Monitorizar o desempenho dos modelos implementados em produção
APLICA-SE A: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Aprenda a usar o monitoramento de modelo do Azure Machine Learning para acompanhar continuamente o desempenho dos modelos de aprendizado de máquina em produção. O monitoramento de modelos fornece uma visão ampla dos sinais de monitoramento e alerta você para possíveis problemas. Ao monitorar sinais e métricas de desempenho de modelos em produção, você pode avaliar criticamente os riscos inerentes associados a eles e identificar pontos cegos que podem afetar negativamente seus negócios.
Neste artigo você, aprenda a executar as seguintes tarefas:
- Configurar monitoramento pronto e avançado para modelos implantados em pontos de extremidade online do Azure Machine Learning
- Monitore métricas de desempenho para modelos em produção
- Monitorar modelos implantados fora do Azure Machine Learning ou implantados em pontos de extremidade em lote do Azure Machine Learning
- Configure o monitoramento de modelos com sinais e métricas personalizados
- Interpretar os resultados da monitorização
- Integrar o monitoramento de modelo do Azure Machine Learning com a Grade de Eventos do Azure
Pré-requisitos
Antes de seguir as etapas neste artigo, verifique se você tem os seguintes pré-requisitos:
A CLI do Azure e a
mlextensão para a CLI do Azure. Para obter mais informações, consulte Instalar, configurar e usar a CLI (v2).Importante
Os exemplos de CLI neste artigo pressupõem que você esteja usando o shell Bash (ou compatível). Por exemplo, de um sistema Linux ou Subsistema Windows para Linux.
Uma área de trabalho do Azure Machine Learning. Se você não tiver uma, use as etapas em Instalar, configurar e usar a CLI (v2) para criar uma.
Os controlos de acesso baseado em funções (RBAC do Azure) são utilizados para conceder acesso às operações no Azure Machine Learning. Para executar as etapas neste artigo, sua conta de usuário deve receber a função de proprietário ou colaborador para o espaço de trabalho do Azure Machine Learning ou uma função personalizada que permita
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Para obter mais informações, consulte Gerenciar o acesso a um espaço de trabalho do Azure Machine Learning.Para monitorar um modelo implantado em um ponto de extremidade online do Azure Machine Learning (ponto de extremidade online gerenciado ou ponto de extremidade online do Kubernetes), certifique-se de:
Tenha um modelo já implantado em um ponto de extremidade online do Azure Machine Learning. O endpoint online gerenciado e o endpoint online do Kubernetes são suportados. Se você não tiver um modelo implantado em um ponto de extremidade online do Azure Machine Learning, consulte Implantar e pontuar um modelo de aprendizado de máquina usando um ponto de extremidade online.
Habilite a coleta de dados para a implantação do modelo. Você pode habilitar a coleta de dados durante a etapa de implantação para pontos de extremidade online do Azure Machine Learning. Para obter mais informações, consulte Coletar dados de produção de modelos implantados em um ponto de extremidade em tempo real.
Para monitorar um modelo implantado em um ponto de extremidade em lote do Azure Machine Learning ou implantado fora do Azure Machine Learning, certifique-se de:
- Tenha um meio de coletar dados de produção e registrá-los como um ativo de dados do Azure Machine Learning.
- Atualize o ativo de dados registrado continuamente para monitoramento do modelo.
- (Recomendado) Registre o modelo em um espaço de trabalho do Azure Machine Learning, para rastreamento de linhagem.
Importante
Os trabalhos de monitoramento de modelo estão agendados para serem executados em pools de computação do Spark sem servidor com suporte para os seguintes tipos de instância de VM: Standard_E4s_v3, Standard_E8s_v3, Standard_E16s_v3, Standard_E32s_v3e Standard_E64s_v3. Você pode selecionar o tipo de instância de VM com a create_monitor.compute.instance_type propriedade em sua configuração YAML ou na lista suspensa no estúdio de Aprendizado de Máquina do Azure.
Configurar o monitoramento de modelo pronto para uso
Suponha que você implante seu modelo na produção em um ponto de extremidade online do Azure Machine Learning e habilite a coleta de dados no momento da implantação. Nesse cenário, o Azure Machine Learning coleta dados de inferência de produção e os armazena automaticamente no Armazenamento de Blobs do Microsoft Azure. Em seguida, você pode usar o monitoramento de modelo do Azure Machine Learning para monitorar continuamente esses dados de inferência de produção.
Você pode usar a CLI do Azure, o SDK do Python ou o estúdio para uma configuração pronta para uso do monitoramento de modelo. A configuração de monitoramento de modelo pronta para uso fornece os seguintes recursos de monitoramento:
- O Azure Machine Learning deteta automaticamente o conjunto de dados de inferência de produção associado a uma implementação online do Azure Machine Learning e utiliza o conjunto de dados para monitorização de modelos.
- O conjunto de dados de referência de comparação é definido como o conjunto de dados de inferência de produção recente e passada.
- A configuração de monitoramento inclui e rastreia automaticamente os sinais de monitoramento integrados: desvio de dados, desvio de previsão e qualidade de dados. Para cada sinal de monitoramento, o Azure Machine Learning usa:
- o conjunto de dados de inferência de produção recente e passada como o conjunto de dados de referência de comparação.
- Padrões inteligentes para métricas e limites.
- Um trabalho de monitoramento está programado para ser executado diariamente às 3h15 (por exemplo) para adquirir sinais de monitoramento e avaliar cada resultado métrico em relação ao limite correspondente. Por padrão, quando qualquer limite é excedido, o Aprendizado de Máquina do Azure envia um email de alerta para o usuário que configurou o monitor.
O monitoramento de modelo do Azure Machine Learning é usado az ml schedule para agendar um trabalho de monitoramento. Você pode criar o monitor de modelo pronto para uso com o seguinte comando CLI e definição YAML:
az ml schedule create -f ./out-of-box-monitoring.yaml
O YAML a seguir contém a definição para o monitoramento de modelo pronto para uso.
# out-of-box-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: credit_default_model_monitoring
display_name: Credit default model monitoring
description: Credit default model monitoring setup with minimal configurations
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute: # specify a spark compute for monitoring job
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification # model task type: [classification, regression, question_answering]
endpoint_deployment_id: azureml:credit-default:main # azureml endpoint deployment id
alert_notification: # emails to get alerts
emails:
- abc@example.com
- def@example.com


Configurar o monitoramento avançado de modelos
O Azure Machine Learning fornece muitos recursos para monitoramento contínuo de modelos. Consulte Recursos de monitoramento de modelo para obter uma lista abrangente desses recursos. Em muitos casos, você precisa configurar o monitoramento de modelo com recursos avançados de monitoramento. Nas seções a seguir, você configura o monitoramento de modelo com esses recursos:
- Uso de vários sinais de monitoramento para uma visão ampla.
- Uso de dados de treinamento de modelo histórico ou dados de validação como o conjunto de dados de referência de comparação.
- Monitoramento dos principais N recursos mais importantes e recursos individuais.
Configurar a importância do recurso
A importância do recurso representa a importância relativa de cada recurso de entrada para a saída de um modelo. Por exemplo, temperature pode ser mais importante para a previsão de um modelo em comparação com .elevation Habilitar a importância do recurso pode lhe dar visibilidade sobre quais recursos você não quer desviar ou ter problemas de qualidade de dados na produção.
Para habilitar a importância do recurso com qualquer um dos seus sinais (como desvio de dados ou qualidade de dados), você precisa fornecer:
- Seu conjunto de dados de treinamento como o
reference_dataconjunto de dados. - A
reference_data.data_column_names.target_columnpropriedade, que é o nome da coluna de saída/previsão do modelo.
Depois de habilitar a importância do recurso, você verá uma importância de recurso para cada recurso que estiver monitorando na interface do usuário do estúdio de monitoramento do modelo do Azure Machine Learning.
Você pode ativar/desabilitar alertas para cada sinal definindo alert_enabled a propriedade ao usar o SDK ou a CLI.
Você pode usar a CLI do Azure, o SDK do Python ou o estúdio para configuração avançada de monitoramento de modelo.
Crie uma configuração avançada de monitoramento de modelo com o seguinte comando CLI e definição YAML:
az ml schedule create -f ./advanced-model-monitoring.yaml
O YAML a seguir contém a definição para monitoramento avançado de modelos.
# advanced-model-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: fraud_detection_model_monitoring
display_name: Fraud detection model monitoring
description: Fraud detection model monitoring with advanced configurations
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute:
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:credit-default:main
monitoring_signals:
advanced_data_drift: # monitoring signal name, any user defined name works
type: data_drift
# reference_dataset is optional. By default referece_dataset is the production inference data associated with Azure Machine Learning online endpoint
reference_data:
input_data:
path: azureml:credit-reference:1 # use training data as comparison reference dataset
type: mltable
data_context: training
data_column_names:
target_column: DEFAULT_NEXT_MONTH
features:
top_n_feature_importance: 10 # monitor drift for top 10 features
alert_enabled: true
metric_thresholds:
numerical:
jensen_shannon_distance: 0.01
categorical:
pearsons_chi_squared_test: 0.02
advanced_data_quality:
type: data_quality
# reference_dataset is optional. By default reference_dataset is the production inference data associated with Azure Machine Learning online endpoint
reference_data:
input_data:
path: azureml:credit-reference:1
type: mltable
data_context: training
features: # monitor data quality for 3 individual features only
- SEX
- EDUCATION
alert_enabled: true
metric_thresholds:
numerical:
null_value_rate: 0.05
categorical:
out_of_bounds_rate: 0.03
feature_attribution_drift_signal:
type: feature_attribution_drift
# production_data: is not required input here
# Please ensure Azure Machine Learning online endpoint is enabled to collected both model_inputs and model_outputs data
# Azure Machine Learning model monitoring will automatically join both model_inputs and model_outputs data and used it for computation
reference_data:
input_data:
path: azureml:credit-reference:1
type: mltable
data_context: training
data_column_names:
target_column: DEFAULT_NEXT_MONTH
alert_enabled: true
metric_thresholds:
normalized_discounted_cumulative_gain: 0.9
alert_notification:
emails:
- abc@example.com
- def@example.com






Configurar o monitoramento de desempenho do modelo
A monitorização de modelos do Azure Machine Learning permite-lhe acompanhar o desempenho dos seus modelos em produção calculando as respetivas métricas de desempenho. Atualmente, há suporte para as seguintes métricas de desempenho do modelo:
Para os modelos de classificação:
- Precisão
- Precisão
- Recuperar
Para modelos de regressão:
- Erro Absoluto Médio (MAE)
- Erro quadrático médio (MSE)
- Erro quadrático médio raiz (RMSE)
Mais pré-requisitos para o monitoramento de desempenho do modelo
Você deve satisfazer os seguintes requisitos para configurar o sinal de desempenho do modelo:
Tenha dados de saída para o modelo de produção (as previsões do modelo) com um ID exclusivo para cada linha. Se você coletar dados de produção com o coletor de dados do Azure Machine Learning, um
correlation_idserá fornecido para cada solicitação de inferência para você. Com o coletor de dados, você também tem a opção de registrar sua própria ID exclusiva do seu aplicativo.Nota
Para o monitoramento de desempenho do modelo do Azure Machine Learning, recomendamos que você registre sua ID exclusiva em sua própria coluna, usando o coletor de dados do Azure Machine Learning.
Tenha dados de verdade básica (reais) com um ID exclusivo para cada linha. A ID exclusiva de uma determinada linha deve corresponder à ID exclusiva das saídas do modelo para essa solicitação de inferência específica. Esse ID exclusivo é usado para unir seu conjunto de dados de verdade de base com as saídas do modelo.
Sem ter dados de verdade básica, você não pode executar o monitoramento de desempenho do modelo. Como os dados de verdade básica são encontrados no nível do aplicativo, é sua responsabilidade coletá-los à medida que se tornam disponíveis. Você também deve manter um ativo de dados no Aprendizado de Máquina do Azure que contenha esses dados básicos de verdade.
(Opcional) Tenha um conjunto de dados tabular pré-unido com saídas de modelo e dados de verdade de base já unidos.
Monitorar os requisitos de desempenho do modelo ao usar o coletor de dados
Se você usar o coletor de dados do Aprendizado de Máquina do Azure para coletar dados de inferência de produção sem fornecer sua própria ID exclusiva para cada linha como uma coluna separada, uma correlationid será gerada automaticamente para você e incluída no objeto JSON registrado. No entanto, o coletor de dados enviará linhas em lote que são enviadas em curtos intervalos de tempo umas das outras. As linhas em lote cairão dentro do mesmo objeto JSON e, portanto, terão o mesmo correlationid.
Para diferenciar entre as linhas no mesmo objeto JSON, o monitoramento de desempenho do modelo do Aprendizado de Máquina do Azure usa indexação para determinar a ordem das linhas no objeto JSON. Por exemplo, se três linhas forem agrupadas em lotes e a linha um tiver uma ID de test_0, a linha dois terá uma ID de , e a correlationid linha três terá uma ID de test_1test_2.test Para garantir que seu conjunto de dados de verdade básica contenha IDs exclusivas que correspondam às saídas do modelo de inferência de produção coletado, certifique-se de indexar cada correlationid uma adequadamente. Se o objeto JSON registrado tiver apenas uma linha, o correlationid será correlationid_0.
Para evitar usar essa indexação, recomendamos que você registre sua ID exclusiva em sua própria coluna dentro do DataFrame pandas que você está registrando com o coletor de dados do Azure Machine Learning. Em seguida, na configuração de monitoramento do modelo, especifique o nome desta coluna para unir os dados de saída do modelo com os dados de verdade básica. Desde que as IDs de cada linha em ambos os conjuntos de dados sejam as mesmas, o monitoramento de modelo do Azure Machine Learning pode executar o monitoramento de desempenho do modelo.
Exemplo de fluxo de trabalho para monitorar o desempenho do modelo
Para entender os conceitos associados ao monitoramento de desempenho do modelo, considere este exemplo de fluxo de trabalho. Suponha que você esteja implantando um modelo para prever se as transações com cartão de crédito são fraudulentas ou não, você pode seguir estas etapas para monitorar o desempenho do modelo:
- Configure sua implantação para usar o coletor de dados para coletar os dados de inferência de produção do modelo (dados de entrada e saída). Digamos que os dados de saída são armazenados em uma coluna
is_fraud. - Para cada linha dos dados de inferência coletados, registre um ID exclusivo. A ID exclusiva pode vir do seu aplicativo ou você pode usar o que o
correlationidAprendizado de Máquina do Azure gera exclusivamente para cada objeto JSON registrado. - Mais tarde, quando os dados reais (ou reais)
is_fraudse tornam disponíveis, eles também são registrados e mapeados para o mesmo ID exclusivo que foi registrado com as saídas do modelo. - Esses dados de verdade
is_fraudbásica também são coletados, mantidos e registrados no Azure Machine Learning como um ativo de dados. - Crie um sinal de monitoramento de desempenho do modelo que una a inferência de produção do modelo e os ativos de dados de verdade básica, usando as colunas de ID exclusivas.
- Por fim, calcule as métricas de desempenho do modelo.
Depois de satisfazer os pré-requisitos para o monitoramento de desempenho do modelo, você pode configurar o monitoramento do modelo com o seguinte comando CLI e definição YAML:
az ml schedule create -f ./model-performance-monitoring.yaml
O YAML a seguir contém a definição para monitoramento de modelo com dados de inferência de produção que você coletou.
$schema: http://azureml/sdk-2-0/Schedule.json
name: model_performance_monitoring
display_name: Credit card fraud model performance
description: Credit card fraud model performance
trigger:
type: recurrence
frequency: day
interval: 7
schedule:
hours: 10
minutes: 15
create_monitor:
compute:
instance_type: standard_e8s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:loan-approval-endpoint:loan-approval-deployment
monitoring_signals:
fraud_detection_model_performance:
type: model_performance
production_data:
data_column_names:
prediction: is_fraud
correlation_id: correlation_id
reference_data:
input_data:
path: azureml:my_model_ground_truth_data:1
type: mltable
data_column_names:
actual: is_fraud
correlation_id: correlation_id
data_context: actuals
alert_enabled: true
metric_thresholds:
tabular_classification:
accuracy: 0.95
precision: 0.8
alert_notification:
emails:
- abc@example.com





Configure o monitoramento de modelo trazendo seus dados de produção para o Azure Machine Learning
Você também pode configurar o monitoramento de modelo para modelos implantados em pontos de extremidade em lote do Azure Machine Learning ou implantados fora do Azure Machine Learning. Se você não tiver uma implantação, mas tiver dados de produção, poderá usá-los para executar o monitoramento contínuo do modelo. Para monitorar esses modelos, você deve ser capaz de:
- Colete dados de inferência de produção de modelos implantados na produção.
- Registre os dados de inferência de produção como um ativo de dados do Azure Machine Learning e garanta atualizações contínuas dos dados.
- Forneça um componente de pré-processamento de dados personalizado e registre-o como um componente do Azure Machine Learning.
Você deve fornecer um componente de pré-processamento de dados personalizado se os dados não forem coletados com o coletor de dados. Sem esse componente de pré-processamento de dados personalizado, o sistema de monitoramento de modelo do Azure Machine Learning não saberá como processar seus dados em forma de tabela com suporte para janelas de tempo.
Seu componente de pré-processamento personalizado deve ter estas assinaturas de entrada e saída:
| Entrada/Saída | Nome da assinatura | Tipo | Description | Valor de exemplo |
|---|---|---|---|---|
| input | data_window_start |
literal, string | Hora de início da janela de dados em formato ISO8601. | 2023-05-01T04:31:57.012Z |
| input | data_window_end |
literal, string | Hora de fim da janela de dados em formato ISO8601. | 2023-05-01T04:31:57.012Z |
| input | input_data |
uri_folder | Os dados de inferência de produção coletados, que são registrados como um ativo de dados do Azure Machine Learning. | azureml:myproduction_inference_data:1 |
| saída | preprocessed_data |
MLTable | Um conjunto de dados tabular, que corresponde a um subconjunto do esquema de dados de referência. |
Para obter um exemplo de um componente de pré-processamento de dados personalizado, consulte custom_preprocessing no repositório do GitHub azuremml-examples.
Depois de satisfazer os requisitos anteriores, você pode configurar o monitoramento de modelo com o seguinte comando CLI e definição YAML:
az ml schedule create -f ./model-monitoring-with-collected-data.yaml
O YAML a seguir contém a definição para monitoramento de modelo com dados de inferência de produção que você coletou.
# model-monitoring-with-collected-data.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: fraud_detection_model_monitoring
display_name: Fraud detection model monitoring
description: Fraud detection model monitoring with your own production data
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute:
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:fraud-detection-endpoint:fraud-detection-deployment
monitoring_signals:
advanced_data_drift: # monitoring signal name, any user defined name works
type: data_drift
# define production dataset with your collected data
production_data:
input_data:
path: azureml:my_production_inference_data_model_inputs:1 # your collected data is registered as Azure Machine Learning asset
type: uri_folder
data_context: model_inputs
pre_processing_component: azureml:production_data_preprocessing:1.0.0
reference_data:
input_data:
path: azureml:my_model_training_data:1 # use training data as comparison baseline
type: mltable
data_context: training
data_column_names:
target_column: is_fraud
features:
top_n_feature_importance: 20 # monitor drift for top 20 features
alert_enabled: true
metric_thresholds:
numerical:
jensen_shannon_distance: 0.01
categorical:
pearsons_chi_squared_test: 0.02
advanced_prediction_drift: # monitoring signal name, any user defined name works
type: prediction_drift
# define production dataset with your collected data
production_data:
input_data:
path: azureml:my_production_inference_data_model_outputs:1 # your collected data is registered as Azure Machine Learning asset
type: uri_folder
data_context: model_outputs
pre_processing_component: azureml:production_data_preprocessing:1.0.0
reference_data:
input_data:
path: azureml:my_model_validation_data:1 # use training data as comparison reference dataset
type: mltable
data_context: validation
alert_enabled: true
metric_thresholds:
categorical:
pearsons_chi_squared_test: 0.02
alert_notification:
emails:
- abc@example.com
- def@example.com
Configure o monitoramento de modelos com sinais e métricas personalizados
Com o monitoramento de modelo do Azure Machine Learning, você pode definir um sinal personalizado e implementar qualquer métrica de sua escolha para monitorar seu modelo. Você pode registrar esse sinal personalizado como um componente do Azure Machine Learning. Quando seu trabalho de monitoramento de modelo do Azure Machine Learning é executado na agenda especificada, ele calcula a(s) métrica(s) que você definiu em seu sinal personalizado, assim como faz para os sinais pré-criados (desvio de dados, desvio de previsão e qualidade de dados).
Para configurar um sinal personalizado a ser usado para monitoramento de modelo, você deve primeiro definir o sinal personalizado e registrá-lo como um componente do Azure Machine Learning. O componente Azure Machine Learning deve ter estas assinaturas de entrada e saída:
Assinatura de entrada do componente
O DataFrame de entrada do componente deve conter os seguintes itens:
- An
mltablecom os dados processados do componente de pré-processamento - Qualquer número de literais, cada um representando uma métrica implementada como parte do componente de sinal personalizado. Por exemplo, se você implementou a métrica,
std_deviationprecisará de uma entrada parastd_deviation_threshold. Geralmente, deve haver uma entrada por métrica com o nome<metric_name>_threshold.
| Nome da assinatura | Tipo | Description | Valor de exemplo |
|---|---|---|---|
| production_data | MLTable | Um conjunto de dados tabular que corresponde a um subconjunto do esquema de dados de referência. | |
| std_deviation_threshold | literal, string | Respetivo limite para a métrica implementada. | 2 |
Assinatura de saída do componente
A porta de saída do componente deve ter a seguinte assinatura.
| Nome da assinatura | Tipo | Description |
|---|---|---|
| signal_metrics | MLTable | O mltable que contém as métricas computadas. O esquema é definido na próxima seção signal_metrics esquema. |
signal_metrics esquema
O DataFrame de saída do componente deve conter quatro colunas: group, metric_name, metric_valuee threshold_value.
| Nome da assinatura | Tipo | Description | Valor de exemplo |
|---|---|---|---|
| grupo | literal, string | Agrupamento lógico de nível superior a ser aplicado a essa métrica personalizada. | MONTANTE DA TRANSAÇÃO |
| metric_name | literal, string | O nome da métrica personalizada. | std_deviation |
| metric_value | numérico | O valor da métrica personalizada. | 44,896.082 |
| threshold_value | numérico | O limite para a métrica personalizada. | 2 |
A tabela a seguir mostra um exemplo de saída de um componente de sinal personalizado que calcula a std_deviation métrica:
| grupo | metric_value | metric_name | threshold_value |
|---|---|---|---|
| MONTANTE DA TRANSAÇÃO | 44,896.082 | std_deviation | 2 |
| LOCALHOUR | 3.983 | std_deviation | 2 |
| TRANSACTIONAMOUNTUSD | 54,004.902 | std_deviation | 2 |
| DIGITALITEMCOUNT | 7.238 | std_deviation | 2 |
| CONTAGEM DE ITENS FÍSICOS | 5.509 | std_deviation | 2 |
Para ver um exemplo de definição de componente de sinal personalizado e código de computação métrica, consulte custom_signal no repositório azureml-examples.
Depois de satisfazer os requisitos para usar sinais e métricas personalizados, você pode configurar o monitoramento de modelo com o seguinte comando CLI e definição YAML:
az ml schedule create -f ./custom-monitoring.yaml
O YAML a seguir contém a definição para monitoramento de modelo com um sinal personalizado. Algumas coisas a observar sobre o código:
- Ele pressupõe que você já tenha criado e registrado seu componente com a definição de sinal personalizada no Azure Machine Learning.
- O
component_iddo componente de sinal personalizado registrado éazureml:my_custom_signal:1.0.0. - Se você tiver coletado seus dados com o coletor de dados, poderá omitir a
pre_processing_componentpropriedade. Se desejar usar um componente de pré-processamento para pré-processar dados de produção não coletados pelo coletor de dados, você pode especificá-lo.
# custom-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: my-custom-signal
trigger:
type: recurrence
frequency: day # can be minute, hour, day, week, month
interval: 7 # #every day
create_monitor:
compute:
instance_type: "standard_e4s_v3"
runtime_version: "3.3"
monitoring_signals:
customSignal:
type: custom
component_id: azureml:my_custom_signal:1.0.0
input_data:
production_data:
input_data:
type: uri_folder
path: azureml:my_production_data:1
data_context: test
data_window:
lookback_window_size: P30D
lookback_window_offset: P7D
pre_processing_component: azureml:custom_preprocessor:1.0.0
metric_thresholds:
- metric_name: std_deviation
threshold: 2
alert_notification:
emails:
- abc@example.com
Interpretar os resultados da monitorização
Depois de configurar o monitor de modelo e a primeira execução ter sido concluída, você pode navegar de volta para a guia Monitoramento no estúdio de Aprendizado de Máquina do Azure para exibir os resultados.
Na visualização principal Monitoramento , selecione o nome do monitor modelo para ver a página Visão geral do monitor. Esta página mostra o modelo, o ponto de extremidade e a implantação correspondentes, juntamente com detalhes sobre os sinais que você configurou. A próxima imagem mostra um painel de monitoramento que inclui desvio de dados e sinais de qualidade de dados. Dependendo dos sinais de monitoramento configurados, seu painel pode ter uma aparência diferente.
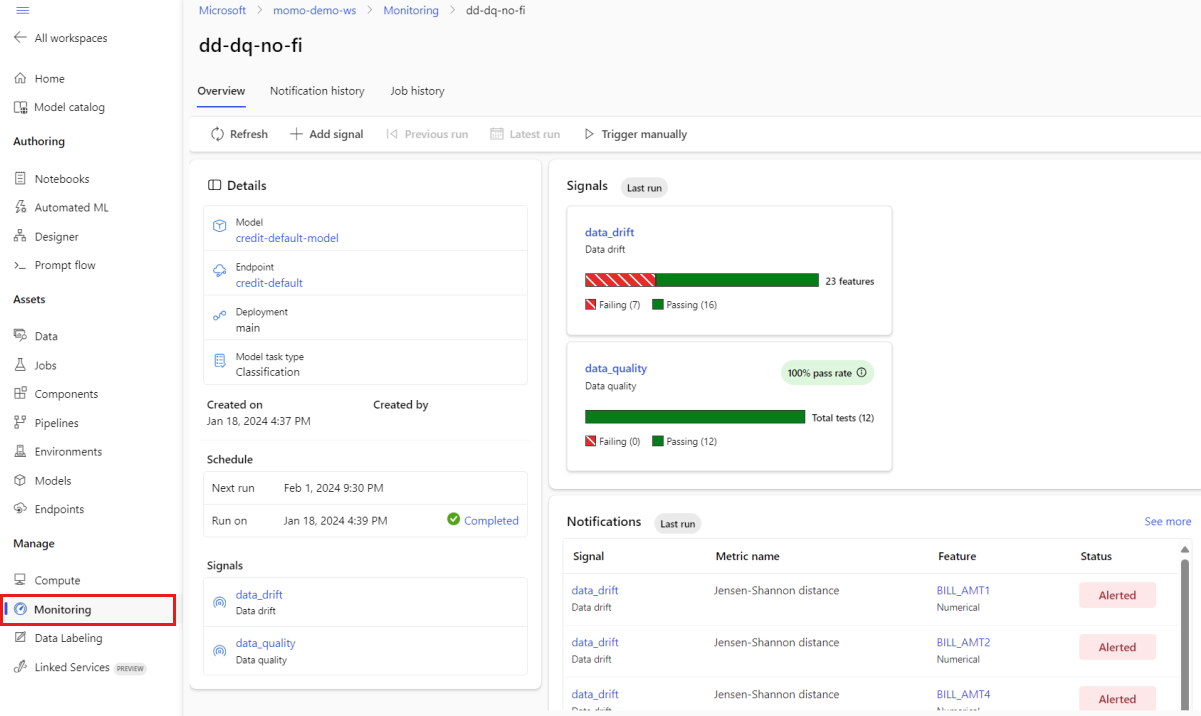
Procure na seção Notificações do painel para ver, para cada sinal, quais recursos violaram o limite configurado para suas respetivas métricas:
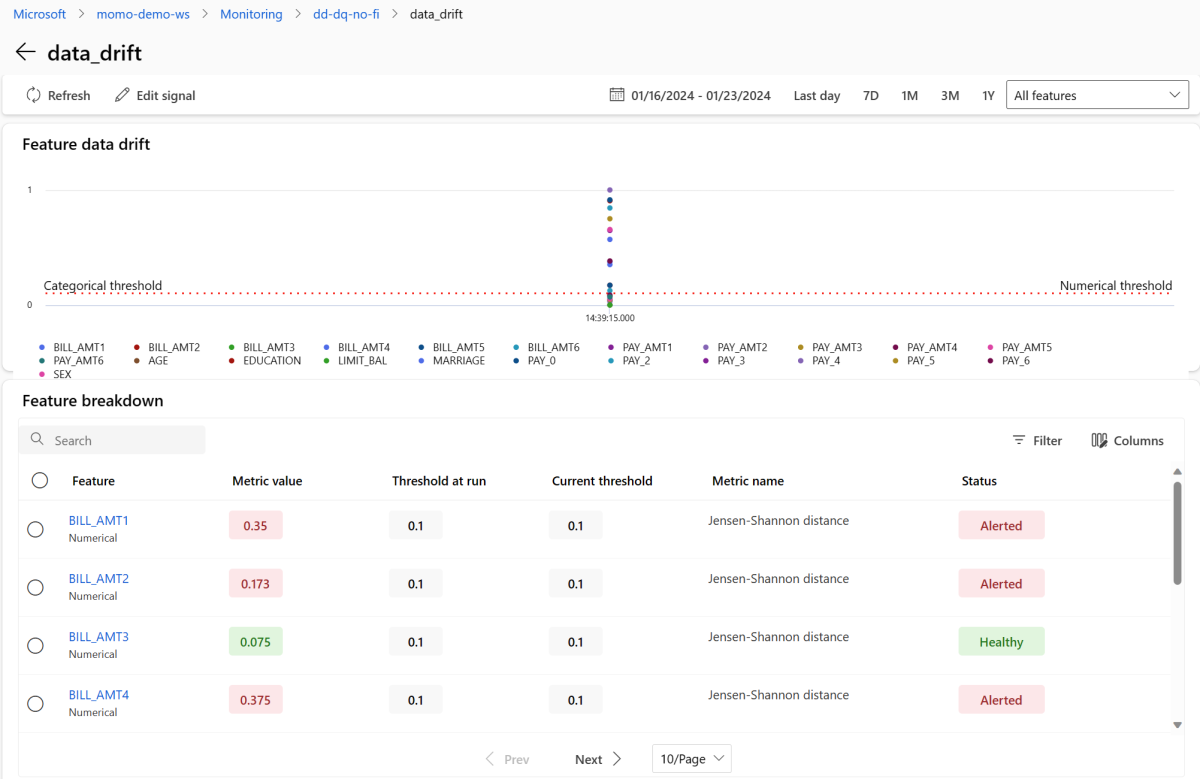
Selecione o data_drift para ir para a página de detalhes do desvio de dados. Na página de detalhes, você pode ver o valor da métrica de desvio de dados para cada recurso numérico e categórico incluído na configuração de monitoramento. Quando o monitor tiver mais de uma execução, você verá uma linha de tendência para cada recurso.
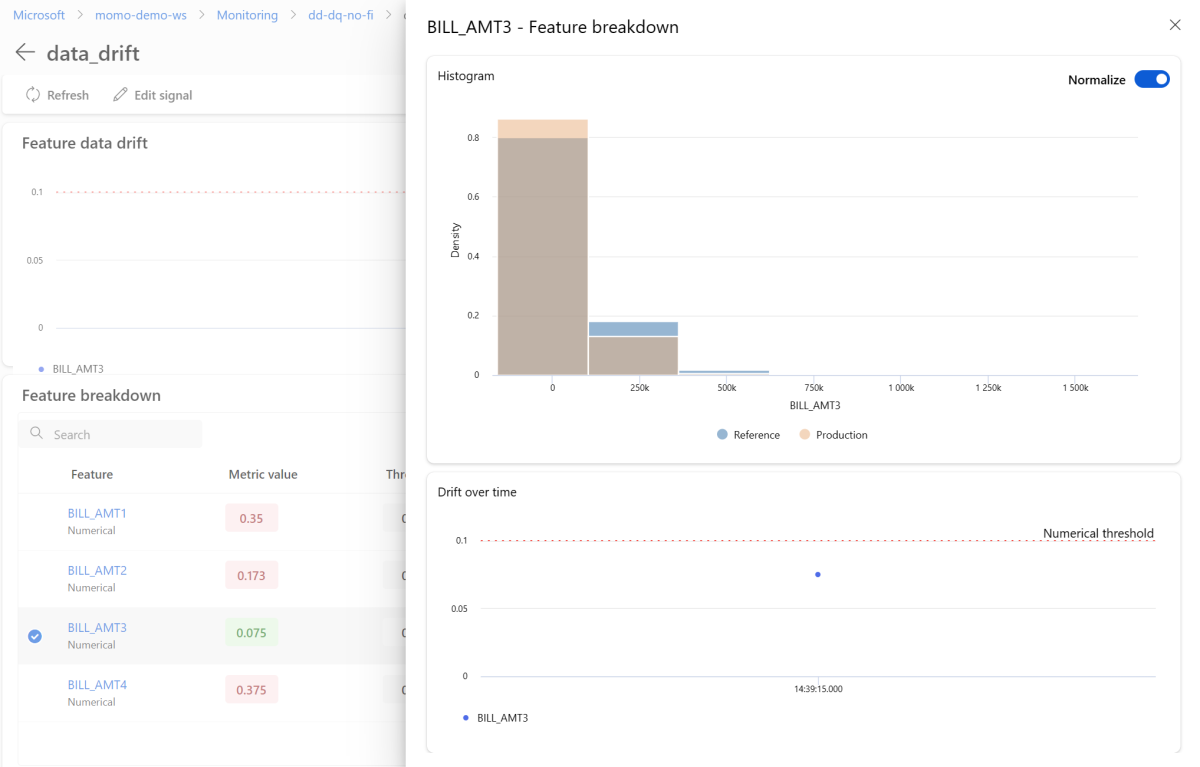
Para exibir um recurso individual em detalhes, selecione o nome do recurso para exibir a distribuição de produção em comparação com a distribuição de referência. Essa visualização também permite que você acompanhe o desvio ao longo do tempo para esse recurso específico.
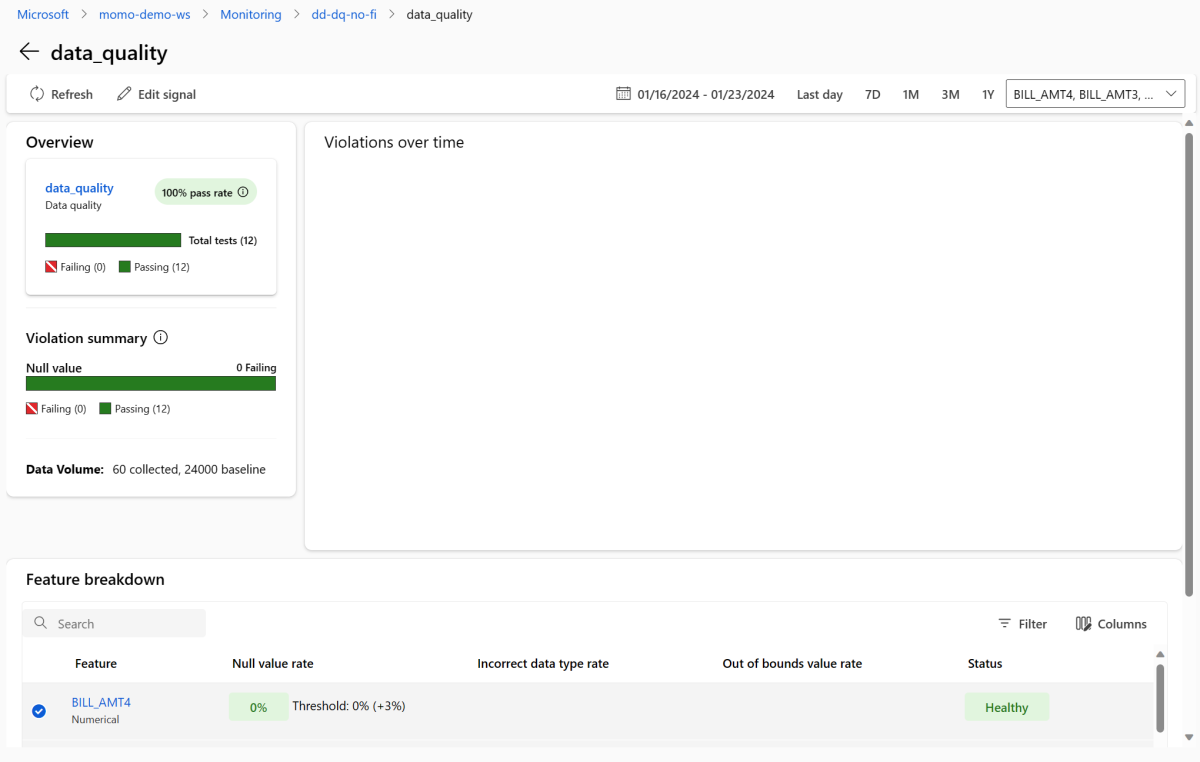
Retorne ao painel de monitoramento e selecione data_quality para exibir a página de sinal de qualidade de dados. Nesta página, você pode ver as taxas de valor nulo, taxas fora dos limites e taxas de erro de tipo de dados para cada recurso que você está monitorando.




A monitorização do modelo é um processo contínuo. Com o monitoramento de modelo do Azure Machine Learning, você pode configurar vários sinais de monitoramento para obter uma visão ampla do desempenho de seus modelos em produção.
Integrar o monitoramento de modelo do Azure Machine Learning com a Grade de Eventos do Azure
Você pode usar eventos gerados pelo monitoramento de modelo do Aprendizado de Máquina do Azure para configurar aplicativos, processos ou fluxos de trabalho de CI/CD orientados a eventos com a Grade de Eventos do Azure. Você pode consumir eventos por meio de vários manipuladores de eventos, como Hubs de Eventos do Azure, funções do Azure e aplicativos lógicos. Com base no desvio detetado pelos monitores, você pode agir programaticamente, como configurar um pipeline de aprendizado de máquina para treinar novamente um modelo e implantá-lo novamente.
Para começar a integrar o monitoramento de modelo do Azure Machine Learning com a Grade de Eventos:
Siga as etapas em consulte Configurar no portal do Azure. Dê um nome à sua Assinatura de Evento , como MonitoringEvent, e selecione apenas a caixa Executar status alterado em Tipos de Evento.
Aviso
Certifique-se de selecionar Executar status alterado para o tipo de evento. Não selecione Desvio do conjunto de dados detetado, pois ele se aplica ao desvio de dados v1, em vez do monitoramento do modelo do Azure Machine Learning.
Siga as etapas em Filtrar & inscrever-se em eventos para configurar a filtragem de eventos para seu cenário. Navegue até a guia Filtros e adicione a seguinte Chave, Operador e Valor em Filtros Avançados:
-
Chave:
data.RunTags.azureml_modelmonitor_threshold_breached - Valor: falhou devido a um ou mais recursos violando limites métricos
- Operador: String contém
Com esse filtro, os eventos são gerados quando o status de execução é alterado (de Concluído para Reprovado ou de Falha para Concluído) para qualquer monitor em seu espaço de trabalho do Azure Machine Learning.
-
Chave:
Para filtrar no nível de monitoramento, use a seguinte chave, operador e valor em Filtros avançados:
-
Chave:
data.RunTags.azureml_modelmonitor_threshold_breached -
Valor:
your_monitor_name_signal_name - Operador: String contém
Certifique-se de que
your_monitor_name_signal_nameé o nome de um sinal no monitor específico para o qual pretende filtrar eventos. Por exemplo,credit_card_fraud_monitor_data_drift. Para que esse filtro funcione, essa cadeia de caracteres deve corresponder ao nome do seu sinal de monitoramento. Você deve nomear seu sinal com o nome do monitor e o nome do sinal para este caso.-
Chave:
Quando tiver concluído a configuração da Subscrição de Eventos, selecione o ponto de extremidade pretendido para servir como manipulador de eventos, como os Hubs de Eventos do Azure.
Depois que os eventos forem capturados, você poderá visualizá-los na página do ponto de extremidade:

Você também pode exibir eventos na guia Métricas do Azure Monitor:
