Ajustar prompts usando variantes
Elaborar um bom prompt é uma tarefa desafiadora que requer muita criatividade, clareza e relevância. Um bom prompt pode obter a saída desejada de um modelo de linguagem pré-treinado, enquanto um prompt ruim pode levar a saídas imprecisas, irrelevantes ou sem sentido. Portanto, é necessário ajustar prompts para otimizar seu desempenho e robustez para diferentes tarefas e domínios.
Assim, introduzimos o conceito de variantes que podem ajudá-lo a testar o comportamento do modelo sob diferentes condições, como diferentes palavras, formatação, contexto, temperatura ou top-k, comparar e encontrar o melhor prompt e configuração que maximiza a precisão, diversidade ou coerência do modelo.
Neste artigo, mostraremos como usar variantes para ajustar prompts e avaliar o desempenho de diferentes variantes.
Pré-requisitos
Antes de ler este artigo, é melhor passar:
Como ajustar prompts usando variantes?
Neste artigo, usaremos o fluxo de exemplo de Classificação da Web como exemplo.
Abra o fluxo de amostra e remova o nó prepare_examples como um início.
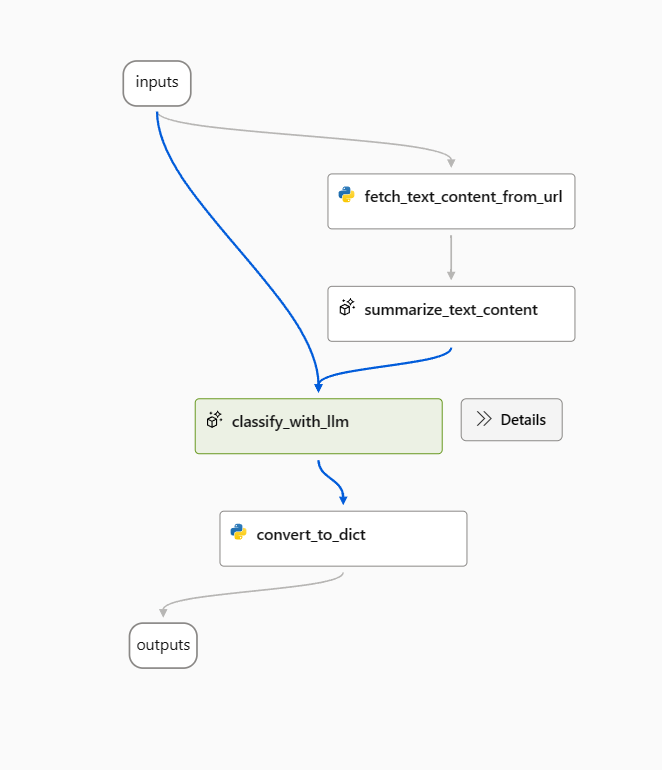
Use o seguinte prompt como um prompt de linha de base no nó classify_with_llm .

Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
The output shoule be in this format: {"category": "App", "evidence": "Both"}
OUTPUT:
Para otimizar esse fluxo, pode haver várias maneiras, e a seguir estão duas direções:
Para classify_with_llm nó: aprendi com a comunidade e os papéis que uma temperatura mais baixa dá maior precisão, mas menos criatividade e surpresa, então uma temperatura mais baixa é adequada para tarefas de classificação e também poucos prompts podem aumentar o desempenho do LLM. Então, eu gostaria de testar como meu fluxo se comporta quando a temperatura é alterada de 1 para 0, e quando o prompt é com poucos exemplos de tiro.
Para summarize_text_content nó: também quero testar o comportamento do meu fluxo quando altero o resumo de 100 palavras para 300, para ver se mais conteúdo de texto pode ajudar a melhorar o desempenho.
Criar variantes
- Selecione o botão Mostrar variantes no canto superior direito do nó LLM. O nó LLM existente é variant_0 e é a variante padrão.
- Selecione o botão Clonar no variant_0 para gerar variant_1 e, em seguida, você pode configurar parâmetros para valores diferentes ou atualizar o prompt em variant_1.
- Repita a etapa para criar mais variantes.
- Selecione Ocultar variantes para parar de adicionar mais variantes. Todas as variantes são dobradas. A variante padrão é mostrada para o nó.
Para classify_with_llm nó, com base em variant_0:
- Crie variant_1 onde a temperatura é alterada de 1 para 0.
- Crie variant_2 onde a temperatura é 0 e você pode usar o seguinte prompt, incluindo exemplos de algumas fotos.
Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
Here are a few examples:
URL: https://play.google.com/store/apps/details?id=com.spotify.music
Text content: Spotify is a free music and podcast streaming app with millions of songs, albums, and original podcasts. It also offers audiobooks, so users can enjoy thousands of stories. It has a variety of features such as creating and sharing music playlists, discovering new music, and listening to popular and exclusive podcasts. It also has a Premium subscription option which allows users to download and listen offline, and access ad-free music. It is available on all devices and has a variety of genres and artists to choose from.
OUTPUT: {"category": "App", "evidence": "Both"}
URL: https://www.youtube.com/channel/UC_x5XG1OV2P6uZZ5FSM9Ttw
Text content: NFL Sunday Ticket is a service offered by Google LLC that allows users to watch NFL games on YouTube. It is available in 2023 and is subject to the terms and privacy policy of Google LLC. It is also subject to YouTube's terms of use and any applicable laws.
OUTPUT: {"category": "Channel", "evidence": "URL"}
URL: https://arxiv.org/abs/2303.04671
Text content: Visual ChatGPT is a system that enables users to interact with ChatGPT by sending and receiving not only languages but also images, providing complex visual questions or visual editing instructions, and providing feedback and asking for corrected results. It incorporates different Visual Foundation Models and is publicly available. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models.
OUTPUT: {"category": "Academic", "evidence": "Text content"}
URL: https://ab.politiaromana.ro/
Text content: There is no content available for this text.
OUTPUT: {"category": "None", "evidence": "None"}
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
OUTPUT:
Para summarize_text_content nó, com base em variant_0, você pode criar variant_1 onde 100 words é alterado para 300 palavras no prompt.
Agora, o fluxo tem a seguinte aparência, 2 variantes para summarize_text_content nó e 3 para classify_with_llm nó.

Execute todas as variantes com uma única linha de dados e verifique as saídas
Para garantir que todas as variantes possam ser executadas com êxito e funcionar conforme o esperado, você pode executar o fluxo com uma única linha de dados para testar.
Nota
Cada vez que você só pode selecionar um nó LLM com variantes para executar, enquanto outros nós LLM usarão a variante padrão.
Neste exemplo, configuramos variantes para summarize_text_content nó e classify_with_llm nó, portanto, você precisa executar duas vezes para testar todas as variantes.
- Selecione o botão Executar no canto superior direito.
- Selecione um nó LLM com variantes. Os outros nós LLM usarão a variante padrão.
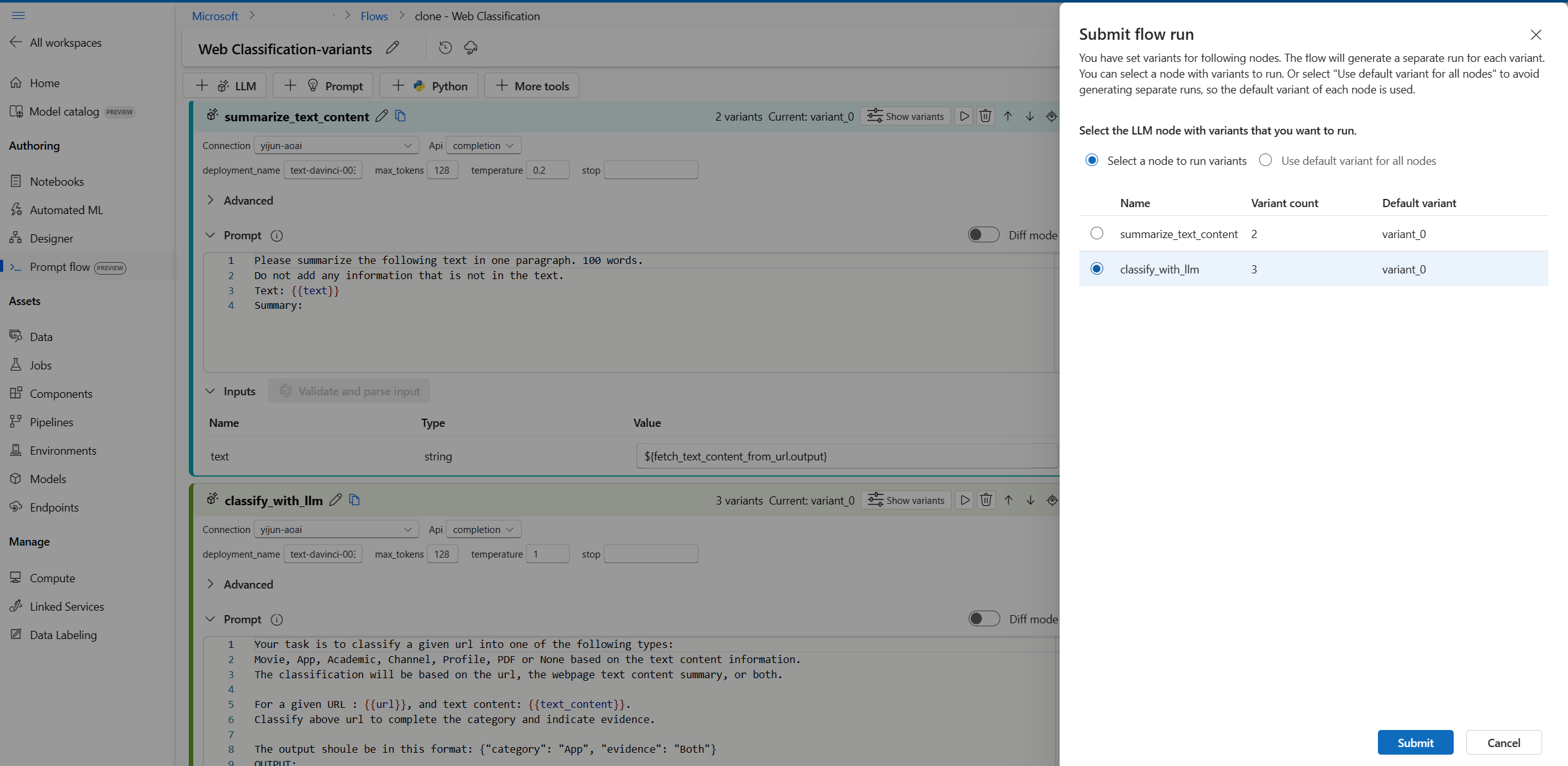
- Envie a execução do fluxo.
- Depois que a execução do fluxo for concluída, você poderá verificar o resultado correspondente para cada variante.
- Envie outra execução de fluxo com o outro nó LLM com variantes e verifique as saídas.
- Você pode alterar outros dados de entrada (por exemplo, usar um URL de página da Wikipédia) e repetir as etapas acima para testar variantes para dados diferentes.

Avaliar variantes
Quando você executa as variantes com alguns dados e verifica os resultados a olho nu, isso não pode refletir a complexidade e a diversidade dos dados do mundo real, enquanto isso, a saída não é mensurável, então é difícil comparar a eficácia de diferentes variantes e, em seguida, escolher a melhor.
Você pode enviar uma execução em lote, que permite testar as variantes com uma grande quantidade de dados e avaliá-las com métricas, para ajudá-lo a encontrar o melhor ajuste.
Primeiro, você precisa preparar um conjunto de dados, que seja representativo o suficiente do problema do mundo real que você deseja resolver com fluxo imediato. Neste exemplo, é uma lista de URLs e sua verdade de base de classificação. Usaremos precisão para avaliar o desempenho das variantes.
Selecione Avaliar no canto superior direito da página.
Ocorre um assistente para Batch run & Evaluation . O primeiro passo é selecionar um nó para executar todas as suas variantes.
Para testar o funcionamento de diferentes variantes para cada nó em um fluxo, você precisa executar uma execução em lote para cada nó com variantes uma a uma. Isso ajuda a evitar a influência das variantes de outros nós e a se concentrar nos resultados das variantes desse nó. Isso segue a regra do experimento controlado, o que significa que você só muda uma coisa de cada vez e mantém tudo o resto igual.
Por exemplo, você pode selecionar classify_with_llm nó para executar todas as variantes, o nó summarize_text_content usará a variante padrão para esta execução em lote.
Em seguida, em Configurações de execução em lote, você pode definir o nome da execução em lote, escolher um tempo de execução, carregar os dados preparados.
Em seguida, em Configurações de avaliação, selecione um método de avaliação.
Como esse fluxo é para classificação, você pode selecionar o método Avaliação de Precisão de Classificação para avaliar a precisão.
A precisão é calculada comparando os rótulos previstos atribuídos pelo fluxo (previsão) com os rótulos reais dos dados (verdade do solo) e contando quantos deles correspondem.
Na seção Mapeamento de entrada de avaliação, você precisa especificar que a verdade do terreno vem da coluna de categoria do conjunto de dados de entrada, e a previsão vem de uma das saídas de fluxo: categoria.
Depois de revisar todas as configurações, você pode enviar a execução em lote.
Depois que a execução for enviada, selecione o link, vá para a página de detalhes da execução.
Nota
A execução pode levar vários minutos para ser concluída.
Visualizar saídas
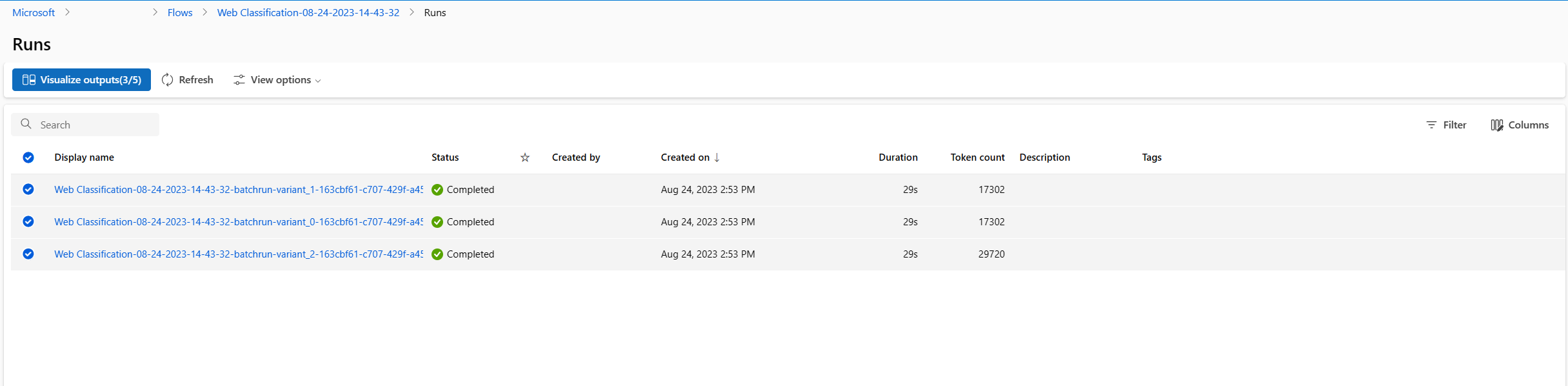
- Após a conclusão da execução em lote e da avaliação, na página de detalhes da execução, selecione várias vezes as execuções em lote para cada variante e, em seguida, selecione Visualizar saídas. Você verá as métricas de 3 variantes para o nó classify_with_llm e as saídas previstas LLM para cada registro de dados.
- Depois de identificar qual variante é a melhor, você pode voltar para a página de criação de fluxo e definir essa variante como variante padrão do nó
- Você também pode repetir as etapas acima para avaliar as variantes de summarize_text_content nó.
Agora, você concluiu o processo de ajuste de prompts usando variantes. Você pode aplicar essa técnica ao seu próprio fluxo de prompt para encontrar a melhor variante para o nó LLM.