de gerenciamento e operações do Azure Synapse.
Alta disponibilidade (HA) e recuperação de desastres (DR)
O Teradata implementa recursos como FALLBACKo utilitário ARC (Archive Restore Copy) e o DSA (Data Stream Architecture) para fornecer proteção contra perda de dados e alta disponibilidade (HA) por meio da replicação e arquivamento de dados. As opções de recuperação de desastres (DR) incluem Dual Ative Solution, DR as a service ou um sistema de substituição, dependendo do requisito de tempo de recuperação.
Gorjeta
O Azure Synapse cria instantâneos automaticamente para garantir tempos de recuperação rápidos.
O Azure Synapse usa instantâneos de banco de dados para fornecer alta disponibilidade do depósito. Um instantâneo do data warehouse cria um ponto de restauração que pode ser usado para recuperar ou copiar um data warehouse para um estado anterior. Como o Azure Synapse é um sistema distribuído, um instantâneo de data warehouse consiste em muitos arquivos que estão no Armazenamento do Azure. Os instantâneos capturam alterações incrementais dos dados armazenados em seu data warehouse.
O Azure Synapse tira instantâneos automaticamente ao longo do dia, criando pontos de restauração que ficam disponíveis por sete dias. Este período de retenção não pode ser alterado. O Azure Synapse dá suporte a um RPO (Recovery Point Objetive, objetivo de ponto de recuperação) de oito horas. Um data warehouse pode ser restaurado na região principal a partir de qualquer um dos instantâneos tirados nos últimos sete dias.
Gorjeta
Use instantâneos definidos pelo usuário para definir um ponto de recuperação antes das atualizações de chave.
Os pontos de restauração definidos pelo usuário também são suportados, permitindo o acionamento manual de instantâneos para criar pontos de restauração de um data warehouse antes e depois de grandes modificações. Esse recurso garante que os pontos de restauração sejam logicamente consistentes, o que fornece proteção de dados adicional em caso de interrupções da carga de trabalho ou erros do usuário para um RPO desejado de menos de 8 horas.
Gorjeta
O Microsoft Azure fornece backups automáticos para um local geográfico separado para habilitar a DR.
Além dos instantâneos descritos anteriormente, o Azure Synapse também executa como padrão um backup geográfico uma vez por dia em um data center emparelhado. O RPO para uma restauração geográfica é de 24 horas. Você pode restaurar o backup geográfico para um servidor em qualquer outra região onde o Azure Synapse é suportado. Um backup geográfico garante que um data warehouse possa ser restaurado caso os pontos de restauração na região principal não estejam disponíveis.
Gestão de cargas de trabalho
Gorjeta
Em um data warehouse de produção, normalmente há cargas de trabalho mistas com diferentes características de uso de recursos em execução simultânea.
Uma carga de trabalho é uma classe de solicitações de banco de dados com características comuns cujo acesso ao banco de dados pode ser gerenciado com um conjunto de regras. As cargas de trabalho são úteis para:
Definição de diferentes prioridades de acesso para diferentes tipos de pedidos.
Monitoramento de padrões de uso de recursos, ajuste de desempenho e planejamento de capacidade.
Limitar o número de solicitações ou sessões que podem ser executadas ao mesmo tempo.
Em um sistema Teradata, o gerenciamento de carga de trabalho é o ato de gerenciar o desempenho da carga de trabalho monitorando a atividade do sistema e agindo quando os limites pré-definidos são atingidos. O gerenciamento de carga de trabalho usa regras, e cada regra se aplica apenas a algumas solicitações de banco de dados. No entanto, a recolha de todas as regras aplica-se a todo o trabalho ativo na plataforma. O Teradata Ative System Management (TASM) executa o gerenciamento completo da carga de trabalho em um banco de dados Teradata.
No Azure Synapse, as classes de recursos são limites de recursos predeterminados que governam os recursos de computação e a simultaneidade para a execução da consulta. As classes de recursos podem ajudá-lo a gerenciar sua carga de trabalho definindo limites para o número de consultas executadas simultaneamente e para os recursos de computação atribuídos a cada consulta. Há um compromisso entre memória e simultaneidade.
O Azure Synapse registra automaticamente as estatísticas de utilização de recursos. As métricas incluem estatísticas de uso de CPU, memória, cache, E/S e espaço de trabalho temporário para cada consulta. O Azure Synapse também registra informações de conectividade, como tentativas de conexão com falha.
Gorjeta
As métricas de baixo nível e em todo o sistema são registradas automaticamente no Azure.
O Azure Synapse dá suporte a estes conceitos básicos de gerenciamento de carga de trabalho:
Classificação da carga de trabalho: você pode atribuir uma solicitação a um grupo de carga de trabalho para definir níveis de importância.
Importância da carga de trabalho: você pode influenciar a ordem na qual uma solicitação obtém acesso aos recursos. Por padrão, as consultas são liberadas da fila em uma base de primeiro a entrar, primeiro a sair, à medida que os recursos ficam disponíveis. A importância da carga de trabalho permite que consultas de prioridade mais alta recebam recursos imediatamente, independentemente da fila.
Isolamento da carga de trabalho: você pode reservar recursos para um grupo de carga de trabalho, atribuir uso máximo e mínimo para recursos variáveis, limitar os recursos que um grupo de solicitações pode consumir e definir um valor de tempo limite para matar automaticamente consultas fugitivas.
A execução de cargas de trabalho mistas pode representar desafios de recursos em sistemas ocupados. Um esquema de gerenciamento de carga de trabalho bem-sucedido gerencia efetivamente os recursos, garante uma utilização altamente eficiente dos recursos e maximiza o retorno sobre o investimento (ROI). A classificação da carga de trabalho, a importância da carga de trabalho e o isolamento da carga de trabalho oferecem mais controle sobre como a carga de trabalho utiliza os recursos do sistema.
O guia de gerenciamento de carga de trabalho descreve as técnicas para analisar a carga de trabalho, gerenciar e monitorar a importância da carga de trabalho](.. /.. /sql-data-warehouse/sql-data-warehouse-how-to-manage-and-monitor-workload-importance.md) e as etapas para converter uma classe de recurso em um grupo de carga de trabalho. Use o portal do Azure e as consultas T-SQL em DMVs para monitorar a carga de trabalho e garantir que os recursos aplicáveis sejam utilizados de forma eficiente. O Azure Synapse fornece um conjunto de Modos de Exibição de Gerenciamento Dinâmico (DMVs) para monitorar todos os aspetos do gerenciamento de carga de trabalho. Essas exibições são úteis ao solucionar ativamente a solução de problemas e identificar gargalos de desempenho em sua carga de trabalho.
Essas informações também podem ser usadas para planejamento de capacidade, determinando os recursos necessários para usuários adicionais ou carga de trabalho de aplicativos. Isso também se aplica ao planejamento de scale-up/scale-downs de recursos de computação para suporte econômico de cargas de trabalho "de pico".
Para obter mais informações sobre o gerenciamento de carga de trabalho no Azure Synapse, consulte Gerenciamento de carga de trabalho com classes de recursos.
Dimensionar recursos de computação
Gorjeta
Um dos principais benefícios do Azure é a capacidade de aumentar e reduzir de forma independente os recursos de computação sob demanda para lidar com cargas de trabalho de pico de forma econômica.
A arquitetura do Azure Synapse separa armazenamento e computação, permitindo que cada um seja dimensionado de forma independente. Como resultado, os recursos de computação podem ser dimensionados para atender às demandas de desempenho independentemente do armazenamento de dados. Também pode colocar em pausa e retomar recursos de computação. Um benefício natural dessa arquitetura é que a cobrança de computação e armazenamento é separada. Se um data warehouse não estiver em uso, você poderá economizar nos custos de computação pausando a computação.
Os recursos de computação podem ser ampliados ou reduzidos ajustando a configuração das unidades do data warehouse para o data warehouse. O desempenho de carregamento e consulta aumentará linearmente à medida que você adicionar mais unidades de data warehouse.
Adicionar mais nós de computação adiciona mais poder de computação e capacidade de aproveitar mais processamento paralelo. À medida que o número de nós de computação aumenta, o número de distribuições por nó de computação diminui, fornecendo mais poder de computação e processamento paralelo para consultas. Da mesma forma, a diminuição das unidades de data warehouse reduz o número de nós de computação, o que reduz os recursos de computação para consultas.
Próximos passos
Para saber mais sobre visualização e relatórios, consulte o próximo artigo desta série: Visualização e relatórios para migrações Teradata.