Transformar dados no designer do Azure Machine Learning
Neste artigo, você aprenderá a transformar e salvar conjuntos de dados no designer do Azure Machine Learning para preparar seus próprios dados para o aprendizado de máquina.
Você usará o conjunto de dados de amostra da Classificação Binária de Renda do Censo de Adultos para preparar dois conjuntos de dados: um conjunto de dados que inclui informações do censo de adultos apenas dos Estados Unidos e outro conjunto de dados que inclui informações do censo de adultos não americanos.
Neste artigo, vai aprender a:
- Transforme um conjunto de dados para prepará-lo para treinamento.
- Exporte os conjuntos de dados resultantes para um armazenamento de dados.
- Veja os resultados.
Este tutorial é um pré-requisito para o artigo como treinar novamente modelos de designer. Nesse artigo, você aprenderá a usar os conjuntos de dados transformados para treinar vários modelos, com parâmetros de pipeline.
Importante
Se você não observar os elementos gráficos mencionados neste documento, como botões no estúdio ou designer, talvez não tenha o nível correto de permissões para o espaço de trabalho. Entre em contato com o administrador da assinatura do Azure para verificar se você recebeu o nível correto de acesso. Para obter mais informações, visite Gerenciar usuários e funções.
Transformar um conjunto de dados
Nesta seção, você aprenderá como importar o conjunto de dados de exemplo e dividir os dados em conjuntos de dados dos EUA e de outros países. Visite como importar dados para obter mais informações sobre como importar seus próprios dados para o designer.
Importar dados
Use estas etapas para importar o conjunto de dados de exemplo:
Entre no estúdio do Azure Machine Learning e selecione o espaço de trabalho que deseja usar
Vá para o designer. Selecione Criar um novo pipeline usando componentes pré-construídos clássicos para criar um novo pipeline
À esquerda da tela do pipeline, na guia Componente, expanda o nó Dados de exemplo
Arraste e solte o conjunto de dados de classificação binária de renda do Adult Census na tela
Selecione com o botão direito do mouse o componente do conjunto de dados Adult Census Income e selecione Visualizar dados
Use a janela de visualização de dados para explorar o conjunto de dados. Tome especial nota dos valores da coluna "país nativo"
Dividir os dados
Nesta seção, você usará o componente Dados divididos para identificar e dividir linhas que contenham "Estados Unidos" na coluna "país nativo"
À esquerda da tela, na guia componente, expanda a seção Transformação de dados e localize o componente Dados divididos
Arraste o componente Dados divididos para a tela e solte esse componente abaixo do componente do conjunto de dados
Conectar o componente do conjunto de dados ao componente Dados divididos
Selecione o componente Dados divididos para abrir o painel Dados divididos
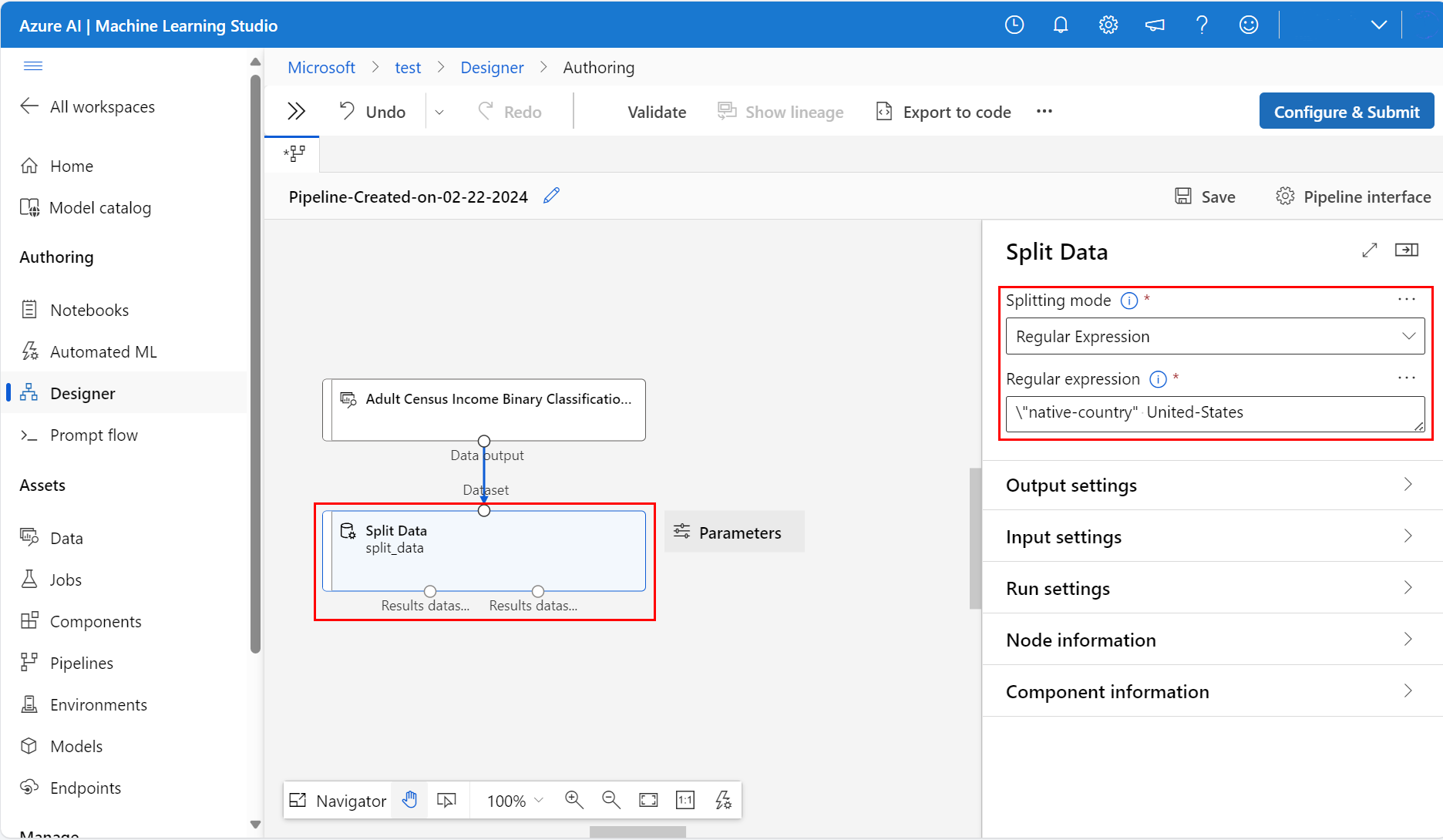
À direita da tela no ícone Parâmetros, defina Modo de divisão como Expressão regular
Insira a expressão regular:
\"native-country" United-StatesO modo de expressão regular testa uma única coluna para um valor. Visite a página de referência do componente de algoritmo relacionado para obter mais informações sobre o componente Dados divididos
Seu pipeline deve ser semelhante a esta captura de tela:
Salvar os conjuntos de dados
Agora que você configurou seu pipeline para dividir os dados, você deve especificar onde persistir os conjuntos de dados. Para este exemplo, use o componente Exportar dados para salvar seu conjunto de dados em um armazenamento de dados. Visite Conectar-se aos serviços de armazenamento do Azure para obter mais informações sobre armazenamentos de dados.
À esquerda da tela na paleta de componentes, expanda a seção Entrada e saída de dados e localize o componente Exportar dados
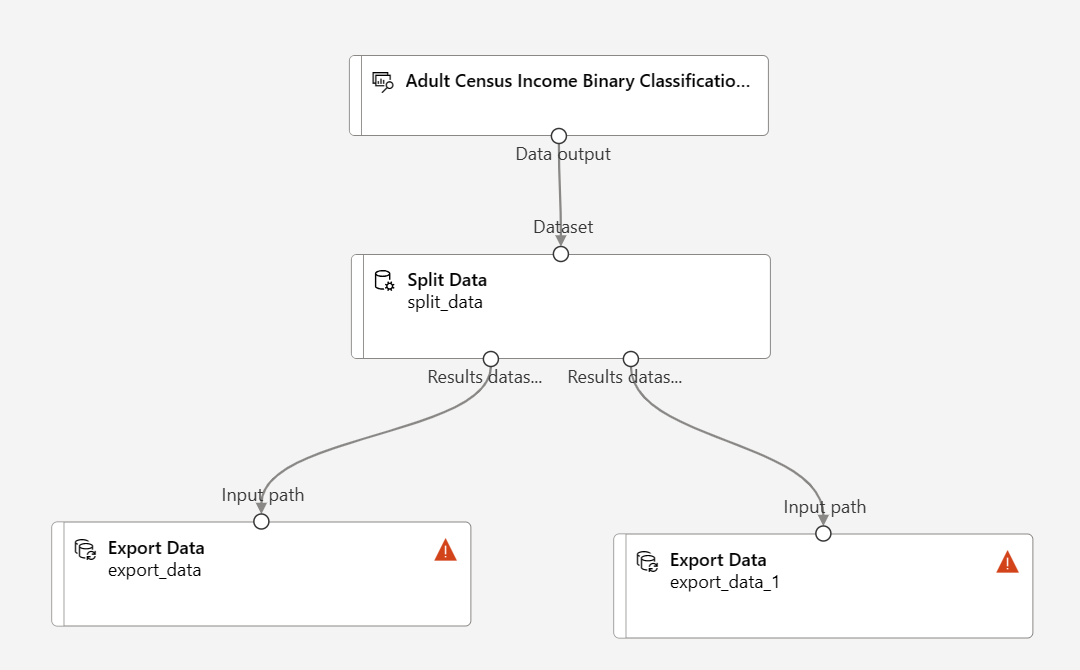
Arraste e solte dois componentes Exportar dados abaixo do componente Dados divididos
Conecte cada porta de saída do componente Split Data a um componente Export Data diferente
Seu pipeline deve ser semelhante a este:
Selecione o componente Exportar dados conectado à porta mais à esquerda do componente Dados divididos para abrir o painel de configuração Exportar dados
Para o componente Split Data , a ordem da porta de saída é importante. A primeira porta de saída contém as linhas onde a expressão regular é true. Nesse caso, a primeira porta contém linhas para renda baseada nos EUA e a segunda porta contém linhas para renda não baseada nos EUA
No painel de detalhes do componente à direita da tela, defina as seguintes opções:
Tipo de armazenamento de dados: Armazenamento de Blob do Azure
Datastore: Selecione um armazenamento de dados existente ou selecione "Novo armazenamento de dados" para criar um novo
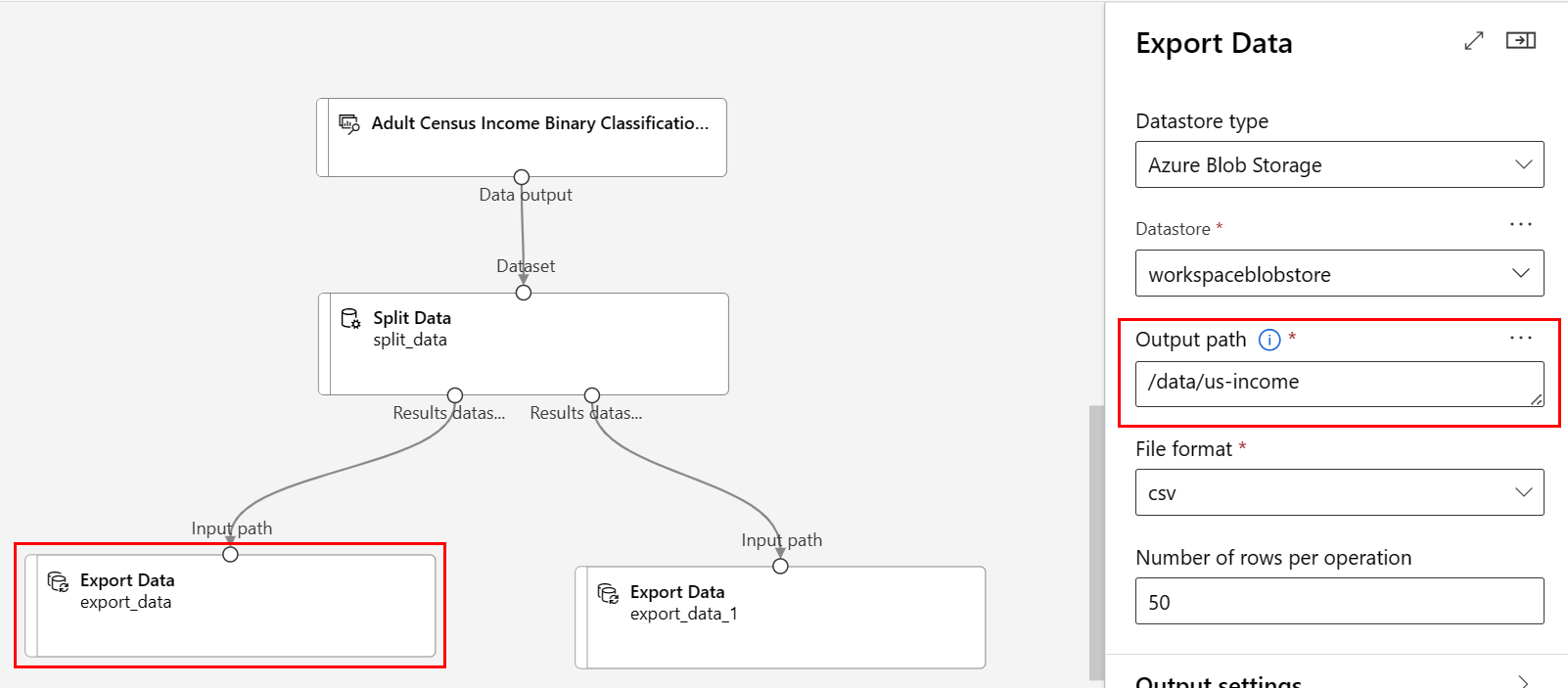
Caminho:
/data/us-incomeFormato de arquivo: csv
Nota
Este artigo pressupõe que você tenha acesso a um armazenamento de dados registrado no espaço de trabalho atual do Azure Machine Learning. Visite Conectar-se aos serviços de armazenamento do Azure para obter instruções de configuração do armazenamento de dados
Você pode criar um armazenamento de dados se não tiver um agora. Por exemplo, este artigo salva os conjuntos de dados na conta de armazenamento de blob padrão associada ao espaço de trabalho. Ele salva os conjuntos de dados no
azuremlcontêiner, em uma nova pasta chamadadataSelecione o componente Exportar dados conectado à porta mais à direita do componente Dados divididos para abrir o painel de configuração Exportar dados
À direita da tela no painel de detalhes do componente, defina as seguintes opções:
Tipo de armazenamento de dados: Armazenamento de Blob do Azure
Armazenamento de dados: selecione o armazenamento de dados anterior
Caminho:
/data/non-us-incomeFormato de arquivo: csv
Verifique se o componente Exportar dados conectado à porta esquerda dos dados divididos tem o caminho
/data/us-incomeVerifique se o componente Exportar dados conectado à porta correta tem o caminho
/data/non-us-incomeSeu pipeline e configurações devem ter esta aparência:
Submeter o trabalho
Agora que você configurou seu pipeline para dividir e exportar os dados, envie um trabalho de pipeline.
Selecione Configurar & Enviar na parte superior da tela
Selecione a opção Criar nova opção no painel Noções básicas de Configurar trabalho de pipeline, para criar um experimento
Os experimentos agrupam logicamente trabalhos de pipeline relacionados. Se você executar esse pipeline no futuro, deverá usar o mesmo experimento para fins de registro e rastreamento
Forneça um nome de experimento descritivo - por exemplo, "split-census-data"
Selecione Rever + Submeter e, em seguida, selecione Submeter
Ver resultados
Depois que o pipeline terminar de ser executado, você poderá navegar até o armazenamento de blob do portal do Azure para exibir seus resultados. Você também pode exibir os resultados intermediários do componente Dados divididos para confirmar se os dados foram divididos corretamente.
Selecione o componente Dividir dados
No painel de detalhes do componente à direita da tela, selecione a guia Saídas + logs
Selecione a lista suspensa Mostrar saídas de dados
Selecione o ícone
 de visualização ao lado de Conjunto de dados de resultados1
de visualização ao lado de Conjunto de dados de resultados1Verifique se a coluna "país nativo" contém apenas o valor "Estados Unidos"
Selecione o ícone
de visualização ao lado de Conjunto de dados de resultados2Verifique se a coluna "país nativo" não contém o valor "Estados Unidos"
Clean up resources (Limpar recursos)
Para continuar com a parte dois deste Retrain models with Azure Machine Learning designer how-to, ignore esta seção.
Importante
Você pode usar os recursos criados como pré-requisitos para outros tutoriais e artigos de instruções do Azure Machine Learning.
Excluir tudo
Se você não planeja usar nada do que criou, exclua todo o grupo de recursos para não incorrer em cobranças.
No portal do Azure, selecione Grupos de recursos no lado esquerdo da janela.
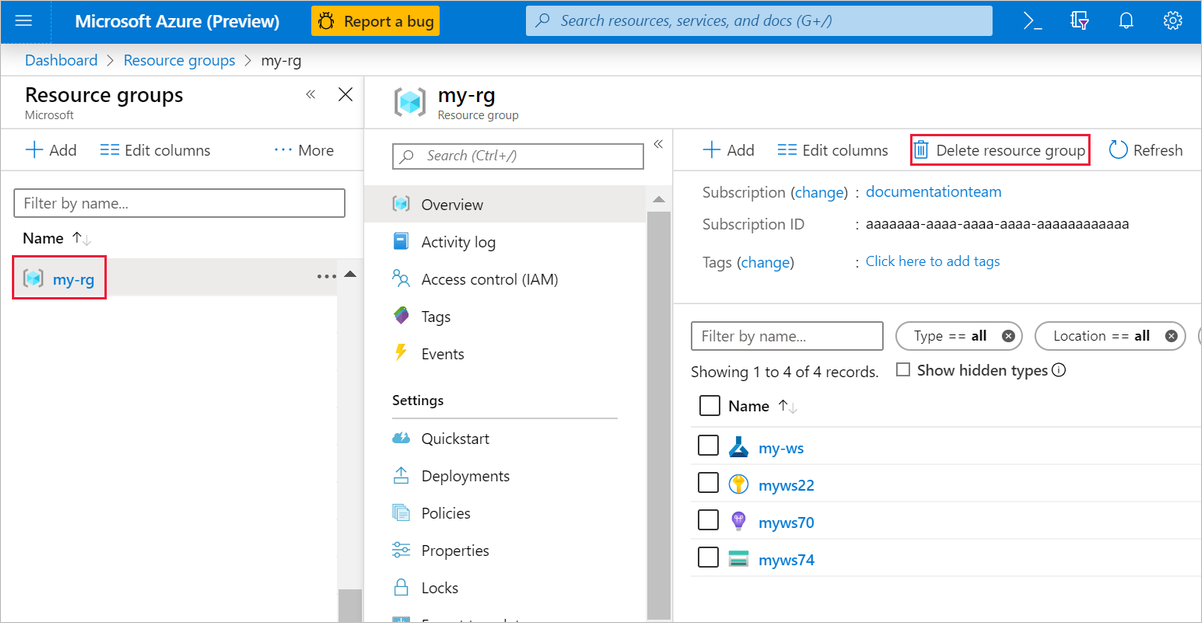
Na lista, selecione o grupo de recursos que você criou.
Selecione Eliminar grupo de recursos.
A exclusão do grupo de recursos também exclui todos os recursos criados no designer.
Excluir ativos individuais
No designer onde você criou seu experimento, exclua ativos individuais selecionando-os e, em seguida, selecionando o botão Excluir .
O destino de computação que você criou aqui é automaticamente dimensionado para zero nós quando não está sendo usado. Esta ação é tomada para minimizar as cobranças. Se você quiser excluir o destino de computação, execute estas etapas:
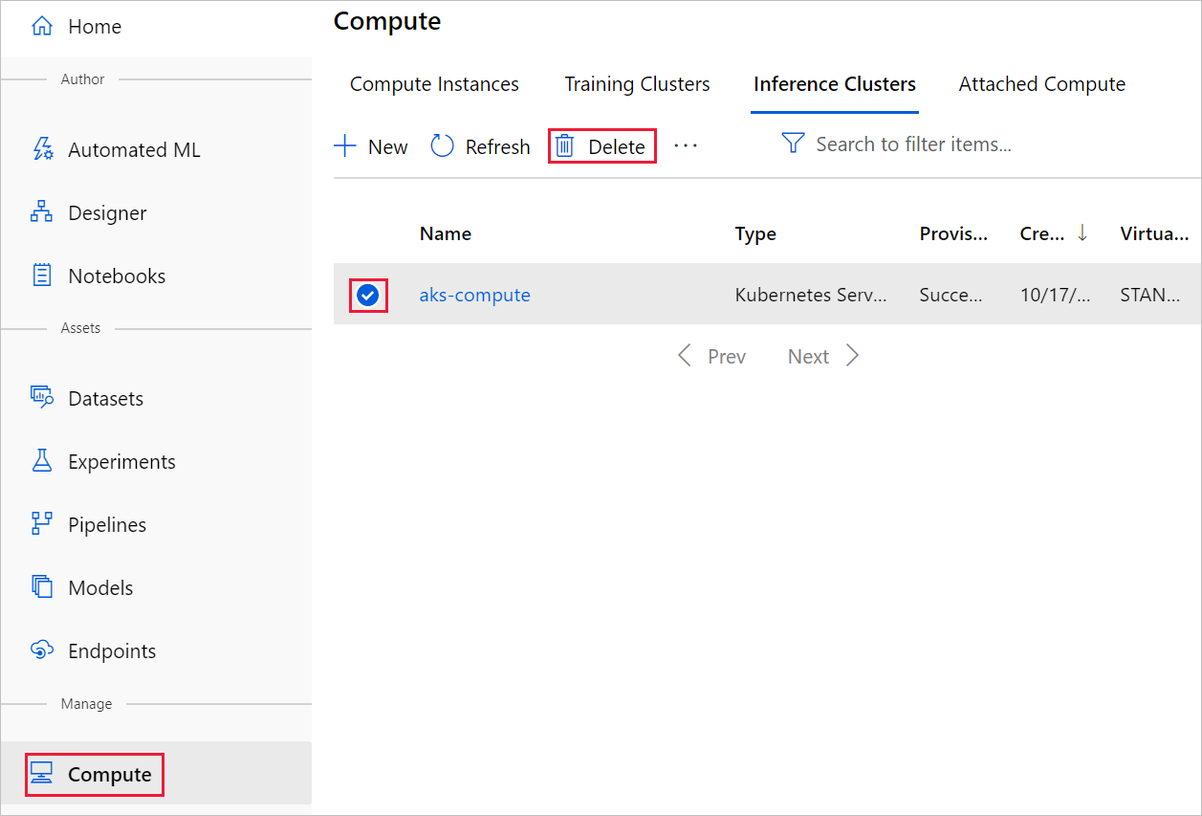
Você pode cancelar o registro de conjuntos de dados do seu espaço de trabalho selecionando cada conjunto de dados e selecionando Cancelar registro.
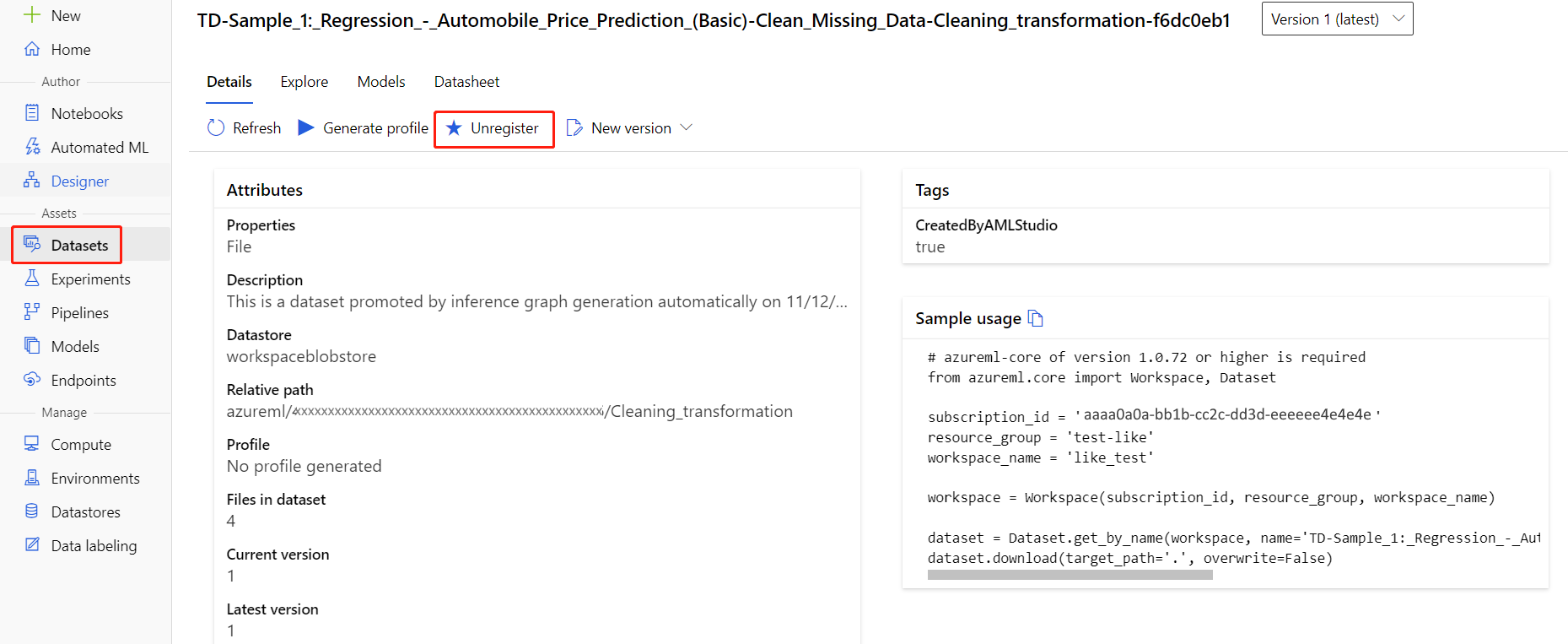
Para excluir um conjunto de dados, vá para a conta de armazenamento usando o portal do Azure ou o Gerenciador de Armazenamento do Azure e exclua manualmente esses ativos.
Próximos passos
Neste artigo, você aprendeu como transformar um conjunto de dados e salvá-lo em um armazenamento de dados registrado.
Continue para a próxima parte desta série de instruções com Retreinar modelos com o designer do Azure Machine Learning, para usar seus conjuntos de dados transformados e parâmetros de pipeline para treinar modelos de aprendizado de máquina.