Gerenciar entradas e saídas para componentes e pipelines
Os pipelines do Azure Machine Learning dão suporte a entradas e saídas nos níveis de componente e pipeline. Este artigo descreve as entradas e saídas de pipeline e componentes e como gerenciá-las.
No nível do componente, as entradas e saídas definem a interface do componente. Você pode usar a saída de um componente como entrada para outro componente no mesmo pipeline pai, permitindo que dados ou modelos sejam passados entre componentes. Essa interconectividade representa o fluxo de dados dentro do pipeline.
No nível do pipeline, você pode usar entradas e saídas para enviar trabalhos de pipeline com entradas ou parâmetros de dados variáveis, como learning_rate. As entradas e saídas são especialmente úteis quando você invoca um pipeline por meio de um ponto de extremidade REST. Você pode atribuir valores diferentes à entrada do pipeline ou acessar a saída de diferentes trabalhos do pipeline. Para obter mais informações, consulte Criar trabalhos e dados de entrada para pontos de extremidade em lote.
Tipos de entrada e saída
Os seguintes tipos são suportados como entradas e saídas de componentes ou pipelines:
Tipos de dados. Para obter mais informações, consulte Tipos de dados.
uri_fileuri_foldermltable
Tipos de modelos.
mlflow_modelcustom_model
Os seguintes tipos primitivos também são suportados apenas para entradas:
- Tipos primitivos
stringnumberintegerboolean
Não há suporte para saída de tipo primitivo.
Exemplos de entradas e saídas
Esses exemplos são do pipeline NYC Taxi Data Regression no repositório GitHub de exemplos do Azure Machine Learning.
- O componente de trem tem uma
numberentrada chamadatest_split_ratio. - O componente de preparação tem uma saída de
uri_foldertipo. O código-fonte do componente lê os arquivos CSV da pasta de entrada, processa os arquivos e grava os arquivos CSV processados na pasta de saída. - O componente do trem tem uma saída de
mlflow_modeltipo. O código-fonte do componente salva o modelo treinado usando omlflow.sklearn.save_modelmétodo.
Serialização de saída
O uso de dados ou saídas de modelo serializa as saídas e as salva como arquivos em um local de armazenamento. Etapas posteriores podem acessar os arquivos durante a execução do trabalho montando esse local de armazenamento ou baixando ou carregando os arquivos para o sistema de arquivos de computação.
O código-fonte do componente deve serializar o objeto de saída, que geralmente é armazenado na memória, em arquivos. Por exemplo, você pode serializar um dataframe pandas em um arquivo CSV. O Azure Machine Learning não define nenhum método padronizado para serialização de objetos. Você tem a flexibilidade de escolher seus métodos preferidos para serializar objetos em arquivos. No componente downstream, você pode escolher como desserializar e ler esses arquivos.
Caminhos de entrada e saída do tipo de dados
Para entradas e saídas de ativos de dados, você deve especificar um parâmetro de caminho que aponte para o local dos dados. A tabela a seguir mostra os locais de dados com suporte para entradas e saídas de pipeline do Azure Machine Learning, com path exemplos de parâmetros.
| Location | Entrada | Saída | Exemplo |
|---|---|---|---|
| Um caminho no computador local | ✓ | ./home/<username>/data/my_data |
|
| Um caminho em um servidor http/s público | ✓ | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
|
| Um caminho no Armazenamento do Azure | * | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>ou abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
|
| Um caminho em um armazenamento de dados do Azure Machine Learning | ✓ | ✓ | azureml://datastores/<data_store_name>/paths/<path> |
| Um caminho para um ativo de dados | ✓ | ✓ | azureml:my_data:<version> |
* Usar o Armazenamento do Azure diretamente não é recomendado para entrada, porque ele pode precisar de configuração de identidade extra para ler os dados. É melhor usar caminhos de armazenamento de dados do Azure Machine Learning, que são suportados em vários tipos de trabalho de pipeline.
Modos de entrada e saída do tipo de dados
Para entradas e saídas de tipo de dados, você pode escolher entre vários modos de download, upload e montagem para definir como o destino de computação acessa os dados. A tabela a seguir mostra os modos suportados para diferentes tipos de entradas e saídas.
| Type | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|
uri_folder entrada |
✓ | ✓ | ✓ | ||||
uri_file entrada |
✓ | ✓ | ✓ | ||||
mltable entrada |
✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder Saída |
✓ | ✓ | |||||
uri_file Saída |
✓ | ✓ | |||||
mltable Saída |
✓ | ✓ | ✓ |
Os ro_mount modos ou rw_mount são recomendados para a maioria dos casos. Para obter mais informações, consulte Modos.
Entradas e saídas em gráficos de pipeline
Na página de trabalho de pipeline no estúdio do Azure Machine Learning, as entradas e saídas de componentes aparecem como pequenos círculos chamados portas de entrada/saída. Essas portas representam o fluxo de dados no pipeline. A saída do nível do pipeline é exibida em caixas roxas para facilitar a identificação.
A captura de tela a seguir do gráfico de pipeline NYC Taxi Data Regression mostra muitas entradas e saídas de componentes e pipelines.

Quando você passa o mouse sobre uma porta de entrada/saída, o tipo é exibido.
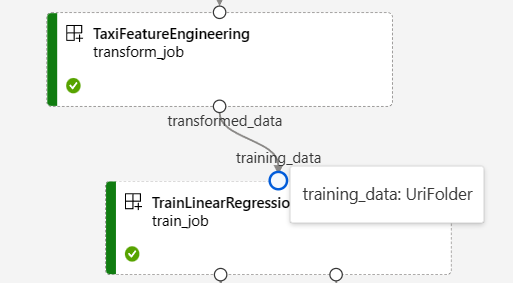
O gráfico de pipeline não exibe entradas de tipo primitivo. Essas entradas aparecem na guia Configurações do painel Visão geral do trabalho do pipeline para entradas no nível do pipeline ou no painel do componente para entradas no nível do componente. Para abrir o painel de componentes, clique duas vezes no componente no gráfico.

Quando você edita um pipeline no Studio Designer, as entradas e saídas do pipeline estão no painel de interface do pipeline e as entradas e saídas do componente estão no painel do componente.
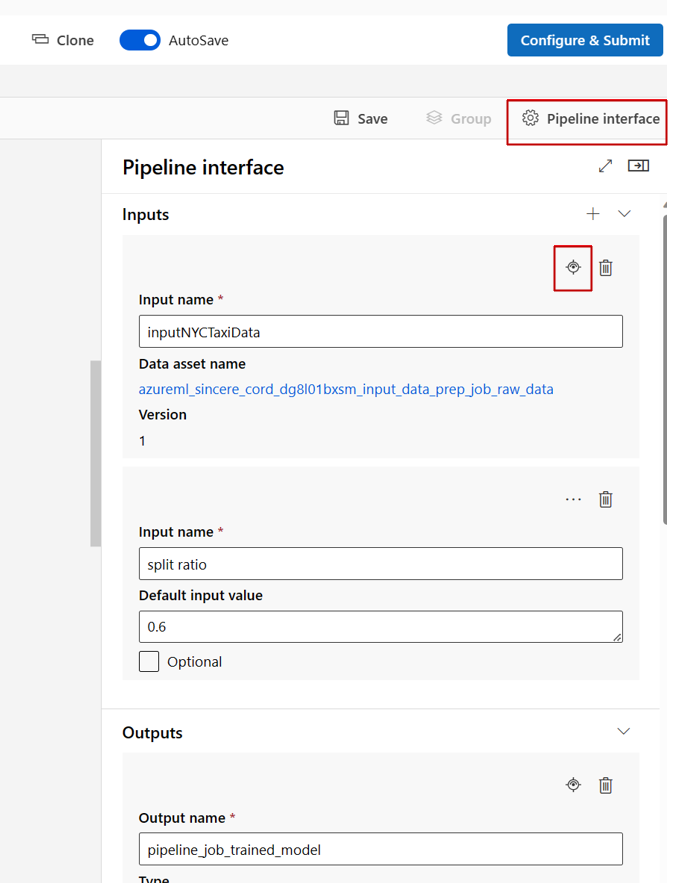
Promover entradas/saídas de componentes para o nível do pipeline
Promover a entrada/saída de um componente para o nível de pipeline permite substituir a entrada/saída do componente quando você envia um trabalho de pipeline. Essa capacidade é especialmente útil para acionar pipelines usando pontos de extremidade REST.
Os exemplos a seguir mostram como promover entradas/saídas no nível do componente para entradas/saídas no nível do pipeline.
O pipeline a seguir promove três entradas e três saídas para o nível do pipeline. Por exemplo, pipeline_job_training_max_epocs é entrada no nível do pipeline porque é declarada sob a inputs seção no nível raiz.
Na train_job seção , a jobs entrada nomeada max_epocs é referenciada como ${{parent.inputs.pipeline_job_training_max_epocs}}, o que significa que a train_jobentrada do faz referência à entrada no max_epocs nível pipeline_job_training_max_epocs do pipeline. A saída do pipeline é promovida usando o mesmo esquema.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 1b_e2e_registered_components
description: E2E dummy train-score-eval pipeline with registered components
inputs:
pipeline_job_training_max_epocs: 20
pipeline_job_training_learning_rate: 1.8
pipeline_job_learning_rate_schedule: 'time-based'
outputs:
pipeline_job_trained_model:
mode: upload
pipeline_job_scored_data:
mode: upload
pipeline_job_evaluation_report:
mode: upload
settings:
default_compute: azureml:cpu-cluster
jobs:
train_job:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
type: vs_code
my_jupyter_lab:
type: jupyter_lab
my_tensorboard:
type: tensor_board
log_dir: "outputs/tblogs"
# my_ssh:
# type: tensor_board
# ssh_public_keys: <paste the entire pub key content>
# nodes: all # Use the `nodes` property to pick which node you want to enable interactive services on. If `nodes` are not selected, by default, interactive applications are only enabled on the head node.
score_job:
type: command
component: azureml:my_score@latest
inputs:
model_input: ${{parent.jobs.train_job.outputs.model_output}}
test_data:
type: uri_folder
path: ./data
outputs:
score_output: ${{parent.outputs.pipeline_job_scored_data}}
evaluate_job:
type: command
component: azureml:my_eval@latest
inputs:
scoring_result: ${{parent.jobs.score_job.outputs.score_output}}
outputs:
eval_output: ${{parent.outputs.pipeline_job_evaluation_report}}
Você pode encontrar o exemplo completo no pipeline train-score-eval com componentes registrados no repositório de exemplos do Azure Machine Learning.
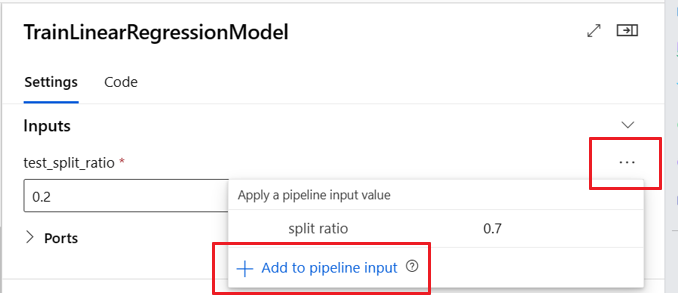
Definir entradas opcionais
Por padrão, todas as entradas são necessárias e devem ter um valor padrão ou ser atribuído um valor cada vez que você enviar um trabalho de pipeline. No entanto, você pode definir uma entrada opcional.
Nota
Não há suporte para saídas opcionais.
A definição de entradas opcionais pode ser útil em dois cenários:
Se você definir uma entrada opcional de tipo de dados/modelo e não atribuir um valor a ela ao enviar o trabalho de pipeline, o componente de pipeline não terá essa dependência de dados. Se a porta de entrada do componente não estiver vinculada a nenhum componente ou nó de dados/modelo, o pipeline invocará o componente diretamente em vez de aguardar uma dependência anterior.
Se você definir
continue_on_step_failure = Truepara o pipeline, masnode2usar a entrada necessária donode1,node2não será executado senode1falhar. Senode1a entrada for opcional,node2será executada mesmo senode1falhar. O gráfico a seguir demonstra esse cenário.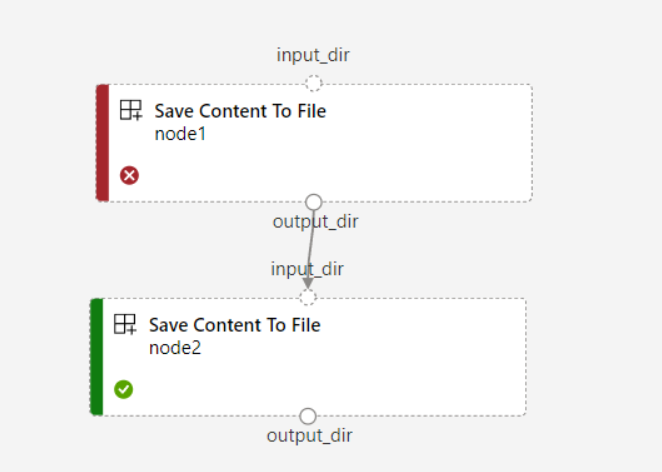
O exemplo de código a seguir mostra como definir entrada opcional. Quando a entrada é definida como optional = true, você deve usar $[[]] para abraçar as entradas de linha de comando, como nas linhas destacadas do exemplo.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_data_component_cli
display_name: train_data
description: A example train component
tags:
author: azureml-sdk-team
type: command
inputs:
training_data:
type: uri_folder
max_epocs:
type: integer
optional: true
learning_rate:
type: number
default: 0.01
optional: true
learning_rate_schedule:
type: string
default: time-based
optional: true
outputs:
model_output:
type: uri_folder
code: ./train_src
environment: azureml://registries/azureml/environments/sklearn-1.5/labels/latest
command: >-
python train.py
--training_data ${{inputs.training_data}}
$[[--max_epocs ${{inputs.max_epocs}}]]
$[[--learning_rate ${{inputs.learning_rate}}]]
$[[--learning_rate_schedule ${{inputs.learning_rate_schedule}}]]
--model_output ${{outputs.model_output}}

Personalizar caminhos de saída
Por padrão, a saída do componente é armazenada no conjunto definido {default_datastore} para o pipeline, azureml://datastores/${{default_datastore}}/paths/${{name}}/${{output_name}}. Se não estiver definido, o padrão será o armazenamento de blob do espaço de trabalho.
O trabalho {name} é resolvido no momento da execução do trabalho e {output_name} é o nome definido no componente YAML. Você pode personalizar onde armazenar a saída definindo um caminho de saída.
O arquivo pipeline.yml no pipeline train-score-eval com exemplo de componentes registrados define um pipeline que tem três saídas de nível de pipeline. Você pode usar o comando a seguir para definir caminhos de saída personalizados para a pipeline_job_trained_model saída.
# define the custom output path using datastore uri
# add relative path to your blob container after "azureml://datastores/<datastore_name>/paths"
output_path="azureml://datastores/{datastore_name}/paths/{relative_path_of_container}"
# create job and define path using --outputs.<outputname>
az ml job create -f ./pipeline.yml --set outputs.pipeline_job_trained_model.path=$output_path

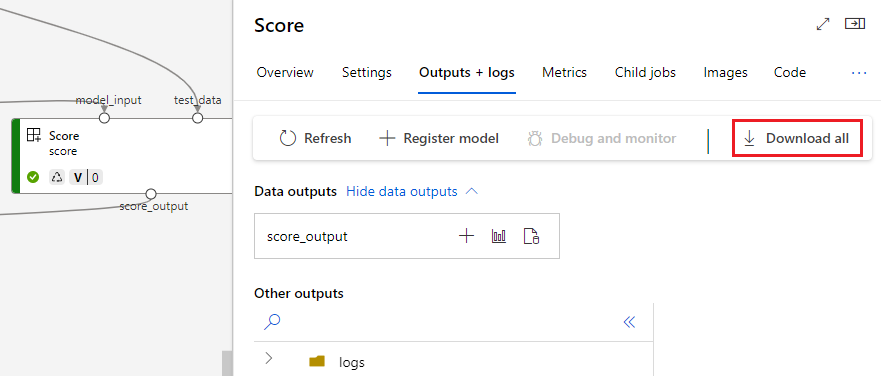
Download de saídas
Você pode baixar saídas no nível de pipeline ou componente.
Baixar saídas de nível de pipeline
Você pode baixar todas as saídas de um trabalho ou baixar uma saída específica.
# Download all the outputs of the job
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
# Download a specific output
az ml job download --output-name <OUTPUT_PORT_NAME> -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>

Baixar saídas de componentes
Para baixar as saídas de um componente filho, primeiro liste todos os trabalhos filho de um trabalho de pipeline e, em seguida, use um código semelhante para baixar as saídas.
# List all child jobs in the job and print job details in table format
az ml job list --parent-job-name <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID> -o table
# Select the desired child job name to download output
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
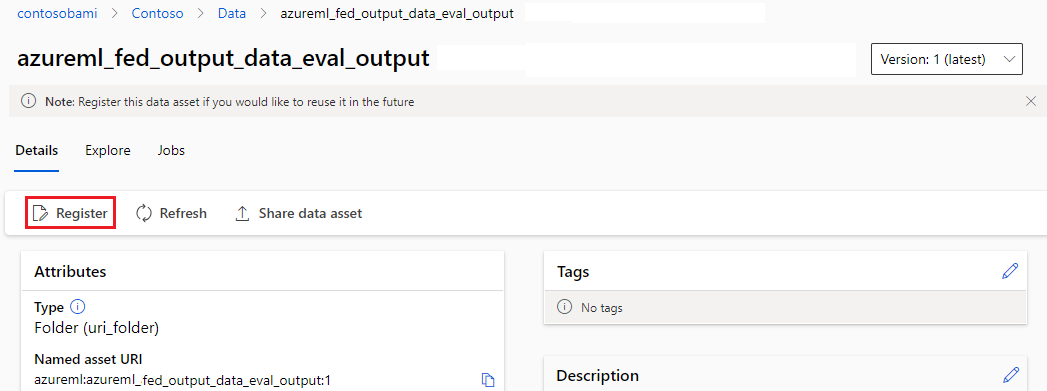
Registrar a saída como um ativo nomeado
Você pode registrar a saída de um componente ou pipeline como um ativo nomeado atribuindo um name e version à saída. O ativo registrado pode ser listado em seu espaço de trabalho por meio da interface do usuário do estúdio, CLI ou SDK e pode ser referenciado em trabalhos futuros do espaço de trabalho.
Registrar saída no nível do pipeline
display_name: register_pipeline_output
type: pipeline
jobs:
node:
type: command
inputs:
component_in_path:
type: uri_file
path: https://dprepdata.blob.core.windows.net/demo/Titanic.csv
component: ../components/helloworld_component.yml
outputs:
component_out_path: ${{parent.outputs.component_out_path}}
outputs:
component_out_path:
type: mltable
name: pipeline_output # Define name and version to register pipeline output
version: '1'
settings:
default_compute: azureml:cpu-cluster
Registrar saída de componente
display_name: register_node_output
type: pipeline
jobs:
node:
type: command
component: ../components/helloworld_component.yml
inputs:
component_in_path:
type: uri_file
path: 'https://dprepdata.blob.core.windows.net/demo/Titanic.csv'
outputs:
component_out_path:
type: uri_folder
name: 'node_output' # Define name and version to register a child job's output
version: '1'
settings:
default_compute: azureml:cpu-cluster