Tutorial: Implementar o padrão de captura do data lake para atualizar uma tabela Delta do Databricks
Este tutorial mostra como manipular eventos em uma conta de armazenamento que tem um namespace hierárquico.
Você criará uma pequena solução que permite que um usuário preencha uma tabela Delta do Databricks carregando um arquivo csv (valores separados por vírgula) que descreve uma ordem de venda. Você criará essa solução conectando uma assinatura de Grade de Eventos, uma Função do Azure e um Trabalho no Azure Databricks.
Neste tutorial, vai:
- Crie uma assinatura de Grade de Eventos que chame uma Função do Azure.
- Crie uma Função do Azure que receba uma notificação de um evento e, em seguida, execute o trabalho no Azure Databricks.
- Crie um trabalho Databricks que insere um pedido do cliente em uma tabela Delta do Databricks localizada na conta de armazenamento.
Criaremos essa solução na ordem inversa, começando com o espaço de trabalho do Azure Databricks.
Pré-requisitos
Crie uma conta de armazenamento que tenha um namespace hierárquico (Armazenamento do Azure Data Lake). Este tutorial usa uma conta de armazenamento chamada
contosoorders.Consulte Criar uma conta de armazenamento para usar com o Armazenamento do Azure Data Lake.
Verifique se sua conta de usuário tem a função de Colaborador de Dados de Blob de Armazenamento atribuída a ela.
Crie uma entidade de serviço, crie um segredo do cliente e conceda à entidade de serviço acesso à conta de armazenamento.
Consulte Tutorial: Conectar-se ao Armazenamento do Azure Data Lake (Etapas 1 a 3). Depois de concluir essas etapas, certifique-se de colar a ID do locatário, a ID do aplicativo e os valores secretos do cliente em um arquivo de texto. Você vai precisar deles em breve.
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Criar uma ordem de venda
Primeiro, crie um arquivo csv que descreva uma ordem de venda e, em seguida, carregue esse arquivo para a conta de armazenamento. Mais tarde, você usará os dados desse arquivo para preencher a primeira linha em nossa tabela Delta do Databricks.
No portal do Azure, navegue para a sua nova conta de armazenamento.
Selecione Storage browser-Blob> containers-Add> container e crie um novo contêiner chamado data.
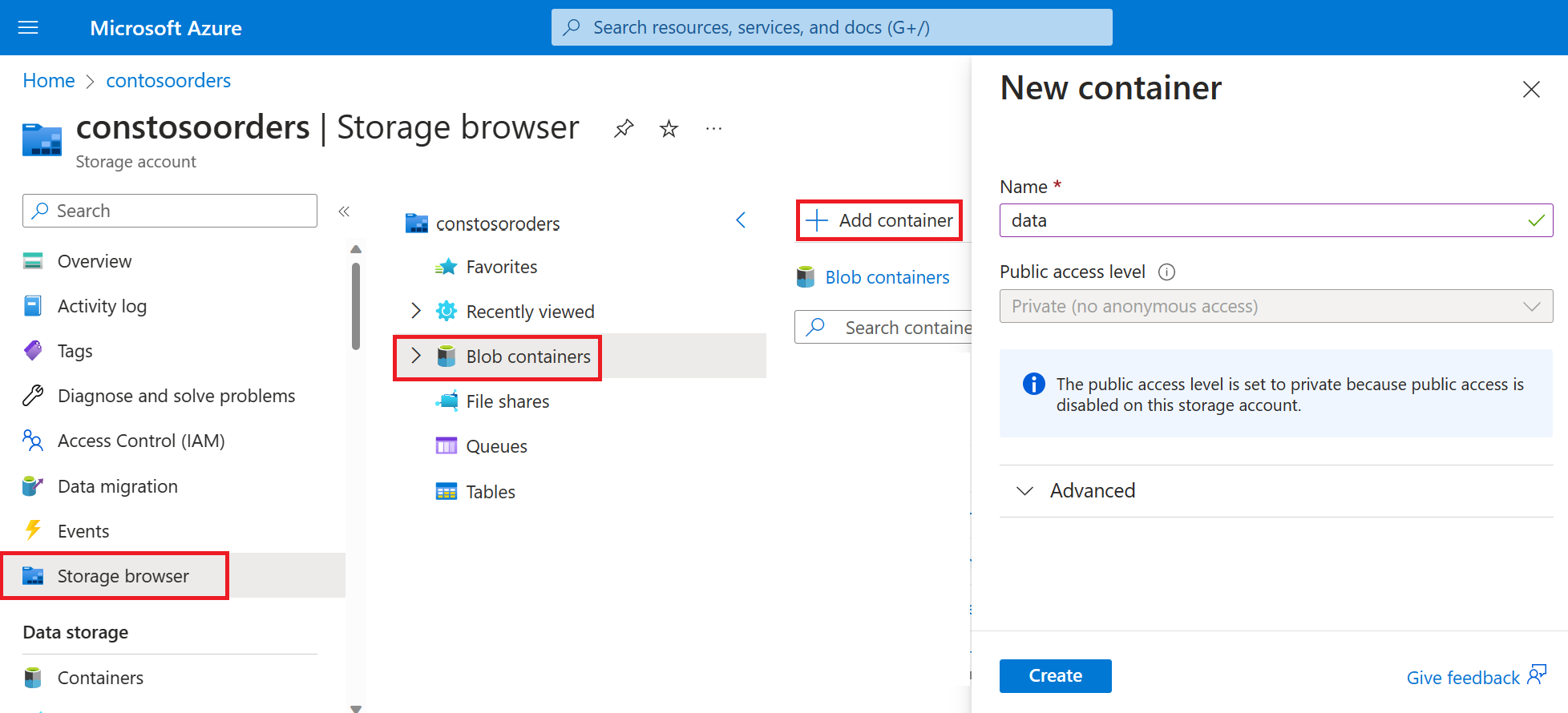
No contêiner de dados, crie um diretório chamado input.
Cole o texto a seguir em um editor de texto.
InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536365,85123A,WHITE HANGING HEART T-LIGHT HOLDER,6,12/1/2010 8:26,2.55,17850,United KingdomGuarde este ficheiro no seu computador local e dê-lhe o nome data.csv.
No navegador de armazenamento, carregue esse arquivo para a pasta de entrada .
Criar um trabalho no Azure Databricks
Nesta seção, você executará estas tarefas:
- Crie um espaço de trabalho do Azure Databricks.
- Crie um bloco de notas.
- Crie e preencha uma tabela Delta do Databricks.
- Adicione código que insere linhas na tabela Delta do Databricks.
- Crie uma Tarefa.
Criar uma área de trabalho do Azure Databricks
Nesta secção, vai criar uma área de trabalho do Azure Databricks com o portal do Azure.
Crie um espaço de trabalho do Azure Databricks. Nomeie esse espaço de trabalho
contoso-orders. Consulte Criar um espaço de trabalho do Azure Databricks.Crie um cluster. Nomeie o cluster
customer-order-cluster. Consulte Criar um cluster.Crie um bloco de notas. Nomeie o bloco de anotações
configure-customer-tablee escolha Python como o idioma padrão do bloco de anotações. Consulte Criar um bloco de notas.
Criar e preencher uma tabela Delta do Databricks
No bloco de notas que criou, copie e cole o seguinte bloco de código na primeira célula, mas ainda não execute este código.
Substitua os
appIdvalores de espaço reservado ,password,tenantneste bloco de código pelos valores coletados ao concluir os pré-requisitos deste tutorial.dbutils.widgets.text('source_file', "", "Source File") spark.conf.set("fs.azure.account.auth.type", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id", "<appId>") spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>") spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<tenant>/oauth2/token") adlsPath = 'abfss://data@contosoorders.dfs.core.windows.net/' inputPath = adlsPath + dbutils.widgets.get('source_file') customerTablePath = adlsPath + 'delta-tables/customers'Este código cria um widget chamado source_file. Mais tarde, você criará uma Função do Azure que chama esse código e passa um caminho de arquivo para esse widget. Esse código também autentica sua entidade de serviço com a conta de armazenamento e cria algumas variáveis que você usará em outras células.
Nota
Em uma configuração de produção, considere armazenar sua chave de autenticação no Azure Databricks. Em seguida, adicione uma chave de pesquisa ao seu bloco de código em vez da chave de autenticação.
Por exemplo, em vez de usar esta linha de código:spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>"), você usaria a seguinte linha de código:spark.conf.set("fs.azure.account.oauth2.client.secret", dbutils.secrets.get(scope = "<scope-name>", key = "<key-name-for-service-credential>")).
Depois de concluir este tutorial, consulte o artigo Armazenamento do Azure Data Lake no site do Azure Databricks para ver exemplos dessa abordagem.Pressione as teclas SHIFT + ENTER para executar o código neste bloco.
Copie e cole o bloco de código a seguir em uma célula diferente e pressione as teclas SHIFT + ENTER para executar o código nesse bloco.
from pyspark.sql.types import StructType, StructField, DoubleType, IntegerType, StringType inputSchema = StructType([ StructField("InvoiceNo", IntegerType(), True), StructField("StockCode", StringType(), True), StructField("Description", StringType(), True), StructField("Quantity", IntegerType(), True), StructField("InvoiceDate", StringType(), True), StructField("UnitPrice", DoubleType(), True), StructField("CustomerID", IntegerType(), True), StructField("Country", StringType(), True) ]) rawDataDF = (spark.read .option("header", "true") .schema(inputSchema) .csv(adlsPath + 'input') ) (rawDataDF.write .mode("overwrite") .format("delta") .saveAsTable("customer_data", path=customerTablePath))Esse código cria a tabela Delta do Databricks em sua conta de armazenamento e, em seguida, carrega alguns dados iniciais do arquivo csv que você carregou anteriormente.
Depois que esse bloco de código for executado com êxito, remova-o do seu bloco de anotações.
Adicionar código que insere linhas na tabela Delta do Databricks
Copie e cole o seguinte bloco de código em uma célula diferente, mas não execute essa célula.
upsertDataDF = (spark .read .option("header", "true") .csv(inputPath) ) upsertDataDF.createOrReplaceTempView("customer_data_to_upsert")Esse código insere dados em uma exibição de tabela temporária usando dados de um arquivo csv. O caminho para esse arquivo csv vem do widget de entrada que você criou em uma etapa anterior.
Copie e cole o bloco de código a seguir em uma célula diferente. Esse código mescla o conteúdo da exibição de tabela temporária com a tabela Delta do Databricks.
%sql MERGE INTO customer_data cd USING customer_data_to_upsert cu ON cd.CustomerID = cu.CustomerID WHEN MATCHED THEN UPDATE SET cd.StockCode = cu.StockCode, cd.Description = cu.Description, cd.InvoiceNo = cu.InvoiceNo, cd.Quantity = cu.Quantity, cd.InvoiceDate = cu.InvoiceDate, cd.UnitPrice = cu.UnitPrice, cd.Country = cu.Country WHEN NOT MATCHED THEN INSERT (InvoiceNo, StockCode, Description, Quantity, InvoiceDate, UnitPrice, CustomerID, Country) VALUES ( cu.InvoiceNo, cu.StockCode, cu.Description, cu.Quantity, cu.InvoiceDate, cu.UnitPrice, cu.CustomerID, cu.Country)
Create a Job (Crie uma Tarefa)
Crie um Trabalho que execute o bloco de anotações criado anteriormente. Mais tarde, você criará uma Função do Azure que executa esse trabalho quando um evento é gerado.
Selecione Novo-trabalho>.
Dê um nome ao trabalho, escolha o bloco de anotações que você criou e clusterize. Em seguida, selecione Criar para criar o trabalho.
Criar uma Função do Azure
Crie uma Função do Azure que execute o Trabalho.
No seu espaço de trabalho do Azure Databricks, clique no seu nome de utilizador do Azure Databricks na barra superior e, em seguida, na lista pendente, selecione Definições do Utilizador.
Na guia Tokens de acesso, selecione Gerar novo token.
Copie o token exibido e clique em Concluído.
No canto superior do espaço de trabalho Databricks, escolha o ícone de pessoas e, em seguida, escolha Configurações do usuário.

Selecione o botão Gerar novo token e, em seguida, selecione o botão Gerar .
Certifique-se de copiar o token para um local seguro. Sua Função do Azure precisa desse token para autenticar com Databricks para que possa executar o Trabalho.
A partir do menu do portal do Azure ou a partir da Home page, selecione Criar um recurso.
Na página Novo, selecione Aplicativo de função de computação>.
Na guia Noções básicas da página Criar aplicativo de função, escolha um grupo de recursos e altere ou verifique as seguintes configurações:
Definição Value Nome da Aplicação de Funções contosoorder Pilha de runtime .NET Publicar Código Sistema operativo Windows Tipo de plano Consumo (Sem servidor) Selecione Rever + criar e, em seguida, selecione Criar.
Quando a implantação estiver concluída, selecione Ir para o recurso para abrir a página de visão geral do aplicativo de função.
No grupo Configurações, selecione Configuração.
Na página Configurações do aplicativo, escolha o botão Nova configuração do aplicativo para adicionar cada configuração.

Adicione as seguintes configurações:
Nome da definição Value DBX_INSTANCE A região do seu espaço de trabalho databricks. Por exemplo: westus2.azuredatabricks.netDBX_PAT O token de acesso pessoal que você gerou anteriormente. DBX_JOB_ID O identificador do trabalho em execução. Selecione Salvar para confirmar essas configurações.
No grupo Funções, selecione Funções e, em seguida, selecione Criar.
Escolha Azure Event Grid Trigger.
Instale a extensão Microsoft.Azure.WebJobs.Extensions.EventGrid se for solicitado. Se você precisar instalá-lo, terá que escolher o Gatilho de Grade de Eventos do Azure novamente para criar a função.
O painel Nova função é exibido.
No painel Nova função, nomeie a função UpsertOrder e selecione o botão Criar.
Substitua o conteúdo do arquivo de código por esse código e selecione o botão Salvar :
#r "Azure.Messaging.EventGrid" #r "System.Memory.Data" #r "Newtonsoft.Json" #r "System.Text.Json" using Azure.Messaging.EventGrid; using Azure.Messaging.EventGrid.SystemEvents; using Newtonsoft.Json; using Newtonsoft.Json.Linq; private static HttpClient httpClient = new HttpClient(); public static async Task Run(EventGridEvent eventGridEvent, ILogger log) { log.LogInformation("Event Subject: " + eventGridEvent.Subject); log.LogInformation("Event Topic: " + eventGridEvent.Topic); log.LogInformation("Event Type: " + eventGridEvent.EventType); log.LogInformation(eventGridEvent.Data.ToString()); if (eventGridEvent.EventType == "Microsoft.Storage.BlobCreated" || eventGridEvent.EventType == "Microsoft.Storage.FileRenamed") { StorageBlobCreatedEventData fileData = eventGridEvent.Data.ToObjectFromJson<StorageBlobCreatedEventData>(); if (fileData.Api == "FlushWithClose") { log.LogInformation("Triggering Databricks Job for file: " + fileData.Url); var fileUrl = new Uri(fileData.Url); var httpRequestMessage = new HttpRequestMessage { Method = HttpMethod.Post, RequestUri = new Uri(String.Format("https://{0}/api/2.0/jobs/run-now", System.Environment.GetEnvironmentVariable("DBX_INSTANCE", EnvironmentVariableTarget.Process))), Headers = { { System.Net.HttpRequestHeader.Authorization.ToString(), "Bearer " + System.Environment.GetEnvironmentVariable("DBX_PAT", EnvironmentVariableTarget.Process)}, { System.Net.HttpRequestHeader.ContentType.ToString(), "application/json" } }, Content = new StringContent(JsonConvert.SerializeObject(new { job_id = System.Environment.GetEnvironmentVariable("DBX_JOB_ID", EnvironmentVariableTarget.Process), notebook_params = new { source_file = String.Join("", fileUrl.Segments.Skip(2)) } })) }; var response = await httpClient.SendAsync(httpRequestMessage); response.EnsureSuccessStatusCode(); } } }
Esse código analisa informações sobre o evento de armazenamento que foi gerado e, em seguida, cria uma mensagem de solicitação com url do arquivo que disparou o evento. Como parte da mensagem, a função passa um valor para o widget source_file que você criou anteriormente. O código da função envia a mensagem para o trabalho do Databricks e usa o token obtido anteriormente como autenticação.
Criar uma subscrição do Event Grid
Nesta seção, você criará uma assinatura de Grade de Eventos que chama a Função do Azure quando os arquivos são carregados na conta de armazenamento.
Selecione Integração e, na página Integração, selecione Gatilho de grade de eventos.
No painel Editar gatilho, nomeie o evento
eventGridEvente selecione Criar assinatura de evento.Nota
O nome
eventGridEventcorresponde ao parâmetro nomeado que é passado para a Função do Azure.Na guia Noções básicas da página Criar Assinatura de Evento, altere ou verifique as seguintes configurações:
Definição Valor Nome contoso-order-event-subscription Tipo de tópico Conta de armazenamento Recurso de origem contosoorders Nome do tópico do sistema <create any name>Filtrar Tipos de Eventos Blob criado e Blob excluído Selecione o botão Criar.
Testar a subscrição da Grelha de Eventos
Crie um ficheiro com o nome
customer-order.csv, cole as seguintes informações nesse ficheiro e guarde-o no computador local.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,228,1/1/2018 9:01,33.85,20993,Sierra LeoneNo Gerenciador de Armazenamento, carregue esse arquivo para a pasta de entrada da sua conta de armazenamento.
O carregamento de um arquivo gera o evento Microsoft.Storage.BlobCreated . A Grelha de Eventos notifica todos os subscritores desse evento. No nosso caso, a Função do Azure é o único assinante. A Função do Azure analisa os parâmetros de evento para determinar qual evento ocorreu. Em seguida, ele passa a URL do arquivo para o trabalho do Databricks. O Trabalho do Databricks lê o arquivo e adiciona uma linha à tabela Delta do Databricks localizada na sua conta de armazenamento.
Para verificar se o trabalho foi bem-sucedido, veja as execuções do seu trabalho. Você verá um status de conclusão. Para obter mais informações sobre como exibir execuções para um trabalho, consulte Exibir execuções para um trabalho
Em uma nova célula da pasta de trabalho, execute essa consulta em uma célula para ver a tabela delta atualizada.
%sql select * from customer_dataA tabela retornada mostra o registro mais recente.

Para atualizar esse registro, crie um arquivo chamado
customer-order-update.csv, cole as seguintes informações nesse arquivo e salve-o no computador local.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,22,1/1/2018 9:01,33.85,20993,Sierra LeoneEste arquivo csv é quase idêntico ao anterior, exceto a quantidade da ordem é alterada de
228para22.No Gerenciador de Armazenamento, carregue esse arquivo para a pasta de entrada da sua conta de armazenamento.
Execute a
selectconsulta novamente para ver a tabela delta atualizada.%sql select * from customer_dataA tabela retornada mostra o registro atualizado.

Clean up resources (Limpar recursos)
Quando não forem mais necessários, exclua o grupo de recursos e todos os recursos relacionados. Para fazer isso, selecione o grupo de recursos para a conta de armazenamento e selecione Excluir.