Adicionar perfis de pontuação para aumentar as pontuações de pesquisa
Os perfis de pontuação permitem-lhe aumentar a classificação dos documentos correspondentes com base em critérios. Neste artigo, saiba como especificar e atribuir um perfil de pontuação que aumenta uma pontuação de pesquisa com base nos parâmetros fornecidos.
Você pode usar perfis de pontuação para pesquisa de palavras-chave, pesquisa vetorial e pesquisa híbrida. No entanto, os perfis de pontuação só se aplicam a campos não vetoriais, portanto, certifique-se de que seu índice tenha campos numéricos ou de texto que possam ser usados em um perfil de pontuação. O suporte de perfil de pontuação para pesquisa vetorial e híbrida está disponível nas APIs REST 2024-05-01-preview e 2024-07-01 e nos pacotes do SDK do Azure direcionados a essas versões.
Pontos-chave sobre a pontuação de perfis
Os parâmetros do perfil de pontuação são:
Campos ponderados, onde uma correspondência é encontrada em um campo de cadeia de caracteres específico. Por exemplo, você pode querer que as correspondências encontradas em um campo "resumo" sejam mais relevantes do que a mesma correspondência encontrada em um campo "conteúdo".
Funções para dados numéricos, incluindo datas, intervalos e coordenadas geográficas. Há também uma função Tags que opera em um campo fornecendo uma coleção arbitrária de cadeias de caracteres. Você pode escolher essa abordagem em vez de campos ponderados se quiser aumentar uma pontuação com base no fato de uma correspondência ser encontrada em um campo de tags.
Você pode criar vários perfis e, em seguida, modificar a lógica de consulta para escolher qual deles será usado.
Você pode ter até 100 perfis de pontuação em um índice (consulte Limites de serviço), mas só pode especificar um perfil de cada vez em qualquer consulta.
Você pode usar o classificador semântico com perfis de pontuação. Quando vários recursos de classificação ou relevância estão em jogo, a classificação semântica é a última etapa. Como funciona a pontuação de pesquisa fornece uma ilustração.
Nota
Não está familiarizado com conceitos de relevância? Visite Relevância e pontuação na Pesquisa de IA do Azure para obter plano de fundo. Você também pode assistir a este segmento de vídeo no YouTube para pontuar perfis sobre os resultados classificados no BM25.
Definição do perfil de pontuação
Um perfil de pontuação é nomeado objeto definido em um esquema de índice. Um perfil de pontuação é composto por campos ponderados, funções e parâmetros.
A definição a seguir mostra um perfil simples chamado "geo". Este exemplo impulsiona os resultados que têm o termo de pesquisa no campo hotelName. Ele também usa a distance função para favorecer resultados que estão a menos de 10 quilômetros da localização atual. Se alguém pesquisar o termo "pousada" e "pousada" fizer parte do nome do hotel, os documentos que incluem hotéis com "pousada" em um raio de 10 KM da localização atual aparecerão mais acima nos resultados da pesquisa.
"scoringProfiles": [
{
"name":"geo",
"text": {
"weights": {
"hotelName": 5
}
},
"functions": [
{
"type": "distance",
"boost": 5,
"fieldName": "location",
"interpolation": "logarithmic",
"distance": {
"referencePointParameter": "currentLocation",
"boostingDistance": 10
}
}
]
}
]
Para usar esse perfil de pontuação, sua consulta é formulada para especificar o parâmetro scoringProfile na solicitação. Se você estiver usando a API REST, as consultas serão especificadas por meio de solicitações GET e POST. No exemplo a seguir, "currentLocation" tem um delimitador de um único traço (-). É seguido pelas coordenadas de longitude e latitude, onde longitude é um valor negativo.
GET /indexes/hotels/docs?search+inn&scoringProfile=geo&scoringParameter=currentLocation--122.123,44.77233&api-version=2024-07-01
Observe as diferenças de sintaxe ao usar o POST. No POST, "scoringParameters" é plural e é uma matriz.
POST /indexes/hotels/docs&api-version=2024-07-01
{
"search": "inn",
"scoringProfile": "geo",
"scoringParameters": ["currentLocation--122.123,44.77233"]
}
Esta consulta pesquisa o termo "pousada" e passa no local atual. Observe que essa consulta inclui outros parâmetros, como scoringParameter. Os parâmetros de consulta, incluindo "scoringParameter", são descritos em Pesquisar documentos (API REST).
Consulte o exemplo estendido para pesquisa vetorial e híbrida e o exemplo estendido para pesquisa de palavras-chave para mais cenários.
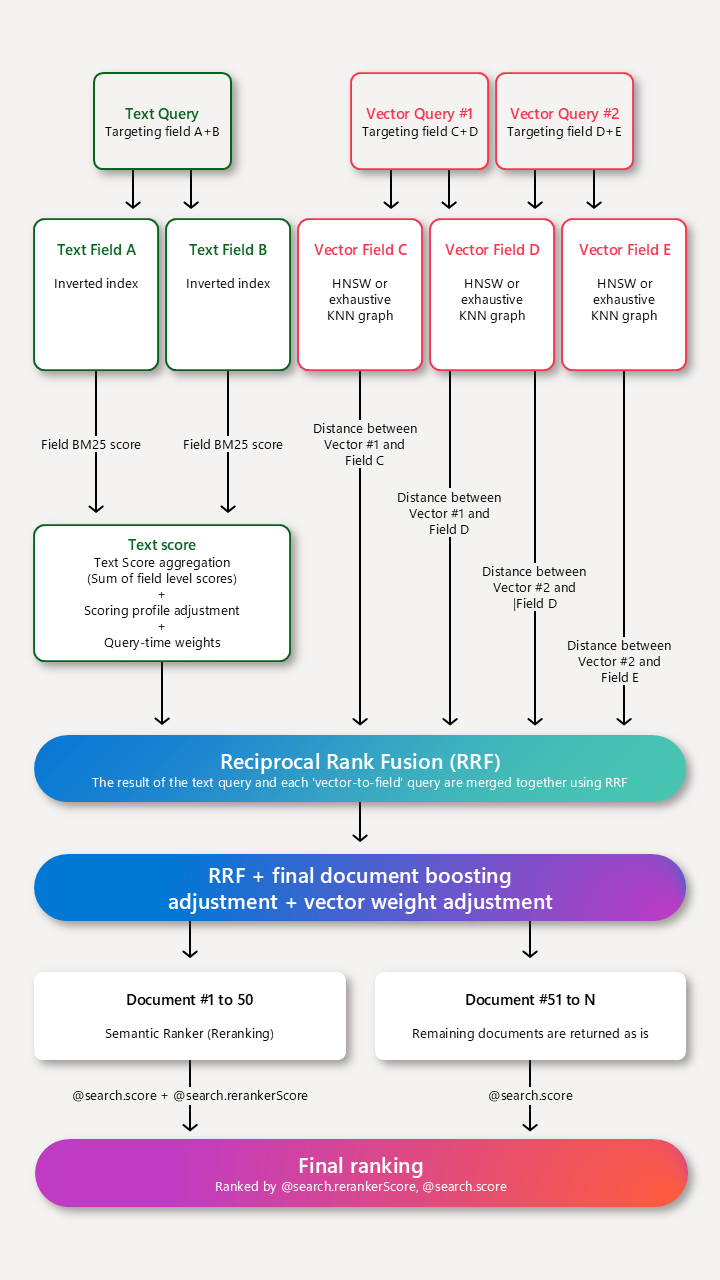
Como funciona a pontuação de pesquisa na Pesquisa de IA do Azure
Os perfis de pontuação complementam o algoritmo de pontuação padrão, aumentando as pontuações das correspondências que atendem aos critérios do perfil. As funções de pontuação aplicam-se a:
- Pesquisa de texto (palavra-chave)
- Consultas vetoriais puras
- Consultas híbridas, com subconsultas de texto e vetoriais executadas em paralelo
Para consultas de texto autônomas, os perfis de pontuação identificam o máximo de 1.000 correspondências em uma pesquisa classificada como BM25, e as 50 melhores são retornadas nos resultados.
Para vetores puros, a consulta é somente vetorial, mas se os documentos de correspondência k incluírem campos não vetoriais com ocntente legível por humanos, um perfil de pontuação pode ser aplicado. O perfil de pontuação revisa o conjunto de resultados impulsionando documentos que correspondem aos critérios no perfil.
Para consultas de texto em uma consulta híbrida, os perfis de pontuação identificam o máximo de 1.000 correspondências em uma pesquisa classificada como BM25. No entanto, uma vez que esses 1.000 resultados são identificados, eles são restaurados para sua ordem BM25 original para que possam ser repontuados ao lado dos resultados dos vetores na ordem final da Função de Classificação Recíproca (RRF), onde o perfil de pontuação (identificado como "ajuste de reforço de documento final" na ilustração) é aplicado aos resultados mesclados, juntamente com a ponderação vetorial e a classificação semântica como a última etapa.
Adicionar um perfil de pontuação a um índice de pesquisa
Comece com uma definição de índice. Você pode adicionar e atualizar perfis de pontuação em um índice existente sem precisar reconstruí-lo. Use uma solicitação Criar ou Atualizar Índice para postar uma revisão.
Cole no modelo fornecido neste artigo.
Forneça um nome que siga as convenções de nomenclatura.
Especifique os critérios de reforço. Um único perfil pode conter campos ponderados de texto, funções ou ambos.
Você deve trabalhar iterativamente, usando um conjunto de dados que o ajudará a provar ou refutar a eficácia de um determinado perfil.
Os perfis de pontuação podem ser definidos no portal do Azure, conforme mostrado na captura de tela a seguir, ou programaticamente por meio de APIs REST ou em SDKs do Azure, como a classe ScoringProfile no SDK do Azure para .NET.

Usar campos ponderados por texto
Use campos ponderados por texto quando o contexto do campo for importante e as consultas incluírem searchable campos de cadeia de caracteres. Por exemplo, se uma consulta incluir o termo "aeroporto", talvez você queira que "aeroporto" no campo Descrição tenha mais peso do que no HotelName.
Os campos ponderados são pares nome-valor compostos por um searchable campo e um número positivo que é usado como multiplicador. Se a pontuação de campo original de HotelName for 3, a pontuação impulsionada para esse campo se tornará 6, contribuindo para uma pontuação geral mais alta para o próprio documento pai.
"scoringProfiles": [
{
"name": "boostSearchTerms",
"text": {
"weights": {
"HotelName": 2,
"Description": 5
}
}
}
]
Utilizar funções
Use funções quando pesos relativos simples são insuficientes ou não se aplicam, como é o caso da distância e do frescor, que são cálculos sobre dados numéricos. Você pode especificar várias funções por perfil de pontuação. Para obter mais informações sobre os tipos de dados EDM usados no Azure AI Search, consulte Tipos de dados suportados.
| Function | Description | Casos de utilização |
|---|---|---|
| Distância | Impulsione pela proximidade ou localização geográfica. Esta função só pode ser usada com Edm.GeographyPoint campos. |
Use para cenários de "encontrar perto de mim". |
| frescura | Aumentar por valores em um campo datetime (Edm.DateTimeOffset).
Defina boostingDuration para especificar um valor que represente um período de tempo durante o qual o impulsionamento ocorre. |
Use quando quiser impulsionar por datas mais recentes ou mais antigas. Classifique itens como eventos de calendário com datas futuras, de modo que os itens mais próximos do presente possam ser classificados mais alto do que os itens mais adiante no futuro. Uma extremidade do intervalo é fixada à hora atual. Para aumentar uma série de vezes no passado, use um boostingDuration positivo. Para impulsionar uma série de vezes no futuro, use um boostingDuration negativo. |
| magnitude | Alterar classificações com base no intervalo de valores para um campo numérico. O valor deve ser um número inteiro ou de vírgula flutuante. Para classificações de estrelas de 1 a 4, isso seria 1. Para margens superiores a 50%, seriam 50. Esta função só pode ser usada com Edm.Double e Edm.Int campos. Para a função de magnitude, você pode inverter o intervalo, de alto para baixo, se quiser o padrão inverso (por exemplo, para impulsionar itens com preços mais baixos do que itens com preços mais altos). Dada uma faixa de preços de US $ 100 a US $ 1, você definiria boostingRangeStart em 100 e boostingRangeEnd em 1 para impulsionar os itens de preço mais baixo. |
Use quando quiser aumentar por margem de lucro, classificações, contagem de cliques, número de downloads, preço mais alto, preço mais baixo ou contagem de downloads. Quando dois itens forem relevantes, o item com a classificação mais alta será exibido primeiro. |
| etiqueta | Impulsione por tags que são comuns a documentos de pesquisa e cadeias de caracteres de consulta. As tags são fornecidas em um tagsParameterarquivo . Esta função só pode ser usada com campos de pesquisa do tipo Edm.String e Collection(Edm.String). |
Use quando tiver campos de tag. Se uma determinada tag dentro da lista for uma lista delimitada por vírgula, você poderá usar um normalizador de texto no campo para remover as vírgulas no momento da consulta (mapear o caractere de vírgula para um espaço). Esta abordagem irá "nivelar" a lista de modo a que todos os termos sejam uma única e longa cadeia de termos delimitados por vírgula. |
Regras para o uso de funções
- As funções só podem ser aplicadas a campos atribuídos como
filterable. - O tipo de função ("frescura", "magnitude", "distância", "etiqueta") deve ser minúsculo.
- As funções não podem incluir valores nulos ou vazios.
- As funções só podem ter um único campo por definição de função. Para usar magnitude duas vezes no mesmo perfil, forneça duas definições de magnitude, uma para cada campo.
Template
Esta seção mostra a sintaxe e o modelo para perfis de pontuação. Para obter uma descrição das propriedades, consulte a referência da API REST.
"scoringProfiles": [
{
"name": "name of scoring profile",
"text": (optional, only applies to searchable fields) {
"weights": {
"searchable_field_name": relative_weight_value (positive #'s),
...
}
},
"functions": (optional) [
{
"type": "magnitude | freshness | distance | tag",
"boost": # (positive number used as multiplier for raw score != 1),
"fieldName": "(...)",
"interpolation": "constant | linear (default) | quadratic | logarithmic",
"magnitude": {
"boostingRangeStart": #,
"boostingRangeEnd": #,
"constantBoostBeyondRange": true | false (default)
}
// ( - or -)
"freshness": {
"boostingDuration": "..." (value representing timespan over which boosting occurs)
}
// ( - or -)
"distance": {
"referencePointParameter": "...", (parameter to be passed in queries to use as reference location)
"boostingDistance": # (the distance in kilometers from the reference location where the boosting range ends)
}
// ( - or -)
"tag": {
"tagsParameter": "..."(parameter to be passed in queries to specify a list of tags to compare against target field)
}
}
],
"functionAggregation": (optional, applies only when functions are specified) "sum (default) | average | minimum | maximum | firstMatching"
}
],
"defaultScoringProfile": (optional) "...",
Definir interpolações
As interpolações definem a forma da inclinação usada para pontuação. Como a pontuação é alta a baixa, a inclinação está sempre diminuindo, mas a interpolação determina a curva da inclinação descendente. Podem ser utilizadas as seguintes interpolações:
| Interpolação | Description |
|---|---|
linear |
Para itens que estão dentro da faixa máxima e mínima, o aumento é aplicado em uma quantidade constantemente decrescente. Linear é a interpolação padrão para um perfil de pontuação. |
constant |
Para itens que estão dentro do intervalo inicial e final, um impulso constante é aplicado aos resultados de classificação. |
quadratic |
Em comparação com uma interpolação linear que tem um impulso constantemente decrescente, o Quadratic inicialmente diminui em um ritmo menor e, em seguida, à medida que se aproxima da faixa final, diminui em um intervalo muito maior. Essa opção de interpolação não é permitida em funções de pontuação de tags. |
logarithmic |
Em comparação com uma interpolação linear que tem um impulso constantemente decrescente, a logarítmica inicialmente diminui em ritmo mais alto e, em seguida, à medida que se aproxima da faixa final, diminui em um intervalo muito menor. Essa opção de interpolação não é permitida em funções de pontuação de tags. |

Definir boostingDuration para a função de frescura
boostingDuration é um atributo da freshness função. Você o usa para definir um período de expiração após o qual o impulsionamento será interrompido para um documento específico. Por exemplo, para impulsionar uma linha de produtos ou marca para um período promocional de 10 dias, você deve especificar o período de 10 dias como "P10D" para esses documentos.
boostingDuration deve ser formatado como um valor XSD "dayTimeDuration" (um subconjunto restrito de um valor de duração ISO 8601). O padrão para isso é: "P[nD][T[nH][nM][nS]]".
A tabela a seguir fornece vários exemplos.
| Duração | boostingDuração |
|---|---|
| 1 dia | "P1D" |
| 2 dias e 12 horas | "P2DT12H" |
| 15 minutos | "PT15M" |
| 30 dias, 5 horas, 10 minutos e 6,334 segundos | "P30DT5H10M6.334S" |
Para obter mais exemplos, consulte Esquema XML: Tipos de dados (W3.org site).
Exemplo estendido para pesquisa vetorial e híbrida
Veja esta postagem de blog e caderno para uma demonstração do uso de perfis de pontuação e impulsionamento de documentos em cenários de IA vetorial e generativa.
Exemplo estendido para pesquisa por palavra-chave
O exemplo a seguir mostra o esquema de um índice com dois perfis de pontuação (boostGenre, newAndHighlyRated). Qualquer consulta em relação a esse índice que inclua qualquer perfil como um parâmetro de consulta usará o perfil para pontuar o conjunto de resultados.
O boostGenre perfil usa campos de texto ponderados, aumentando as correspondências encontradas nos campos albumTitle, genre e artistName. Os campos são impulsionados 1,5, 5 e 2, respectivamente. Por que o gênero é impulsionado tão mais alto do que os outros? Se a pesquisa for realizada sobre dados um pouco homogêneos (como é o caso de 'gênero' no musicstoreindex), você pode precisar de uma variação maior nos pesos relativos. Por exemplo, no musicstoreindex, 'rock' aparece como um gênero e em descrições de gênero com frases idênticas. Se você quiser que o gênero supere a descrição do gênero, o campo de gênero precisará de um peso relativo muito maior.
{
"name": "musicstoreindex",
"fields": [
{ "name": "key", "type": "Edm.String", "key": true },
{ "name": "albumTitle", "type": "Edm.String" },
{ "name": "albumUrl", "type": "Edm.String", "filterable": false },
{ "name": "genre", "type": "Edm.String" },
{ "name": "genreDescription", "type": "Edm.String", "filterable": false },
{ "name": "artistName", "type": "Edm.String" },
{ "name": "orderableOnline", "type": "Edm.Boolean" },
{ "name": "rating", "type": "Edm.Int32" },
{ "name": "tags", "type": "Collection(Edm.String)" },
{ "name": "price", "type": "Edm.Double", "filterable": false },
{ "name": "margin", "type": "Edm.Int32", "retrievable": false },
{ "name": "inventory", "type": "Edm.Int32" },
{ "name": "lastUpdated", "type": "Edm.DateTimeOffset" }
],
"scoringProfiles": [
{
"name": "boostGenre",
"text": {
"weights": {
"albumTitle": 1.5,
"genre": 5,
"artistName": 2
}
}
},
{
"name": "newAndHighlyRated",
"functions": [
{
"type": "freshness",
"fieldName": "lastUpdated",
"boost": 10,
"interpolation": "quadratic",
"freshness": {
"boostingDuration": "P365D"
}
},
{
"type": "magnitude",
"fieldName": "rating",
"boost": 10,
"interpolation": "linear",
"magnitude": {
"boostingRangeStart": 1,
"boostingRangeEnd": 5,
"constantBoostBeyondRange": false
}
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [ "albumTitle", "artistName" ]
}
]
}