Azure Synapse Data Explorer descrição geral da ingestão de dados (Pré-visualização)
A ingestão de dados é o processo utilizado para carregar registos de dados de uma ou mais origens para importar dados para uma tabela no conjunto de Azure Synapse Data Explorer. Depois de ingeridos, os dados ficam disponíveis para consulta.
O Azure Synapse Data Explorer serviço de gestão de dados, responsável pela ingestão de dados, implementa o seguinte processo:
- Extrai dados em lotes ou transmissão em fluxo a partir de uma origem externa e lê pedidos de uma fila pendente do Azure.
- Os dados em lote que fluem para a mesma base de dados e tabela estão otimizados para débito de ingestão.
- Os dados iniciais são validados e o formato é convertido sempre que necessário.
- Mais manipulação de dados, incluindo esquemas correspondentes, organização, indexação, codificação e compressão dos dados.
- Os dados são mantidos no armazenamento de acordo com a política de retenção definida.
- Os dados ingeridos são consolidados no motor, onde estão disponíveis para consulta.
Formatos, propriedades e permissões de dados suportados
Propriedades de ingestão: as propriedades que afetam a forma como os dados serão ingeridos (por exemplo, etiquetagem, mapeamento, hora de criação).
Permissões: para ingerir dados, o processo requer permissões ao nível do ingestor de bases de dados. Outras ações, como a consulta, podem exigir permissões de administrador da base de dados, utilizador da base de dados ou administrador de tabelas.
Criação de batches vs ingestões de transmissão em fluxo
A ingestão de batches faz a criação de batches de dados e está otimizada para um débito de ingestão elevado. Este método é o tipo de ingestão preferencial e mais eficaz. Os dados são colocados em lote de acordo com as propriedades de ingestão. Pequenos lotes de dados são intercalados e otimizados para resultados de consultas rápidas. A política de criação de batches de ingestão pode ser definida em bases de dados ou tabelas. Por predefinição, o valor máximo de criação de batches é de 5 minutos, 1000 itens ou um tamanho total de 1 GB. O limite de tamanho dos dados para um comando de ingestão de lotes é de 4 GB.
A ingestão de transmissão em fluxo é a ingestão de dados contínua de uma origem de transmissão em fluxo. A ingestão de transmissão em fluxo permite latência quase em tempo real para pequenos conjuntos de dados por tabela. Os dados são inicialmente ingeridos no arquivo de linhas e, em seguida, movidos para extensões do arquivo de colunas.
Métodos e ferramentas de ingestão
Azure Synapse Data Explorer suporta vários métodos de ingestão, cada um com os seus próprios cenários de destino. Estes métodos incluem ferramentas de ingestão, conectores e plug-ins para diversos serviços, pipelines geridos, ingestão programática com SDKs e acesso direto à ingestão.
Ingestão com pipelines geridos
Para organizações que pretendam ter gestão (limitação, repetições, monitores, alertas e muito mais) feita por um serviço externo, a utilização de um conector é provavelmente a solução mais adequada. A ingestão em fila é adequada para grandes volumes de dados. Azure Synapse Data Explorer suporta os seguintes Pipelines do Azure:
- Hub de Eventos: um pipeline que transfere eventos de serviços para Azure Synapse Data Explorer. Para obter mais informações, veja Ingerir dados do Hub de Eventos para Azure Synapse Data Explorer.
- Pipelines do Synapse: um serviço de integração de dados totalmente gerido para cargas de trabalho analíticas em pipelines do Synapse liga-se a mais de 90 origens suportadas para fornecer uma transferência de dados eficiente e resiliente. Os pipelines do Synapse preparam, transformam e enriquecem os dados para fornecer informações que podem ser monitorizadas de diferentes formas. Este serviço pode ser utilizado como uma solução única, numa linha cronológica periódica ou acionado por eventos específicos.
Ingestão programática com SDKs
Azure Synapse Data Explorer fornece SDKs que podem ser utilizados para a ingestão de dados e consultas. A ingestão programática é otimizada para reduzir os custos de ingestão (COGs), minimizando as transações de armazenamento durante e seguindo o processo de ingestão.
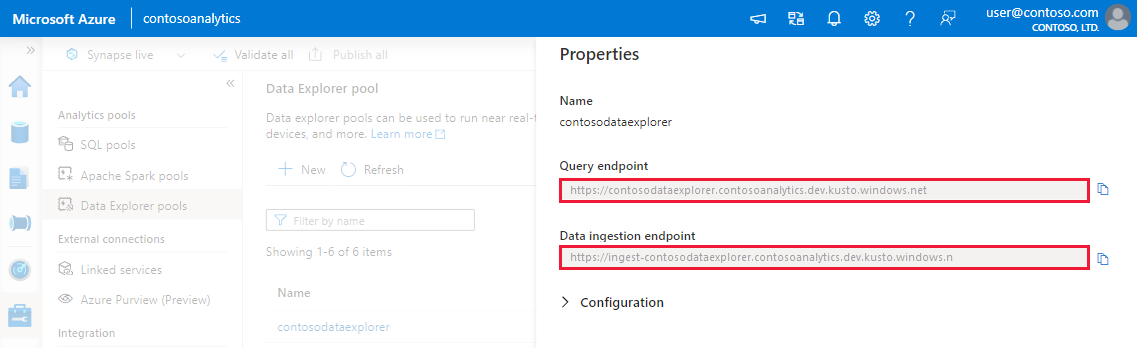
Antes de começar, utilize os seguintes passos para obter os pontos finais do conjunto de Data Explorer para configurar a ingestão programática.
No Synapse Studio, no painel esquerdo, selecione Gerir>Data Explorer conjuntos.
Selecione o conjunto de Data Explorer que pretende utilizar para ver os respetivos detalhes.
Tome nota dos pontos finais de Consulta e Ingestão de Dados. Utilize o Ponto final da consulta como cluster ao configurar ligações ao conjunto de Data Explorer. Ao configurar SDKs para ingestão de dados, utilize o ponto final de ingestão de dados.
SDKs disponíveis e projetos open source
Ferramentas
- Ingestão com um clique: permite-lhe ingerir dados rapidamente ao criar e ajustar tabelas a partir de uma vasta gama de tipos de origem. A ingestão com um clique sugere automaticamente tabelas e estruturas de mapeamento com base na origem de dados no Azure Synapse Data Explorer. A ingestão com um clique pode ser utilizada para ingestão única ou para definir a ingestão contínua através do Event Grid no contentor para o qual os dados foram ingeridos.
Linguagem de Pesquisa Kusto comandos de controlo de ingestão
Existem vários métodos através dos quais os dados podem ser ingeridos diretamente no motor através de comandos Linguagem de Pesquisa Kusto (KQL). Uma vez que este método ignora os serviços Gestão de Dados, só é adequado para exploração e prototipagem. Não utilize este método em cenários de produção ou de elevado volume.
Ingestão inline: um comando de controlo .ingest inline é enviado para o motor, sendo que os dados a ingerir fazem parte do próprio texto do comando. Este método destina-se a fins de teste improvisados.
Ingerir a partir da consulta: um comando de controlo .set, .append, .set-or-append ou .set-or-replace é enviado para o motor, com os dados especificados indiretamente como os resultados de uma consulta ou um comando.
Ingerir a partir do armazenamento (solicitação): um comando de controlo .ingest em é enviado para o motor, com os dados armazenados em algum armazenamento externo (por exemplo, Armazenamento de Blobs do Azure) acessíveis pelo motor e apontados pelo comando.
Para obter um exemplo de como utilizar comandos de controlo de ingestão, veja Analisar com Data Explorer.
Processo de ingestão
Depois de escolher o método de ingestão mais adequado para as suas necessidades, siga os seguintes passos:
Definir política de retenção
Os dados ingeridos numa tabela no Azure Synapse Data Explorer estão sujeitos à política de retenção efetiva da tabela. A menos que seja explicitamente definida numa tabela, a política de retenção eficaz deriva da política de retenção da base de dados. A retenção frequente é uma função do tamanho do cluster e da política de retenção. Ingerir mais dados do que o espaço disponível irá forçar o primeiro dos dados a retenção fria.
Certifique-se de que a política de retenção da base de dados é adequada às suas necessidades. Caso contrário, substitua-a explicitamente ao nível da tabela. Para obter mais informações, veja Política de retenção.
Criar tabelas
Para ingerir dados, é necessário criar previamente uma tabela. Utilize uma das seguintes opções:
Crie uma tabela com um comando. Para obter um exemplo de como utilizar o comando criar uma tabela, veja Analisar com Data Explorer.
Crie uma tabela com a Ingestão com um clique.
Nota
Se um registo estiver incompleto ou não for possível analisar um campo como o tipo de dados necessário, as colunas de tabela correspondentes serão preenchidas com valores nulos.
Criar mapeamento de esquema
O mapeamento de esquema ajuda a vincular campos de dados de origem a colunas de tabela de destino. O mapeamento permite-lhe levar dados de diferentes origens para a mesma tabela, com base nos atributos definidos. São suportados diferentes tipos de mapeamentos, tanto orientados para linhas (CSV, JSON e AVRO) como orientados para colunas (Parquet). Na maioria dos métodos, os mapeamentos também podem ser pré-criados na tabela e referenciados a partir do parâmetro de comando de ingestão.
Definir política de atualização (opcional)
Alguns dos mapeamentos de formato de dados (Parquet, JSON e Avro) suportam transformações de tempo de ingestão simples e úteis. Quando o cenário exigir um processamento mais complexo no momento da ingestão, utilize a política de atualização, que permite o processamento simples com comandos Linguagem de Pesquisa Kusto. A política de atualização executa automaticamente extrações e transformações em dados ingeridos na tabela original e ingere os dados resultantes numa ou mais tabelas de destino. Defina a política de atualização.