Tutorial: Blobs de Markdown aninhados de índice do Armazenamento do Azure usando REST
Nota
Esta funcionalidade está atualmente em pré-visualização pública. Essa visualização é fornecida sem um contrato de nível de serviço e não é recomendada para cargas de trabalho de produção. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas. Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
A Pesquisa de IA do Azure pode indexar documentos e matrizes de Markdown no Armazenamento de Blobs do Azure usando um indexador que sabe como ler dados de Markdown.
Este tutorial mostra como indexar arquivos Markdown indexados usando o oneToMany modo de análise Markdown. Ele usa um cliente REST e as APIs REST de pesquisa para executar as seguintes tarefas:
- Configurar dados de exemplo e configurar uma fonte de
azureblobdados - Criar um índice do Azure AI Search para conter conteúdo pesquisável
- Criar e executar um indexador para ler o contêiner e extrair conteúdo pesquisável
- Pesquisar o índice que acabou de criar
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
Azure AI Search. Crie ou localize um recurso existente do Azure AI Search em sua assinatura atual.
Nota
Você pode usar o serviço gratuito para este tutorial. Um serviço de pesquisa gratuito limita você a três índices, três indexadores e três fontes de dados. Este tutorial cria um de cada. Antes de começar, certifique-se de que tem espaço no seu serviço para aceitar os novos recursos.
Criar um documento Markdown
Copie e cole o Markdown a seguir em um arquivo chamado sample_markdown.md. Os dados de exemplo são um único arquivo Markdown contendo vários elementos Markdown. Escolhemos um arquivo Markdown para ficar abaixo dos limites de armazenamento do nível gratuito.
# Project Documentation
## Introduction
This document provides a complete overview of the **Markdown Features** used within this project. The following sections demonstrate the richness of Markdown formatting, with examples of lists, tables, links, images, blockquotes, inline styles, and more.
---
## Table of Contents
1. [Headers](#headers)
2. [Introduction](#introduction)
3. [Basic Text Formatting](#basic-text-formatting)
4. [Lists](#lists)
5. [Blockquotes](#blockquotes)
6. [Images](#images)
7. [Links](#links)
8. [Tables](#tables)
9. [Code Blocks and Inline Code](#code-blocks-and-inline-code)
10. [Horizontal Rules](#horizontal-rules)
11. [Inline Elements](#inline-elements)
12. [Escaping Characters](#escaping-characters)
13. [HTML Elements](#html-elements)
14. [Emojis](#emojis)
15. [Footnotes](#footnotes)
16. [Task Lists](#task-lists)
17. [Conclusion](#conclusion)
---
## Headers
Markdown supports six levels of headers. Use `#` to create headers:
"# Project Documentation" at the top of the document is an example of an h1 header.
"## Headers" above is an example of an h2 header.
### h3 example
#### h4 example
##### h5 example
###### h6 example
This is an example of content underneath a header.
## Basic Text Formatting
You can apply various styles to your text:
- **Bold**: Use double asterisks or underscores: `**bold**` or `__bold__`.
- *Italic*: Use single asterisks or underscores: `*italic*` or `_italic_`.
- ~~Strikethrough~~: Use double tildes: `~~strikethrough~~`.
## Lists
### Ordered List
1. First item
2. Second item
3. Third item
### Unordered List
- Item A
- Item B
- Item C
### Nested List
1. Parent item
- Child item
- Child item
## Blockquotes
> This is a blockquote.
> Blockquotes are great for emphasizing important information.
>> Nested blockquotes are also possible!
## Images

## Links
[Visit Markdown Guide](https://www.markdownguide.org)
## Tables
| Syntax | Description | Example |
|-------------|-------------|---------------|
| Header | Title | Header Cell |
| Paragraph | Text block | Row Content |
## Code Blocks and Inline Code
### Inline Code
Use backticks to create `inline code`.
### Code Block
```javascript
// JavaScript example
function greet(name) {
console.log(`Hello, ${name}!`);
}
greet('World');
```
## Horizontal Rules
Use three or more dashes or underscores to create a horizontal rule.
---
___
## Inline Elements
Sometimes, it’s useful to include `inline code` to highlight code-like content.
You can also emphasize text like *this* or make it **bold**.
## Escaping Characters
To render special Markdown characters, use backslashes:
- \*Asterisks\*
- \#Hashes\#
- \[Brackets\]
## HTML Elements
You can mix HTML tags with Markdown:
<table>
<tr>
<th>HTML Table</th>
<th>With Markdown</th>
</tr>
<tr>
<td>Row 1</td>
<td>Data 1</td>
</tr>
</table>
## Emojis
Markdown supports some basic emojis:
- :smile: 😄
- :rocket: 🚀
- :checkered_flag: 🏁
## Footnotes
This is an example of a footnote[^1]. Footnotes allow you to add notes without cluttering the main text.
[^1]: This is the content of the footnote.
## Task Lists
- [x] Complete the introduction
- [ ] Add more examples
- [ ] Review the document
## Conclusion
Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.
Thank you for reviewing this example!
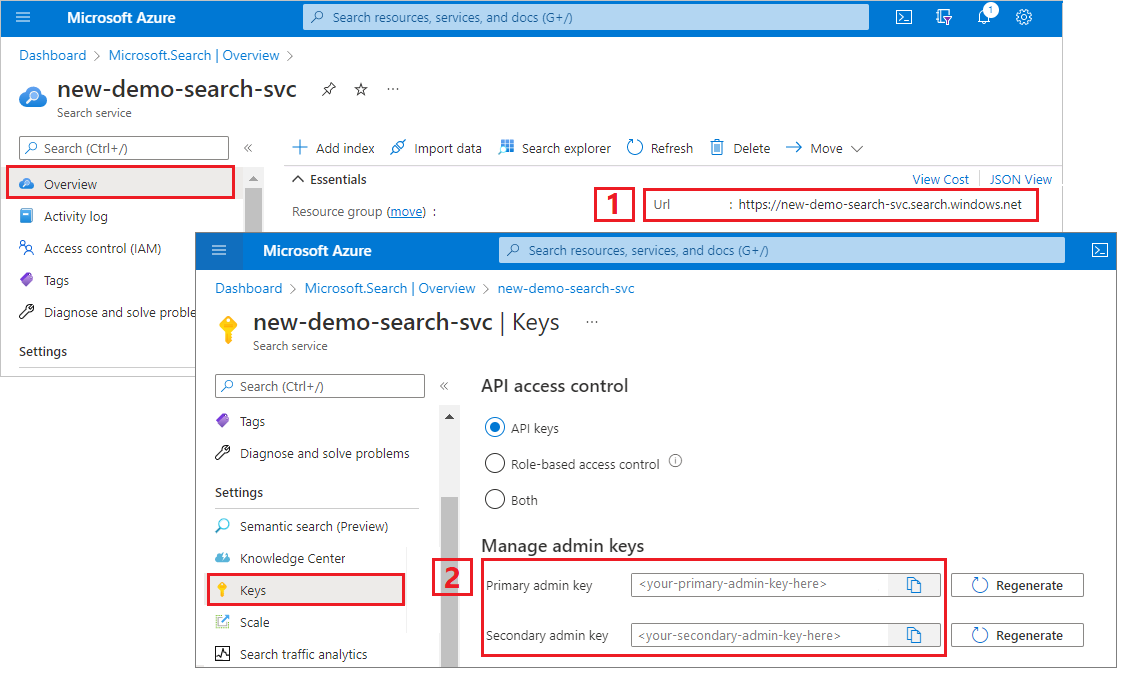
Copiar um URL de serviço de pesquisa e uma chave de API
Para este tutorial, as conexões com o Azure AI Search exigem um ponto de extremidade e uma chave de API. Você pode obter esses valores no portal do Azure. Para métodos de conexão alternativos, consulte identidades gerenciadas.
Entre no portal do Azure, navegue até a página Visão geral do serviço de pesquisa e copie a URL. Um ponto final de exemplo poderá ser parecido com
https://mydemo.search.windows.net.Em Teclas de Configurações>, copie uma chave de administrador. As chaves de administrador são usadas para adicionar, modificar e excluir objetos. Existem duas chaves de administração intercambiáveis. Copie qualquer uma delas.
Configurar o arquivo REST
Inicie o Visual Studio Code e crie um novo arquivo.
Forneça valores para as variáveis usadas na solicitação:
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnectionString = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HERESalve o arquivo usando uma
.restextensão de arquivo ou.http.
Consulte Guia de início rápido: pesquisa de texto usando REST se precisar de ajuda com o cliente REST.
Criar uma origem de dados
Create Data Source (REST) cria uma conexão de fonte de dados que especifica quais dados indexar.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Envie o pedido. A resposta deve ser semelhante a:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DCF52E926A3C76"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('sample-markdown-ds')?api-version=2024-11-01-preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 0714c187-217e-4d35-928a-5069251e5cba
elapsed-time: 204
Date: Fri, 25 Oct 2024 19:52:35 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DCF52E926A3C76\"",
"name": "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "markdown-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
Criar um índice
Criar índice (REST) cria um índice de pesquisa no seu serviço de pesquisa. Um índice especifica todos os campos e seus atributos.
Na análise um-para-muitos, o documento de pesquisa define o lado "muitos" da relação. Os campos especificados no índice determinam a estrutura do documento de pesquisa.
Você só precisa de campos para os elementos Markdown suportados pelo analisador. Estes campos são:
content: Uma cadeia de caracteres que contém a marcação bruta encontrada em um local específico, com base nos metadados do cabeçalho nesse ponto do documento.sections: Um objeto que contém subcampos para os metadados do cabeçalho até o nível de cabeçalho desejado. Por exemplo, quandomarkdownHeaderDepthé definido comoh3, contém camposh1de cadeia de caracteres ,h2eh3. Estes campos são indexados espelhando esta estrutura no índice, ou através de mapeamentos de campo no formato/sections/h1,sections/h2, etc. Consulte as configurações de índice e indexador nos exemplos a seguir para obter exemplos no contexto. Os subcampos contidos são:-
h1- Uma cadeia de caracteres que contém o valor do cabeçalho h1. Cadeia de caracteres vazia se não estiver definida neste ponto do documento. - (Opcional)
h2- Uma string contendo o valor do cabeçalho h2. Cadeia de caracteres vazia se não estiver definida neste ponto do documento. - (Opcional)
h3- Uma string contendo o valor do cabeçalho h3. Cadeia de caracteres vazia se não estiver definida neste ponto do documento. - (Opcional)
h4- Uma string contendo o valor do cabeçalho h4. Cadeia de caracteres vazia se não estiver definida neste ponto do documento. - (Opcional)
h5- Uma string contendo o valor do cabeçalho h5. Cadeia de caracteres vazia se não estiver definida neste ponto do documento. - (Opcional)
h6- Uma string contendo o valor do cabeçalho h6. Cadeia de caracteres vazia se não estiver definida neste ponto do documento.
-
ordinal_position: Um valor inteiro que indica a posição da seção dentro da hierarquia do documento. Este campo é utilizado para ordenar as secções na sua sequência original tal como aparecem no documento, começando com uma posição ordinal de 1 e incrementando sequencialmente para cada bloco de conteúdo.
Essa implementação aproveita os mapeamentos de campo no indexador para mapear do conteúdo enriquecido para o índice. Para obter mais informações sobre a estrutura de documento um-para-muitos analisada, consulte blobs de marcação de índice.
Este exemplo fornece exemplos de como indexar dados com e sem mapeamentos de campo. Neste caso, sabemos que h1 contém o título do documento, para que possamos mapeá-lo para um campo chamado title. Também mapearemos os h2 campos e h3 para h2_subheader e h3_subheader respectivamente. Os content campos e ordinal_position não requerem mapeamento porque são extraídos do Markdown diretamente para campos usando esses nomes. Para obter um exemplo de um esquema de índice completo que não requer mapeamentos de campo, consulte o final desta seção.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "title", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Esquema de índice em uma configuração sem mapeamentos de campo
Os mapeamentos de campo permitem que você manipule e filtre o conteúdo enriquecido para se ajustar à forma de índice desejada, mas talvez você queira apenas obter o conteúdo enriquecido diretamente. Nesse caso, o esquema teria a seguinte aparência:
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "sections",
"type": "Edm.ComplexType",
"fields": [
{"name": "h1", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Para reiterar, temos subcampos até h3 no objeto sections porque markdownHeaderDepth está definido como h3.
Se você optar por usar esse esquema, certifique-se de ajustar as solicitações posteriores de acordo. Isso exigirá a remoção dos mapeamentos de campo da configuração do indexador e a atualização das consultas de pesquisa para usar os nomes de campo correspondentes.
Criar e executar um indexador
Criar indexador cria um indexador no seu serviço de pesquisa. Um indexador se conecta à fonte de dados, carrega e indexa dados e, opcionalmente, fornece um agendamento para automatizar a atualização de dados.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-indexer",
"dataSourceName": "sample-markdown-ds",
"targetIndexName": "sample-markdown-index",
"parameters" : {
"configuration": {
"parsingMode": "markdown",
"markdownParsingSubmode": "oneToMany",
"markdownHeaderDepth": "h3"
}
},
"fieldMappings" : [
{
"sourceFieldName": "/sections/h1",
"targetFieldName": "title",
"mappingFunction": null
}
]
}
Pontos principais:
O indexador analisará apenas cabeçalhos até
h3. Quaisquer cabeçalhos de nível inferior (h4,h5,h6) serão tratados como texto simples e aparecerão nocontentcampo. É por isso que os mapeamentos de índice e campo só existem até uma profundidade deh3.Os
contentcampos eordinal_positionnão requerem mapeamento de campo, pois existem com esses nomes no conteúdo enriquecido.
Executar consultas
Pode começar a pesquisar assim que o primeiro documento for carregado.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Envie o pedido. Esta é uma consulta de pesquisa de texto completo não especificada que retorna todos os campos marcados como recuperáveis no índice, juntamente com uma contagem de documentos. A resposta deve ser semelhante a:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 6b94e605-55e8-47a5-ae15-834f926ddd14
elapsed-time: 77
Date: Fri, 25 Oct 2024 20:22:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 22,
"value": [
<22 search documents here>
]
}
Adicione um search parâmetro para pesquisar em uma cadeia de caracteres.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "h4",
"count": true,
}
Envie o pedido. A resposta deve ser semelhante a:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: ec5d03f1-e3e7-472f-9396-7ff8e3782105
elapsed-time: 52
Date: Fri, 25 Oct 2024 20:26:29 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 0.8744742,
"section_id": "aHR0cHM6Ly9hcmphZ2Fubmpma2ZpbGVzLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tYXJrZG93bi10dXRvcmlhbC9zYW1wbGVfbWFya2Rvd24ubWQ7NA2",
"content": "#### h4 example\r\n##### h5 example\r\n###### h6 example\r\nThis is an example of content underneath a header.\r\n",
"title": "Project Documentation",
"h2_subheader": "Headers",
"h3_subheader": "h3 example",
"ordinal_position": 4
}
]
}
Pontos principais:
Como o
markdownHeaderDepthestá definido comoh3, oh4,h5eh6os cabeçalhos são tratados como texto sem formatação, por isso aparecem nocontentcampo.A posição ordinal aqui é
4. Este conteúdo aparece em quarto lugar entre as 22 seções de conteúdo total.
Adicione um select parâmetro para limitar os resultados a menos campos. Adicione um filter para restringir ainda mais a pesquisa.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "Markdown",
"count": true,
"select": "title, content, h2_subheader",
"filter": "h2_subheader eq 'Conclusion'"
}
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a6f9bd46-a064-4e28-818f-ea077618014b
elapsed-time: 35
Date: Fri, 25 Oct 2024 20:36:10 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 1.1029507,
"content": "Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.\r\n\r\nThank you for reviewing this example!",
"title": "Project Documentation",
"h2_subheader": "Conclusion"
}
]
}
Para filtros, você também pode usar operadores lógicos (e, ou, não) e operadores de comparação (eq, ne, gt, lt, ge, le). As comparações de cadeias são sensíveis às maiúsculas e minúsculas. Para obter mais informações e exemplos, consulte Criar uma consulta.
Nota
O $filter parâmetro só funciona em campos que foram marcados como filtráveis na criação do índice.
Repor e executar novamente
Os indexadores podem ser redefinidos, limpando o histórico de execução, o que permite uma reexecução completa. As seguintes solicitações GET são para redefinição, seguidas de reexecução.
### Reset the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/reset?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/run?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/sample-markdown-indexer/status?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
Clean up resources (Limpar recursos)
Quando estiver a trabalhar na sua própria subscrição, no final de um projeto, é uma boa ideia remover os recursos de que já não necessita. Os recursos que deixar em execução podem custar dinheiro. Pode eliminar recursos individualmente ou eliminar o grupo de recursos para eliminar todo o conjunto de recursos.
Você pode usar o portal do Azure para excluir índices, indexadores e fontes de dados.
Próximos passos
Agora que você está familiarizado com os conceitos básicos da indexação de Blob do Azure, vamos examinar mais de perto a configuração do indexador para blobs Markdown no Armazenamento do Azure.