Gerenciar sessão de computação de fluxo de prompt no estúdio de Aprendizado de Máquina do Azure
Uma sessão de computação de fluxo de prompt fornece recursos de computação necessários para a execução do aplicativo, incluindo uma imagem do Docker que contém todos os pacotes de dependência necessários. Esse ambiente confiável e escalável permite um fluxo rápido para executar eficientemente suas tarefas e funções para uma experiência de usuário perfeita.
Permissões e funções para gerenciamento de sessão de computação
Para atribuir funções, você precisa ter owner permissão ou Microsoft.Authorization/roleAssignments/write permissão no recurso.
Para usuários da sessão de computação, atribua a AzureML Data Scientist função no espaço de trabalho. Para saber mais, consulte Gerenciar o acesso a um espaço de trabalho do Azure Machine Learning.
A atribuição de função pode levar vários minutos para entrar em vigor.
Iniciar uma sessão de computação em estúdio
Antes de usar o estúdio do Azure Machine Learning para iniciar uma sessão de computação, certifique-se de que:
- Você tem a
AzureML Data Scientistfunção no espaço de trabalho. - O armazenamento de dados padrão (geralmente
workspaceblobstore) em seu espaço de trabalho é o tipo de blob. - O diretório de trabalho (
workspaceworkingdirectory) existe no espaço de trabalho. - Se você usar uma rede virtual para fluxo de prompt, compreenderá as considerações em Isolamento de rede no fluxo de prompt.
Iniciar uma sessão de computação em uma página de fluxo
Um fluxo liga-se a uma sessão de computação. Você pode iniciar uma sessão de computação em uma página de fluxo.
Selecione Iniciar. Inicie uma sessão de computação usando o ambiente definido na
flow.dag.yamlpasta de fluxo, ela é executada no tamanho da máquina virtual (VM) da computação sem servidor que você tem cota suficiente no espaço de trabalho.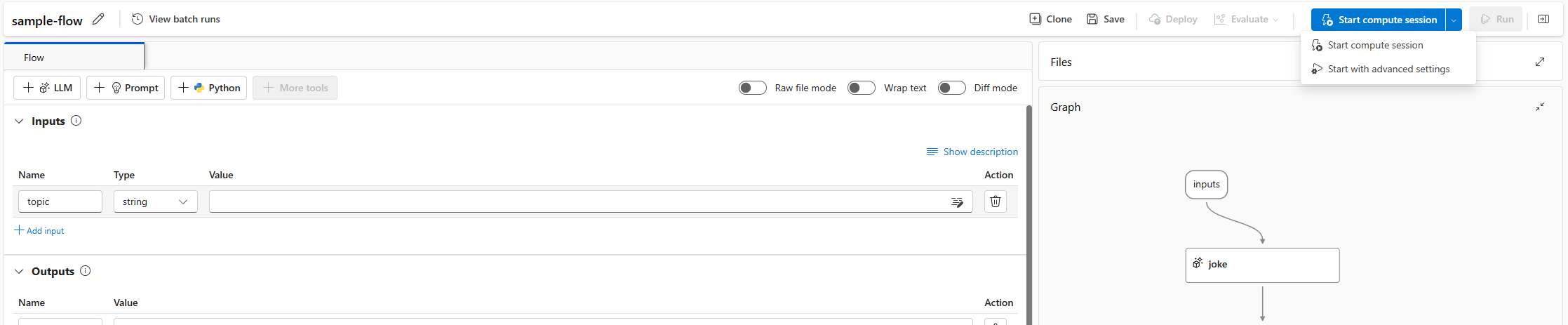
Selecione Iniciar com configurações avançadas. Nas configurações avançadas, você pode:
- Selecione o tipo de computação. Você pode escolher entre computação sem servidor e instância de computação.
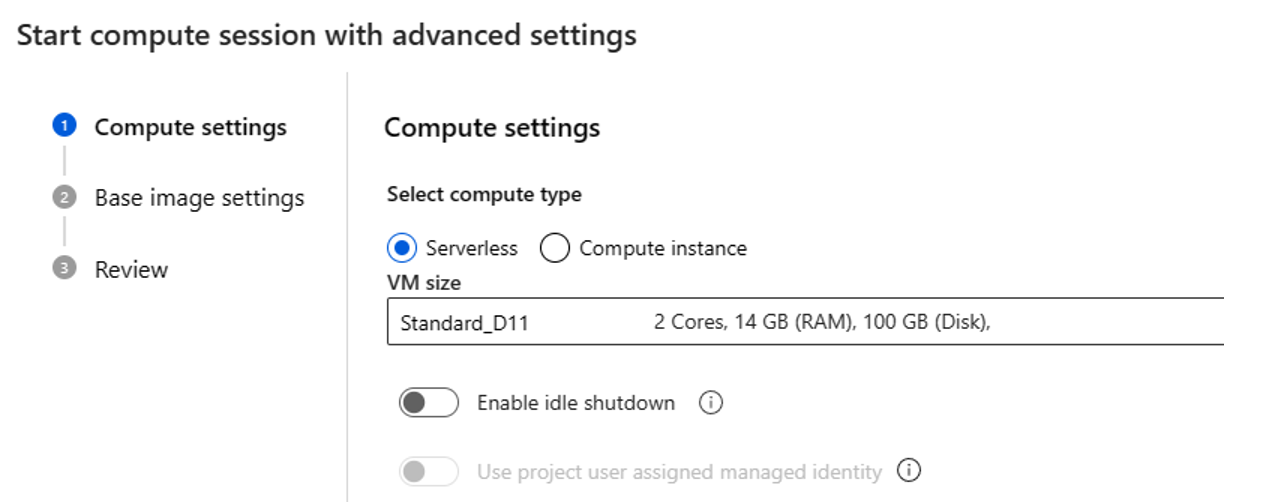
Se você escolher computação sem servidor, poderá definir as seguintes configurações:
- Personalize o tamanho da VM que a sessão de computação usa. Opte por VM série D e superior. Para obter mais informações, consulte a seção sobre séries e tamanhos de VM suportados
- Personalize o tempo ocioso, que exclui a sessão de computação automaticamente se ela não estiver em uso por um tempo.
- Defina a identidade gerenciada atribuída pelo usuário. A sessão de computação usa essa identidade para extrair uma imagem base, autenticar com conexão e instalar pacotes. Verifique se a identidade gerenciada atribuída pelo usuário tem permissão suficiente. Se você não definir essa identidade, usaremos a identidade do usuário por padrão.
- Você pode usar o seguinte comando da CLI para atribuir a identidade gerenciada atribuída ao usuário ao espaço de trabalho. Saiba mais sobre como criar e atualizar identidades atribuídas pelo usuário para um espaço de trabalho.
az ml workspace update -f workspace_update_with_multiple_UAIs.yml --subscription <subscription ID> --resource-group <resource group name> --name <workspace name>Em que o conteúdo do workspace_update_with_multiple_UAIs.yml é o seguinte:
identity: type: system_assigned, user_assigned user_assigned_identities: '/subscriptions/<subscription_id>/resourcegroups/<resource_group_name>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<uai_name>': {} '<UAI resource ID 2>': {}Gorjeta
As seguintes atribuições de função do RBAC do Azure são necessárias em sua identidade gerenciada atribuída pelo usuário para seu espaço de trabalho do Azure Machine Learning acessar dados nos recursos associados ao espaço de trabalho.
Recurso Permissão Área de trabalho do Azure Machine Learning Contribuinte Armazenamento do Azure Colaborador (plano de controle) + Contribuidor de dados de Blob de armazenamento + Colaborador privilegiado de dados de arquivo de armazenamento (plano de dados, consumir rascunho de fluxo em compartilhamento de arquivos e dados em blob) Azure Key Vault (ao usar o modelo de permissão de políticas de acesso) Colaborador + quaisquer permissões de política de acesso além das operações de limpeza, este é o modo padrão para o Cofre de Chaves do Azure vinculado. Azure Key Vault (ao usar o modelo de permissão RBAC) Colaborador (plano de controlo) + Administrador do Cofre de Chaves (plano de dados) Registo de Contentores do Azure Contribuinte Azure Application Insights Contribuinte Nota
O remetente do trabalho precisa ter
assignpermissão sobre a identidade gerenciada atribuída ao usuário, você pode atribuirManaged Identity Operatorfunção, pois toda vez que criar sessão de computação sem servidor, ele atribuirá a identidade gerenciada atribuída ao usuário para computar.Se você escolher instância de computação como tipo de computação, só poderá definir o tempo de desligamento ocioso.
Como está sendo executado em uma instância de computação existente, o tamanho da VM é fixo e não pode ser alterado no lado da sessão.
A identidade usada para esta sessão também é definida na instância de computação, por padrão ela usa a identidade do usuário. Saiba mais sobre como atribuir identidade à instância de computação
Para o tempo de desligamento ocioso, ele é usado para definir o ciclo de vida da sessão de computação, se a sessão estiver ociosa pelo tempo definido, ela será excluída automaticamente. E se você tiver o desligamento ocioso habilitado na instância de computação, ele terá efeito a partir do nível de computação.
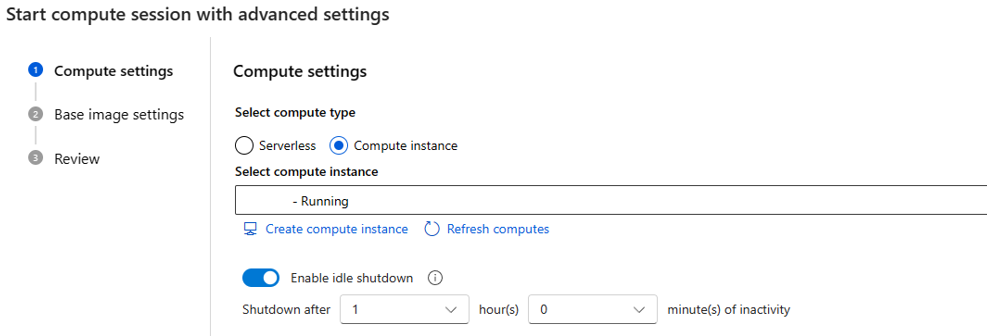
Saiba mais sobre como criar e gerenciar instâncias de computação
- Selecione o tipo de computação. Você pode escolher entre computação sem servidor e instância de computação.



Usar uma sessão de computação para enviar uma execução de fluxo na CLI/SDK
Além do studio, você também pode especificar a sessão de computação em CLI/SDK ao enviar uma execução de fluxo.
Você também pode especificar o tipo de instância ou o nome da instância de computação na parte do recurso. Se você não especificar o tipo de instância ou o nome da instância de computação, o Aprendizado de Máquina do Azure escolhe um tipo de instância (tamanho da VM) com base em fatores como cota, custo, desempenho e tamanho do disco. Saiba mais sobre computação sem servidor.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path_to_flow>
data: <path_to_flow>/data.jsonl
# specify identity used by serverless compute.
# default value
# identity:
# type: user_identity
# use workspace first UAI
# identity:
# type: managed
# use specified client_id's UAI
# identity:
# type: managed
# client_id: xxx
column_mapping:
url: ${data.url}
# define cloud resource
resources:
instance_type: <instance_type> # serverless compute type
# compute: <compute_instance_name> # use compute instance as compute type
Envie esta execução via CLI:
pfazure run create --file run.yml
Nota
O desligamento ocioso é de uma hora se você estiver usando CLI/SDK para enviar uma execução de fluxo. Você pode ir para a página de computação para liberar a computação.
Arquivos de referência fora da pasta de fluxo
Às vezes, você pode querer fazer referência a um requirements.txt arquivo que está fora da pasta de fluxo. Por exemplo, você pode ter um projeto complexo que inclui vários fluxos e eles compartilham o mesmo requirements.txt arquivo. Para fazer isso, você pode adicionar este campo additional_includes ao flow.dag.yaml. O valor deste campo é uma lista do caminho relativo do arquivo/pasta para a pasta de fluxo. Por exemplo, se requirements.txt estiver na pasta pai da pasta de fluxo, você poderá adicioná-lo ../requirements.txt ao additional_includes campo.
inputs:
question:
type: string
outputs:
output:
type: string
reference: ${answer_the_question_with_context.output}
environment:
python_requirements_txt: requirements.txt
additional_includes:
- ../requirements.txt
...
O requirements.txt arquivo é copiado para a pasta de fluxo e use-o para iniciar sua sessão de computação.
Atualizar uma sessão de computação na página de fluxo do estúdio
Em uma página de fluxo, você pode usar as seguintes opções para gerenciar uma sessão de computação:
- Altere as configurações da sessão de computação, altere as configurações de computação como o tamanho da VM e a identidade gerenciada atribuída pelo usuário para computação sem servidor, se você estiver usando uma instância de computação, poderá alterar para usar outra instância. Você também pode alterar
- também pode alterar a identidade gerenciada atribuída pelo usuário para computação sem servidor. Se você alterar o tamanho da VM, a sessão de computação será redefinida com o novo tamanho da VM. Se
- Instalar pacotes a partir de requirements.txt Abrir
requirements.txtna interface do usuário de fluxo de prompt, você pode adicionar pacotes nele. - Exibir pacotes instalados mostra os pacotes instalados na sessão de computação. Ele inclui os pacotes instalados na imagem base e os pacotes especificados no
requirements.txtarquivo na pasta de fluxo. - Redefinir sessão de computação exclui a sessão de computação atual e cria uma nova com o mesmo ambiente. Se você encontrar um problema de conflito de pacote, você pode tentar esta opção.
- Parar sessão de computação exclui a sessão de computação atual. Se não houver nenhuma sessão de computação ativa na computação subjacente, o recurso de computação sem servidor também será excluído.

Você também pode personalizar o ambiente que você usa para executar esse fluxo adicionando pacotes no requirements.txt arquivo na pasta de fluxo. Depois de adicionar mais pacotes neste arquivo, você pode escolher uma destas opções:
- Salve e instale gatilhos
pip install -r requirements.txtna pasta de fluxo. O processo pode levar alguns minutos, dependendo dos pacotes que você instala. - Salvar apenas salva o
requirements.txtarquivo. Você mesmo pode instalar os pacotes mais tarde.

Nota
Você pode alterar o local e até mesmo o nome do arquivo do , mas certifique-se de requirements.txtalterá-lo também no flow.dag.yaml arquivo na pasta de fluxo.
Não fixe a versão de promptflow e promptflow-tools no requirements.txt, porque já os incluímos na imagem base da sessão.
requirements.txt não suportará arquivos de roda local. Construa-os em sua imagem e atualize a imagem base personalizada no flow.dag.yaml. Saiba mais sobre como criar uma imagem base personalizada.
Adicionar pacotes em um feed privado no Azure DevOps
Se você quiser usar um feed privado no Azure DevOps, siga estas etapas:
Atribua identidade gerenciada ao espaço de trabalho ou à instância de computação.
Use a computação sem servidor como sessão de computação, você precisa atribuir identidade gerenciada atribuída pelo usuário ao espaço de trabalho.
Crie uma identidade gerenciada atribuída pelo usuário e adicione essa identidade na organização do Azure DevOps. Para saber mais, consulte Usar entidades de serviço e identidades gerenciadas.
Nota
Se o botão Adicionar usuários não estiver visível, você provavelmente não terá as permissões necessárias para executar essa ação.
Adicione ou atualize identidades atribuídas pelo usuário a um espaço de trabalho.
Nota
Certifique-se de que a identidade gerenciada atribuída pelo usuário tenha
Microsoft.KeyVault/vaults/readno keyvault vinculado ao espaço de trabalho.
Use a instância de computação como sessão de computação, você precisa atribuir uma identidade gerenciada atribuída pelo usuário a uma instância de computação.
Adicione
{private}ao URL do seu feed privado. Por exemplo, se você quiser instalartest_packagea partir dotest_feedAzure DevOps, adicione-i https://{private}@{test_feed_url_in_azure_devops}requirements.txt:-i https://{private}@{test_feed_url_in_azure_devops} test_packageEspecifique usando a identidade gerenciada atribuída pelo usuário na configuração da sessão de computação.
Se você estiver usando computação sem servidor, especifique a identidade gerenciada atribuída pelo usuário em Iniciar com configurações avançadas se a sessão de computação não estiver em execução ou use o botão Alterar configurações da sessão de computação se a sessão de computação estiver em execução.
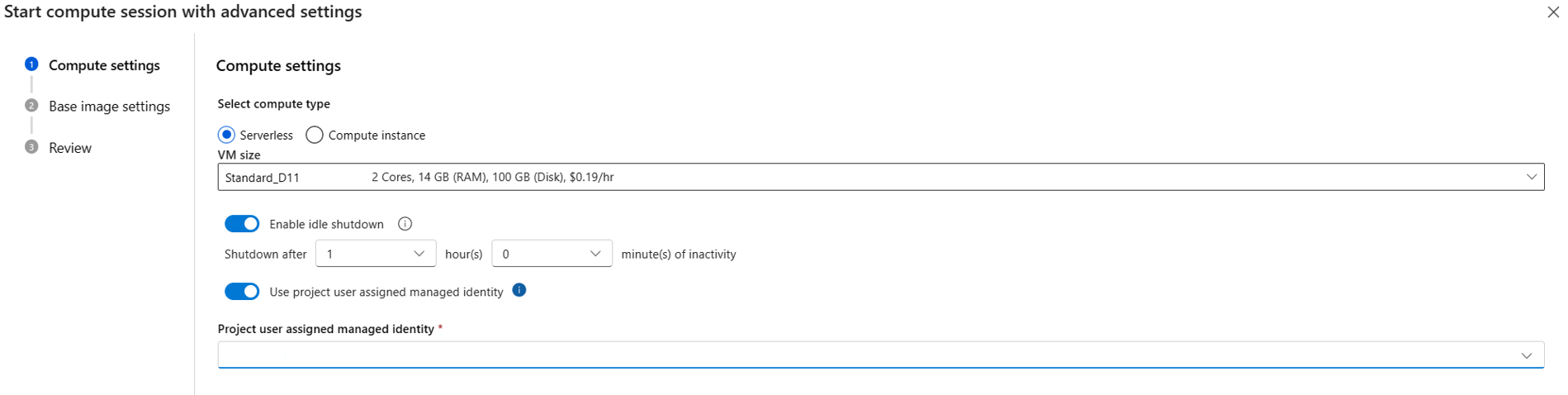
Se você estiver usando a instância de computação, ela usará a identidade gerenciada atribuída pelo usuário que você atribuiu à instância de computação.

Nota
Essa abordagem se concentra principalmente em testes rápidos na fase de desenvolvimento de fluxo, se você também quiser implantar esse fluxo como ponto final, crie este feed privado em sua imagem e atualize a imagem base personalizada no flow.dag.yaml. Saiba mais sobre como criar uma imagem de base personalizada
Alterar a imagem base da sessão de computação
Por padrão, usamos a imagem base de fluxo de prompt mais recente. Se você quiser usar uma imagem base diferente, você pode criar uma personalizada.
- No estúdio, você pode alterar a imagem base nas configurações de imagem base em configurações de sessão de computação.

Você também pode especificar a nova imagem base no
environmentflow.dag.yamlarquivo na pasta de fluxo.
environment: image: <your-custom-image> python_requirements_txt: requirements.txt

Para usar a nova imagem base, você precisa redefinir a sessão de computação. Esse processo leva vários minutos, pois extrai a nova imagem base e reinstala pacotes.
Gerenciar instância sem servidor usada pela sessão de computação
Ao usar a computação sem servidor como uma sessão de computação, você pode gerenciar a instância sem servidor. Exiba a instância sem servidor na guia Lista de sessões de computação na página de computação.

Você também pode acessar fluxos e execuções em execução na computação na guia Fluxos ativos e execuções . À medida que a exclusão, a instância afeta o fluxo e é executada nele.

Relação entre sessão de computação, recurso de computação, fluxo e usuário
- Um único usuário pode ter vários recursos de computação (sem servidor ou instância de computação). Devido a diferentes necessidades, um único usuário pode ter vários recursos de computação. Por exemplo, um usuário pode ter vários recursos de computação com tamanho de VM diferente ou identidade gerenciada atribuída pelo usuário diferente.
- Um recurso de computação só pode ser usado por um único usuário. Um recurso de computação é usado como caixa de desenvolvimento privada de um único usuário. Vários usuários não podem compartilhar os mesmos recursos de computação.
- Um recurso de computação pode hospedar várias sessões de computação. Uma sessão de computação é um contêiner executado em um recurso de computação subjacente. Por exemplo, a criação de fluxo de prompt não precisa de muitos recursos de computação, portanto, um único recurso de computação pode hospedar várias sessões de computação do mesmo usuário.
- Uma sessão de computação pertence apenas a um único recurso de computação de cada vez. Mas você pode excluir ou interromper uma sessão de computação e realocá-la para outro recurso de computação.
- Um fluxo só pode ter uma sessão de computação. Cada fluxo é independente e define a imagem base e os pacotes python necessários na pasta flow para a sessão de computação.
Alternar o tempo de execução para a sessão de computação
As sessões de computação têm as seguintes vantagens em relação aos tempos de execução da instância de computação:
- Gerencie automaticamente o ciclo de vida da sessão e a computação subjacente. Você não precisa mais criá-los e gerenciá-los manualmente.
- Personalize facilmente os pacotes adicionando pacotes no
requirements.txtarquivo na pasta de fluxo, em vez de criar um ambiente personalizado.
Alterne um tempo de execução de instância de computação para uma sessão de computação usando as seguintes etapas:
- Prepare seu
requirements.txtarquivo na pasta de fluxo. Certifique-se de que não fixa a versão depromptflowepromptflow-toolsnorequirements.txt, porque já os incluímos na imagem base. A sessão de computação instala os pacotes norequirements.txtarquivo quando é iniciada. - Se você criar um ambiente personalizado para criar um tempo de execução da instância de computação, poderá obter a imagem da página de detalhes do ambiente e especificá-la no
flow.dag.yamlarquivo na pasta de fluxo. Para saber mais, consulte Alterar a imagem base da sessão de computação. Verifique se você ou o usuário relacionado atribuído à identidade gerenciada no espaço de trabalho temacr pullpermissão para a imagem.

- Para o recurso de computação, você pode continuar a usar a instância de computação existente se quiser gerenciar manualmente o ciclo de vida ou pode tentar computação sem servidor cujo ciclo de vida é gerenciado pelo sistema.