Confiabilidade no Microsoft Fabric
Este artigo descreve o suporte à confiabilidade no Microsoft Fabric e a resiliência regional com zonas de disponibilidade, recuperação entre regiões e continuidade de negócios. Para obter uma visão geral mais detalhada da confiabilidade no Azure, consulte Confiabilidade do Azure.
Suporte à zona de disponibilidade
As zonas de disponibilidade são grupos fisicamente separados de datacenters dentro de cada região do Azure. Quando uma zona falha, os serviços podem fazer failover para uma das zonas restantes.
Para obter mais informações sobre zonas de disponibilidade no Azure, consulte O que são zonas de disponibilidade?
A malha faz esforços comercialmente razoáveis para oferecer suporte a zonas de disponibilidade com redundância de zona, onde os recursos são replicados automaticamente entre zonas, sem a necessidade de você configurar ou configurar.
Pré-requisitos
- Atualmente, o Fabric oferece suporte parcial à zona de disponibilidade em um número limitado de regiões. Este suporte parcial da zona de disponibilidade abrange experiências (e/ou certas funcionalidades dentro de uma experiência).
- Experiências como Fluxos de Eventos não suportam zonas de disponibilidade.
- A engenharia de dados suporta zonas de disponibilidade se você usar o OneLake. Se você usar outras fontes de dados, como o ADLS Gen2, precisará garantir que o armazenamento com redundância de zona (ZRS) esteja habilitado.
- A disponibilidade da zona pode ou não estar disponível para experiências e/ou recursos/funcionalidades do Fabric que estão em visualização.
- Gateways locais e modelos semânticos grandes no Power BI não oferecem suporte a zonas de disponibilidade.
- O Data Factory (pipelines) suporta zonas de disponibilidade na Europa Ocidental, mas as execuções de pipelines novos ou em andamento podem falhar em caso de interrupção da zona.
Regiões suportadas
A Fabric faz esforços comercialmente razoáveis para fornecer suporte à zona de disponibilidade em várias regiões, da seguinte forma:
| Américas | Power BI | Datamarts | Armazéns de Dados | Análise em tempo real | Data Factory (pipelines) | Engenharia de Dados | Base de Dados SQL |
|---|---|---|---|---|---|---|---|
| Sul do Brasil | |||||||
| Canadá Central | |||||||
| E.U.A. Central | |||||||
| E.U.A. Leste | |||||||
| E.U.A. Leste 2 | |||||||
| E.U.A. Centro-Sul | |||||||
| E.U.A. Oeste 2 | |||||||
| EUA Oeste 3 | |||||||
| Europa | Power BI | Datamarts | Armazéns de Dados | Análise em tempo real | Data Factory (pipelines) | Engenharia de Dados | Base de Dados SQL |
| França Central | |||||||
| Alemanha Centro-Oeste | |||||||
| Norte da Itália | |||||||
| Europa do Norte | |||||||
| Leste da Noruega | |||||||
| Polónia Central | |||||||
| Sul do Reino Unido | |||||||
| Europa Ocidental | |||||||
| Suécia Central | |||||||
| Médio Oriente | Power BI | Datamarts | Armazéns de Dados | Análise em tempo real | Data Factory (pipelines) | Engenharia de Dados | Base de Dados SQL |
| Catar Central | |||||||
| Israel Central | |||||||
| África | Power BI | Datamarts | Armazéns de Dados | Análise em tempo real | Data Factory (pipelines) | Engenharia de Dados | Base de Dados SQL |
| Norte da África do Sul | |||||||
| Ásia-Pacífico | Power BI | Datamarts | Armazéns de Dados | Análise em tempo real | Data Factory (pipelines) | Engenharia de Dados | Base de Dados SQL |
| Leste da Austrália | |||||||
| Leste do Japão | |||||||
| Sudeste Asiático |
Experiência de zoneamento
Durante uma interrupção em toda a zona, nenhuma ação é necessária durante a recuperação da zona. Os recursos de malha em regiões listadas em regiões suportadas se auto-recuperam e reequilibram automaticamente para aproveitar a zona íntegra. A execução de trabalhos do Spark pode falhar se o nó principal estiver na zona com falha. Nesse caso, os trabalhos terão de ser reenviados.
Importante
Embora a Microsoft se esforce para fornecer suporte uniforme e consistente à zona de disponibilidade, em alguns casos de falha na zona de disponibilidade, as capacidades de malha localizadas em regiões do Azure com flutuações de demanda do cliente mais altas podem ter latência maior do que o normal.
Recuperação de desastres entre regiões e continuidade de negócios
A recuperação de desastres (DR) consiste na recuperação de eventos de alto impacto, como desastres naturais ou implantações com falha que resultam em tempo de inatividade e perda de dados. Independentemente da causa, a melhor solução para um desastre é um plano de DR bem definido e testado e um design de aplicativo que suporte ativamente a DR. Antes de começar a pensar em criar seu plano de recuperação de desastres, consulte Recomendações para projetar uma estratégia de recuperação de desastres.
Quando se trata de DR, a Microsoft usa o modelo de responsabilidade compartilhada. Em um modelo de responsabilidade compartilhada, a Microsoft garante que a infraestrutura de linha de base e os serviços da plataforma estejam disponíveis. Ao mesmo tempo, muitos serviços do Azure não replicam dados automaticamente ou recorrem de uma região com falha para replicação cruzada para outra região habilitada. Para esses serviços, você é responsável por configurar um plano de recuperação de desastres que funcione para sua carga de trabalho. A maioria dos serviços executados nas ofertas de plataforma como serviço (PaaS) do Azure fornecem recursos e orientação para dar suporte à DR e você pode usar recursos específicos do serviço para dar suporte à recuperação rápida para ajudar a desenvolver seu plano de DR.
Esta seção descreve um plano de recuperação de desastres para o Fabric projetado para ajudar sua organização a manter seus dados seguros e acessíveis quando ocorre um desastre regional não planejado. O plano abrange os seguintes tópicos:
Replicação entre regiões: a malha oferece replicação entre regiões para dados armazenados no OneLake. Pode optar por participar ou não desta funcionalidade com base nos seus requisitos.
Acesso a dados após desastre: em um cenário de desastre regional, o Fabric garante o acesso aos dados, com certas limitações. Embora a criação ou modificação de novos itens seja restrita após o failover, o foco principal continua sendo garantir que os dados existentes permaneçam acessíveis e intactos.
Orientação para recuperação: o Fabric fornece um conjunto estruturado de instruções para guiá-lo durante o processo de recuperação. A orientação estruturada facilita a transição de volta às operações regulares.
O Power BI, agora parte da malha, tem um sistema sólido de recuperação de desastres e oferece os seguintes recursos:
BCDR como padrão: o Power BI inclui automaticamente recursos de recuperação de desastres em sua oferta padrão. Não é necessário ativar ou ativar este recurso separadamente.
Replicação entre regiões: o Power BI usa a replicação com redundância geográfica do armazenamento do Azure e a replicação com redundância geográfica do SQL do Azure para garantir que as instâncias de backup existam em outras regiões e possam ser usadas. Isso significa que os dados são duplicados em diferentes regiões, aumentando sua disponibilidade e reduzindo os riscos associados a interrupções regionais.
Serviços contínuos e acesso após desastre: mesmo durante eventos de interrupção, os itens do Power BI permanecem acessíveis no modo somente leitura. Os itens incluem modelos semânticos, relatórios e painéis, garantindo que as empresas possam continuar seus processos de análise e tomada de decisão sem obstáculos significativos.
Para obter mais informações, consulte as Perguntas frequentes sobre alta disponibilidade, failover e recuperação de desastres do Power BI
Importante
Para clientes cujas regiões de origem não têm uma região de par do Azure e são afetadas por um desastre, a capacidade de utilizar as capacidades de malha pode ser comprometida, mesmo que os dados dentro dessas capacidades sejam replicados. Esta limitação está ligada à infraestrutura da região de origem, essencial para o funcionamento das capacidades.
Região de origem e funcionalidade de capacidade
Para um planejamento eficaz de recuperação de desastres, é fundamental que você entenda a relação entre sua região de origem e os locais de capacidade. Compreender a região de origem e os locais de capacidade ajuda a fazer seleções estratégicas de regiões de capacidade, bem como os processos de replicação e recuperação correspondentes.
A região inicial para o arrendamento e armazenamento de dados da sua organização está definida para a localização do endereço de faturação do primeiro utilizador que se inscrever. Para obter mais detalhes sobre a configuração do arrendamento, aceda a Planeamento da implementação do Power BI: Configuração do inquilino. Quando você cria novas capacidades, seu armazenamento de dados é definido para a região inicial por padrão. Se desejar alterar sua região de armazenamento de dados para outra região, será necessário habilitar o Multi-Geo, um recurso Fabric Premium.
Importante
Escolher uma região diferente para sua capacidade não realoca totalmente todos os seus dados para essa região. Alguns elementos de dados ainda permanecem armazenados na região de origem. Para ver quais dados permanecem na região inicial e quais dados são armazenados na região habilitada para Multi-Geo, consulte Configurar suporte a Multi-Geo para Fabric Premium.
No caso de uma região de origem que não tenha uma região emparelhada, as capacidades em qualquer região habilitada para Multi-Geo podem enfrentar problemas operacionais se a região de origem encontrar um desastre, já que a funcionalidade de serviço principal está ligada à região de origem.
Se você selecionar uma região habilitada para Multi-Geo dentro da UE, é garantido que seus dados sejam armazenados dentro do limite de dados da UE.
Para saber como identificar sua região de origem, consulte Localizar sua região de origem do Fabric.
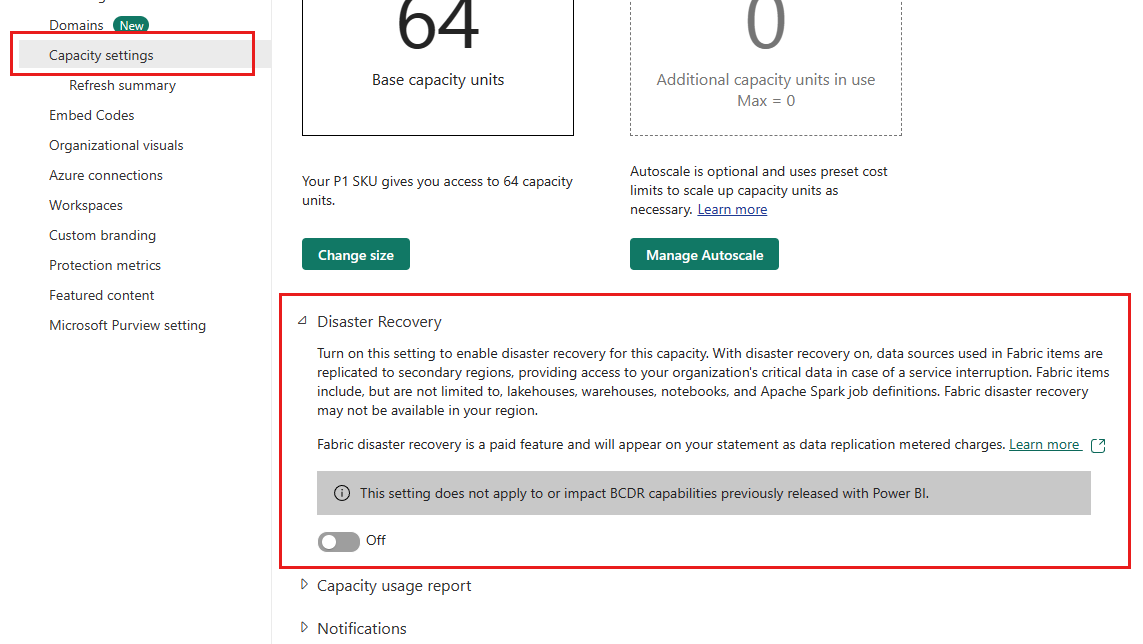
Configuração da capacidade de recuperação de desastres
O Fabric fornece uma opção de recuperação de desastres na página de configurações de capacidade. Está disponível onde os emparelhamentos regionais do Azure se alinham com a presença de serviço do Fabric. Aqui estão as especificidades desta opção:
Acesso à função: somente usuários com a função de administrador de capacidade ou superior podem usar essa opção.
Granularidade: A granularidade do switch é o nível de capacidade. Está disponível para capacidades Premium e Fabric.
Escopo de dados: a alternância de recuperação de desastres aborda especificamente os dados do OneLake, que incluem dados do Lakehouse e do Warehouse. O switch não influencia seus dados armazenados fora do OneLake.
Continuidade BCDR para Power BI: enquanto a recuperação de desastres para dados OneLake pode ser ativada e desativada, o BCDR para Power BI é sempre suportado, independentemente de o switch estar ligado ou desligado.
Frequência: Depois de alterar a configuração de capacidade de recuperação de desastres, você deve aguardar 30 dias antes de poder alterá-la novamente. O período de espera é estabelecido para manter a estabilidade e evitar alternâncias constantes,
Nota
Depois de ativar a configuração de capacidade de recuperação de desastres, pode levar até uma semana para que os dados comecem a ser replicados.
Replicação de dados
Quando você ativa a configuração de capacidade de recuperação de desastres, a replicação entre regiões é habilitada como um recurso de recuperação de desastres para dados do OneLake. A plataforma Fabric se alinha às regiões do Azure para provisionar os pares de redundância geográfica. No entanto, algumas regiões não têm uma região de par do Azure ou a região de par não suporta Malha. Para essas regiões, a replicação de dados não está disponível. Para obter mais informações, consulte Regiões com zonas de disponibilidade e sem par de regiões e Disponibilidade da região de malha.
Nota
Embora o Fabric ofereça uma solução de replicação de dados no OneLake para oferecer suporte à recuperação de desastres, há limitações notáveis. Por exemplo, os dados de bancos de dados KQL e conjuntos de consultas são armazenados externamente no OneLake, o que significa que uma abordagem de recuperação de desastres separada é necessária. Consulte o restante deste documento para obter detalhes sobre a abordagem de recuperação de desastres para cada item de malha.
Faturação
O recurso de recuperação de desastres no Fabric permite a replicação geográfica de seus dados para maior segurança e confiabilidade. Esse recurso consome mais armazenamento e transações, que são cobradas como Armazenamento BCDR e Operações BCDR, respectivamente. Você pode monitorar e gerenciar esses custos no aplicativo Microsoft Fabric Capacity Metrics, onde eles aparecem como itens de linha separados.
Para obter um detalhamento exaustivo de todos os custos de recuperação de desastres associados para ajudá-lo a planejar e orçar de acordo, consulte Consumo de computação e armazenamento do OneLake.
Configurar a recuperação após desastre
Embora o Fabric forneça recursos de recuperação de desastres para oferecer suporte à resiliência de dados, você deve seguir determinadas etapas manuais para restaurar o serviço durante interrupções. Esta seção detalha as ações que você deve tomar para se preparar para possíveis interrupções.
Fase 1: Preparação
Ativar as configurações de capacidade de recuperação de desastres: revise e defina regularmente as configurações de capacidade de recuperação de desastres para garantir que elas atendam às suas necessidades de proteção e desempenho.
Crie backups de dados: copie dados críticos armazenados fora do OneLake para outra região de forma alinhada ao seu plano de recuperação de desastres.
Fase 2: Failover de desastre
Quando um desastre grave torna a região principal irrecuperável, o Microsoft Fabric inicia um failover regional. O acesso ao portal do Fabric não estará disponível até que o failover seja concluído e uma notificação seja publicada na página de suporte do Microsoft Fabric.
O tempo necessário para a conclusão do failover pode variar, embora normalmente leve menos de uma hora. Quando o failover estiver concluído, aqui está o que você pode esperar:
Portal de malha: você pode acessar o portal e ler operações, como navegar em espaços de trabalho e itens existentes, continuar a funcionar. Todas as operações de gravação, como criar ou modificar um espaço de trabalho, são pausadas.
Power BI: Você pode executar operações de leitura, como exibir painéis e relatórios. Não há suporte para atualizações, operações de publicação de relatórios, modificações de painel e relatório e outras operações que exijam alterações nos metadados.
Lakehouse/Warehouse: Você não pode abrir esses itens, mas os arquivos podem ser acessados por meio de APIs ou ferramentas do OneLake.
Definição de trabalho do Spark: não é possível abrir definições de trabalho do Spark, mas os arquivos de código podem ser acessados por meio de APIs ou ferramentas do OneLake. Todos os metadados ou configurações serão salvos após o failover.
Bloco de notas: não é possível abrir blocos de notas e o conteúdo do código não será guardado após o desastre.
Modelo/Experimento de ML: Não é possível abrir modelos ou experimentos de ML. O conteúdo do código e os metadados, como métricas e configurações de execução, não serão salvos após o desastre.
Dataflow Gen2/Pipeline/Eventstream: Não é possível abrir esses itens, mas é possível usar destinos de recuperação de desastres suportados (lakehouses ou armazéns) para proteger os dados.
KQL Database/Queryset: Você não poderá acessar bancos de dados KQL e conjuntos de consultas após o failover. Mais etapas de pré-requisito são necessárias para proteger os dados em bancos de dados KQL e conjuntos de consultas.
Em um cenário de desastre, o portal de malha e o Power BI estão no modo somente leitura e outros itens de malha não estão disponíveis, você pode acessar seus dados armazenados no OneLake usando APIs ou ferramentas de terceiros. Tanto o portal quanto o Power BI mantêm a capacidade de executar operações de leitura e gravação nesses dados. Essa capacidade garante que os dados críticos permaneçam acessíveis e modificáveis e atenua possíveis interrupções de suas operações de negócios.
Os dados do OneLake permanecem acessíveis através de vários canais:
API do OneLake ADLS Gen2: Consulte Conectando-se ao Microsoft OneLake
Exemplos de ferramentas que podem se conectar aos dados do OneLake:
Azure Storage Explorer: Consulte Integrar o OneLake com o Azure Storage Explorer
Explorador de arquivos do OneLake: consulte Usar o explorador de arquivos do OneLake para acessar dados do Fabric
Fase 3: Plano de recuperação
Embora o Fabric garanta que os dados permaneçam acessíveis após um desastre, você também pode agir para restaurar totalmente seus serviços para o estado anterior ao incidente. Esta seção fornece um guia passo a passo para ajudá-lo durante o processo de recuperação.
Etapas de recuperação
Crie uma nova capacidade de malha em qualquer região após um desastre. Dada a alta demanda durante esses eventos, recomendamos selecionar uma região fora do seu geo principal para aumentar a probabilidade de disponibilidade do serviço de computação. Para obter informações sobre como criar uma capacidade, consulte Comprar uma assinatura do Microsoft Fabric.
Crie espaços de trabalho na capacidade recém-criada. Se necessário, use os mesmos nomes dos espaços de trabalho antigos.
Crie itens com os mesmos nomes daqueles que você deseja recuperar. Esta etapa é importante se você usar o script personalizado para recuperar casas de lago e armazéns.
Restaure os itens. Para cada item, siga a seção relevante nas Diretrizes de recuperação de desastres específicas da experiência para restaurar o item.