Tutorial: Criar um analisador personalizado para números de telefone
Em soluções de pesquisa, cadeias de caracteres que têm padrões complexos ou caracteres especiais podem ser um desafio para trabalhar porque o analisador padrão remove ou interpreta incorretamente partes significativas de um padrão, resultando em uma experiência de pesquisa ruim quando os usuários não conseguem encontrar as informações esperadas. Os números de telefone são um exemplo clássico de cadeias de caracteres difíceis de analisar. Eles vêm em vários formatos e incluem caracteres especiais que o analisador padrão ignora.
Com números de telefone como assunto, este tutorial examina de perto os problemas de dados padronizados e mostra como resolver esse problema usando um analisador personalizado. A abordagem descrita aqui pode ser usada como está para números de telefone ou adaptada para campos com as mesmas características (padronizados, com caracteres especiais), como URLs, e-mails, códigos postais e datas.
Neste tutorial, você usa um cliente REST e as APIs REST do Azure AI Search para:
- Entenda o problema
- Desenvolver um analisador personalizado inicial para lidar com números de telefone
- Testar o analisador personalizado
- Itere no projeto do analisador personalizado para melhorar ainda mais os resultados
Pré-requisitos
Os seguintes serviços e ferramentas são necessários para este tutorial.
Azure AI Search. Crie ou localize um recurso existente do Azure AI Search em sua assinatura atual. Você pode usar um serviço gratuito para este início rápido.
Transferir ficheiros
O código-fonte deste tutorial é o arquivo custom-analyzer.rest no repositório GitHub Azure-Samples/azure-search-rest-samples .
Copiar uma chave e um URL
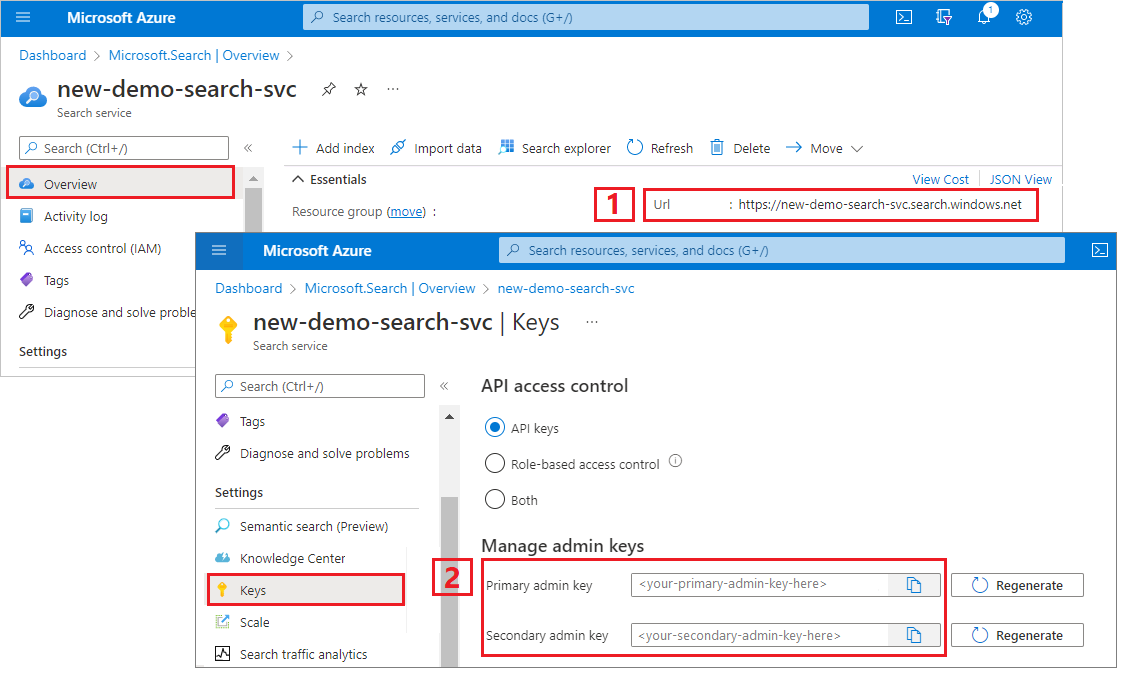
As chamadas REST neste tutorial exigem um ponto de extremidade de serviço de pesquisa e uma chave de API de administrador. Você pode obter esses valores no portal do Azure.
Entre no portal do Azure, navegue até a página Visão geral e copie a URL. Um ponto final de exemplo poderá ser parecido com
https://mydemo.search.windows.net.Em Teclas de Configurações>, copie uma chave de administrador. As chaves de administrador são usadas para adicionar, modificar e excluir objetos. Existem duas chaves de administração intercambiáveis. Copie qualquer uma delas.
Uma chave de API válida estabelece confiança, por solicitação, entre o aplicativo que envia a solicitação e o serviço de pesquisa que a manipula.
Criar um índice inicial
Abra um novo arquivo de texto no Visual Studio Code.
Defina variáveis para o ponto de extremidade de pesquisa e a chave de API coletada na etapa anterior.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-URL-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERESalve o arquivo com uma
.restextensão de arquivo.Cole no exemplo a seguir para criar um pequeno índice chamado
phone-numbers-indexcom dois campos:idephone_number. Ainda não definimos um analisador, portanto, ostandard.luceneanalisador é usado por padrão.### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false } ] }Selecione Enviar pedido. Você deve ter uma
HTTP/1.1 201 Createdresposta e o corpo da resposta deve incluir a representação JSON do esquema de índice.Carregue dados no índice, usando documentos que contêm vários formatos de número de telefone. Estes são os seus dados de teste.
### Load documents POST {{baseUrl}}/indexes/phone-numbers-index/docs/index?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "value": [ { "@search.action": "upload", "id": "1", "phone_number": "425-555-0100" }, { "@search.action": "upload", "id": "2", "phone_number": "(321) 555-0199" }, { "@search.action": "upload", "id": "3", "phone_number": "+1 425-555-0100" }, { "@search.action": "upload", "id": "4", "phone_number": "+1 (321) 555-0199" }, { "@search.action": "upload", "id": "5", "phone_number": "4255550100" }, { "@search.action": "upload", "id": "6", "phone_number": "13215550199" }, { "@search.action": "upload", "id": "7", "phone_number": "425 555 0100" }, { "@search.action": "upload", "id": "8", "phone_number": "321.555.0199" } ] }Vamos tentar algumas consultas semelhantes ao que um usuário pode digitar. Um usuário pode pesquisar
(425) 555-0100em qualquer número de formatos e ainda esperar que os resultados sejam retornados. Comece por pesquisar(425) 555-0100:### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2024-07-01&search=(425) 555-0100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}A consulta retorna três dos quatro resultados esperados, mas também retorna dois resultados inesperados:
{ "value": [ { "@search.score": 0.05634898, "phone_number": "+1 425-555-0100" }, { "@search.score": 0.05634898, "phone_number": "425 555 0100" }, { "@search.score": 0.05634898, "phone_number": "425-555-0100" }, { "@search.score": 0.020766128, "phone_number": "(321) 555-0199" }, { "@search.score": 0.020766128, "phone_number": "+1 (321) 555-0199" } ] }Vamos tentar novamente sem qualquer formatação:
4255550100.### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2024-07-01&search=4255550100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}Esta consulta faz ainda pior, retornando apenas uma das quatro correspondências corretas.
{ "value": [ { "@search.score": 0.6015292, "phone_number": "4255550100" } ] }
Se você acha esses resultados confusos, você não está sozinho. Na próxima seção, vamos analisar por que estamos obtendo esses resultados.
Rever como os analisadores funcionam
Para entender esses resultados de pesquisa, precisamos entender o que o analisador está fazendo. A partir daí, podemos testar o analisador padrão usando a API de análise, fornecendo uma base para projetar um analisador que atenda melhor às nossas necessidades.
Um analisador é um componente do mecanismo de pesquisa de texto completo responsável pelo processamento de texto em cadeias de caracteres de consulta e documentos indexados. Diferentes analisadores manipulam o texto de maneiras diferentes, dependendo do cenário. Para este cenário, precisamos construir um analisador adaptado para números de telefone.
Os analisadores consistem em três componentes:
- Filtros de caracteres que removem ou substituem caracteres individuais do texto de entrada.
- Um Tokenizer que divide o texto de entrada em tokens, que se tornam chaves no índice de pesquisa.
- Filtros de token que manipulam os tokens produzidos pelo tokenizador.
No diagrama a seguir, você pode ver como esses três componentes funcionam juntos para tokenizar uma frase:
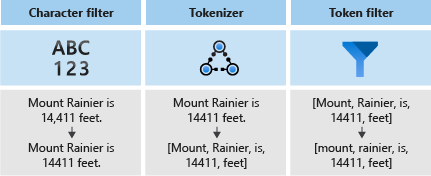
Esses tokens são então armazenados em um índice invertido, o que permite pesquisas rápidas de texto completo. Um índice invertido permite a pesquisa de texto completo, mapeando todos os termos únicos extraídos durante a análise lexical para os documentos em que ocorrem. Você pode ver um exemplo no diagrama a seguir:

Toda a pesquisa se resume à busca pelos termos armazenados no índice invertido. Quando um usuário emite uma consulta:
- A consulta é analisada e os termos da consulta são analisados.
- O índice invertido é então digitalizado em busca de documentos com termos correspondentes.
- Finalmente, os documentos recuperados são classificados pelo algoritmo de pontuação.
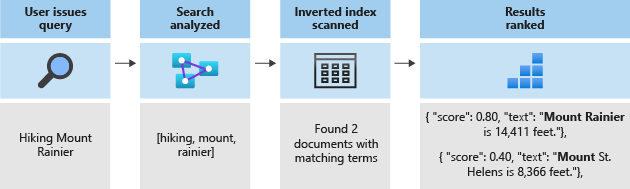
Se os termos da consulta não corresponderem aos termos do índice invertido, os resultados não serão retornados. Para saber mais sobre como as consultas funcionam, consulte este artigo sobre pesquisa de texto completo.
Nota
As consultas de termo parcial são uma exceção importante a esta regra. Essas consultas (consulta de prefixo, consulta curinga, consulta regex) ignoram o processo de análise lexical, ao contrário das consultas de termo regulares. Os termos parciais são apenas reduzidos antes de serem comparados com os termos do índice. Se um analisador não estiver configurado para suportar esses tipos de consultas, você geralmente receberá resultados inesperados porque os termos correspondentes não existem no índice.
Analisadores de teste usando a API de análise
O Azure AI Search fornece uma API de Análise que permite testar analisadores para entender como eles processam texto.
A API de análise é chamada usando a seguinte solicitação:
POST {{baseUrl}}/indexes/phone-numbers-index/analyze?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "(425) 555-0100",
"analyzer": "standard.lucene"
}
A API retorna os tokens extraídos do texto, usando o analisador especificado. O analisador Lucene padrão divide o número de telefone em três tokens separados:
{
"tokens": [
{
"token": "425",
"startOffset": 1,
"endOffset": 4,
"position": 0
},
{
"token": "555",
"startOffset": 6,
"endOffset": 9,
"position": 1
},
{
"token": "0100",
"startOffset": 10,
"endOffset": 14,
"position": 2
}
]
}
Por outro lado, o número 4255550100 de telefone formatado sem qualquer pontuação é tokenizado em um único token.
{
"text": "4255550100",
"analyzer": "standard.lucene"
}
Resposta:
{
"tokens": [
{
"token": "4255550100",
"startOffset": 0,
"endOffset": 10,
"position": 0
}
]
}
Tenha em mente que tanto os termos de consulta quanto os documentos indexados passam por análise. Pensando nos resultados da pesquisa da etapa anterior, podemos começar a ver por que esses resultados foram retornados.
Na primeira consulta, números de telefone inesperados foram retornados porque um de seus tokens, 555, correspondia a um dos termos que pesquisamos. Na segunda consulta, apenas um número foi retornado porque era o único registro que tinha uma correspondência 4255550100de token .
Crie um analisador personalizado
Agora que entendemos os resultados que estamos vendo, vamos criar um analisador personalizado para melhorar a lógica de tokenização.
O objetivo é fornecer uma pesquisa intuitiva em relação a números de telefone, independentemente do formato da consulta ou da cadeia de caracteres indexada. Para alcançar esse resultado, especificaremos um filtro de caracteres, um tokenizador e um filtro de token.
Filtros de caracteres
Os filtros de caracteres são usados para processar texto antes que ele seja inserido no tokenizador. Os usos comuns de filtros de caracteres incluem a filtragem de elementos HTML ou a substituição de caracteres especiais.
Para números de telefone, queremos remover espaços em branco e caracteres especiais porque nem todos os formatos de número de telefone contêm os mesmos caracteres especiais e espaços.
"charFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.MappingCharFilter",
"name": "phone_char_mapping",
"mappings": [
"-=>",
"(=>",
")=>",
"+=>",
".=>",
"\\u0020=>"
]
}
]
O filtro remove -+(). e espaça a entrada.
| Entrada | Saída |
|---|---|
(321) 555-0199 |
3215550199 |
321.555.0199 |
3215550199 |
Tokenizadores
Os tokenizadores dividem o texto em tokens e descartam alguns caracteres, como pontuação, ao longo do caminho. Em muitos casos, o objetivo da tokenização é dividir uma frase em palavras individuais.
Para este cenário, usaremos um tokenizador de palavra-chave, keyword_v2porque queremos capturar o número de telefone como um único termo. Note que esta não é a única forma de resolver este problema. Consulte a secção Abordagens alternativas abaixo.
Os tokenizadores de palavras-chave sempre produzem o mesmo texto que foi dado como um único termo.
| Entrada | Saída |
|---|---|
The dog swims. |
[The dog swims.] |
3215550199 |
[3215550199] |
Filtros de token
Os filtros de token filtrarão ou modificarão os tokens gerados pelo tokenizador. Um uso comum de um filtro de token é minúscula para todos os caracteres usando um filtro de token minúsculo. Outro uso comum é filtrar palavrasthecomo , andou is.
Embora não precisemos usar nenhum desses filtros para esse cenário, usaremos um filtro de token nGram para permitir pesquisas parciais de números de telefone.
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2",
"name": "custom_ngram_filter",
"minGram": 3,
"maxGram": 20
}
]
NGramTokenFilterV2
O filtro de token nGram_v2 divide os tokens em n-gramas de um determinado tamanho com base nos minGram parâmetros e maxGram .
Para o analisador de telefone, definimos minGram como 3 porque essa é a substring mais curta que esperamos que os usuários pesquisem.
maxGram está configurado para 20 garantir que todos os números de telefone, mesmo com extensões, cabem em um único n-grama.
O efeito colateral infeliz de n-gramas é que alguns falsos positivos serão devolvidos. Corrigiremos isso em uma etapa posterior, criando um analisador separado para pesquisas que não inclua o filtro de token n-grama.
| Entrada | Saída |
|---|---|
[12345] |
[123, 1234, 12345, 234, 2345, 345] |
[3215550199] |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Analisador
Com nossos filtros de caracteres, tokenizador e filtros de token no lugar, estamos prontos para definir nosso analisador.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer",
"tokenizer": "keyword_v2",
"tokenFilters": [
"custom_ngram_filter"
],
"charFilters": [
"phone_char_mapping"
]
}
]
A partir da API Analyze, dadas as seguintes entradas, as saídas do analisador personalizado são mostradas na tabela a seguir.
| Entrada | Saída |
|---|---|
12345 |
[123, 1234, 12345, 234, 2345, 345] |
(321) 555-0199 |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Todos os tokens na coluna de saída existem no índice. Se a nossa consulta incluir qualquer um desses termos, o número de telefone será devolvido.
Reconstruir usando o novo analisador
Exclua o índice atual:
### Delete the index DELETE {{baseUrl}}/indexes/phone-numbers-index?api-version=2024-07-01 HTTP/1.1 api-key: {{apiKey}}Recrie o índice usando o novo analisador. Este esquema de índice adiciona uma definição de analisador personalizada e uma atribuição de analisador personalizada no campo de número de telefone.
### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index-2", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false, "analyzer": "phone_analyzer" } ], "analyzers": [ { "@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer", "name": "phone_analyzer", "tokenizer": "keyword_v2", "tokenFilters": [ "custom_ngram_filter" ], "charFilters": [ "phone_char_mapping" ] } ], "charFilters": [ { "@odata.type": "#Microsoft.Azure.Search.MappingCharFilter", "name": "phone_char_mapping", "mappings": [ "-=>", "(=>", ")=>", "+=>", ".=>", "\\u0020=>" ] } ], "tokenFilters": [ { "@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2", "name": "custom_ngram_filter", "minGram": 3, "maxGram": 20 } ] }
Testar o analisador personalizado
Depois de recriar o índice, agora você pode testar o analisador usando a seguinte solicitação:
POST {{baseUrl}}/indexes/tutorial-first-analyzer/analyze?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "+1 (321) 555-0199",
"analyzer": "phone_analyzer"
}
Agora você deve ver a coleção de tokens resultantes do número de telefone:
{
"tokens": [
{
"token": "132",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "1321",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "13215",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
...
...
...
]
}
Revisar o analisador personalizado para lidar com falsos positivos
Depois de fazer algumas consultas de amostra em relação ao índice com o analisador personalizado, você descobrirá que a recuperação melhorou e todos os números de telefone correspondentes agora são retornados. No entanto, o filtro de token n-gram faz com que alguns falsos positivos também sejam retornados. Este é um efeito colateral comum de um filtro de token de n-grama.
Para evitar falsos positivos, criaremos um analisador separado para consulta. Este analisador é idêntico ao anterior, exceto que omite o custom_ngram_filter.
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_search",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [],
"charFilters": [
"phone_char_mapping"
]
}
Na definição de índice, especificamos um indexAnalyzer e um searchAnalyzer.
{
"name": "phone_number",
"type": "Edm.String",
"sortable": false,
"searchable": true,
"filterable": false,
"facetable": false,
"indexAnalyzer": "phone_analyzer",
"searchAnalyzer": "phone_analyzer_search"
}
Com essa mudança, você está pronto. Eis os passos seguintes:
Exclua o índice.
Recrie o índice depois de adicionar o novo analisador personalizado (
phone_analyzer-search) e atribuir esse analisador àphone-numberpropriedade dosearchAnalyzercampo.Recarregue os dados.
Teste novamente as consultas para verificar se a pesquisa funciona conforme o esperado. Se você estiver usando o arquivo de exemplo, esta etapa criará o terceiro índice chamado
phone-number-index-3.
Abordagens alternativas
O analisador descrito na seção anterior foi projetado para maximizar a flexibilidade de pesquisa. No entanto, fá-lo à custa do armazenamento de muitos termos potencialmente sem importância no índice.
O exemplo a seguir mostra um analisador alternativo que é mais eficiente na tokenização, mas tem desvantagens.
Dada uma entrada de , o analisador não pode logicamente dividir o número de 14255550100telefone. Por exemplo, não é possível separar o código do país, 1, do código de área, 425. Esta discrepância levaria a que o número de telefone não fosse devolvido se um utilizador não incluísse um código de país na sua pesquisa.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_shingles",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [
"custom_shingle_filter"
]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.StandardTokenizerV2",
"name": "custom_tokenizer_phone",
"maxTokenLength": 4
}
],
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.ShingleTokenFilter",
"name": "custom_shingle_filter",
"minShingleSize": 2,
"maxShingleSize": 6,
"tokenSeparator": ""
}
]
Você pode ver no exemplo a seguir que o número de telefone é dividido nas partes que você normalmente esperaria que um usuário estivesse procurando.
| Entrada | Saída |
|---|---|
(321) 555-0199 |
[321, 555, 0199, 321555, 5550199, 3215550199] |
Dependendo das suas necessidades, esta pode ser uma abordagem mais eficiente para o problema.
Conclusões
Este tutorial demonstrou o processo de criação e teste de um analisador personalizado. Você criou um índice, indexou dados e, em seguida, consultou o índice para ver quais resultados de pesquisa foram retornados. A partir daí, você usou a API Analyze para ver o processo de análise lexical em ação.
Embora o analisador definido neste tutorial ofereça uma solução fácil para pesquisar números de telefone, esse mesmo processo pode ser usado para criar um analisador personalizado para qualquer cenário que compartilhe características semelhantes.
Clean up resources (Limpar recursos)
Quando estiver a trabalhar com a sua própria subscrição, é aconselhável remover os recursos de que já não necessita no final de um projeto. Os recursos que deixar em execução podem custar dinheiro. Pode eliminar recursos individualmente ou eliminar o grupo de recursos para eliminar todo o conjunto de recursos.
Você pode localizar e gerenciar recursos no portal do Azure, usando o link Todos os recursos ou Grupos de recursos no painel de navegação esquerdo.
Próximos passos
Agora que você está familiarizado com como criar um analisador personalizado, vamos dar uma olhada em todos os diferentes filtros, tokenizadores e analisadores disponíveis para criar uma experiência de pesquisa rica.