Tutorial: Deteção de anomalias com os serviços de IA do Azure
Neste tutorial, você aprenderá como enriquecer facilmente seus dados no Azure Synapse Analytics com os serviços de IA do Azure. Você usará o Azure AI Anomaly Detetor para encontrar anomalias. Um usuário no Azure Synapse pode simplesmente selecionar uma tabela para enriquecer para deteção de anomalias.
Este tutorial aborda:
- Etapas para obter um conjunto de dados de tabela do Spark que contém dados de séries temporais.
- Uso de uma experiência de assistente no Azure Synapse para enriquecer dados usando o Detetor de Anomalias.
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
- Espaço de trabalho do Azure Synapse Analytics com uma conta de armazenamento do Azure Data Lake Storage Gen2 configurada como o armazenamento padrão. Você precisa ser o Contribuidor de Dados de Blob de Armazenamento do sistema de arquivos Data Lake Storage Gen2 com o qual trabalha.
- Pool de faíscas em seu espaço de trabalho do Azure Synapse Analytics. Para obter detalhes, consulte Criar um pool de faíscas no Azure Synapse.
- Conclusão das etapas de pré-configuração no tutorial Configurar serviços de IA do Azure no Azure Synapse .
Inicie sessão no portal do Azure
Inicie sessão no portal do Azure.
Criar uma tabela do Spark
Você precisa de uma tabela Spark para este tutorial.
Crie um bloco de anotações PySpark e execute o código a seguir.
from pyspark.sql.functions import lit
df = spark.createDataFrame([
("1972-01-01T00:00:00Z", 826.0),
("1972-02-01T00:00:00Z", 799.0),
("1972-03-01T00:00:00Z", 890.0),
("1972-04-01T00:00:00Z", 900.0),
("1972-05-01T00:00:00Z", 766.0),
("1972-06-01T00:00:00Z", 805.0),
("1972-07-01T00:00:00Z", 821.0),
("1972-08-01T00:00:00Z", 20000.0),
("1972-09-01T00:00:00Z", 883.0),
("1972-10-01T00:00:00Z", 898.0),
("1972-11-01T00:00:00Z", 957.0),
("1972-12-01T00:00:00Z", 924.0),
("1973-01-01T00:00:00Z", 881.0),
("1973-02-01T00:00:00Z", 837.0),
("1973-03-01T00:00:00Z", 9000.0)
], ["timestamp", "value"]).withColumn("group", lit("series1"))
df.write.mode("overwrite").saveAsTable("anomaly_detector_testing_data")
Uma tabela do Spark chamada anomaly_detetor_testing_data agora deve aparecer no banco de dados padrão do Spark.
Abra o assistente de serviços de IA do Azure
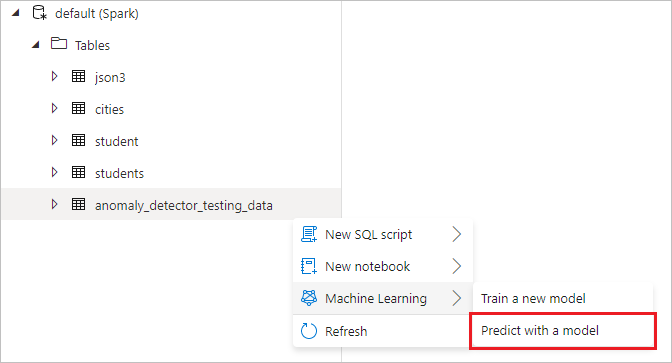
Clique com o botão direito do mouse na tabela Spark criada na etapa anterior. Selecione Aprendizado de Máquina>Prever com um modelo para abrir o assistente.
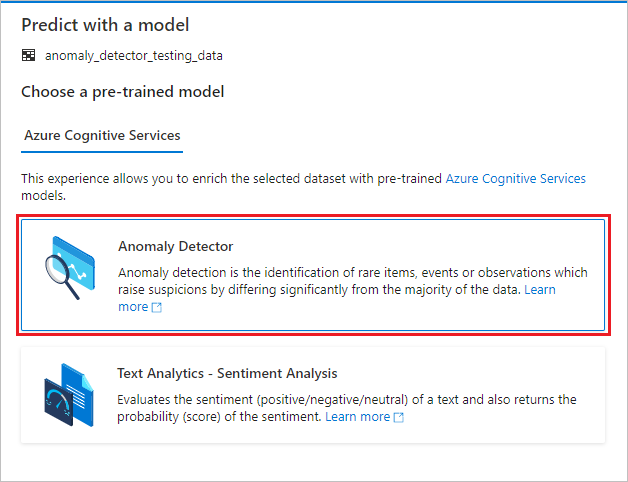
Um painel de configuração é exibido e você é solicitado a selecionar um modelo pré-treinado. Selecione Detetor de anomalias.
Configurar o Detetor de Anomalias
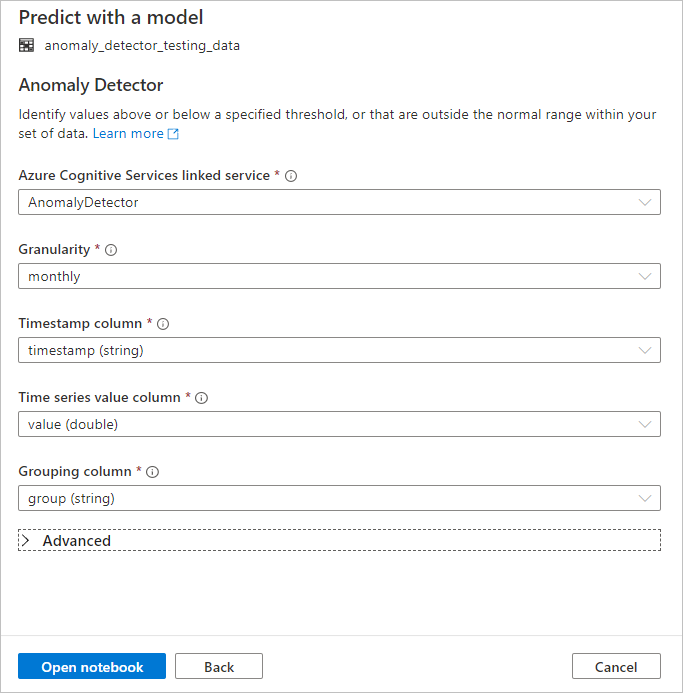
Forneça os seguintes detalhes para configurar o Detetor de Anomalias:
Serviço vinculado dos Serviços Cognitivos do Azure: como parte das etapas de pré-requisito, você criou um serviço vinculado ao seu serviço de IA do Azure. Selecione-o aqui.
Granularidade: a taxa na qual seus dados são amostrados. Escolha mensalmente.
Coluna de carimbo de data/hora: A coluna que representa a hora da série. Escolha timestamp (string).
Coluna de valor da série temporal: A coluna que representa o valor da série no momento especificado pela coluna Carimbo de data/hora. Escolha o valor (duplo).
Coluna de agrupamento: a coluna que agrupa a série. Ou seja, todas as linhas que têm o mesmo valor nesta coluna devem formar uma série temporal. Escolha grupo (string).
Quando terminar, selecione Abrir bloco de anotações. Isso gerará um bloco de anotações para você com código PySpark que usa os serviços de IA do Azure para detetar anomalias.
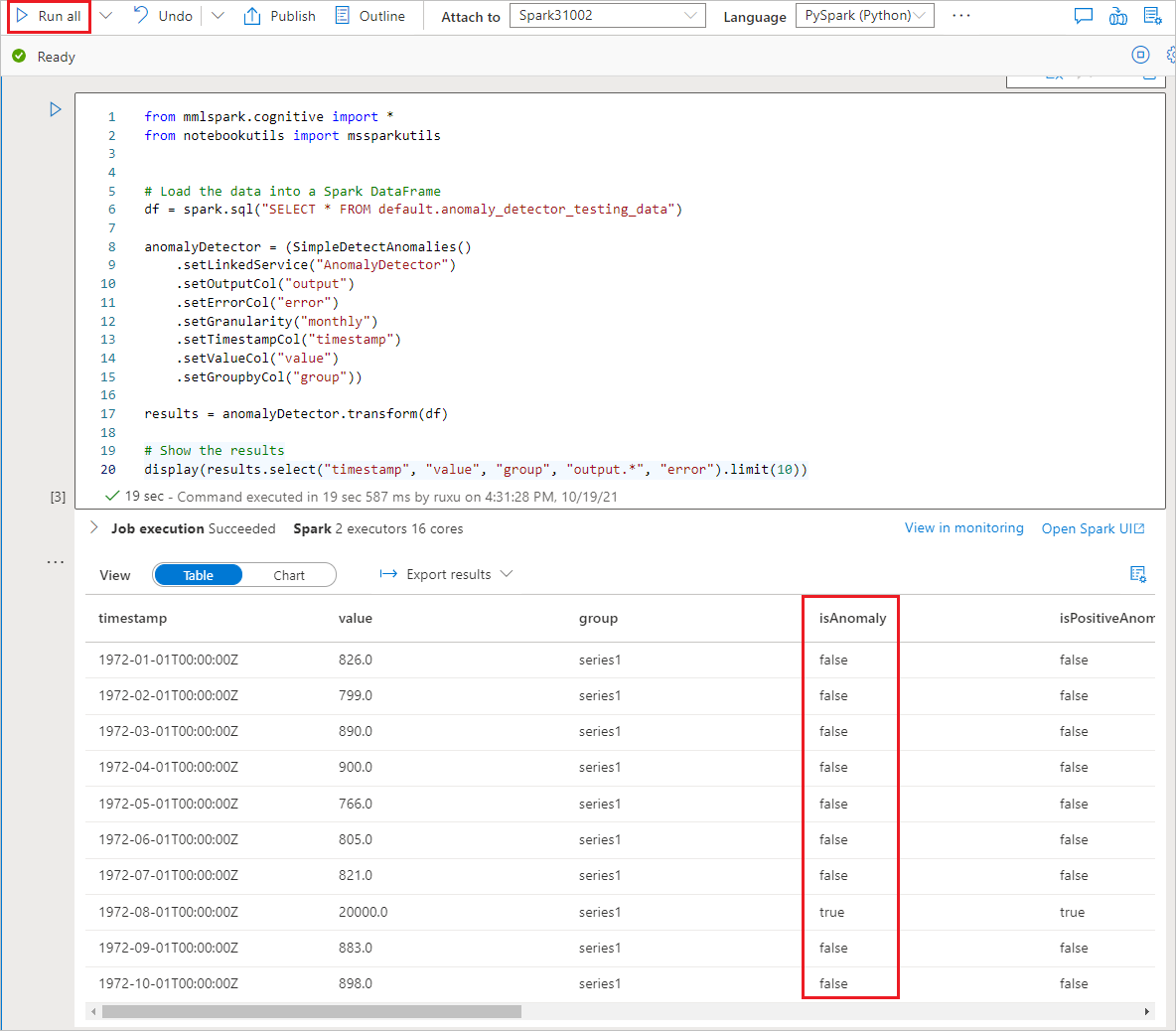
Executar o bloco de notas
O bloco de anotações que você acabou de abrir usa a biblioteca SynapseML para se conectar aos serviços de IA do Azure. O serviço vinculado de serviços de IA do Azure que você forneceu permite que você faça referência segura ao seu serviço de IA do Azure a partir dessa experiência sem revelar segredos.
Agora você pode executar todas as células para executar a deteção de anomalias. Selecione Executar tudo. Saiba mais sobre o Detetor de Anomalias nos serviços de IA do Azure.