Avaliar erros em modelos de aprendizagem automática
Um dos maiores desafios com as práticas atuais de depuração de modelos é usar métricas agregadas para pontuar modelos em um conjunto de dados de referência. A precisão do modelo pode não ser uniforme entre subgrupos de dados e pode haver coortes de entrada para as quais o modelo falha com mais frequência. As consequências diretas dessas falhas são a falta de confiabilidade e segurança, o aparecimento de problemas de equidade e a perda de confiança no aprendizado de máquina.

A análise de erros afasta-se das métricas de precisão agregada. Ele expõe a distribuição de erros para desenvolvedores de forma transparente e permite que eles identifiquem e diagnostiquem erros de forma eficiente.
O componente de análise de erros do painel de IA responsável fornece aos profissionais de aprendizado de máquina uma compreensão mais profunda da distribuição de falhas do modelo e os ajuda a identificar rapidamente coortes errôneas de dados. Esta componente identifica as coortes de dados com uma taxa de erro mais elevada em comparação com a taxa de erro global de referência. Ele contribui para o estágio de identificação do fluxo de trabalho do ciclo de vida do modelo através de:
- Uma árvore de decisão que revela coortes com altas taxas de erro.
- Um mapa de calor que visualiza como os recursos de entrada afetam a taxa de erro entre coortes.
Discrepâncias nos erros podem ocorrer quando o sistema tem um desempenho inferior para grupos demográficos específicos ou coortes de entrada raramente observadas nos dados de treinamento.
Os recursos desse componente vêm do pacote Análise de Erros, que gera perfis de erro de modelo.
Use a análise de erros quando precisar:
- Obtenha uma compreensão profunda de como as falhas de modelo são distribuídas em um conjunto de dados e em várias dimensões de entrada e recurso.
- Divida as métricas de desempenho agregadas para descobrir automaticamente coortes errôneas, a fim de informar suas etapas de mitigação direcionadas.
Árvore de erros
Muitas vezes, os padrões de erro são complexos e envolvem mais de um ou dois recursos. Os desenvolvedores podem ter dificuldade em explorar todas as combinações possíveis de recursos para descobrir bolsões de dados ocultos com falhas críticas.
Para aliviar a carga, a visualização em árvore binária particiona automaticamente os dados de referência em subgrupos interpretáveis que têm taxas de erro inesperadamente altas ou baixas. Em outras palavras, a árvore usa os recursos de entrada para separar ao máximo o erro do modelo do sucesso. Para cada nó que define um subgrupo de dados, os usuários podem investigar as seguintes informações:
- Taxa de erro: uma parte das instâncias no nó para as quais o modelo está incorreto. É mostrado através da intensidade da cor vermelha.
- Cobertura de erros: uma parte de todos os erros que caem no nó. É mostrado através da taxa de preenchimento do nó.
- Representação de dados: o número de instâncias em cada nó da árvore de erro. Ele é mostrado através da espessura da borda de entrada para o nó, juntamente com o número total de instâncias no nó.

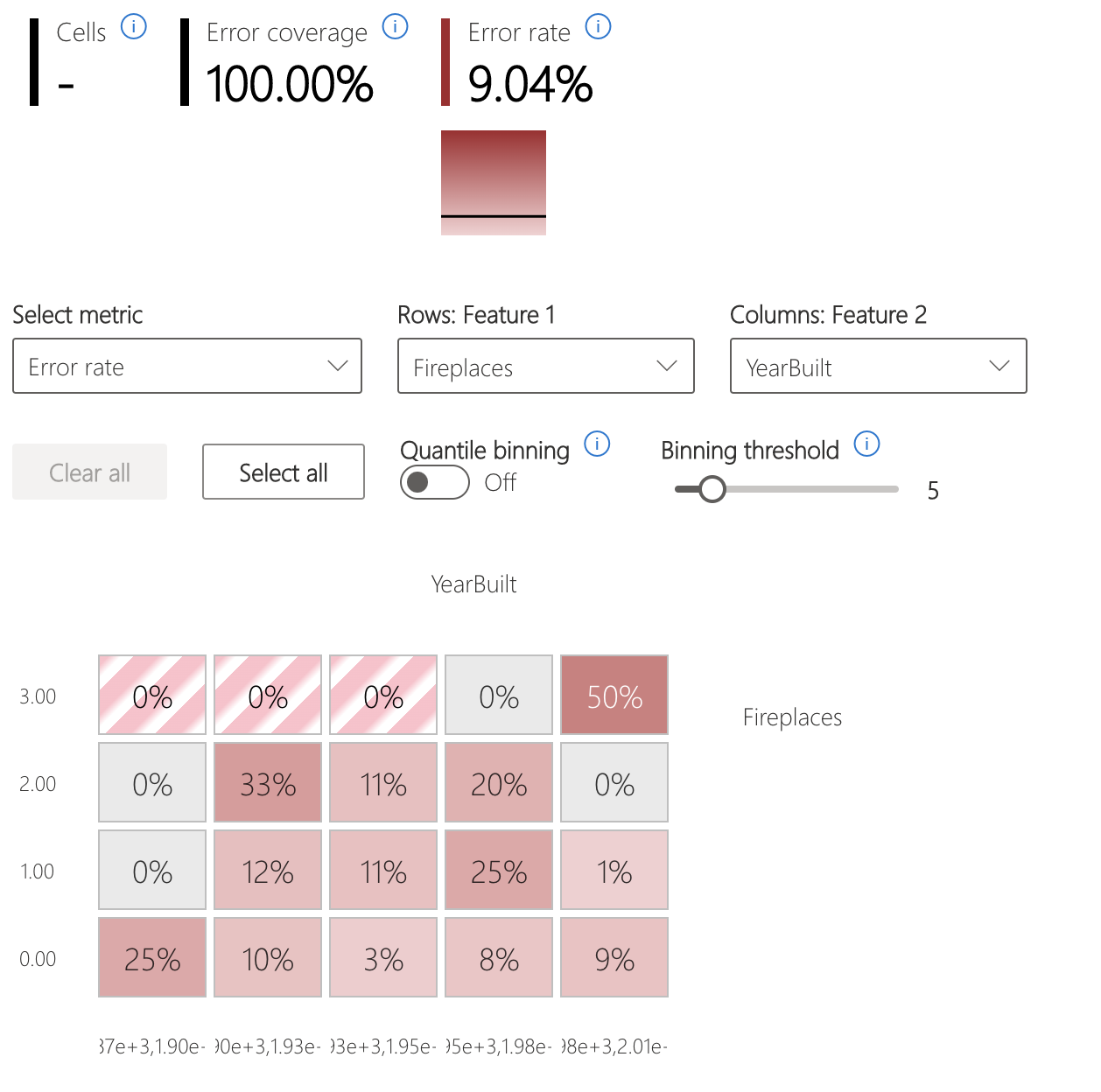
Mapa de calor de erro
A exibição fatia os dados com base em uma grade unidimensional ou bidimensional de recursos de entrada. Os usuários podem escolher os recursos de entrada de interesse para análise.
O mapa de calor visualiza células com alto erro usando uma cor vermelha mais escura para chamar a atenção do usuário para essas regiões. Esse recurso é especialmente benéfico quando os temas de erro são diferentes entre partições, o que acontece com frequência na prática. Nesta visão de identificação de erros, a análise é altamente guiada pelos usuários e seu conhecimento ou hipóteses de quais recursos podem ser mais importantes para a compreensão de falhas.
Próximos passos
- Saiba como gerar o painel de IA Responsável por meio de CLI e SDK ou da interface do usuário do estúdio Azure Machine Learning.
- Explore as visualizações de análise de erros suportadas.
- Saiba como gerar um scorecard de IA Responsável com base nos insights observados no painel de IA Responsável.