Práticas recomendadas para usar o Armazenamento do Azure Data Lake
Este artigo fornece diretrizes de práticas recomendadas que ajudam a otimizar o desempenho, reduzir custos e proteger sua conta de Armazenamento do Azure habilitada para Armazenamento Data Lake.
Para obter sugestões gerais sobre a estruturação de um data lake, consulte estes artigos:
- Visão geral do Armazenamento Azure Data Lake para o cenário de gerenciamento e análise de dados
- Provisionar três contas do Armazenamento do Azure Data Lake para cada zona de aterrissagem de dados
Localizar documentação
O Armazenamento Azure Data Lake não é um serviço dedicado ou um tipo de conta. É um conjunto de recursos que suportam cargas de trabalho analíticas de alto rendimento. A documentação do Armazenamento Data Lake fornece práticas recomendadas e orientações para o uso desses recursos. Para todos os outros aspetos do gerenciamento de contas, como configuração de segurança de rede, design para alta disponibilidade e recuperação de desastres, consulte o conteúdo da documentação de armazenamento de Blob.
Avalie o suporte a recursos e problemas conhecidos
Use o padrão a seguir ao configurar sua conta para usar os recursos de armazenamento de Blob.
Analise o artigo Suporte ao recurso de Armazenamento de Blob nas contas de Armazenamento do Azure para determinar se um recurso é totalmente suportado em sua conta. Alguns recursos ainda não são suportados ou têm suporte parcial em contas habilitadas para Armazenamento Data Lake. O suporte a recursos está sempre em expansão, portanto, certifique-se de revisar periodicamente este artigo para atualizações.
Analise o artigo Problemas conhecidos com o Armazenamento do Azure Data Lake para ver se há limitações ou orientações especiais sobre o recurso que você pretende usar.
Analise os artigos de recursos para obter qualquer orientação específica para contas habilitadas para o Armazenamento Data Lake.
Compreender os termos utilizados na documentação
À medida que você se move entre conjuntos de conteúdo, você percebe algumas pequenas diferenças terminológicas. Por exemplo, o conteúdo apresentado na documentação de armazenamento de Blob usará o termo blob em vez de arquivo. Tecnicamente, os ficheiros que ingere para a sua conta de armazenamento tornam-se blobs na sua conta. Portanto, o termo está correto. No entanto, o termo blob pode causar confusão se você estiver acostumado com o arquivo de termos. Você também verá o termo contêiner usado para se referir a um sistema de arquivos. Considere estes termos como sinónimos.
Considere premium
Se suas cargas de trabalho exigem uma latência baixa e consistente e/ou exigem um alto número de operações de entrada e saída por segundo (IOP), considere usar uma conta de armazenamento de blob de bloco premium. Este tipo de conta disponibiliza dados através de hardware de alto desempenho. Os dados são armazenados em unidades de estado sólido (SSDs) que são otimizadas para baixa latência. As SSD proporcionam um débito mais elevado em comparação com as unidades de disco rígido tradicionais. Os custos de armazenamento de desempenho premium são mais altos, mas os custos de transação são menores. Portanto, se suas cargas de trabalho executarem um grande número de transações, uma conta de blob de bloco de desempenho premium pode ser econômica.
Se sua conta de armazenamento for usada para análises, é altamente recomendável que você use o Armazenamento Azure Data Lake junto com uma conta de armazenamento de blob de bloco premium. Essa combinação de usar contas de armazenamento de blob de bloco premium junto com uma conta habilitada para Armazenamento Data Lake é conhecida como a camada premium para o Armazenamento do Azure Data Lake.
Otimizar para ingestão de dados
Ao ingerir dados de um sistema de origem, o hardware de origem, o hardware de rede de origem ou a conectividade de rede com sua conta de armazenamento podem ser um gargalo.
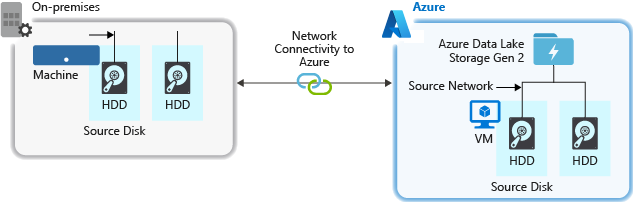
Hardware de origem
Quer esteja a utilizar máquinas no local ou Máquinas Virtuais (VMs) no Azure, certifique-se de que seleciona cuidadosamente o hardware adequado. Para hardware de disco, considere usar unidades de estado sólido (SSD) e escolha hardware de disco com eixos mais rápidos. Para hardware de rede, use os controladores de interface de rede (NIC) mais rápidos possível. No Azure, recomendamos as VMs do Azure D14, que têm o disco e o hardware de rede apropriados.
Conectividade de rede com a conta de armazenamento
A conectividade de rede entre os dados de origem e a conta de armazenamento às vezes pode ser um gargalo. Quando os dados de origem estiverem no local, considere usar um link dedicado com o Azure ExpressRoute. Se os dados de origem estiverem no Azure, o desempenho será melhor quando os dados estiverem na mesma região do Azure que sua conta habilitada para Armazenamento Data Lake.
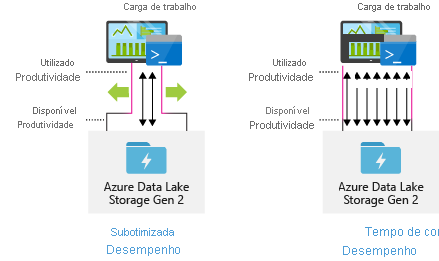
Configurar ferramentas de ingestão de dados para paralelização máxima
Para obter o melhor desempenho, use toda a taxa de transferência disponível executando o maior número possível de leituras e gravações em paralelo.
A tabela a seguir resume as principais configurações de várias ferramentas populares de ingestão.
| Ferramenta | Definições |
|---|---|
| DistCp | -m (mapeador) |
| Fábrica de Dados do Azure | parallelCopies |
| Sqoop | fs.azure.block.size, -m (mapeador) |
| AzCopy | AZCOPY_CONCURRENCY_VALUE |
Nota
O desempenho geral de suas operações de ingestão depende de outros fatores específicos da ferramenta que você está usando para ingerir dados. Para obter as melhores orientações atualizadas, consulte a documentação de cada ferramenta que você pretende usar.
Sua conta pode ser dimensionada para fornecer a taxa de transferência necessária para todos os cenários de análise. Por padrão, uma conta habilitada para Armazenamento Data Lake fornece taxa de transferência suficiente em sua configuração padrão para atender às necessidades de uma ampla categoria de casos de uso. Se você atingir o limite padrão, a conta poderá ser configurada para fornecer mais taxa de transferência entrando em contato com o Suporte do Azure.
Estruturar conjuntos de dados
Considere o planejamento prévio da estrutura de seus dados. O formato de arquivo, o tamanho do arquivo e a estrutura de diretórios podem afetar o desempenho e o custo.
Formatos de ficheiro
Os dados podem ser ingeridos em vários formatos. Os dados podem aparecer em formatos legíveis por humanos, como JSON, CSV ou XML, ou como formatos binários compactados, como .tar.gz. Os dados também podem vir em vários tamanhos. Os dados podem ser compostos por arquivos grandes (alguns terabytes), como dados de uma exportação de uma tabela SQL de seus sistemas locais. Os dados também podem vir na forma de um grande número de arquivos minúsculos (alguns kilobytes), como dados de eventos em tempo real de uma solução de Internet das Coisas (IoT). Você pode otimizar a eficiência e os custos escolhendo um formato de arquivo e tamanho de arquivo apropriados.
O Hadoop suporta um conjunto de formatos de arquivo otimizados para armazenar e processar dados estruturados. Alguns formatos comuns são Avro, Parquet e Optimized Row Columnar (ORC). Todos estes formatos são formatos de ficheiro binário legíveis por máquina. Eles são compactados para ajudá-lo a gerenciar o tamanho do arquivo. Eles têm um esquema incorporado em cada arquivo, o que os torna autodescritos. A diferença entre esses formatos está em como os dados são armazenados. O Avro armazena dados em um formato baseado em linha e os formatos Parquet e ORC armazenam dados em um formato colunar.
Considere o uso do formato de arquivo Avro nos casos em que seus padrões de E/S são mais pesados de gravação ou os padrões de consulta favorecem a recuperação de várias linhas de registros em sua totalidade. Por exemplo, o formato Avro funciona bem com um barramento de mensagens, como Hubs de Eventos ou Kafka, que gravam vários eventos/mensagens sucessivamente.
Considere os formatos de arquivo Parquet e ORC quando os padrões de E/S forem mais lidos ou quando os padrões de consulta estiverem focados em um subconjunto de colunas nos registros. As transações de leitura podem ser otimizadas para recuperar colunas específicas em vez de ler o registro inteiro.
Apache Parquet é um formato de arquivo de código aberto que é otimizado para leitura de pipelines de análise pesada. A estrutura de armazenamento colunar do Parquet permite ignorar dados não relevantes. Suas consultas são muito mais eficientes porque podem restringir o escopo de quais dados enviar do armazenamento para o mecanismo de análise. Além disso, como tipos de dados semelhantes (para uma coluna) são armazenados juntos, o Parquet suporta esquemas eficientes de compactação e codificação de dados que podem reduzir os custos de armazenamento de dados. Serviços como o Azure Synapse Analytics, o Azure Databricks e o Azure Data Factory têm funcionalidades nativas que tiram partido dos formatos de ficheiro Parquet.
Tamanho do ficheiro
Arquivos maiores levam a um melhor desempenho e custos reduzidos.
Normalmente, os mecanismos de análise, como o HDInsight, têm uma sobrecarga por arquivo que envolve tarefas como listagem, verificação de acesso e execução de várias operações de metadados. Se você armazenar seus dados como muitos arquivos pequenos, isso pode afetar negativamente o desempenho. Em geral, organize seus dados em arquivos de tamanho maior para um melhor desempenho (256 MB a 100 GB de tamanho). Alguns mecanismos e aplicativos podem ter problemas para processar com eficiência arquivos com mais de 100 GB de tamanho.
Aumentar o tamanho do arquivo também pode reduzir os custos de transação. As operações de leitura e gravação são cobradas em incrementos de 4 megabytes, portanto, você será cobrado pela operação, independentemente de o arquivo conter ou não 4 megabytes ou apenas alguns kilobytes. Para obter informações sobre preços, consulte Preços do Armazenamento do Azure Data Lake.
Às vezes, os pipelines de dados têm controle limitado sobre os dados brutos, que têm muitos arquivos pequenos. Em geral, recomendamos que seu sistema tenha algum tipo de processo para agregar arquivos pequenos em arquivos maiores para uso por aplicativos downstream. Se você estiver processando dados em tempo real, poderá usar um mecanismo de streaming em tempo real (como o Azure Stream Analytics ou o Spark Streaming) junto com um agente de mensagens (como Hubs de Eventos ou Apache Kafka) para armazenar seus dados como arquivos maiores. Ao agregar arquivos pequenos em arquivos maiores, considere salvá-los em um formato otimizado para leitura, como o Apache Parquet , para processamento downstream.
Estrutura do diretório
Cada carga de trabalho tem requisitos diferentes sobre como os dados são consumidos, mas esses são alguns layouts comuns a serem considerados ao trabalhar com Internet das Coisas (IoT), cenários em lote ou ao otimizar dados de séries temporais.
Estrutura da IoT
Em cargas de trabalho de IoT, pode haver uma grande quantidade de dados sendo ingerida que abrange vários produtos, dispositivos, organizações e clientes. É importante planejar previamente o layout do diretório para organização, segurança e processamento eficiente dos dados para consumidores downstream. Um modelo geral a considerar pode ser o seguinte layout:
- {Região}/{Assunto(s)}/{aaaa}/{mm}/{dd}/{hh}/
Por exemplo, a telemetria de pouso para um motor de avião no Reino Unido pode se parecer com a seguinte estrutura:
- Reino Unido/Aviões/BA1293/Motor1/2017/08/11/12/
Neste exemplo, colocando a data no final da estrutura de diretórios, você pode usar ACLs para proteger mais facilmente regiões e assuntos para usuários e grupos específicos. Se você colocar a estrutura de data no início, seria muito mais difícil proteger essas regiões e assuntos. Por exemplo, se você quisesse fornecer acesso apenas a dados do Reino Unido ou certos aviões, precisaria aplicar uma permissão separada para vários diretórios em cada diretório de horas. Esta estrutura também aumentaria exponencialmente o número de diretórios com o passar do tempo.
Estrutura de trabalhos em lote
Uma abordagem comumente usada no processamento em lote é colocar os dados em um diretório "in". Em seguida, uma vez que os dados são processados, coloque os novos dados em um diretório "out" para que os processos downstream sejam consumidos. Essa estrutura de diretórios às vezes é usada para trabalhos que exigem processamento em arquivos individuais e podem não exigir processamento paralelo maciço em grandes conjuntos de dados. Como a estrutura de IoT recomendada acima, uma boa estrutura de diretórios tem os diretórios de nível pai para coisas como região e assunto (por exemplo, organização, produto ou produtor). Considere data e hora na estrutura para permitir melhor organização, pesquisas filtradas, segurança e automação no processamento. O nível de granularidade para a estrutura de data é determinado pelo intervalo no qual os dados são carregados ou processados, como horário, diário ou até mensal.
Às vezes, o processamento de arquivos não é bem-sucedido devido à corrupção de dados ou formatos inesperados. Nesses casos, uma estrutura de diretórios pode se beneficiar de uma pasta /bad para mover os arquivos para inspeção adicional. O trabalho em lote também pode lidar com o relatório ou notificação desses arquivos incorretos para intervenção manual. Considere a seguinte estrutura de modelo:
- {Região}/{Assunto(s)}/In/{aaaa}/{mm}/{dd}/{hh}/
- {Região}/{Assunto(s)}/out/{aaaa}/{mm}/{dd}/{hh}/
- {Região}/{Assunto(s)}/Bad/{aaaa}/{mm}/{dd}/{hh}/
Por exemplo, uma empresa de marketing recebe extrações diárias de dados de atualizações de clientes de seus clientes na América do Norte. Pode se parecer com o seguinte trecho antes e depois de ser processado:
- NA/Extratos/ACMEPaperCo/In/2017/08/14/updates_08142017.csv
- NA/Extratos/ACMEPaperCo/out/2017/08/14/processed_updates_08142017.csv
No caso comum de dados em lote sendo processados diretamente em bancos de dados como Hive ou bancos de dados SQL tradicionais, não há necessidade de um diretório /in ou /out porque a saída já vai para uma pasta separada para a tabela Hive ou banco de dados externo. Por exemplo, extratos diários de clientes chegariam aos seus respetivos diretórios. Em seguida, um serviço como o Azure Data Factory, Apache Oozie ou Apache Airflow acionaria um trabalho diário do Hive ou do Spark para processar e gravar os dados em uma tabela do Hive.
Estrutura de dados de séries cronológicas
Para cargas de trabalho do Hive, a remoção de partições de dados de séries cronológicas pode ajudar algumas consultas a ler apenas um subconjunto dos dados, o que melhora o desempenho.
Esses pipelines que ingerem dados de séries temporais, geralmente colocam seus arquivos com uma nomenclatura estruturada para arquivos e pastas. Abaixo está um exemplo comum que vemos para dados estruturados por data:
/DataSet/AAAA/MM/DD/datafile_YYYY_MM_DD.tsv
Observe que as informações de data/hora aparecem como pastas e no nome do arquivo.
Para data e hora, o seguinte é um padrão comum
/DataSet/AAAA/MM/DD/HH/mm/datafile_YYYY_MM_DD_HH_mm.tsv
Novamente, a escolha que você faz com a pasta e organização de arquivos deve otimizar para os tamanhos de arquivo maiores e um número razoável de arquivos em cada pasta.
Configurar a segurança
Comece examinando as recomendações no artigo Recomendações de segurança para armazenamento de Blob. Você encontrará orientações de práticas recomendadas sobre como proteger seus dados contra exclusão acidental ou mal-intencionada, proteger dados por trás de um firewall e usar o Microsoft Entra ID como base do gerenciamento de identidades.
Em seguida, revise o artigo Modelo de controle de acesso no Armazenamento do Azure Data Lake para obter orientações específicas para contas habilitadas para o Armazenamento Data Lake. Este artigo ajuda você a entender como usar funções de controle de acesso baseado em função do Azure (Azure RBAC) junto com listas de controle de acesso (ACLs) para impor permissões de segurança em diretórios e arquivos em seu sistema de arquivos hierárquico.
Ingerir, processar e analisar
Há muitas fontes diferentes de dados e maneiras diferentes pelas quais esses dados podem ser ingeridos em uma conta habilitada para Armazenamento Data Lake.
Por exemplo, você pode ingerir grandes conjuntos de dados de clusters HDInsight e Hadoop ou conjuntos menores de dados ad hoc para aplicativos de prototipagem. Você pode ingerir dados transmitidos que são gerados por várias fontes, como aplicativos, dispositivos e sensores. Para esse tipo de dados, você pode usar ferramentas para capturar e processar os dados evento a evento em tempo real e, em seguida, gravar os eventos em lotes em sua conta. Você também pode ingerir logs do servidor Web, que contêm informações como o histórico de solicitações de página. Para dados de log, considere escrever scripts ou aplicativos personalizados para carregá-los para que você tenha a flexibilidade de incluir seu componente de upload de dados como parte de seu aplicativo de big data maior.
Depois que os dados estiverem disponíveis em sua conta, você poderá executar análises nesses dados, criar visualizações e até mesmo baixar dados para sua máquina local ou para outros repositórios, como um banco de dados SQL do Azure ou uma instância do SQL Server.
A tabela a seguir recomenda ferramentas que você pode usar para ingerir, analisar, visualizar e baixar dados. Use os links nesta tabela para encontrar orientações sobre como configurar e usar cada ferramenta.
| Propósito | Ferramentas e orientação de ferramentas |
|---|---|
| Ingerir dados ad hoc | Portal do Azure, Azure PowerShell, Azure CLI, REST, Azure Storage Explorer, Apache DistCp, AzCopy |
| Ingerir dados relacionais | Fábrica de Dados do Azure |
| Ingerir logs do servidor Web | Azure PowerShell, Azure CLI, REST, Azure SDKs (.NET, Java, Python e Node.js), Azure Data Factory |
| Ingerir a partir de clusters HDInsight | Azure Data Factory, Apache DistCp, AzCopy |
| Ingerir a partir de clusters Hadoop | Azure Data Factory, Apache DistCp, WANdisco LiveData Migrator for Azure, Azure Data Box |
| Ingerir grandes conjuntos de dados (vários terabytes) | Azure ExpressRoute |
| Processar e analisar dados | Azure Synapse Analytics, Azure HDInsight, Databricks |
| Visualizar os dados | Power BI, aceleração de consulta do Armazenamento do Azure Data Lake |
| Transferir dados | Portal do Azure, PowerShell, CLI do Azure, REST, SDKs do Azure (.NET, Java, Python e Node.js), Azure Storage Explorer, AzCopy, Azure Data Factory, Apache DistCp |
Nota
Esta tabela não reflete a lista completa de serviços do Azure que dão suporte ao Armazenamento Data Lake. Para ver uma lista de serviços do Azure suportados, o seu nível de suporte, consulte Serviços do Azure que suportam o Armazenamento Azure Data Lake.
Monitorar telemetria
Monitorar o uso e o desempenho é uma parte importante da operacionalização do seu serviço. Os exemplos incluem operações frequentes, operações com alta latência ou operações que causam limitação do lado do serviço.
Toda a telemetria da sua conta de armazenamento está disponível através dos registos de Armazenamento do Azure no Azure Monitor. Esse recurso integra sua conta de armazenamento com o Log Analytics e Hubs de Eventos, além de permitir que você arquive logs em outra conta de armazenamento. Para ver a lista completa de logs de métricas e recursos e seu esquema associado, consulte Referência de dados de monitoramento do Armazenamento do Azure.
O local onde você escolhe armazenar seus logs depende de como você planeja acessá-los. Por exemplo, se você quiser acessar seus logs quase em tempo real e ser capaz de correlacionar eventos em logs com outras métricas do Azure Monitor, poderá armazenar seus logs em um espaço de trabalho do Log Analytics. Em seguida, consulte seus logs usando KQL e consultas de autor, que enumeram a StorageBlobLogs tabela em seu espaço de trabalho.
Se quiser armazenar seus logs para consulta quase em tempo real e retenção de longo prazo, você pode definir suas configurações de diagnóstico para enviar logs para um espaço de trabalho do Log Analytics e uma conta de armazenamento.
Se quiser acessar seus logs por meio de outro mecanismo de consulta, como o Splunk, você pode definir suas configurações de diagnóstico para enviar logs para um hub de eventos e ingerir logs do hub de eventos para o destino escolhido.
Os logs do Armazenamento do Azure no Azure Monitor podem ser habilitados por meio do portal do Azure, PowerShell, CLI do Azure e modelos do Azure Resource Manager. Para implantações em escala, a Política do Azure pode ser usada com suporte total para tarefas de correção. Para obter mais informações, consulte ciphertxt/AzureStoragePolicy.