Tutorial: Indexar blobs JSON aninhados do Armazenamento do Azure usando REST
O Azure AI Search pode indexar documentos JSON e matrizes no Armazenamento de Blobs do Azure usando um indexador que sabe ler dados semiestruturados. Os dados semiestruturados contêm etiquetas ou marcações que separam o conteúdo dentro dos dados. Ele divide a diferença entre dados não estruturados, que devem ser totalmente indexados, e dados formalmente estruturados que aderem a um modelo de dados, como um esquema de banco de dados relacional que pode ser indexado por campo.
Este tutorial mostra como indexar matrizes JSON aninhadas. Ele usa um cliente REST e as APIs REST de pesquisa para executar as seguintes tarefas:
- Configurar dados de exemplo e configurar uma fonte de
azureblobdados - Criar um índice do Azure AI Search para conter conteúdo pesquisável
- Criar e executar um indexador para ler o contêiner e extrair conteúdo pesquisável
- Pesquisar o índice que acabou de criar
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
Azure AI Search. Crie ou localize um recurso existente do Azure AI Search em sua assinatura atual.
Nota
Você pode usar o serviço gratuito para este tutorial. Um serviço de pesquisa gratuito limita você a três índices, três indexadores e três fontes de dados. Este tutorial cria um de cada. Antes de começar, certifique-se de que tem espaço no seu serviço para aceitar os novos recursos.
Transferir ficheiros
Faça o download de um arquivo zip do repositório de dados de exemplo e extraia o conteúdo. Saiba como.
Os dados de exemplo são um único arquivo JSON contendo uma matriz JSON e 1.521 elementos JSON aninhados. Os dados de amostra têm origem no histórico de desempenho da Filarmônica de NY no Kaggle. Escolhemos um arquivo JSON para ficar abaixo dos limites de armazenamento do nível gratuito.
Aqui está o primeiro JSON aninhado no arquivo. O restante do arquivo inclui outras 1.520 ocorrências de apresentações de concertos.
{
"id": "7358870b-65c8-43d5-ab56-514bde52db88-0.1",
"programID": "11640",
"orchestra": "New York Philharmonic",
"season": "2011-12",
"concerts": [
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-07T04:00:00Z",
"Time": "7:30PM"
},
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-08T04:00:00Z",
"Time": "7:30PM"
}
],
"works": [
{
"ID": "5733*",
"composerName": "Bernstein, Leonard",
"workTitle": "WEST SIDE STORY (WITH FILM)",
"conductorName": "Newman, David",
"soloists": []
},
{
"ID": "0*",
"interval": "Intermission",
"soloists": []
}
]
}
Carregar dados de exemplo para o Armazenamento do Azure
No Armazenamento do Azure, crie um novo contêiner e nomeie-o ny-philharmonic-free.
Carregue os arquivos de dados de exemplo.
Obtenha uma cadeia de conexão de armazenamento para que você possa formular uma conexão no Azure AI Search.
À esquerda, selecione Teclas de acesso.
Copie a cadeia de conexão para a tecla um ou para a chave dois. A cadeia de conexão é semelhante ao exemplo a seguir:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Copiar um URL de serviço de pesquisa e uma chave de API
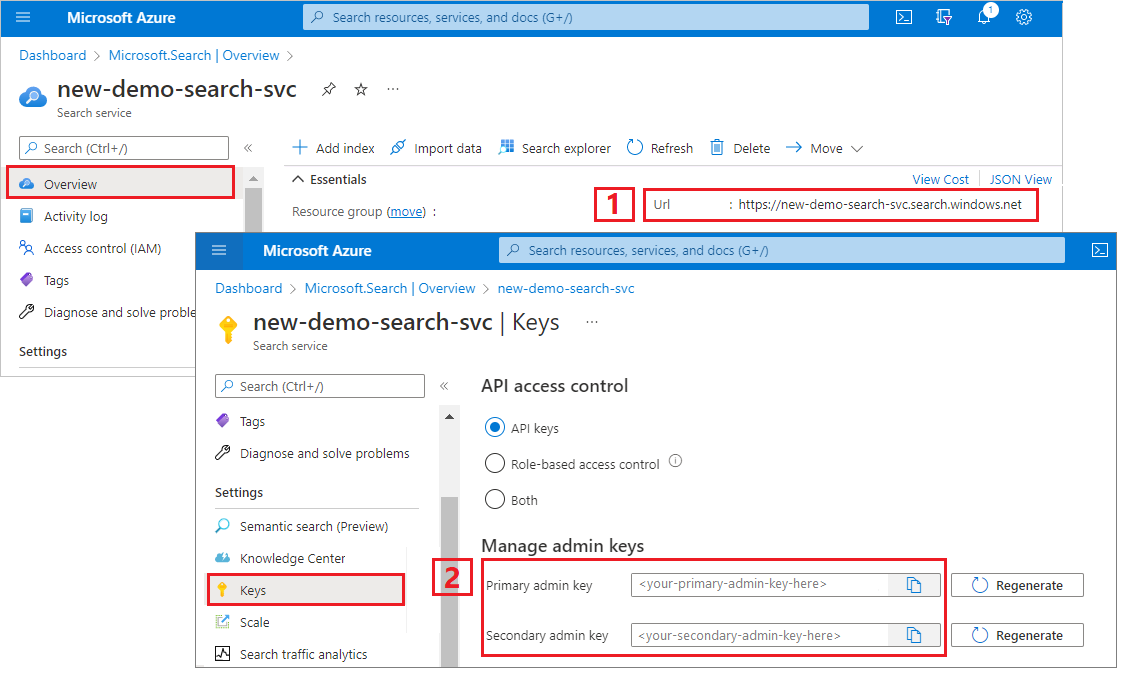
Para este tutorial, as conexões com o Azure AI Search exigem um ponto de extremidade e uma chave de API. Você pode obter esses valores no portal do Azure.
Entre no portal do Azure, navegue até a página Visão geral do serviço de pesquisa e copie a URL. Um ponto final de exemplo poderá ser parecido com
https://mydemo.search.windows.net.Em Teclas de Configurações>, copie uma chave de administrador. As chaves de administrador são usadas para adicionar, modificar e excluir objetos. Existem duas chaves de administração intercambiáveis. Copie qualquer uma delas.
Configurar o arquivo REST
Inicie o Visual Studio Code e crie um novo arquivo
Forneça valores para as variáveis usadas na solicitação:
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnection = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HERESalve o arquivo usando uma
.restextensão de arquivo ou.http.
Consulte Guia de início rápido: pesquisa de texto usando REST se precisar de ajuda com o cliente REST.
Criar uma origem de dados
Create Data Source (REST) cria uma conexão de fonte de dados que especifica quais dados indexar.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnection}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Envie o pedido. A resposta deve ser semelhante a:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DC43A5FDB8448F"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('ny-philharmonic-ds')?api-version=2024-07-01
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 7ca53f73-1054-4959-bc1f-616148a9c74a
elapsed-time: 111
Date: Wed, 13 Mar 2024 21:38:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DC43A5FDB8448F\"",
"name": "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "ny-philharmonic-free",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null
}
Criar um índice
Criar índice (REST) cria um índice de pesquisa no seu serviço de pesquisa. Um índice especifica todos os parâmetros e os respetivos atributos.
Para JSON aninhado, os campos de índice devem ser idênticos aos campos de origem. Atualmente, o Azure AI Search não oferece suporte a mapeamentos de campo para JSON aninhado. Por esse motivo, os nomes de campo e os tipos de dados devem corresponder completamente. O índice a seguir se alinha aos elementos JSON no conteúdo bruto.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "ny-philharmonic-index",
"fields": [
{"name": "programID", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "orchestra", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "season", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{ "name": "concerts", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "eventType", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "Location", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Venue", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Date", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Time", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
},
{ "name": "works", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "ID", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "composerName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "workTitle", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "conductorName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "soloists", "type": "Collection(Edm.String)", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
}
]
}
Pontos principais:
Não é possível usar mapeamentos de campo para reconciliar diferenças em nomes de campos ou tipos de dados. Este esquema de índice foi projetado para espelhar o conteúdo bruto.
JSON aninhado é modelado como
Collection(Edm.ComplextType). No conteúdo bruto, há vários concertos para cada temporada, e várias obras para cada concerto. Para acomodar essa estrutura, use coleções para tipos complexos.No conteúdo bruto, e
Timesão cadeias de caracteres, portanto,Dateos tipos de dados correspondentes no índice também são cadeias de caracteres.
Criar e executar um indexador
Criar indexador cria um indexador no seu serviço de pesquisa. Um indexador se conecta à fonte de dados, carrega e indexa dados e, opcionalmente, fornece um agendamento para automatizar a atualização de dados.
A configuração do indexador inclui o jsonArray modo de análise e um documentRootarquivo .
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-indexer",
"dataSourceName" : "ny-philharmonic-ds",
"targetIndexName" : "ny-philharmonic-index",
"parameters" : {
"configuration" : {
"parsingMode" : "jsonArray", "documentRoot": "/programs"}
},
"fieldMappings" : [
]
}
Pontos principais:
O arquivo de conteúdo bruto contém uma matriz JSON (
"programs") com 1.526 estruturas JSON aninhadas. DefinaparsingModecomojsonArraypara informar ao indexador que cada blob contém uma matriz JSON. Como o JSON aninhado inicia um nível abaixo, definadocumentRootcomo/programs.O indexador é executado por vários minutos. Aguarde a conclusão da execução do indexador antes de executar quaisquer consultas.
Executar consultas
Pode começar a pesquisar assim que o primeiro documento for carregado.
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Envie o pedido. Esta é uma consulta de pesquisa de texto completo não especificada que retorna todos os campos marcados como recuperáveis no índice, juntamente com uma contagem de documentos. A resposta deve ser semelhante a:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a95c4021-f7b4-450b-ba55-596e59ecb6ec
elapsed-time: 106
Date: Wed, 13 Mar 2024 22:09:59 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('ny-philharmonic-index')/$metadata#docs(*)",
"@odata.count": 1521,
"@search.nextPageParameters": {
"search": "*",
"count": true,
"skip": 50
},
"value": [
],
"@odata.nextLink": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01"
}
Adicione um search parâmetro para pesquisar em uma cadeia de caracteres. Adicione um select parâmetro para limitar os resultados a menos campos. Adicione um filter para restringir ainda mais a pesquisa.
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "puccini",
"count": true,
"select": "season, concerts/Date, works/composerName, works/workTitle",
"filter": "season gt '2015-16'"
}
Dois documentos são devolvidos na resposta.
Para filtros, você também pode usar operadores lógicos (e, ou, não) e operadores de comparação (eq, ne, gt, lt, ge, le). As comparações de cadeias são sensíveis às maiúsculas e minúsculas. Para obter mais informações e exemplos, consulte Criar uma consulta.
Nota
O $filter parâmetro só funciona em campos que foram marcados como filtráveis na criação do índice.
Repor e executar novamente
Os indexadores podem ser redefinidos, limpando o histórico de execução, o que permite uma reexecução completa. As seguintes solicitações GET são para redefinição, seguidas de reexecução.
### Reset the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/reset?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/run?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/ny-philharmonic-indexer/status?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
Clean up resources (Limpar recursos)
Quando estiver a trabalhar na sua própria subscrição, no final de um projeto, é uma boa ideia remover os recursos de que já não necessita. Os recursos que deixar em execução podem custar dinheiro. Pode eliminar recursos individualmente ou eliminar o grupo de recursos para eliminar todo o conjunto de recursos.
Você pode usar o portal do Azure para excluir índices, indexadores e fontes de dados.
Próximos passos
Agora que você está familiarizado com os conceitos básicos da indexação de Blob do Azure, vamos examinar mais de perto a configuração do indexador para blobs JSON no Armazenamento do Azure.