Solucionar problemas e identificar consultas de execução lenta no Banco de Dados do Azure para PostgreSQL - Servidor Flexível
APLICA-SE A:  Banco de Dados do Azure para PostgreSQL - Servidor Flexível
Banco de Dados do Azure para PostgreSQL - Servidor Flexível
Este artigo descreve como identificar e diagnosticar a causa raiz de consultas de execução lenta.
Neste artigo, você pode aprender:
- Como identificar consultas de execução lenta.
- Como identificar um procedimento lento junto com ele. Identifique uma consulta lenta entre uma lista de consultas que pertencem ao mesmo procedimento armazenado de execução lenta.
Pré-requisitos
Habilite os guias de solução de problemas seguindo as etapas descritas em Usar guias de solução de problemas.
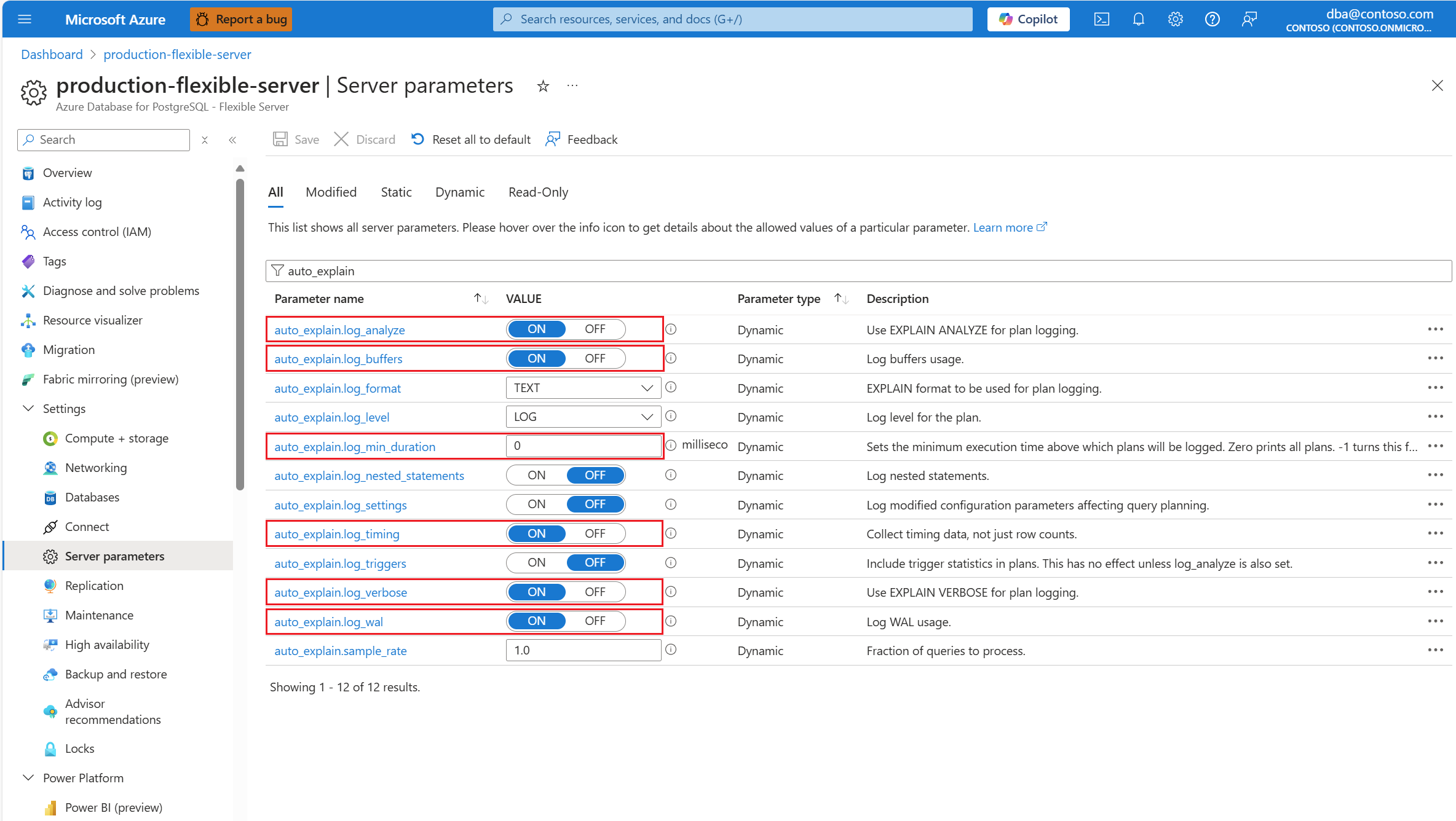
Configure a
auto_explainextensão permitindo listagem e carregando a extensão.Depois que a
auto_explainextensão for configurada, altere os seguintes parâmetros do servidor, que controlam o comportamento da extensão:auto_explain.log_analyzeparaON.auto_explain.log_buffersparaON.auto_explain.log_min_durationde acordo com o que é razoável no seu cenário.auto_explain.log_timingparaON.auto_explain.log_verboseparaON.

Nota
Se você definir auto_explain.log_min_duration como 0, a extensão começará a registrar todas as consultas que estão sendo executadas no servidor. Isso pode afetar o desempenho do banco de dados. A devida diligência deve ser feita para chegar a um valor que é considerado lento no servidor. Por exemplo, se todas as consultas forem concluídas em menos de 30 segundos e isso for aceitável para seu aplicativo, é aconselhável atualizar o parâmetro para 30000 milissegundos. Isso registraria qualquer consulta que levasse mais de 30 segundos para ser concluída.
Identificar consulta lenta
Com guias de solução de problemas e auto_explain extensão em vigor, descrevemos o cenário com a ajuda de um exemplo.
Temos um cenário em que a utilização da CPU aumenta para 90% e queremos determinar a causa do pico. Para depurar o cenário, siga estas etapas:
Assim que você for alertado por um cenário de CPU, no menu de recursos da instância afetada do Banco de Dados do Azure para Servidor Flexível PostgreSQL, na seção Monitoramento , selecione Guias de solução de problemas.
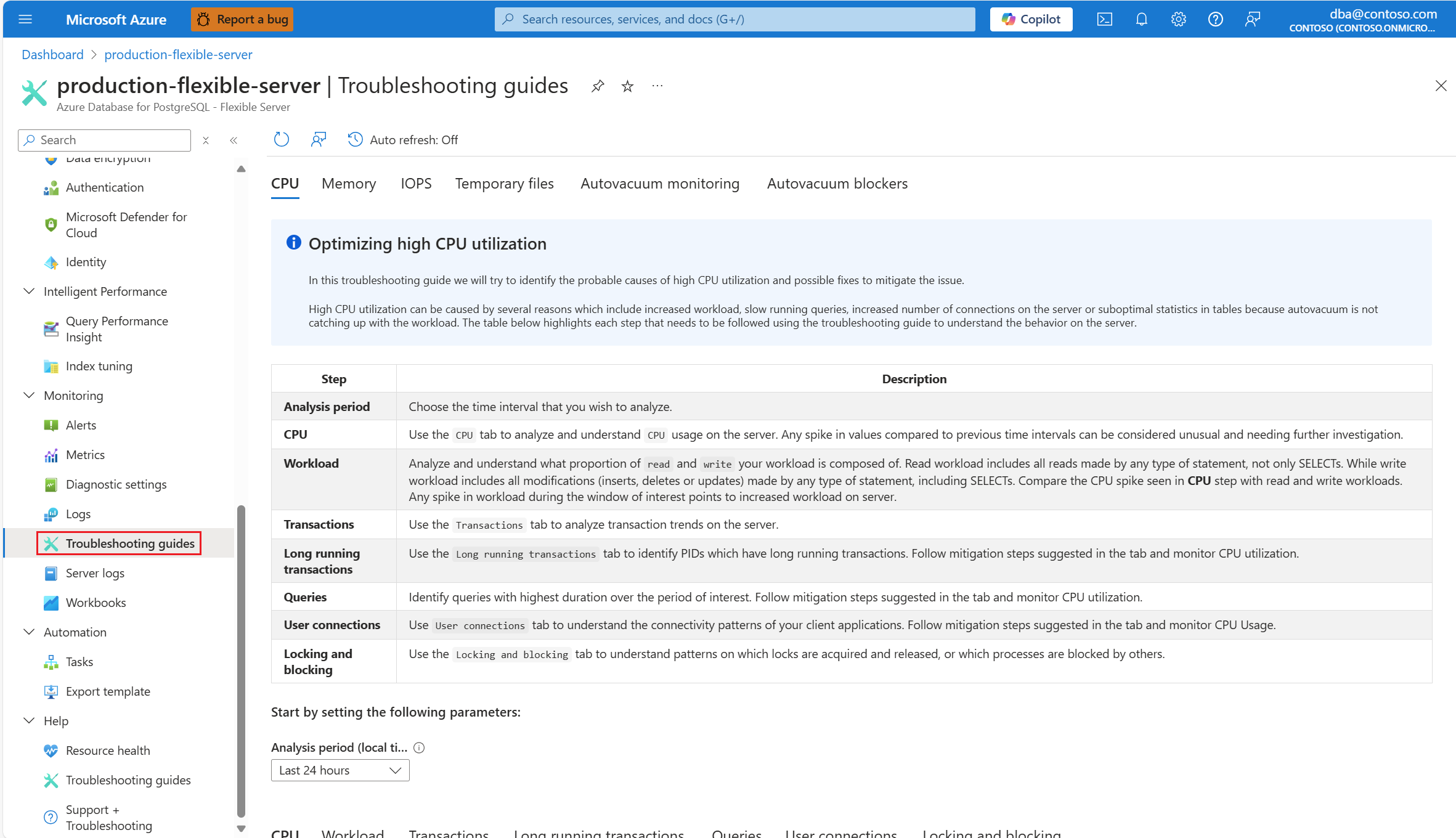
Selecione a guia CPU . O guia de solução de problemas Otimizando alta utilização da CPU é aberto.
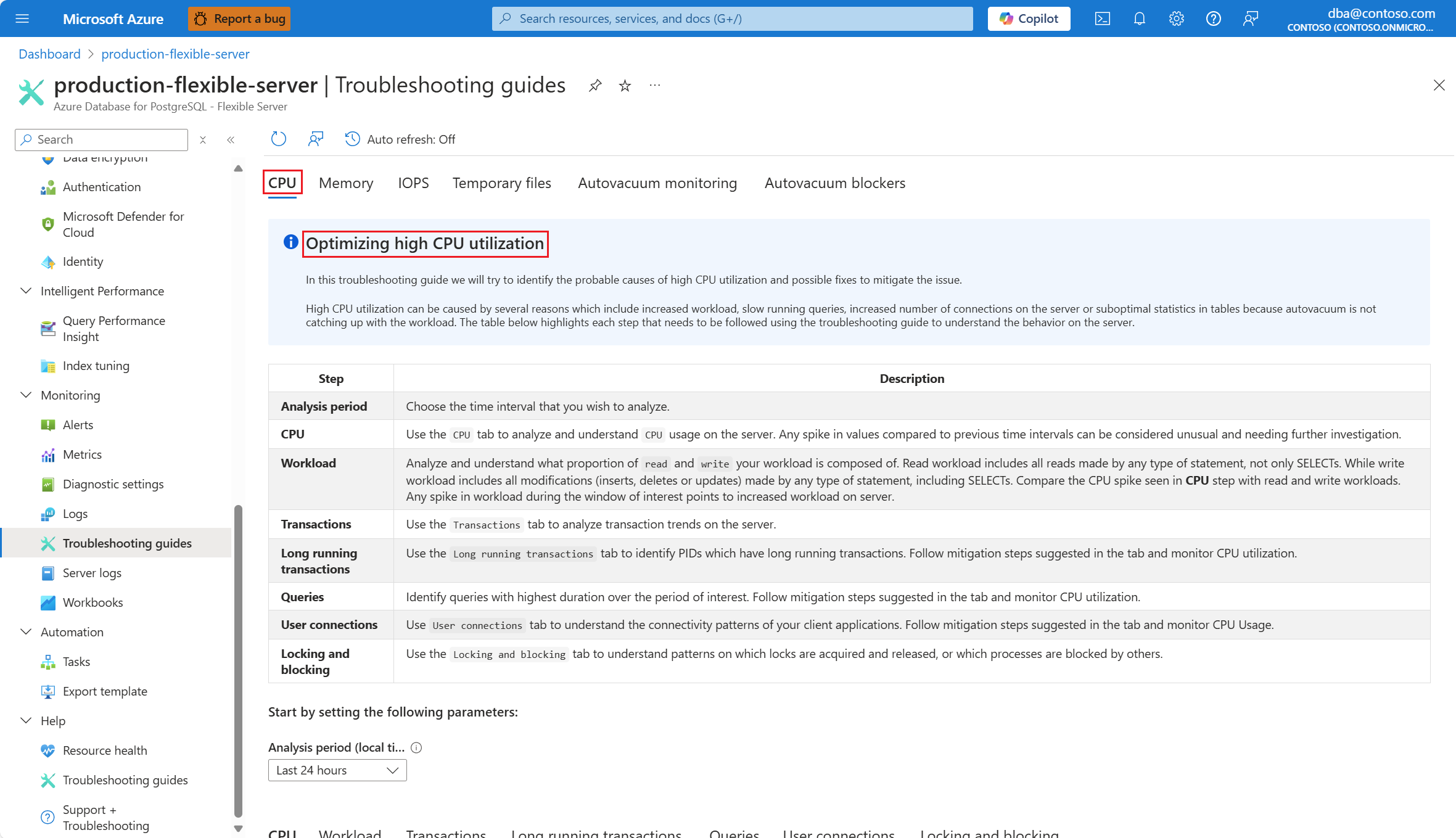
Na lista suspensa Período de análise (hora local), selecione o intervalo de tempo no qual deseja concentrar a análise.
Selecione a guia Consultas . Ele mostra detalhes de todas as consultas executadas no intervalo em que 90% de utilização da CPU foi vista. A partir do instantâneo, parece que a consulta com o tempo médio de execução mais lento durante o intervalo de tempo foi de ~2,6 minutos, e a consulta foi executada 22 vezes durante o intervalo. Essa consulta é provavelmente a causa dos picos de CPU.
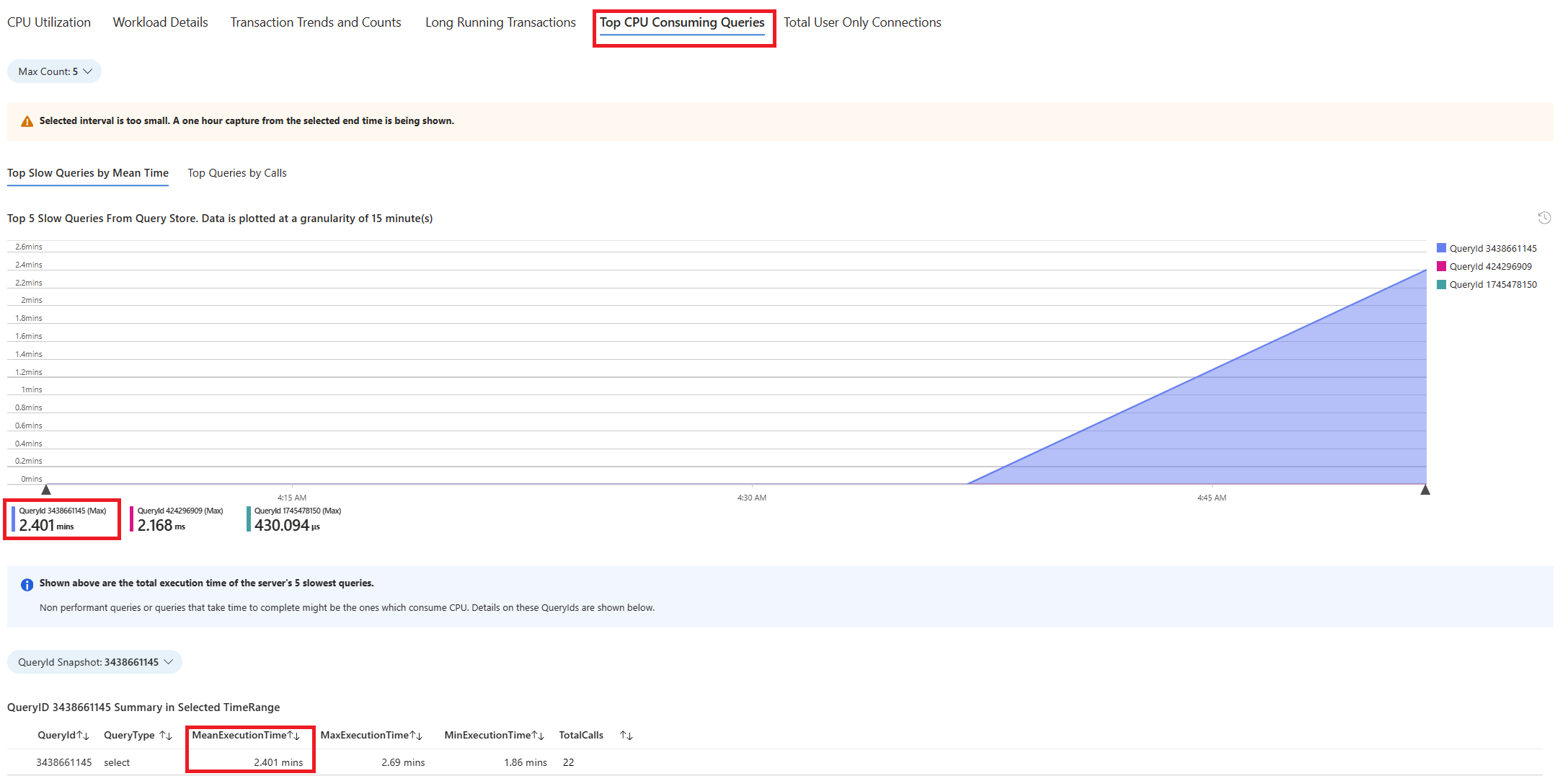
Para recuperar o texto da consulta real, conecte-se ao
azure_sysbanco de dados e execute a consulta a seguir.




psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- No exemplo considerado, a consulta que foi considerada lenta foi:
SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id, c_id
ORDER BY c_w_id;
Para entender qual plano explicativo exato foi gerado, use o Banco de Dados do Azure para logs do Servidor Flexível PostgreSQL. Toda vez que a consulta concluir a execução durante essa janela de tempo, a
auto_explainextensão deve gravar uma entrada nos logs. No menu de recursos, na seção Monitoramento , selecione Logs.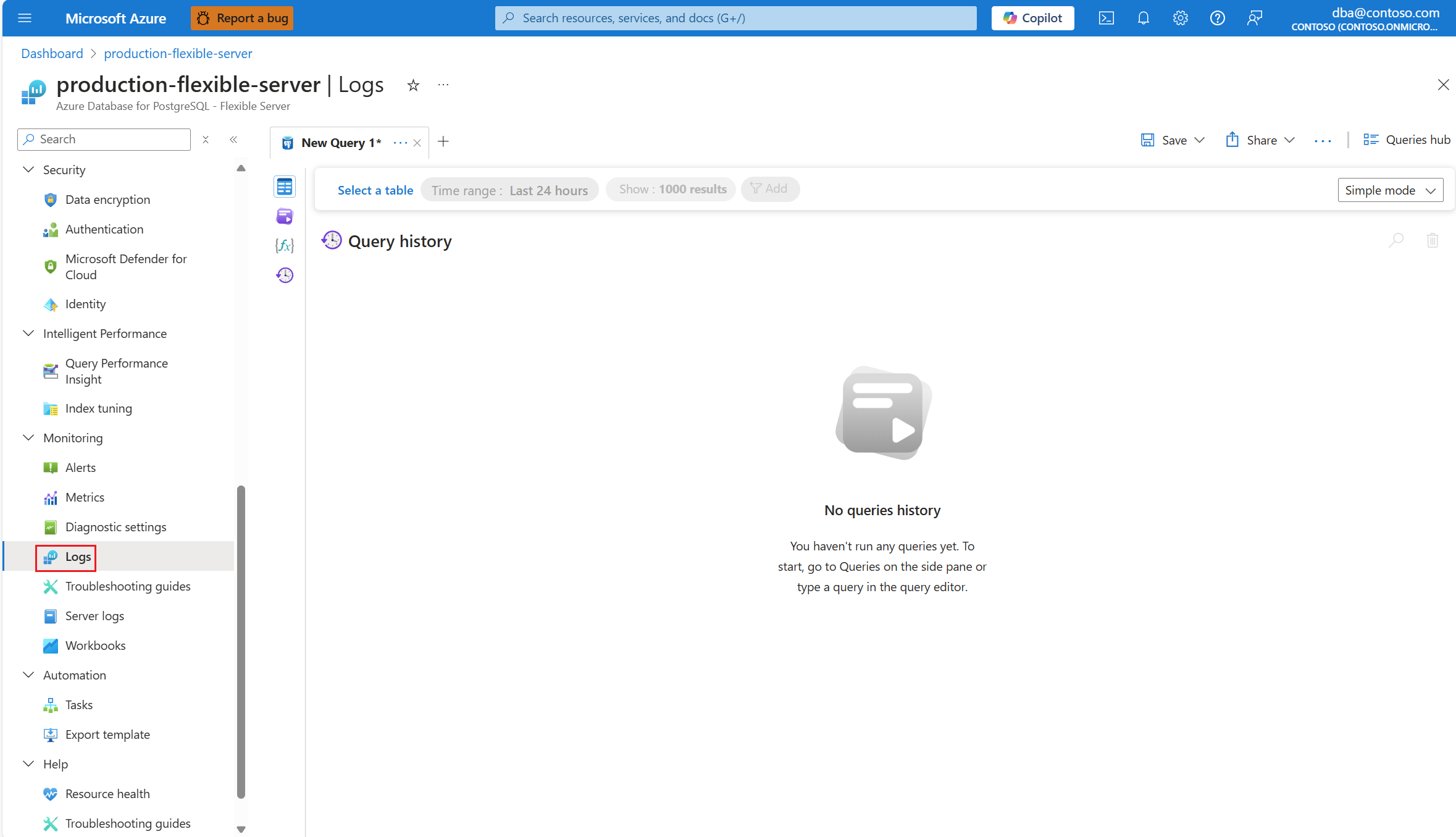
Selecione o intervalo de tempo em que 90% de utilização da CPU foi encontrada.
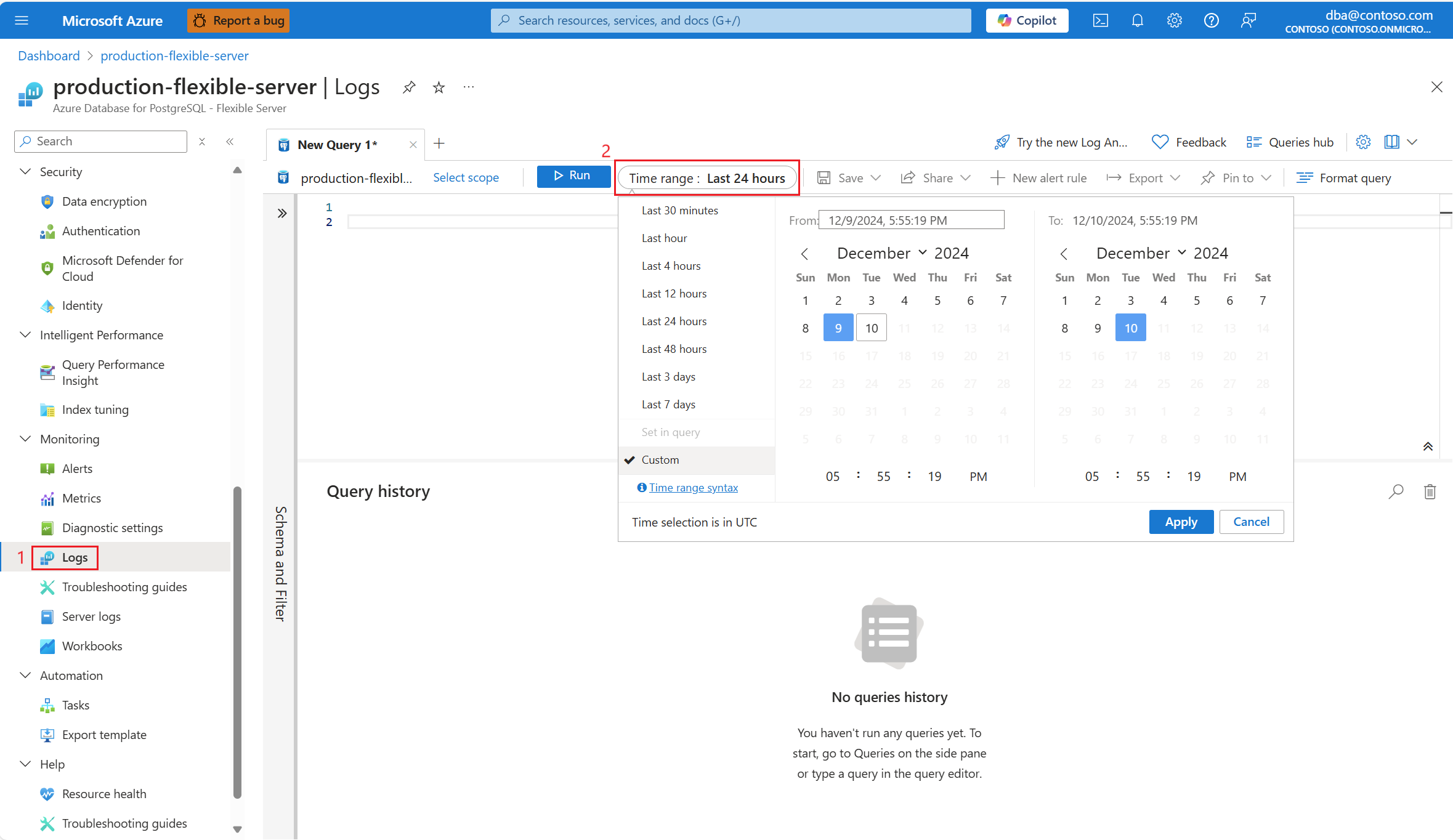
Execute a seguinte consulta para recuperar a saída de EXPLAIN ANALYZE para a consulta identificada.

AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
A coluna de mensagem armazena o plano de execução conforme mostrado nesta saída:
2024-11-10 19:56:46 UTC-6525a8e7.2e3d-LOG: duration: 150692.864 ms plan:
Query Text: SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id,c_id
order by c_w_id;
GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=70930.833..129231.950 rows=10000000 loops=1)
Output: c_id, sum(c_balance), c_w_id
Group Key: customer.c_w_id, customer.c_id
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=70930.821..81898.430 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Sort Key: customer.c_w_id, customer.c_id
Sort Method: external merge Disk: 225104kB
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.021..22997.697 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
A consulta foi executada por ~2,5 minutos, conforme mostrado no guia de solução de problemas. O duration valor de 150692,864 ms da saída do plano de execução obtida confirma-o. Use a saída de EXPLAIN ANALYZE para solucionar problemas adicionais e ajustar a consulta.
Nota
Observador de que a consulta foi executada 22 vezes durante o intervalo e os logs mostrados contêm uma dessas entradas capturadas durante o intervalo.
Identificar consulta de execução lenta em um procedimento armazenado
Com guias de solução de problemas e extensão de auto_explain em vigor, explicamos o cenário com a ajuda de um exemplo.
Temos um cenário em que a utilização da CPU aumenta para 90% e queremos determinar a causa do pico. Para depurar o cenário, siga estas etapas:
Assim que você for alertado por um cenário de CPU, no menu de recursos da instância afetada do Banco de Dados do Azure para Servidor Flexível PostgreSQL, na seção Monitoramento , selecione Guias de solução de problemas.
Selecione a guia CPU . O guia de solução de problemas Otimizando alta utilização da CPU é aberto.
Na lista suspensa Período de análise (hora local), selecione o intervalo de tempo no qual deseja concentrar a análise.
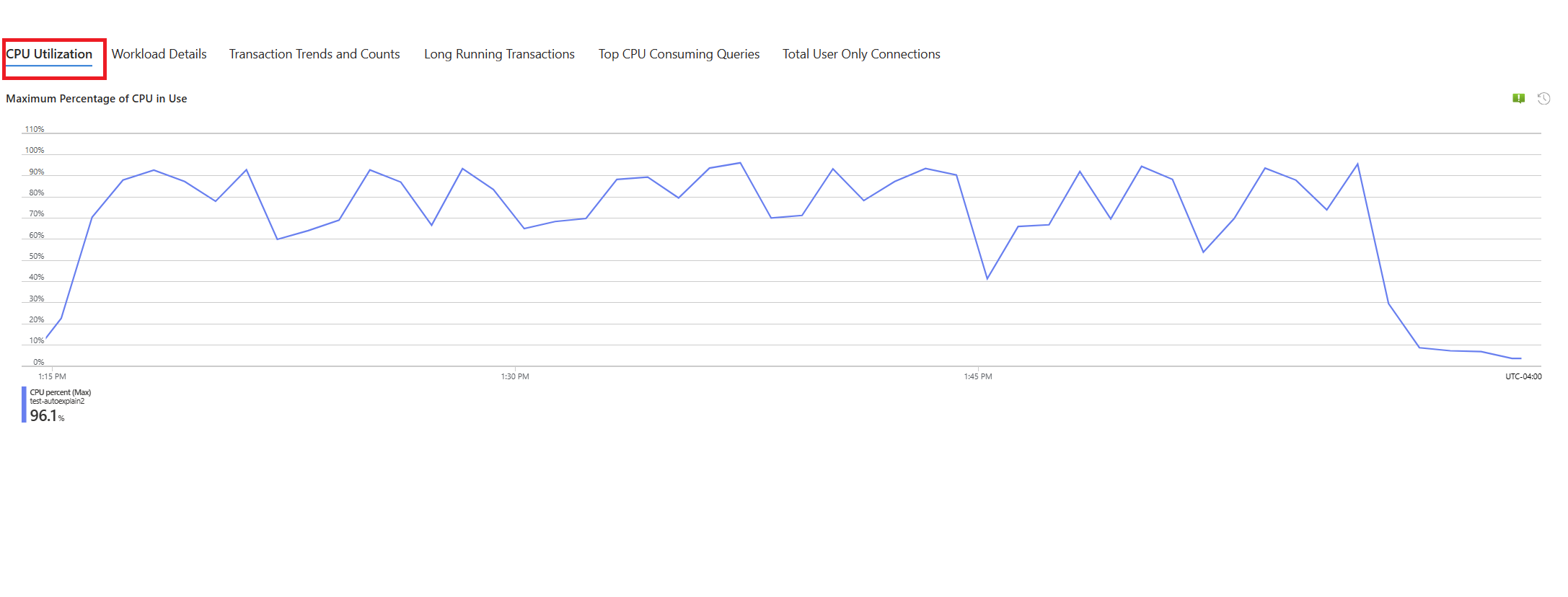
Selecione a guia Consultas . Ele mostra detalhes de todas as consultas executadas no intervalo em que 90% de utilização da CPU foi vista. A partir do instantâneo, parece que a consulta com o tempo médio de execução mais lento durante o intervalo de tempo foi de ~2,6 minutos, e a consulta foi executada 22 vezes durante o intervalo. Essa consulta é provavelmente a causa dos picos de CPU.
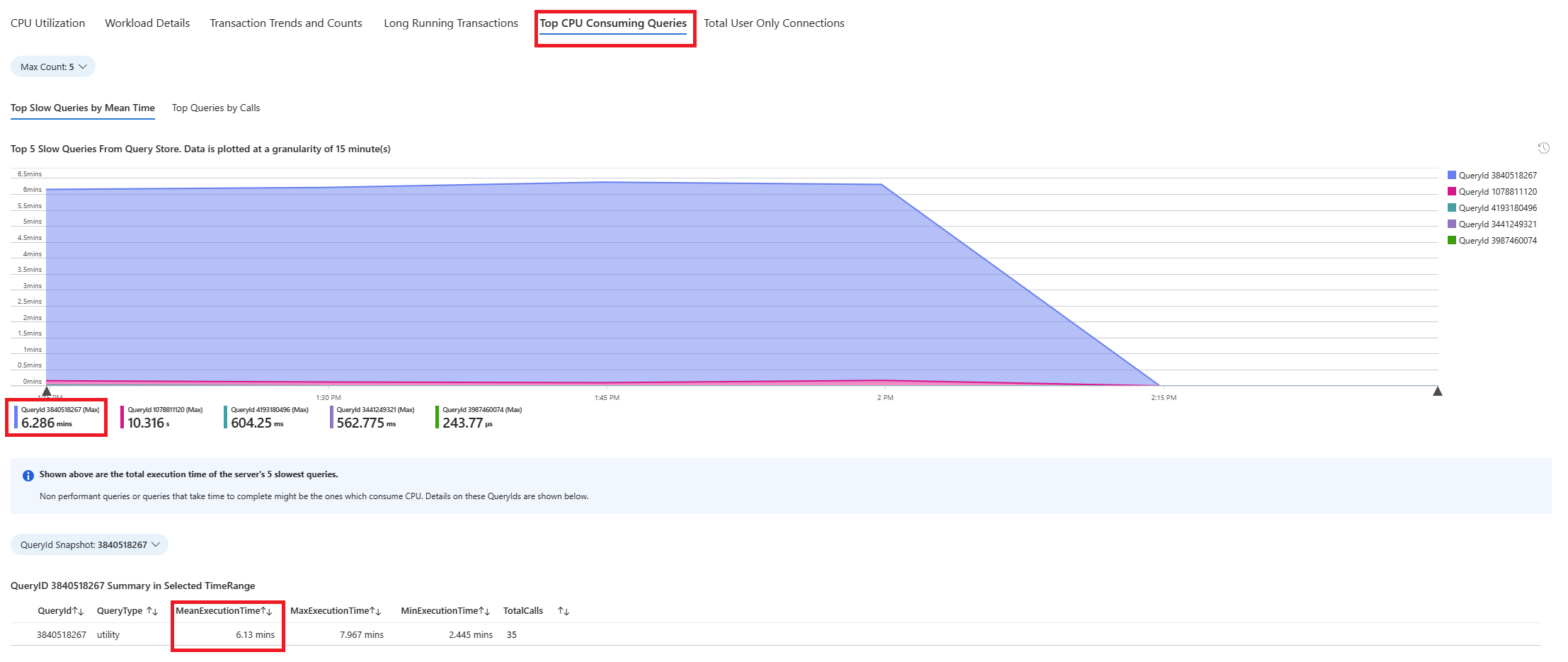
Conecte-se a azure_sys banco de dados e execute a consulta para recuperar o texto real da consulta usando o script abaixo.


psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- No exemplo considerado, a consulta que foi considerada lenta foi um procedimento armazenado:
call autoexplain_test ();
- Para entender qual plano explicativo exato foi gerado, use o Banco de Dados do Azure para logs do Servidor Flexível PostgreSQL. Toda vez que a consulta concluir a execução durante essa janela de tempo, a
auto_explainextensão deve gravar uma entrada nos logs. No menu de recursos, na seção Monitoramento , selecione Logs. Em seguida, em Intervalo de tempo:, selecione a janela de tempo onde deseja focar a análise.

- Execute a seguinte consulta para recuperar a saída de análise explicativa da consulta identificada.
AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
O procedimento tem várias consultas, que são destacadas abaixo. A saída de análise explicativa de cada consulta usada no procedimento armazenado é registrada para analisar mais e solucionar problemas. O tempo de execução das consultas registradas pode ser usado para identificar as consultas mais lentas que fazem parte do procedimento armazenado.
2024-11-10 17:52:45 UTC-6526d7f0.7f67-LOG: duration: 38459.176 ms plan:
Query Text: insert into customer_balance SELECT c_id, SUM(c_balance) AS total_balance FROM customer GROUP BY c_w_id,c_id order by c_w_id
Insert on public.customer_balance (cost=1906820.83..2231820.83 rows=0 width=0) (actual time=38459.173..38459.174 rows=0 loops=1)Buffers: shared hit=10108203 read=454055 dirtied=54058, temp read=77521 written=77701 WAL: records=10000000 fpi=1 bytes=640002197
-> Subquery Scan on "*SELECT*" (cost=1906820.83..2231820.83 rows=10000000 width=36) (actual time=20415.738..29514.742 rows=10000000 loops=1)
Output: "*SELECT*".c_id, "*SELECT*".total_balance Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=20415.737..28574.266 rows=10000000 loops=1)
Output: customer.c_id, sum(customer.c_balance), customer.c_w_id Group Key: customer.c_w_id, customer.c_id Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=20415.723..22023.515 rows=10000000 loops=1)
Output: customer.c_id, customer.c_w_id, customer.c_balance Sort Key: customer.c_w_id, customer.c_id Sort Method: external merge Disk: 225104kB Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.310..15061.471 rows=10000000 loops=1) Output: customer.c_id, customer.c_w_id, customer.c_balance Buffers: shared hit=1 read=400000
2024-11-10 17:52:07 UTC-6526d7f0.7f67-LOG: duration: 61939.529 ms plan:
Query Text: delete from customer_balance
Delete on public.customer_balance (cost=0.00..799173.51 rows=0 width=0) (actual time=61939.525..61939.526 rows=0 loops=1) Buffers: shared hit=50027707 read=620942 dirtied=295462 written=71785 WAL: records=50026565 fpi=34 bytes=2711252160
-> Seq Scan on public.customer_balance (cost=0.00..799173.51 rows=15052451 width=6) (actual time=3185.519..35234.061 rows=50000000 loops=1)
Output: ctid Buffers: shared hit=27707 read=620942 dirtied=26565 written=71785 WAL: records=26565 fpi=34 bytes=11252160
2024-11-10 17:51:05 UTC-6526d7f0.7f67-LOG: duration: 10387.322 ms plan:
Query Text: select max(c_id) from customer
Finalize Aggregate (cost=180185.84..180185.85 rows=1 width=4) (actual time=10387.220..10387.319 rows=1 loops=1) Output: max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Gather (cost=180185.63..180185.84 rows=2 width=4) (actual time=10387.214..10387.314 rows=1 loops=1)
Output: (PARTIAL max(c_id)) Workers Planned: 2 Workers Launched: 0 Buffers: shared hit=37148 read=1204 written=69
-> Partial Aggregate (cost=179185.63..179185.64 rows=1 width=4) (actual time=10387.012..10387.013 rows=1 loops=1) Output: PARTIAL max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Parallel Index Only Scan using customer_i1 on public.customer (cost=0.43..168768.96 rows=4166667 width=4) (actual time=0.446..7676.356 rows=10000000 loops=1)
Output: c_w_id, c_d_id, c_id Heap Fetches: 24 Buffers: shared hit=37148 read=1204 written=69
Nota
Para fins de demonstração, a saída EXPLAIN ANALYZE de apenas algumas consultas usadas no procedimento é mostrada. A ideia é que se possa reunir a saída EXPLICAR ANALISAR de todas as consultas dos logs, e identificar a mais lenta delas e tentar ajustá-las.
Conteúdos relacionados
- Resolver problemas de utilização elevada da CPU na Base de Dados do Azure para PostgreSQL – Servidor Flexível.
- Solucione problemas de alta utilização de IOPS no Banco de Dados do Azure para PostgreSQL - Servidor Flexível.
- Solucione problemas de alta utilização de memória no Banco de Dados do Azure para PostgreSQL - Servidor Flexível.
- Parâmetros de servidor no Banco de Dados do Azure para PostgreSQL - Servidor flexível.
- Ajuste de vácuo automático no Banco de Dados do Azure para PostgreSQL - Servidor Flexível.