Gerenciando o consumo de recursos e a carga no Service Fabric com métricas
As métricas são os recursos que interessam aos seus serviços e que são fornecidos pelos nós no cluster. Uma métrica é qualquer coisa que você queira gerenciar para melhorar ou monitorar o desempenho de seus serviços. Por exemplo, você pode observar o consumo de memória para saber se o serviço está sobrecarregado. Outro uso é descobrir se o serviço poderia se mover para outro lugar onde a memória é menos restrita, a fim de obter um melhor desempenho.
Coisas como memória, disco e uso da CPU são exemplos de métricas. Essas métricas são métricas físicas, recursos que correspondem a recursos físicos no nó que precisam ser gerenciados. As métricas também podem ser (e geralmente são) métricas lógicas. As métricas lógicas são coisas como "MyWorkQueueDepth" ou "MessagesToProcess" ou "TotalRecords". As métricas lógicas são definidas pelo aplicativo e correspondem indiretamente a algum consumo de recursos físicos. As métricas lógicas são comuns porque pode ser difícil medir e relatar o consumo de recursos físicos por serviço. A complexidade de medir e relatar suas próprias métricas físicas também é o motivo pelo qual o Service Fabric fornece algumas métricas padrão.
Métricas padrão
Digamos que você queira começar a escrever e implantar seu serviço. Neste ponto, você não sabe quais recursos físicos ou lógicos ele consome. Não há problema! O Gerenciador de Recursos de Cluster do Service Fabric usa algumas métricas padrão quando nenhuma outra métrica é especificada. Eles são:
- PrimaryCount - contagem de réplicas primárias no nó
- ReplicaCount - contagem do total de réplicas com estado no nó
- Contagem - contagem de todos os objetos de serviço (sem estado e com monitoração de estado) no nó
| Metric | Carregamento de instância sem estado | Carga secundária com estado | Carga primária com estado | Espessura |
|---|---|---|---|---|
| PrimáriaContagem | 0 | 0 | 1 | Alto |
| ReplicaCount | 0 | 1 | 1 | Médio |
| Count | 1 | 1 | 1 | Baixo |
Para cargas de trabalho básicas, as métricas padrão fornecem uma distribuição decente do trabalho no cluster. No exemplo a seguir, vamos ver o que acontece quando criamos dois serviços e confiamos nas métricas padrão para balanceamento. O primeiro serviço é um serviço stateful com três partições e um tamanho de conjunto de réplicas de destino de três. O segundo serviço é um serviço sem estado com uma partição e uma contagem de instâncias de três.
Eis o que obtém:
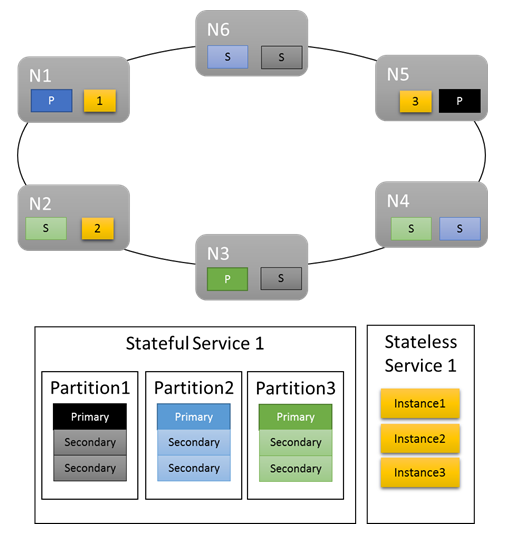
Alguns aspetos a ter em conta:
- As réplicas primárias para o serviço stateful são distribuídas em vários nós
- As réplicas para a mesma partição estão em nós diferentes
- O número total de primários e secundários é distribuído no cluster
- O número total de objetos de serviço é alocado uniformemente em cada nó
Bom!
As métricas padrão funcionam muito bem como um começo. No entanto, as métricas padrão só o levarão até agora. Por exemplo: Qual é a probabilidade de que o esquema de particionamento escolhido resulte em uma utilização perfeitamente uniforme por todas as partições? Qual é a chance de que a carga de um determinado serviço seja constante ao longo do tempo, ou até mesmo a mesma em várias partições agora?
Você pode executar apenas com as métricas padrão. No entanto, isso geralmente significa que a utilização do cluster é menor e mais desigual do que você gostaria. Isso ocorre porque as métricas padrão não são adaptáveis e presumem que tudo é equivalente. Por exemplo, um Primary que está ocupado e um que não está ambos contribuem com "1" para a métrica PrimaryCount. Na pior das hipóteses, usar apenas as métricas padrão também pode resultar em nós superagendados, resultando em problemas de desempenho. Se você estiver interessado em tirar o máximo proveito do cluster e evitar problemas de desempenho, precisará usar métricas personalizadas e relatórios de carga dinâmica.
Métricas personalizadas
As métricas são configuradas por instância de serviço nomeada quando você está criando o serviço.
Qualquer métrica tem algumas propriedades que a descrevem: um nome, um peso e uma carga padrão.
- Nome da métrica: O nome da métrica. O nome da métrica é um identificador exclusivo para a métrica dentro do cluster da perspetiva do Gerenciador de Recursos.
Nota
Nome da métrica personalizada não deve ser nenhum dos nomes de métrica do sistema, ou seja, servicefabric:/_CpuCores ou servicefabric:/_MemoryInMB pois pode levar a um comportamento indefinido. A partir da versão 9.1 do Service Fabric, para serviços existentes com esses nomes de métricas personalizadas, um aviso de integridade é emitido para indicar que o nome da métrica está incorreto.
- Peso: O peso da métrica define a importância dessa métrica em relação às outras métricas desse serviço.
- Carga padrão: a carga padrão é representada de forma diferente, dependendo se o serviço é stateless ou stateful.
- Para serviços sem monitoração de estado, cada métrica tem uma única propriedade chamada DefaultLoad
- Para serviços com monitoração de estado, você define:
- PrimaryDefaultLoad: A quantidade padrão dessa métrica que esse serviço consome quando é uma Primária
- SecondaryDefaultLoad: A quantidade padrão dessa métrica que esse serviço consome quando é um Secondary
Nota
Se você definir métricas personalizadas e quiser também usar as métricas padrão, precisará adicionar explicitamente as métricas padrão de volta e definir pesos e valores para elas. Isso ocorre porque você deve definir a relação entre as métricas padrão e suas métricas personalizadas. Por exemplo, talvez você se importe mais com ConnectionCount ou WorkQueueDepth do que com a distribuição primária. Por padrão, o peso da métrica PrimaryCount é High, portanto, você deseja reduzi-la para Medium ao adicionar outras métricas para garantir que elas tenham precedência.
Definição de métricas para o seu serviço - um exemplo
Digamos que você queira a seguinte configuração:
- Seu serviço relata uma métrica chamada "ConnectionCount"
- Você também deseja usar as métricas padrão
- Você já fez algumas medições e sabe que normalmente uma réplica primária desse serviço ocupa 20 unidades de "ConnectionCount"
- Secundários usam 5 unidades de "ConnectionCount"
- Você sabe que "ConnectionCount" é a métrica mais importante em termos de gerenciamento do desempenho desse serviço específico
- Você ainda deseja que as réplicas primárias sejam equilibradas. Equilibrar réplicas primárias geralmente é uma boa ideia, não importa o que aconteça. Isso ajuda a evitar que a perda de algum nó ou domínio de falha afete a maioria das réplicas primárias junto com ele.
- Caso contrário, as métricas padrão são boas
Aqui está o código que você escreveria para criar um serviço com essa configuração de métrica:
Código:
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
StatefulServiceLoadMetricDescription connectionMetric = new StatefulServiceLoadMetricDescription();
connectionMetric.Name = "ConnectionCount";
connectionMetric.PrimaryDefaultLoad = 20;
connectionMetric.SecondaryDefaultLoad = 5;
connectionMetric.Weight = ServiceLoadMetricWeight.High;
StatefulServiceLoadMetricDescription primaryCountMetric = new StatefulServiceLoadMetricDescription();
primaryCountMetric.Name = "PrimaryCount";
primaryCountMetric.PrimaryDefaultLoad = 1;
primaryCountMetric.SecondaryDefaultLoad = 0;
primaryCountMetric.Weight = ServiceLoadMetricWeight.Medium;
StatefulServiceLoadMetricDescription replicaCountMetric = new StatefulServiceLoadMetricDescription();
replicaCountMetric.Name = "ReplicaCount";
replicaCountMetric.PrimaryDefaultLoad = 1;
replicaCountMetric.SecondaryDefaultLoad = 1;
replicaCountMetric.Weight = ServiceLoadMetricWeight.Low;
StatefulServiceLoadMetricDescription totalCountMetric = new StatefulServiceLoadMetricDescription();
totalCountMetric.Name = "Count";
totalCountMetric.PrimaryDefaultLoad = 1;
totalCountMetric.SecondaryDefaultLoad = 1;
totalCountMetric.Weight = ServiceLoadMetricWeight.Low;
serviceDescription.Metrics.Add(connectionMetric);
serviceDescription.Metrics.Add(primaryCountMetric);
serviceDescription.Metrics.Add(replicaCountMetric);
serviceDescription.Metrics.Add(totalCountMetric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ConnectionCount,High,20,5”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Nota
Os exemplos acima e o restante deste documento descrevem o gerenciamento de métricas por serviço. Também é possível definir métricas para seus serviços no nível do tipo de serviço. Isso é feito especificando-os em seus manifestos de serviço. A definição de métricas de nível de tipo não é recomendada por vários motivos. A primeira razão é que os nomes das métricas são frequentemente específicos do ambiente. A menos que haja um contrato firme em vigor, você não pode ter certeza de que a métrica "Cores" em um ambiente não é "MiliCores" ou "CoReS" em outros. Se suas métricas estiverem definidas em seu manifesto, você precisará criar novos manifestos por ambiente. Isso geralmente leva a uma proliferação de diferentes manifestos com apenas pequenas diferenças, o que pode levar a dificuldades de manejo.
As cargas métricas geralmente são atribuídas por instância de serviço nomeada. Por exemplo, digamos que você crie uma instância do serviço para CustomerA que planeja usá-lo apenas levemente. Digamos também que você crie outro para CustomerB que tenha uma carga de trabalho maior. Nesse caso, você provavelmente gostaria de ajustar as cargas padrão para esses serviços. Se você tiver métricas e cargas definidas por meio de manifestos e quiser oferecer suporte a esse cenário, ele exigirá diferentes tipos de aplicativos e serviços para cada cliente. Os valores definidos no momento da criação do serviço substituem os definidos no manifesto, portanto, você pode usá-los para definir os padrões específicos. No entanto, fazer isso faz com que os valores declarados nos manifestos não correspondam àqueles com os quais o serviço realmente é executado. Isto pode gerar confusão.
Como lembrete: se você quiser apenas usar as métricas padrão, não precisará tocar na coleção de métricas ou fazer nada especial ao criar seu serviço. As métricas padrão são usadas automaticamente quando nenhuma outra é definida.
Agora, vamos analisar cada uma dessas configurações com mais detalhes e falar sobre o comportamento que ela influencia.
Carregamento
O objetivo de definir métricas é representar alguma carga. Load é a quantidade de uma determinada métrica que é consumida por alguma instância de serviço ou réplica em um determinado nó. A carga pode ser configurada em praticamente qualquer ponto. Por exemplo:
- A carga pode ser definida quando um serviço é criado. Esse tipo de configuração de carga é chamado de carga padrão.
- As informações de métrica, incluindo cargas padrão, para um serviço podem ser atualizadas depois que o serviço é criado. Essa atualização de métrica é feita atualizando um serviço.
- As cargas para uma determinada partição podem ser redefinidas para os valores padrão para esse serviço. Essa atualização de métrica é chamada de redefinição da carga da partição.
- A carga pode ser relatada por objeto de serviço, dinamicamente durante o tempo de execução. Essa atualização de métrica é chamada de carga de relatório.
- A carga para réplicas ou instâncias da partição também pode ser atualizada relatando valores de carga por meio de uma chamada de API de malha. Essa atualização de métrica é chamada de carga de relatório para uma partição.
Todas essas estratégias podem ser usadas dentro do mesmo serviço ao longo de sua vida útil.
Carga padrão
A carga padrão é quanto da métrica cada objeto de serviço (instância sem estado ou réplica com monitoração de estado) desse serviço consome. O Gerenciador de Recursos de Cluster usa esse número para a carga do objeto de serviço até receber outras informações, como um relatório de carga dinâmica. Para serviços mais simples, a carga padrão é uma definição estática. A carga padrão nunca é atualizada e é usada durante o tempo de vida do serviço. As cargas padrão funcionam muito bem para cenários simples de planejamento de capacidade em que determinadas quantidades de recursos são dedicadas a cargas de trabalho diferentes e não são alteradas.
Nota
Para obter mais informações sobre gerenciamento de capacidade e definição de capacidades para os nós em seu cluster, consulte este artigo.
O Gerenciador de Recursos de Cluster permite que os serviços com monitoração de estado especifiquem uma carga padrão diferente para seus Primários e Secundários. Os serviços sem estado só podem especificar um valor que se aplique a todas as instâncias. Para serviços com monitoração de estado, a carga padrão para réplicas primárias e secundárias geralmente é diferente, já que as réplicas fazem tipos diferentes de trabalho em cada função. Por exemplo, as primárias geralmente servem para leituras e gravações, e lidam com a maior parte da carga computacional, enquanto as secundárias não. Normalmente, a carga padrão para uma réplica primária é maior do que a carga padrão para réplicas secundárias. Os números reais devem depender das suas próprias medidas.
Carga dinâmica
Digamos que você esteja executando seu serviço há algum tempo. Com algum monitoramento, você notou que:
- Algumas partições ou instâncias de um determinado serviço consomem mais recursos do que outras
- Alguns serviços têm carga que varia ao longo do tempo.
Há muitas coisas que podem causar esses tipos de flutuações de carga. Por exemplo, diferentes serviços ou partições estão associados a diferentes clientes com requisitos diferentes. A carga também pode mudar porque a quantidade de trabalho que o serviço faz varia ao longo do dia. Independentemente do motivo, geralmente não há um único número que você possa usar como padrão. Isso é especialmente verdadeiro se você quiser obter o máximo de utilização do cluster. Qualquer valor escolhido para a carga padrão está errado algumas vezes. Carregamentos padrão incorretos resultam na alocação de recursos do Gerenciador de Recursos de Cluster sobre ou sob alocação. Como resultado, você tem nós que estão mais ou subutilizados, mesmo que o Gerenciador de Recursos de Cluster ache que o cluster está equilibrado. As cargas padrão ainda são boas, pois fornecem algumas informações para o posicionamento inicial, mas não são uma história completa para cargas de trabalho reais. Para capturar com precisão as alterações nos requisitos de recursos, o Gerenciador de Recursos de Cluster permite que cada objeto de serviço atualize sua própria carga durante o tempo de execução. Isso é chamado de relatório de carga dinâmica.
Os relatórios de carga dinâmica permitem que réplicas ou instâncias ajustem sua alocação/carga relatada de métricas ao longo de sua vida útil. Uma réplica de serviço ou instância que estava fria e não estava fazendo nenhum trabalho geralmente relatava que estava usando pequenas quantidades de uma determinada métrica. Uma réplica ou instância ocupada informaria que eles estão usando mais.
A carga de relatórios por réplica ou instância permite que o Gerenciador de Recursos de Cluster reorganize os objetos de serviço individuais no cluster. Reorganizar os serviços ajuda a garantir que eles obtenham os recursos necessários. Os serviços ocupados efetivamente conseguem "recuperar" recursos de outras réplicas ou instâncias que estão atualmente frias ou fazendo menos trabalho.
Nos Serviços Confiáveis, o código para relatar a carga dinamicamente tem esta aparência:
Código:
this.Partition.ReportLoad(new List<LoadMetric> { new LoadMetric("CurrentConnectionCount", 1234), new LoadMetric("metric1", 42) });
Um serviço pode relatar qualquer uma das métricas definidas para ele no momento da criação. Se um serviço relatar a carga de uma métrica que ele não está configurado para usar, o Service Fabric ignorará esse relatório. Se houver outras métricas relatadas ao mesmo tempo que sejam válidas, esses relatórios serão aceitos. O código de serviço pode medir e relatar todas as métricas que sabe fazer, e os operadores podem especificar a configuração de métrica a ser usada sem ter que alterar o código de serviço.
Carga de relatórios para uma partição
A seção anterior descreve como réplicas de serviço ou instâncias de relatório se carregam. Há uma opção adicional para relatar dinamicamente a carga para réplicas ou instâncias de uma partição por meio da API do Service Fabric. Ao relatar a carga de uma partição, você pode relatar várias partições de uma só vez.
Esses relatórios serão usados exatamente da mesma maneira que os relatórios de carga provenientes das próprias réplicas ou instâncias. Os valores relatados serão válidos até que novos valores de carga sejam relatados, seja pela réplica ou instância ou relatando um novo valor de carga para uma partição.
Com essa API, há várias maneiras de atualizar a carga no cluster:
- Uma partição de serviço com monitoração de estado pode atualizar sua carga de réplica primária.
- Os serviços sem monitoração de estado e com monitoração de estado podem atualizar a carga de todas as suas réplicas ou instâncias secundárias.
- Os serviços sem monitoração de estado e com monitoração de estado podem atualizar a carga de uma réplica ou instância específica em um nó.
Também é possível combinar qualquer uma dessas atualizações por partição ao mesmo tempo. A combinação de atualizações de carga para uma partição específica deve ser especificada através do objeto PartitionMetricLoadDescription, que pode conter a lista correspondente de atualizações de carga, conforme mostrado no exemplo abaixo. As atualizações de carga são representadas por meio do objeto MetricLoadDescription, que pode conter o valor de carga atual ou previsto para uma métrica, especificada com um nome de métrica.
Nota
Os valores de carga métrica previstos são atualmente um recurso de visualização. Ele permite que os valores de carga previstos sejam relatados e usados no lado do Service Fabric, mas esse recurso não está habilitado no momento.
A atualização de cargas para várias partições é possível com uma única chamada de API, caso em que a saída conterá uma resposta por partição. Caso a atualização da partição não seja aplicada com êxito por qualquer motivo, as atualizações para essa partição serão ignoradas e o código de erro correspondente para uma partição de destino será fornecido:
- PartitionNotFound - ID de partição especificada não existe.
- ReconfigurationPending - A partição está sendo reconfigurada no momento.
- InvalidForStatelessServices - Foi feita uma tentativa de alterar a carga de uma réplica primária para uma partição pertencente a um serviço sem estado.
- ReplicaDoesNotExist - A réplica ou instância secundária não existe em um nó especificado.
- InvalidOperation - Pode acontecer em dois casos: a atualização da carga para uma partição que pertence ao aplicativo System ou a atualização da carga prevista não está habilitada.
Se alguns desses erros forem retornados, você pode atualizar a entrada para uma partição específica e tentar novamente a atualização para ela.
Código:
Guid partitionId = Guid.Parse("53df3d7f-5471-403b-b736-bde6ad584f42");
string metricName0 = "CustomMetricName0";
List<MetricLoadDescription> newPrimaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 100)
};
string nodeName0 = "NodeName0";
List<MetricLoadDescription> newSpecificSecondaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 200)
};
OperationResult<UpdatePartitionLoadResultList> updatePartitionLoadResults =
await this.FabricClient.UpdatePartitionLoadAsync(
new UpdatePartitionLoadQueryDescription
{
PartitionMetricLoadDescriptionList = new List<PartitionMetricLoadDescription>()
{
new PartitionMetricLoadDescription(
partitionId,
newPrimaryReplicaLoads,
new List<MetricLoadDescription>(),
new List<ReplicaMetricLoadDescription>()
{
new ReplicaMetricLoadDescription(nodeName0, newSpecificSecondaryReplicaLoads)
})
}
},
this.Timeout,
cancellationToken);
Com este exemplo, você executará uma atualização da última carga relatada para uma partição 53df3d7f-5471-403b-b736-bde6ad584f42. A carga de réplica primária para uma métrica CustomMetricName0 será atualizada com o valor 100. Ao mesmo tempo, a carga para a mesma métrica para uma réplica secundária específica localizada no nó NodeName0 será atualizada com o valor 200.
Atualizando a configuração de métrica de um serviço
A lista de métricas associadas ao serviço e as propriedades dessas métricas podem ser atualizadas dinamicamente enquanto o serviço está ativo. Isso permite experimentação e flexibilidade. Alguns exemplos de quando isso é útil são:
- Desativando uma métrica com um relatório de bugs para um serviço específico
- Reconfigurando os pesos das métricas com base no comportamento desejado
- Habilitando uma nova métrica somente depois que o código já tiver sido implantado e validado por meio de outros mecanismos
- Alterar a carga padrão de um serviço com base no comportamento e consumo observados
As principais APIs para alterar a configuração de métricas estão FabricClient.ServiceManagementClient.UpdateServiceAsync em C# e Update-ServiceFabricService no PowerShell. Qualquer informação especificada com essas APIs substitui as informações de métrica existentes para o serviço imediatamente.
Misturando valores de carga padrão e relatórios de carga dinâmica
A carga padrão e as cargas dinâmicas podem ser usadas para o mesmo serviço. Quando um serviço utiliza relatórios de carga padrão e de carga dinâmica, a carga padrão serve como uma estimativa até que os relatórios dinâmicos apareçam. A carga padrão é boa porque dá ao Gerenciador de Recursos de Cluster algo com o qual trabalhar. A carga padrão permite que o Gerenciador de Recursos de Cluster coloque os objetos de serviço em bons locais quando eles são criados. Se nenhuma informação de carga padrão for fornecida, o posicionamento dos serviços será efetivamente aleatório. Quando os relatórios de carregamento chegam mais tarde, o posicionamento aleatório inicial geralmente está errado e o Gerenciador de Recursos de Cluster precisa mover serviços.
Vamos pegar nosso exemplo anterior e ver o que acontece quando adicionamos algumas métricas personalizadas e relatórios de carga dinâmica. Neste exemplo, usamos "MemoryInMb" como uma métrica de exemplo.
Nota
A memória é uma das métricas do sistema que o Service Fabric pode controlar, e relatar você mesmo normalmente é difícil. Na verdade, não esperamos que você informe sobre o consumo de memória; A memória é usada aqui como uma ajuda para aprender sobre os recursos do Gerenciador de Recursos de Cluster.
Vamos supor que inicialmente criamos o serviço stateful com o seguinte comando:
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("MemoryInMb,High,21,11”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Como lembrete, essa sintaxe é ("MetricName, MetricWeight, PrimaryDefaultLoad, SecondaryDefaultLoad").
Vamos ver como seria um possível layout de cluster:
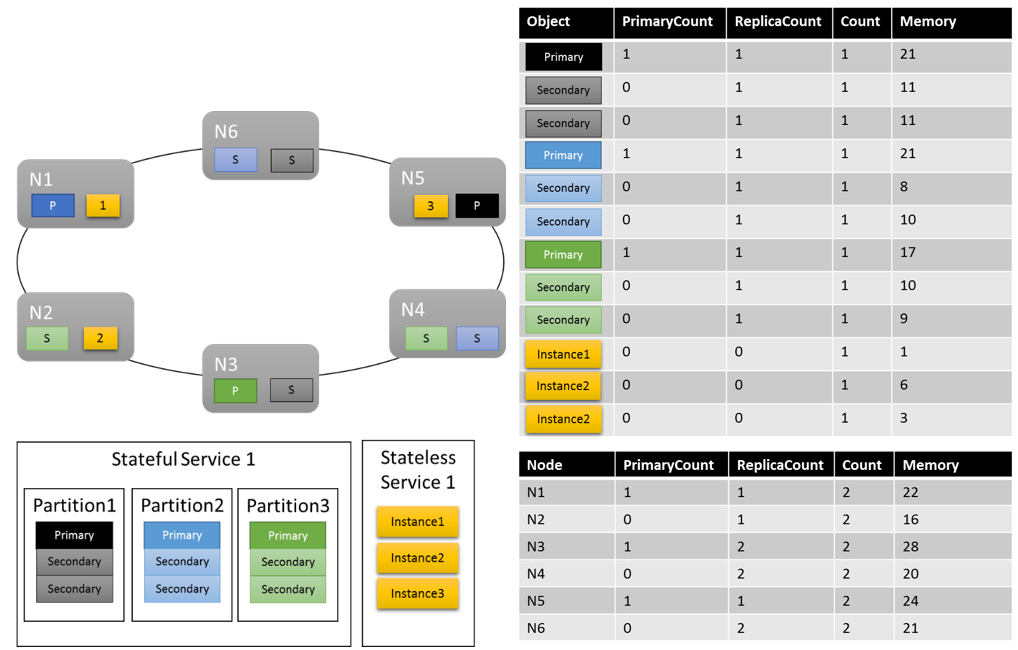
Algumas coisas que vale a pena notar:
- As réplicas secundárias dentro de uma partição podem ter cada uma sua própria carga
- No geral, as métricas parecem equilibradas. Para Memória, a relação entre a carga máxima e mínima é de 1,75 (o nó com mais carga é N3, o mínimo é N2 e 28/16 = 1,75).
Há algumas coisas que ainda precisamos explicar:
- O que determinou se uma proporção de 1,75 era razoável ou não? Como o Cluster Resource Manager sabe se isso é bom o suficiente ou se há mais trabalho a fazer?
- Quando acontece o equilíbrio?
- O que significa que a Memória foi ponderada como "Alta"?
Pesos métricos
Acompanhar as mesmas métricas em diferentes serviços é importante. Essa visão global é o que permite que o Gerenciador de Recursos de Cluster rastreie o consumo no cluster, equilibre o consumo entre nós e garanta que os nós não ultrapassem a capacidade. No entanto, os serviços podem ter visões diferentes quanto à importância da mesma métrica. Além disso, em um cluster com muitas métricas e muitos serviços, soluções perfeitamente equilibradas podem não existir para todas as métricas. Como o Gerenciador de Recursos de Cluster deve lidar com essas situações?
Os pesos métricos permitem que o Gerenciador de Recursos de Cluster decida como equilibrar o cluster quando não há uma resposta perfeita. Os pesos métricos também permitem que o Gerenciador de Recursos de Cluster equilibre serviços específicos de forma diferente. As métricas podem ter quatro níveis de peso diferentes: Zero, Baixo, Médio e Alto. Uma métrica com um peso de Zero não contribui em nada quando se considera se as coisas estão equilibradas ou não. No entanto, sua carga ainda contribui para o gerenciamento de capacidade. As métricas com peso zero ainda são úteis e são frequentemente usadas como parte do comportamento do serviço e do monitoramento de desempenho. Este artigo fornece mais informações sobre o uso de métricas para monitoramento e diagnóstico de seus serviços.
O impacto real de diferentes pesos métricos no cluster é que o Cluster Resource Manager gera soluções diferentes. As ponderações métricas informam ao Cluster Resource Manager que determinadas métricas são mais importantes do que outras. Quando não há uma solução perfeita, o Cluster Resource Manager pode preferir soluções que equilibrem melhor as métricas mais ponderadas. Se um serviço acha que uma determinada métrica não é importante, ele pode achar seu uso dessa métrica desequilibrado. Isso permite que outro serviço obtenha uma distribuição uniforme de alguma métrica que é importante para ele.
Vejamos um exemplo de alguns relatórios de carga e como diferentes pesos métricos resultam em alocações diferentes no cluster. Neste exemplo, vemos que alternar o peso relativo das métricas faz com que o Gerenciador de Recursos de Cluster crie diferentes arranjos de serviços.
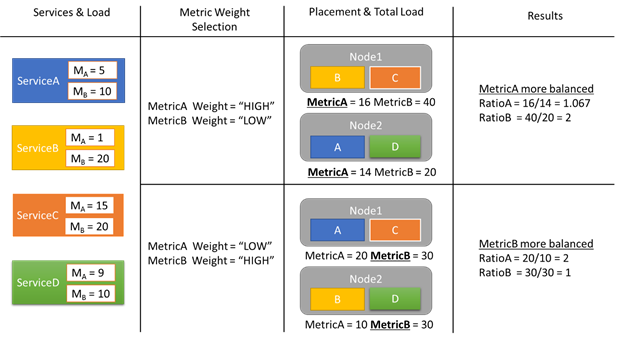
Neste exemplo, há quatro serviços diferentes, todos relatando valores diferentes para duas métricas diferentes, MetricA e MetricB. Em um caso, todos os serviços definem MetricA como o mais importante (Peso = Alto) e MetricB como sem importância (Peso = Baixo). Como resultado, vemos que o Cluster Resource Manager coloca os serviços para que o MetricA seja mais equilibrado do que o MetricB. "Mais equilibrado" significa que o MetricA tem um desvio padrão mais baixo do que o MetricB. No segundo caso, invertemos os pesos métricos. Como resultado, o Cluster Resource Manager troca os serviços A e B para chegar a uma alocação em que o MetricB é mais equilibrado do que o MetricA.
Nota
Os pesos métricos determinam como o Gerenciador de Recursos de Cluster deve se equilibrar, mas não quando o balanceamento deve acontecer. Para obter mais informações sobre balanceamento, confira este artigo
Pesos métricos globais
Digamos que ServiceA define MetricA como peso Alto e ServiceB define o peso para MetricA como Baixo ou Zero. Qual é o peso real que acaba sendo usado?
Há vários pesos que são rastreados para cada métrica. O primeiro peso é aquele definido para a métrica quando o serviço é criado. O outro peso é um peso global, que é calculado automaticamente. O Gerenciador de Recursos de Cluster usa esses dois pesos ao pontuar soluções. Ter em conta ambos os pesos é importante. Isso permite que o Gerenciador de Recursos de Cluster equilibre cada serviço de acordo com suas próprias prioridades e também garanta que o cluster como um todo seja alocado corretamente.
O que aconteceria se o Cluster Resource Manager não se preocupasse com o equilíbrio global e local? Bem, é fácil construir soluções que sejam globalmente equilibradas, mas que resultem em um mau equilíbrio de recursos para serviços individuais. No exemplo a seguir, vamos examinar um serviço configurado apenas com as métricas padrão e ver o que acontece quando apenas o saldo global é considerado:
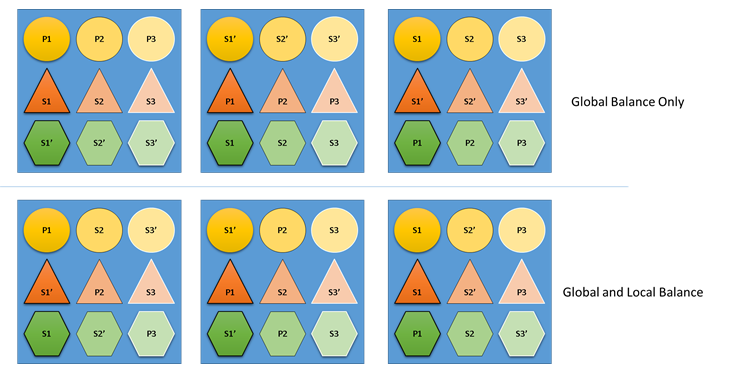
No exemplo superior baseado apenas no equilíbrio global, o cluster como um todo é realmente equilibrado. Todos os nós têm a mesma contagem de primárias e o mesmo número total de réplicas. No entanto, se você olhar para o impacto real dessa alocação, não é tão bom: a perda de qualquer nó afeta uma carga de trabalho específica de forma desproporcional, porque elimina todas as suas primárias. Por exemplo, se o primeiro nó falhar, as três primárias para as três partições diferentes do serviço Circle serão todas perdidas. Por outro lado, os serviços Triangle e Hexagon têm suas partições perdendo uma réplica. Isso não causa nenhuma interrupção, além de ter que recuperar a réplica inativa.
No exemplo inferior, o Gerenciador de Recursos de Cluster distribuiu as réplicas com base no saldo global e por serviço. Ao calcular a pontuação da solução, ele dá a maior parte do peso para a solução global e uma parte (configurável) para serviços individuais. O saldo global de uma métrica é calculado com base na média dos pesos métricos de cada serviço. Cada serviço é balanceado de acordo com seus próprios pesos métricos definidos. Isso garante que os serviços sejam equilibrados dentro de si mesmos de acordo com suas próprias necessidades. Como resultado, se o mesmo primeiro nó falhar, a falha será distribuída em todas as partições de todos os serviços. O impacto para cada um é o mesmo.
Próximos passos
- Para obter mais informações sobre como configurar serviços, Saiba mais sobre como configurar Serviços(service-fabric-cluster-resource-manager-configure-services.md)
- Definir métricas de desfragmentação é uma maneira de consolidar a carga nos nós em vez de distribuí-la. Para saber como configurar a desfragmentação, consulte este artigo
- Para saber como o Gerenciador de Recursos de Cluster gerencia e equilibra a carga no cluster, confira o artigo sobre balanceamento de carga
- Comece do início e obtenha uma Introdução ao Gerenciador de Recursos de Cluster do Service Fabric
- O Custo de Movimento é uma forma de sinalizar ao Cluster Resource Manager que determinados serviços são mais caros para mover do que outros. Para saber mais sobre o custo do movimento, consulte este artigo